Assembly Architecture Go
 Hi, Habr! My name is Marco Kevac, I'm a Badoo system programmer on the Platform team, and I really love Go. If you add up these two things, then you will understand how much I love the assembler in Go.
Hi, Habr! My name is Marco Kevac, I'm a Badoo system programmer on the Platform team, and I really love Go. If you add up these two things, then you will understand how much I love the assembler in Go.More recently, we talked about Habré about what conferences we attended. One of them was GopherCon 2016 , where almost everyone remembered the report of Rob “The Commander” Pike about the Go-shny assembler. I present to you a translation of his report, in the form of an article. I tried to give in the text as much as possible links to relevant articles on Wikipedia.
Assembler? This is something as ancient as a mammoth!

Rob Pike speaks at GopherCon 2016
Thank! This is the most enthusiastic reaction to the assembly language report for many years. You may ask: why do we even talk about assembly language? The reason is, but about it later. You may also ask what interest assembly language may be. Let's go back to 1970 and take a look at the IBM manual: "The most important thing to understand is the following assembly language feature: it allows the programmer to use all the functions of the System / 360 computer as if he programmed at the System / 360 machine code level."
')
In many ways, these words are outdated, but the basic idea is still true: assembler is a way to interact with a computer at its most basic level. In fact, assembly language is needed even today. There was a time when only a assembler was available to the programmer.
Then came the so-called high-level languages, for example, Fortran and Cobol , which slowly but surely supplanted the assembler. For some time, even the C language was considered a high level compared to the assembler. But the need for an assembler persists today - because of the level of access to the computer that it provides.
The assembler is required for the initial loading of the environment, for the work of the stacks , for switching the context . In Go, by the way, switching between the gorutins is also implemented in assembler. There is still a performance issue: sometimes you can manually write code that works more efficiently than the result of the compiler. For example, a substantial part of the math / big package of the standard Go library is written in assembler, because the basic procedures of this library are much more efficient if you bypass the compiler and implement something better than he would have done. Sometimes an assembler is needed to work with new and unusual device functions or with features not available for higher-level languages — for example, new cryptographic instructions of modern processors.
But for me the most important thing in assembly language is that in its terms many people think about computer. Assembly language gives an idea of the instruction sets, the principles of the computer. Even if you do not program in assembly language - and I hope that there are no such things here - you should have an idea about assembly language, just to understand how a computer works. However, I will not pay too much attention to the assembly language itself, and this is in line with the idea of my report.
Many different and good assemblers
Many of you are not very familiar with assembly language. Therefore, I will give a number of examples, trying to adhere to the chronological order.
IBM System / 360
1 PRINT NOGEN 2 STOCK1 START 0 3 BEGIN BALR 11,0 4 USING *,11 5 MVC NEWOH,OLDOH 6 AP NEWOH,RECPT 7 AP NEWOH,ISSUE 8 EOJ 11 OLDOH DC PL4'9' 12 RECPT DC PL4'4' 13 ISSUE DC PL4'6' 14 NEWOH DS PL4 15 END BEGIN This is an IBM System / 360 assembler. It was about this computer was a quote at the beginning. Do not pay attention to the meaning, just take a look.
And this is to show the big picture .
Apollo 11 Guidance Computer
# TO ENTER A JOB REQUEST REQUIRING NO VAC AREA: COUNT 02/EXEC NOVAC INHINT AD FAKEPRET # LOC(MPAC +6) - LOC(QPRET) TS NEWPRIO # PRIORITY OF NEW JOB + NOVAC C(FIXLOC) EXTEND INDEX Q # Q WILL BE UNDISTURBED THROUGHOUT. DCA 0 # 2CADR OF JOB ENTERED. DXCH NEWLOC CAF EXECBANK XCH FBANK TS EXECTEM1 TCF NOVAC2 # ENTER EXECUTIVE BANK. This is the assembler code for the Apollo 11 ship's onboard computer. All of his programs were written entirely in assembler. The assembler helped us get to the moon.
