How we ran Deep Learning
Habr, hello.
As you know, for learning deep neural networks it is best to use machines with a GPU. Our educational programs always have a practical bias, so for us it was imperative that during training each participant had his own virtual machine with a GPU on which he could solve problems during classes, as well as laboratory work during the week. How we chose the infrastructure partner for the implementation of our plans and prepared the environment for our participants will be discussed in our post.
We had plans to launch an educational program for Deep Learning from the beginning of this year, but we switched to the direct program design in August. At about the same time, Microsoft Azure announced that GPU virtuals appeared in their preview format on their platform . For us, this was good news, because on our main program for large data, Microsoft is an infrastructure partner. There was an idea not to produce a zoo, and at the end of November just use their ready-made solution (not a preview). In mid-November, it became clear that Microsoft is not in a hurry to exit the preview and make GPUs available within its cloud ecosystem. We are faced with the fact that we need to urgently look for something else.
A little later, we were able to fairly quickly agree on cooperation in this area with the cloud platform based on IBM Bluemix Infrastructure (formerly Softlayer), and IBM became our infrastructure partner for this program. Alas, it was not without pitfalls. We are the first time, on the go, acquainted with the capabilities of IBM Bluemix. Initially, we expected that we would get ready virtual machines with a GPU for each of the participants. But since Bluemix GPUs are only available in Bare-metal servers (dedicated physical servers), which you can order as a designer in the right configuration and get in a few hours, we ended up with a powerful physical server on the Supermicro platform with two Intel Xeon E5 processors -2690v3, 128 GB of memory and two NVIDIA Tesla M60 cards (each card has 2 GM204GL Maxwell generation chips and 16 GB of video memory), which can be pre-installed with a hypervisor (VMware, Xen or Hyper-V), which is also very not bad! We needed only to break this nimble iron into the necessary number of virtual locks and that's all. Only now we have not planned this stage from the very beginning. This is where the main problem arose, which we solved for quite some time.
')
For practical work, participants in our program required virtual machines with GPUs supporting NVIDIA CUDA and a GNU / Linux-based OS (we most often use Ubuntu 14.04 LTS for our tasks, as easy to use and fairly simple distribution with good community support). Accordingly, first of all, it was necessary to choose a virtualization platform that would support either “passthrough” video cards to the Linux guest system, or (more interestingly) virtual GPU support for the guest OS.
First of all, we decided to consider VMware Vsphere 6 as one of the leading solutions in this market. Fortunately, installation of this hypervisor and all required licenses are available directly from the IBM SoftLayer control panel, that is, installation of the hypervisor is carried out in just a few mouse clicks (do not forget that we work with a dedicated server). VMware claims support for the GRID Virtual GPU technology (vGPU), that is, it is possible to split a single video adapter core into several virtual ones and connect such a GPU to a guest system. In sufficient detail, everything is described in the corresponding document from NVidia. This technology is mostly focused on use in VDI solutions, where 3D graphics acceleration is required for Windows-based guest systems, which in our case is not very suitable. If you study the document from NVidia in more detail, you can find out that when using vGPU there is a concept of vGPU profiles, that is, in fact, by how many vGPU can you divide one core of a video accelerator. The vGPU profile sets the allocated amount of video memory, the maximum number of displays supported, and so on. Thus, using different profiles you can break the NVidia Tesla M60 into a number of virtual machines from 1 to 32. Interesting.
BUT! If you read the document in more detail, you may find that CUDA support on Linux guest systems is available only with the GRID M60-8Q profile, which in essence is just a forwarding of one of the Tesla M60 GPU chips (recall that the Tesla M60 consists of 2 x chips) in one virtual machine. As a result, in any case, having 2 Tesla M60 cards for working with CUDA, you can get a maximum of 4 virtual locks for the Linux guest OS.
Separately, it is worth mentioning that in order to work with vGPU, additional licensing from NVidia (the basics here ) is required and to obtain drivers for the hypervisor and guest systems, you need to obtain these licenses. Also, drivers in the guest systems require an NVidia license server, which must be installed independently, and only Windows operating systems are supported. In addition, vGPU is supported only on the Vsphere 6 Enterprise Plus release, which we have just used.