PDP-10
TITLE COUNT A=1 ;Define a name for an accumulator. START: MOVSI A,-100 ;initialize loop counter. ;A contains -100,,0 LOOP: HRRZM A,TABLE(A) ;Use right half of A to index. AOBJN A,LOOP ;Add 1 to both halves (-77,,1 -76,,2 etc.) ;Jump if still negative. .VALUE ;Halt program. TABLE: BLOCK 100 ;Assemble space to fill up. END START ;End the assembly. This is an assembler for the PDP-10, and it is commented on in detail when compared with other examples.
PDP-11
/ a3 -- pdp-11 assembler pass 1 assem: jsr pc,readop jsr pc,checkeos br ealoop tst ifflg beq 3f cmp r4,$200 blos assem cmpb (r4),$21 /if bne 2f inc ifflg 2: cmpb (r4),$22 /endif bne assem dec ifflg br assem This is a fragment for the PDP-11. Moreover, it is a piece of code for an assembler in Unix v6 - which, of course, is written in assembler. Language C was used later.
Motorola 68000
strtolower public link a6,#0 ;Set up stack frame movea 8(a6),a0 ;A0 = src, from stack movea 12(a6),a1 ;A1 = dst, from stack loop move.b (a0)+,d0 ;Load D0 from (src) cmpi #'A',d0 ;If D0 < 'A', blo copy ;skip cmpi #'Z',d0 ;If D0 > 'Z', bhi copy ;skip addi #'a'-'A',d0 ;D0 = lowercase(D0) copy move.b d0,(a1)+ ;Store D0 to (dst) bne loop ;Repeat while D0 <> NUL unlk a6 ;Restore stack frame rts ;Return end Cray-1
ident slice V6 0 ; initialize S A4 S0 ; initialize *x A5 S1 ; initialize *y A3 S2 ; initialize i loop S0 A3 JSZ exit ; if S0 == 0 goto exit VL A3 ; set vector length V11 ,A4,1 ; load slice of x[i], stride 1 V12 ,A5,1 ; load slice of y[i], stride 1 V13 V11 *F V12 ; slice of x[i] * y[i] V6 V6 +F V13 ; partial sum A14 VL ; get vector length of this iteration A4 A4 + A14 ; *x = *x + VL A5 A5 + A14 ; *y = *y + VL A3 A3 - A14 ; i = i - VL J loop exit This is an assembler for the Motorola 68000, and this is for the Cray-1. I like this example; it is from Robert Griesemer’s dissertation. Reminds how it all began.

Robert Grisemeer speaking at GopherCon 2015
You may notice that all these are different languages, but in some ways they are similar: they have a common, very clear, structure.
Instructions
subroutine header label: instruction operand... ; comment ... Operands
register literal constant address register indirection (register as address) ... Programs in assembly language are usually written in a column: on the left — labels, then instructions, operands, and finally, on the right — comments. Operands are usually registers, constants, or memory addresses, but syntactically for different architectures they are quite similar. There are exceptions. The Cray example stands out against the general background: the addition command is written as a + symbol, as in an arithmetic expression. But the meaning is the same everywhere: this is the addition command, and this is the registers. That is, all this is in reality the same thing.
In other words, even a long time ago, even in my times, the processors were about the same as now. There are counterexamples, but most of the processors (and certainly all the processors on which Go works), in fact, remained the same, if not to pay attention to details. If you do not go into details, you can come to an interesting conclusion: for all these computers, you can make a general grammar. To understand this fact, it took about 30 years.
Ken's ingenious idea

From left to right: Robert Griseseer, Rob Pike, Ken Thompson
Around the mid-1980s, Ken Thompson and I began to think about the development, which later became Plan 9 . Ken wrote a new C compiler, which formed the basis of the C compiler in the Go tools and was used until recently. It was on a computer with a symmetric multiprocessor architecture of the company Sequent, which used the processors National 32000 . In my opinion, this was the first 32-bit microprocessor, available commercially in the form of an integrated circuit. But Ken did one interesting thing - some did not understand it then, but then it turned out to be very important. This is generally a feature of Ken.