As a result, it was decided to abandon the vGPU and simply “forward” the video card into the guest systems, so you can get 4 virtual machines, each of which will have one Tesla M60 chip with 8 GB of video memory. vSphere supports PCI-Passthrough, respectively, there should be no problems, but they appeared.
Tesla cards have been configured to passthrough into virtual machines. A PCI device was added to one of the machines, but the error “PCI passthrough device id invalid” appeared when the machine was started, it turned out that this problem manifests itself only in the vSphere web interface, if you use the Windows client and add the device again, this problem does not arise, but there is another, more general, something like “starting VM ... general error”. Having a little studying an error origin, we tried various options:
But all in vain. PCI Passthrough did not work for us. Given that time was less and less, we decided to stop our research and try Citrix XenServer. This hypervisor is widely used for VDI solutions. The good thing is that from the SoftLayer control panel you can launch the hypervisor reinstallation and select XenServer by one mouse click. It should be noted that its automated installation and configuration took a decent amount of time from the Bluemix platform (about 8 hours in our case). So it is important to set the necessary time for this procedure. Then this story was quite boring, it all worked almost immediately out of the box. In this case, the same option was available with the Passthrough mode. Each of the 4 GM204GL chips from the two Testa M60 adapters was forwarded to a separate virtual machine, set up a virtual network, installed the standard NVidia drivers for the Tesla M60 for Linux, and it all started. To configure XenServer, it is convenient to use Citrix XenCenter, here’s what the projected video cards look like in its GUI:

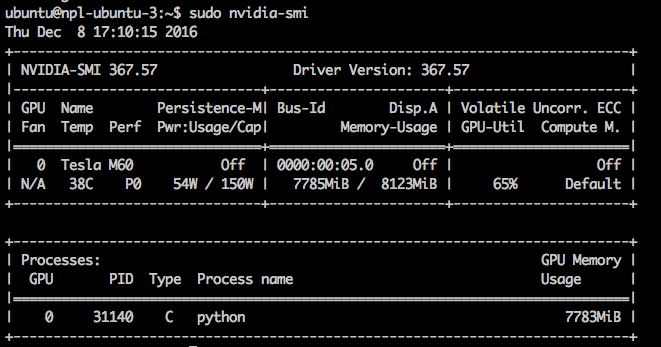
This is how, using the nvidia-smi utility, the administrator can see that the python process (the participants used the Keras and Caffe libraries) uses most of the GPU memory.
In connection with all these unscheduled surveys, we managed to cut the virtual machines working as it should be only to the last of the days of our program. As a result, the guys worked on the g2.2xlarge instances of the AWS platform for a week, because we could not afford to be left without the necessary equipment, and the IBM Bluemix virtualka decided to give participants another week after the end of the program as a bonus, so that they could still solve with deep learning.
We decided to compare which of the solutions is more efficient in terms of performance and cost of maintaining the park.
Let us calculate how much, for example, both options will cost, provided that the infrastructure is used for two weeks, with 16 participants. Our use case is not quite standard, because we wanted to give each member a separate virtual machine.
AWS: $ 0.65 * 24h * 15 days * 16 participants = $ 3,744
IBM Bluemix: $ 2961.1 / month / 2 (2 weeks) * 4 = $ 5,922.2 (server with 2xM60) configuration link
Or if you take an equivalent closer to g2.2xlarge:
$ 2096.40 / month / 2 (2 weeks) * 4 = $ 4192.8 (server with 2xK2 (GK104) GPU - AWS analog) configuration link
In our version, the difference in money turns out to be substantial - almost $ 2,000. Using a more modern GPU, but the performance in the second case is higher:
AWS: 1gpu, 8cores, 15gb ram (GK 104 based on GRID K520)
IBM: 1 gpu, 12 cores, 32gb ram (GM 204 based on M60)
More cores, more memory, a more modern next-generation GPU, and the performance itself is even higher. We conducted a small benchmark, having trained the LeNet network, which recognizes handwritten numbers, with the help of Caffe for 10 thousand iterations. It took 45.5 seconds on the AWS virtual machine, 26.73 seconds on the IBM virtual machine, that is, 1.7 times faster. Over a longer period of time, this may be more significant: 24 hours versus 14 hours. Or in two weeks it would save 6 days, which could be spent on learning something else.
Colleagues from IBM shared another use case - video streaming. AWS used the same 16 g2.2xlarge machines, and at IBM only one 2xM-60 server for Windows guest VMs. By performance, they were comparable, serving the same number of video streams. For the same 2 weeks, the IBM expense will amount to $ 1,422.72, which is cheaper by more than $ 2,000 configuration in AWS. So depending on your needs, this or that configuration may be more profitable for you. Also, colleagues from IBM hinted that they could provide more favorable conditions, even when renting one such server, in AWS, discounts are applied automatically only with a significant consumption of services for tens of thousands of $.
It is also important to note that only Maxwell GPUs are currently available only on the Bluemix platform. At the time of writing the post they did not have analogues in other public cloud platforms. If anything, a direct link to the configurator is here.
In our comparison, we do not touch upon the theme of comparing a platform with a platform, since These services are a completely different approach. IBM Bluemix focuses more on providing infrastructure services (Softlayer) and at the same time offers PaaS Bluemix services to its clients (Analytics, big data, virtual containers, etc.). AWS focuses on virtual services and PaaS, the KVM hypervisor is taken as the basis, and Azure in turn focuses on the entire Microsoft stack.
Obviously, it’s not fair to compare head-to-head prices of certain solutions from different providers, you need to understand what you get for this price! For example, if you go into details and study the documentation, it turns out that AWS and Azure charge you a client for each call to technical support, IBM Bluemix does not. If your services are located in different geographically separated data centers, in the case of Azure and AWS, the customer pays for traffic within the data center network, while in IBM Bluemix, the traffic within the network is free for customers, etc. You can still find all sorts of nuances in the functional, practical, and legal plane. In our opinion, if you need the most personalized solution, and we are talking about significant workloads, then the choice of Bluemix is optimal, because you completely administer and manage resources and any service is transparent, at the same time if you need several workstations as ready for use as possible (require minimal administration) and performance is not critical for you, then Azure and AWS are perfect for you.
The result is that despite all the difficulties that we experienced, the first launch of the Deep Learning program can be considered successful. According to the results of our survey, we obtained the following results:
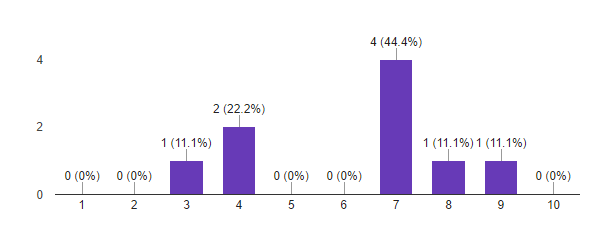
1. How much did your expectations for the course coincide with reality?
On a scale from 1 to 10: 1 - the expectations were not fully met, 10 - the course exceeded all my expectations.

2. What is the main result you got from the program?

3. How do you plan to apply the acquired knowledge and skills?

4. How did you like the format of the program: 2 full-time days with laboratory work?
5. How likely is it that you would recommend this program to your friends?
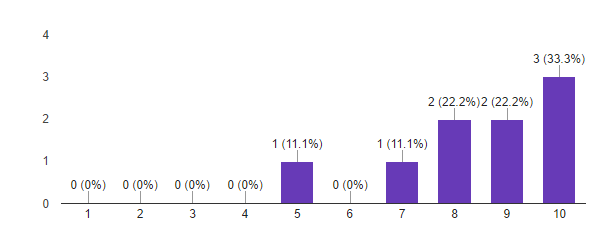
Based on this data, we consider the first launch of the Deep Learning program to be successful. Important metrics for us show that the participants are mostly satisfied with the result and are ready to recommend the program to their friends. It seems that we are not very hit with the format. We made conclusions on the pilot launch, and we will modify it to the next set . There are ideas!
As you know, for learning deep neural networks it is best to use machines with a GPU. Our educational programs always have a practical bias, so for us it was imperative that during training each participant had his own virtual machine with a GPU on which he could solve problems during classes, as well as laboratory work during the week. How we chose the infrastructure partner for the implementation of our plans and prepared the environment for our participants will be discussed in our post.