The compiler did not generate machine instructions - it gave out something like pseudo-code. And then the second program (in fact, the linker ) accepted the result of the compiler and converted these pseudoinstructions into real instructions.
Instructions like
MOVW $0, var could become just
XORW R1, R1 STORE R1, var I will give an abstract example. There is, for example, the MOVW instruction, which places a zero in a variable. The code issued by the linker, which will be executed on the computer, may consist, for example, of XORW instructions, for which both operands are given the same register (that is, it resets the register value), and STORE, which places the value of this register in the variable . Do not worry about the details: the point here is that the instructions that the computer performs may not quite correspond to what we are entering into the assembler.
This process of drawing up real instructions based on pseudoinstructions we call the choice of instructions. A great example of pseudoinstructions is the return instruction from a function that Ken called RET. It has been called that for 30 years, but its implementation depends on the computer on which it runs. In the manuals for some computers it is called RET, but in others it can be a switch to the address that is contained in the register, or a redirect to the address in a special register, or something completely different.
Therefore, an assembler can be considered a way of recording the pseudoinstructions that the compiler generates. In the Plan 9 world, unlike most other architectures, the compiler does not start the assembler — the data is transferred directly to the linker.
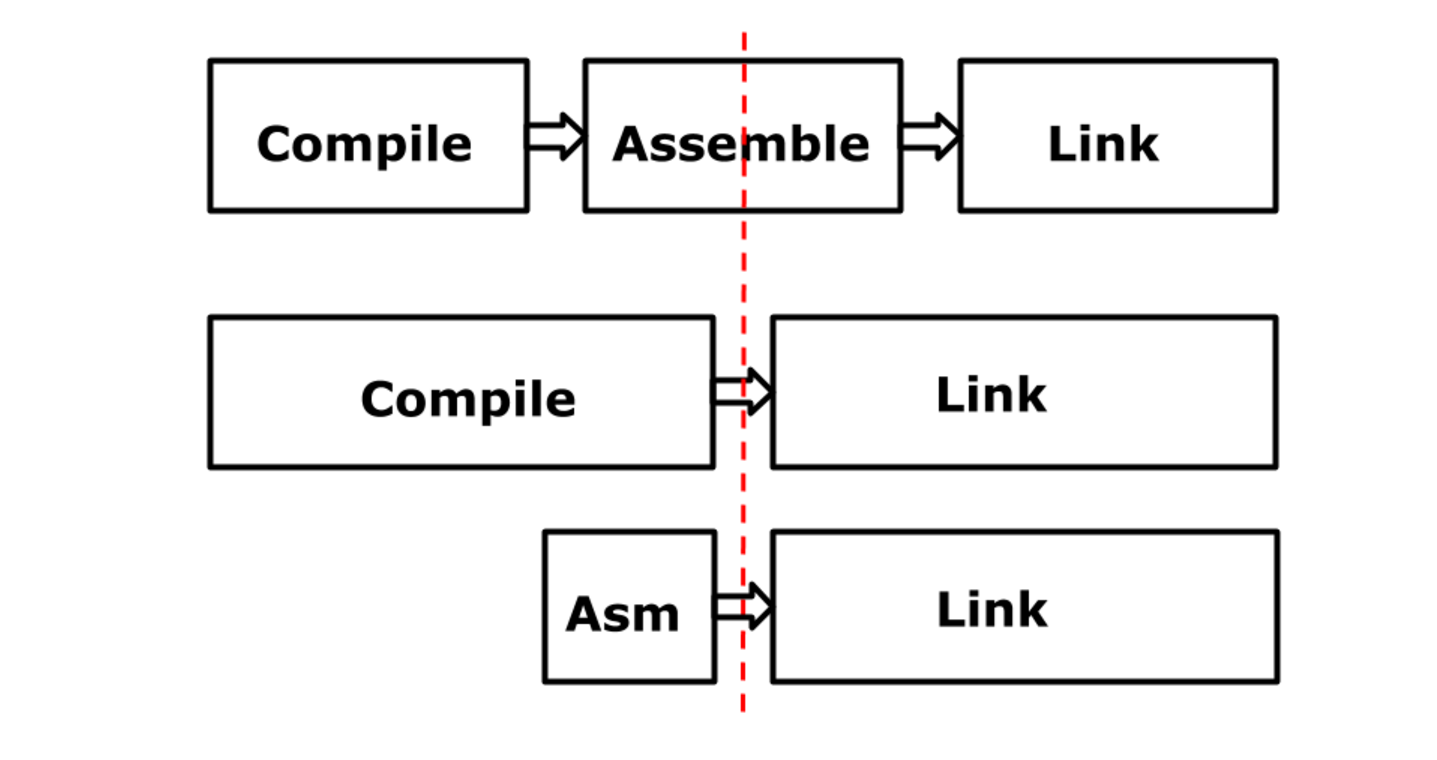
As a result, the process looks something like this. The top line roughly corresponds to traditional architectures. In my opinion, GCC works the same today. This is a compiler, it takes high-level code and converts it into assembly language code. The assembler generates real instructions, and the linker links the individual parts, creating a binary. The bottom two lines show the situation in Plan 9. Here the assembler, in fact, was divided in half: one half remained in the compiler, and the second became part of the linker. The arrows crossing the red line are flows of pseudoinstructions in binary representation. The assembler in Plan 9 serves one purpose: it provides you with the ability to write textual instructions that translate into pseudoinstructions that the linker processes.
Assembler go
This situation persisted for many generations. And the Plan 9 assemblers corresponded to it: they were separate C programs with Yacc grammar, their own for each architecture. They formed a kind of set or package, but they were separate, independently written programs. They had a common code, but not quite ... In general, everything was difficult. And then Go started appearing ... when it was ... in 2007 we started ... Go compilers were added to this heap of programs with funny names - 8g and 6g. And they used the same model. They correspond to the middle line in the diagram. And the way this division was implemented gave many advantages for the Go internal device, but today I don’t have time to tell about it in detail.

Russ Cox speaks at GopherCon 2015
In Go 1.3, we wanted to get rid of all the C code and implement everything exclusively on Go. It would take time. But in the release of Go 1.3, we launched this process. It all started with the fact that Russ ( Russ Cox ) took a large piece of linker and separated it. This is how the liblink library appeared, and most of it was occupied by the so-called instruction selection algorithm. Now this library is called obj , but then it was called liblink. The compiler used this liblink library to convert pseudoinstructions into these instructions. There were several arguments in favor of such a decision.
The most important of these is speeding up the build process. Even in spite of the fact that the compiler is now doing more work - now he chooses instructions, whereas the linker used to do this. Thanks to this device, he does this only once for each library. Previously, if you needed to package the fmt package, for example, the choice of instructions for Printf would be performed again each time. Obviously this is stupid. Now we do it once, and the linker doesn't have to do it. As a result, the compiler runs slower, but the build generally speeds up. The assembler can be arranged in the same way and can use the obj library.