Microsoft Azure N-series
We had plans to launch an educational program for Deep Learning from the beginning of this year, but we switched to the direct program design in August. At about the same time, Microsoft Azure announced that GPU virtuals appeared in their preview format on their platform . For us, this was good news, because on our main program for large data, Microsoft is an infrastructure partner. There was an idea not to produce a zoo, and at the end of November just use their ready-made solution (not a preview). In mid-November, it became clear that Microsoft is not in a hurry to exit the preview and make GPUs available within its cloud ecosystem. We are faced with the fact that we need to urgently look for something else.
Ibm bluemix
A little later, we were able to fairly quickly agree on cooperation in this area with the cloud platform based on IBM Bluemix Infrastructure (formerly Softlayer), and IBM became our infrastructure partner for this program. Alas, it was not without pitfalls. We are the first time, on the go, acquainted with the capabilities of IBM Bluemix. Initially, we expected that we would get ready virtual machines with a GPU for each of the participants. But since Bluemix GPUs are only available in Bare-metal servers (dedicated physical servers), which you can order as a designer in the right configuration and get in a few hours, we ended up with a powerful physical server on the Supermicro platform with two Intel Xeon E5 processors -2690v3, 128 GB of memory and two NVIDIA Tesla M60 cards (each card has 2 GM204GL Maxwell generation chips and 16 GB of video memory), which can be pre-installed with a hypervisor (VMware, Xen or Hyper-V), which is also very not bad! We needed only to break this nimble iron into the necessary number of virtual locks and that's all. Only now we have not planned this stage from the very beginning. This is where the main problem arose, which we solved for quite some time.
')
For practical work, participants in our program required virtual machines with GPUs supporting NVIDIA CUDA and a GNU / Linux-based OS (we most often use Ubuntu 14.04 LTS for our tasks, as easy to use and fairly simple distribution with good community support). Accordingly, first of all, it was necessary to choose a virtualization platform that would support either “passthrough” video cards to the Linux guest system, or (more interestingly) virtual GPU support for the guest OS.
First of all, we decided to consider VMware Vsphere 6 as one of the leading solutions in this market. Fortunately, installation of this hypervisor and all required licenses are available directly from the IBM SoftLayer control panel, that is, installation of the hypervisor is carried out in just a few mouse clicks (do not forget that we work with a dedicated server). VMware claims support for the GRID Virtual GPU technology (vGPU), that is, it is possible to split a single video adapter core into several virtual ones and connect such a GPU to a guest system. In sufficient detail, everything is described in the corresponding document from NVidia. This technology is mostly focused on use in VDI solutions, where 3D graphics acceleration is required for Windows-based guest systems, which in our case is not very suitable. If you study the document from NVidia in more detail, you can find out that when using vGPU there is a concept of vGPU profiles, that is, in fact, by how many vGPU can you divide one core of a video accelerator. The vGPU profile sets the allocated amount of video memory, the maximum number of displays supported, and so on. Thus, using different profiles you can break the NVidia Tesla M60 into a number of virtual machines from 1 to 32. Interesting.
BUT! If you read the document in more detail, you may find that CUDA support on Linux guest systems is available only with the GRID M60-8Q profile, which in essence is just a forwarding of one of the Tesla M60 GPU chips (recall that the Tesla M60 consists of 2 x chips) in one virtual machine. As a result, in any case, having 2 Tesla M60 cards for working with CUDA, you can get a maximum of 4 virtual locks for the Linux guest OS.
Separately, it is worth mentioning that in order to work with vGPU, additional licensing from NVidia (the basics here ) is required and to obtain drivers for the hypervisor and guest systems, you need to obtain these licenses. Also, drivers in the guest systems require an NVidia license server, which must be installed independently, and only Windows operating systems are supported. In addition, vGPU is supported only on the Vsphere 6 Enterprise Plus release, which we have just used.
As a result, it was decided to abandon the vGPU and simply “forward” the video card into the guest systems, so you can get 4 virtual machines, each of which will have one Tesla M60 chip with 8 GB of video memory. vSphere supports PCI-Passthrough, respectively, there should be no problems, but they appeared.