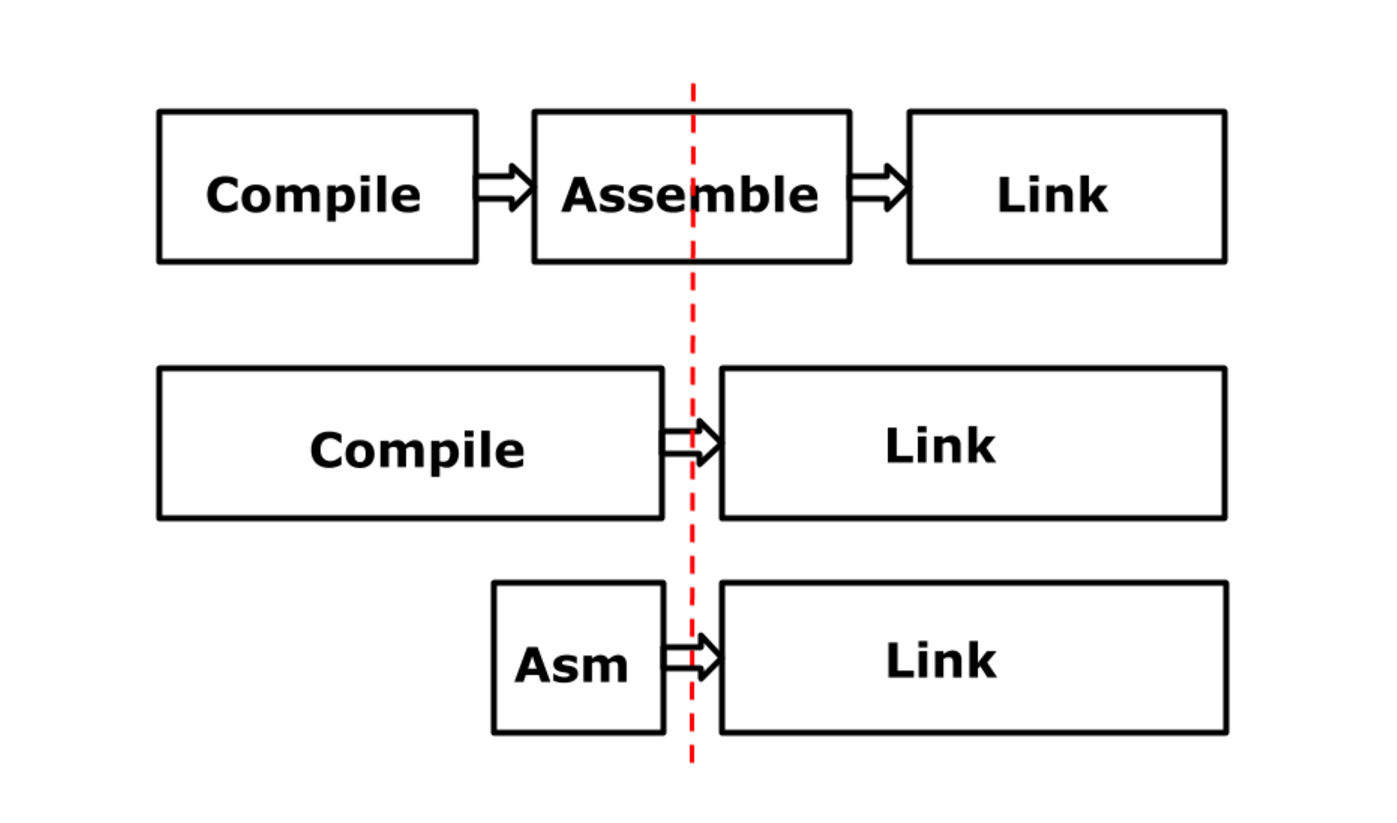
The most important feature of this stage was that nothing had changed for the user: the input language remained the same, the output remained the same, it is all the same binary file, only the details are different. Here is the general scheme of the old architecture, I have already shown it: a compiler, an assembler, a linker. In the Plan 9 world, the linker is controlled by a compiler or an assembler.
Old architecture:
New architecture:
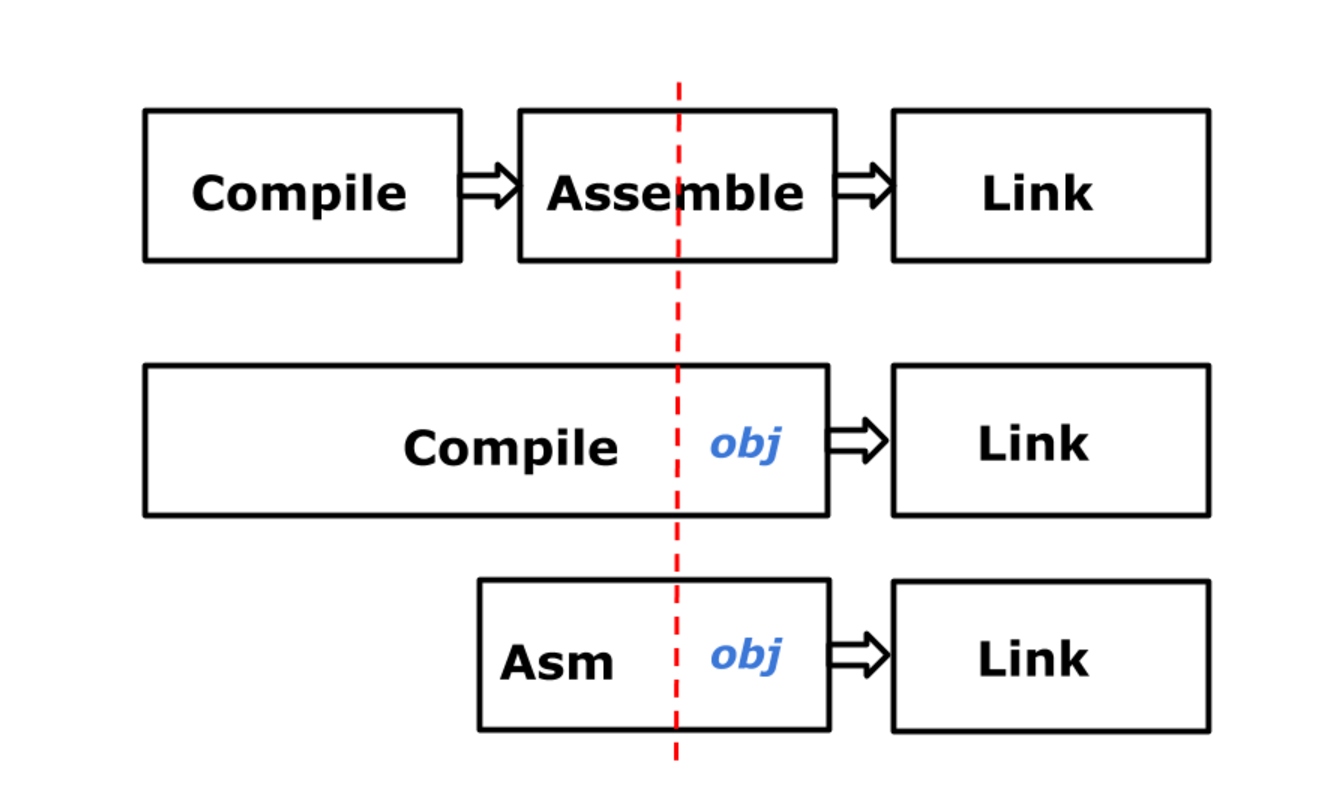
In version 1.3, we switched to such a device. As you can see, now we have a much more traditional linker: it receives real instructions, because the obj library, which performs the selection of instructions, has ceased to be part of the linker and has become the last stage of the compiler and assembler. That is, now the assembler and the compiler are more consistent with the old scheme, if you include the assembler in the process.
This new assembler Go is a weird thing. Nothing like this just exists. What is he doing? It converts textual descriptions of pseudoinstructions into real instructions for the linker. In 1.5 we made a big step - we got rid of C. For this we did a lot of preparatory work in 1.3 and 1.4, and now this problem is finally solved. Russ wrote a translator that converted the old Go source code for compilers (and, by the way, linkers) written in C into Go programs.
The old liblink library was built into the library set, which together we call obj. As a result, there is a thing called obj, this is a portable part, and subdirectories with machine-dependent parts that store information about the features of each architecture. Several papers are devoted to this work: this is an interesting story in itself. Two years ago, Russ spoke at GopherCon with a report, but it is already quite outdated. In fact, we did not do what he said then. And then at GopherFest 2015 I presented a more general, but more accurate overview of the changes in version 1.5.
GOOS=darwin GOARCH=arm go tool compile prog.go So here. Previously, compilers were called 6g, 8g and other strange names. Now this is one program called compile. You run the compile tool and set it up by setting the values of the standard GOOS environment variables (pronounced "goose" as "goose") and GOARCH (pronounced "gorch", like "drunken lustful guy in a bar") - that is how they are officially pronounced. We did the same for the linker. There is a link tool, you set the values of GOOS and GOARCH - and you can compile your program. You may ask yourself: “How can a single compiler support all of these architectures? We know that cross-platform compilation is very, very difficult. ” Not really. You just need to prepare everything in advance. Note the following: here there is only one input language - Go. From the point of view of the compiler, the result of the work is also the same - pseudoinstructions in binary form, which are transferred to the library obj. That is, we only need to set up the obj library by setting the values of the variables at the time the tool is launched. Soon you will learn how to do it.
As for the assembler, we performed machine translation of assemblers from C to Go, but this is not an ideal solution, I did not like it. I offered to write on Go from scratch the only program that would replace them all - asm. The setup would again be done exclusively through GOOS and GOARCH. You may notice that assembly language and Go are not the same thing. Each processor has its own set of instructions, its own set of registers, it is not a single output language. What to do with it? But in fact, they are essentially the same. See it.
package add func add(a, b int) int { return a + b } Here is an example of a simple program that adds two integers and returns the sum. I will not show the pseudoinstructions issued by the compiler if you use the -S flag to view the assembler code. I also removed a lot of unnecessary - if you use this method, you will also see a lot of unnecessary, but at this stage the compiler produces exactly such pseudoinstructions.
32-bit x86 (386)
TEXT add(SB), $0-12 MOVL a+4(FP), BX ADDL b+8(FP), BX MOVL BX, 12(FP) RET 64-bit x86 (amd64)
TEXT add(SB), $0-24 MOVQ b+16(FP), AX MOVQ a+8(FP), CX ADDQ CX, AX MOVQ AX, 24(FP) RET 32-bit arm
TEXT add(SB), $-4-12 MOVW a(FP), R0 MOVW b+4(FP), R1 ADD R1, R0 MOVW R0, 8(FP) RET 64-bit arm (arm64)
TEXT add(SB), $-8-24 MOVD a(FP), R0 MOVD b+8(FP), R1 ADD R1, R0 MOVD R0, 16(FP) RET S390 (s390x)
TEXT add(SB), $0-24 MOVD a(FP), R1 MOVD b+8(FP), R2 ADD R2, R1, R1 MOVD R1, 16(FP) RET Here is an option for a 32-bit architecture. Do not think about the details - just look at the whole picture . Here is the result for the x86 64-bit architecture, it is also called AMD64 , for the 32-bit ARM architecture , for the 64-bit ARM architecture, and here for the IBM System / 390 architecture; for us they are new, but for everyone else, clearly not.
64-bit MIPS (mips64)
TEXT add(SB), $-8-24 MOVV a(FP), R1 MOVV b+8(FP), R2 ADDVU R2, R1 MOVV R1, 16(FP) RET 64-bit Power (ppc64le)
TEXT add(SB), $0-24 MOVD a(FP), R2 MOVD b+8(FP), R3 ADD R3, R2 MOVD R2, 16(FP) RET Here is the code for the 64-bit MIPS architecture , here is the 64-bit POWER architecture. You may notice that they are similar. The reason is that they are essentially the same language. Partly because they are so arranged: in fact, we have used the National 32000 assembler for 30 years, changing only the iron on which it was used. But also because some of them are really identical. These are just instructions, registers, operands, constant values, labels — all the same. The only important difference is that the instructions and registers have different names. Offsets also sometimes differ, but it depends on the size of the machine word.
It all comes down to National 32000 assembler, which Ken wrote. This is the National 32000 assembly language, as Ken describes it, adapted for the modern PowerPC. Thus, we have everything we need - a common input language, the obj library in the backend - and we can write in assembler. With this approach, a problem arises: if you take the leadership of a National or PowerPC and look at assembly language, it turns out that it looks wrong. It has a different syntax, sometimes other instruction names, because at some level these are actually pseudoinstructions. In fact, it does not matter.
For an uninitiated person, the appearance of the Go assembler — all those capital letters and strange things — can seriously confuse. But since we have a common assembly language for all these computers, we can get a remarkable result, which will be discussed below. Therefore, we believe that this is a justified compromise and it is not very difficult to achieve it. It is necessary to learn how to program on 68000 and Ken assembly language - and you can automatically write programs for PowerPC. What's the difference?
How does this work? Assembler version 1.5, I think is an ideal assembler. Give him any computer - and he broadcasts an assembler for him. This is a new program written entirely on Go. It has common lexical and syntactic analyzers that simply accept your input code, everything you give it, and convert the instructions into data structures that describe the instructions in binary form, and then transfer the result to the new library obj, which contains information about specific platforms .
Most of the code that underlies the assembler is fully portable, it contains nothing, no interesting information about the architectures, but there is a table with information about the names of the registers. There are still a few things that are related to the operation of the operands, but there it is quite simple. And all this is configured when you start the program in accordance with the value of the variable GOARCH. GOOS is used in very, very rare cases in which we will not go deep - the main characteristics are determined by GOARCH. There is also an internal package for the assembler, which is called arch, it creates these tables on the fly, dynamically retrieving them from the obj library. And here is a fragment of this code.
import ( "cmd/internal/obj" "cmd/internal/obj/x86" ) func archX86(linkArch *obj.LinkArch) *Arch { register := make(map[string]int16) // Create maps for easy lookup of instruction names etc. for i, s := range x86.Register { register[s] = int16(i + x86.REG_AL) } instructions := make(map[string]obj.As) for i, s := range obj.Anames { instructions[s] = x86.As(i) } return &Arch{ Instructions: instructions, Register: register, ... } } It is a bit simplified, but the essence conveys. This is an arch, internal assembler package. This is the procedure that configures the entire assembler for the x86 architecture. This code is used in both 32- and 64-bit architecture, they are identical from this point of view. And then we just start the loop ... A loop that goes through the register names from the obj library defined in the x86 package for the obj procedures. And we just set up a map that matches the names of the registers and the binary code according to the data from obj. And then do the same for instructions.
These codes are not actually instruction codes; you will not find them in the manual. This is literally an alphabetical list of all things - I repeat that these are just pseudoinstructions, and not real commands. But now we know all the names of all the registers and all the instructions. And the description of the architecture, which we will return, contains only these two maps. Here are the names of the instructions that you know, here are the names of the registers that you know, and a few more things that I did not mention, but everything is pretty simple. This is all the necessary information to convert the assembly language into instructions for these computers. , , . 1, , , . It is quite simple.
ADDW AX, BX &obj.Prog{ As: arch.Instructions["ADDW"], From: obj.Addr{Reg: arch.Register["AX"]}, To: obj.Addr{Reg: arch.Register["BX"]}, ... } . « » (ADDW) 386, . : ADDW AX, BX. , . , , — , , ADDW . A — , . , . — AX, BX. , , : , , obj. , . , , — . .
, , . . , , , … , , , . It's not a problem.
, obj. : , , obj, , , obj , . , obj , . .
, , , , . . , , , … obj , , . , , , . . , , . , -, . A/B- — . .
386, – AMD64. , . , PowerPC, – . , , , . , obj, .
-, . , Go, Yacc. , . . Go, , . , , , . , . , . . . . .
, , , , , open-source-. Git , , , , , . It's great. -, . , open-source- .
, , , , obj . ? . , , … — , pprof, — -, , , , , . , PDF , . , , — ? . , . . , .
— , . . . . , , . , PDF , – . .
, , , , .
Conclusion
. , , . , . , , . , , . , . — , . — , — . , , , .
Go. Thank.
Source: https://habr.com/ru/post/317864/
All Articles