Tesla cards have been configured to passthrough into virtual machines. A PCI device was added to one of the machines, but the error “PCI passthrough device id invalid” appeared when the machine was started, it turned out that this problem manifests itself only in the vSphere web interface, if you use the Windows client and add the device again, this problem does not arise, but there is another, more general, something like “starting VM ... general error”. Having a little studying an error origin, we tried various options:
- Checked whether VT-in is on
- Is IOMMU enabled
- Tried to add to the .vmx file:
-firmware = "efi"
-pciPassthru.use64bitMMIO = "TRUE"
-efi.legacyBoot.enabled = "TRUE"
-efi.bootOrder = "legacy"
But all in vain. PCI Passthrough did not work for us. Given that time was less and less, we decided to stop our research and try Citrix XenServer. This hypervisor is widely used for VDI solutions. The good thing is that from the SoftLayer control panel you can launch the hypervisor reinstallation and select XenServer by one mouse click. It should be noted that its automated installation and configuration took a decent amount of time from the Bluemix platform (about 8 hours in our case). So it is important to set the necessary time for this procedure. Then this story was quite boring, it all worked almost immediately out of the box. In this case, the same option was available with the Passthrough mode. Each of the 4 GM204GL chips from the two Testa M60 adapters was forwarded to a separate virtual machine, set up a virtual network, installed the standard NVidia drivers for the Tesla M60 for Linux, and it all started. To configure XenServer, it is convenient to use Citrix XenCenter, here’s what the projected video cards look like in its GUI:
This is how, using the nvidia-smi utility, the administrator can see that the python process (the participants used the Keras and Caffe libraries) uses most of the GPU memory.
In connection with all these unscheduled surveys, we managed to cut the virtual machines working as it should be only to the last of the days of our program. As a result, the guys worked on the g2.2xlarge instances of the AWS platform for a week, because we could not afford to be left without the necessary equipment, and the IBM Bluemix virtualka decided to give participants another week after the end of the program as a bonus, so that they could still solve with deep learning.
AWS vs. IBM Bluemix Comparison
We decided to compare which of the solutions is more efficient in terms of performance and cost of maintaining the park.
Let us calculate how much, for example, both options will cost, provided that the infrastructure is used for two weeks, with 16 participants. Our use case is not quite standard, because we wanted to give each member a separate virtual machine.
AWS: $ 0.65 * 24h * 15 days * 16 participants = $ 3,744
IBM Bluemix: $ 2961.1 / month / 2 (2 weeks) * 4 = $ 5,922.2 (server with 2xM60) configuration link
Or if you take an equivalent closer to g2.2xlarge:
$ 2096.40 / month / 2 (2 weeks) * 4 = $ 4192.8 (server with 2xK2 (GK104) GPU - AWS analog) configuration link
In our version, the difference in money turns out to be substantial - almost $ 2,000. Using a more modern GPU, but the performance in the second case is higher:
AWS: 1gpu, 8cores, 15gb ram (GK 104 based on GRID K520)
IBM: 1 gpu, 12 cores, 32gb ram (GM 204 based on M60)
More cores, more memory, a more modern next-generation GPU, and the performance itself is even higher. We conducted a small benchmark, having trained the LeNet network, which recognizes handwritten numbers, with the help of Caffe for 10 thousand iterations. It took 45.5 seconds on the AWS virtual machine, 26.73 seconds on the IBM virtual machine, that is, 1.7 times faster. Over a longer period of time, this may be more significant: 24 hours versus 14 hours. Or in two weeks it would save 6 days, which could be spent on learning something else.
Colleagues from IBM shared another use case - video streaming. AWS used the same 16 g2.2xlarge machines, and at IBM only one 2xM-60 server for Windows guest VMs. By performance, they were comparable, serving the same number of video streams. For the same 2 weeks, the IBM expense will amount to $ 1,422.72, which is cheaper by more than $ 2,000 configuration in AWS. So depending on your needs, this or that configuration may be more profitable for you. Also, colleagues from IBM hinted that they could provide more favorable conditions, even when renting one such server, in AWS, discounts are applied automatically only with a significant consumption of services for tens of thousands of $.
It is also important to note that only Maxwell GPUs are currently available only on the Bluemix platform. At the time of writing the post they did not have analogues in other public cloud platforms. If anything, a direct link to the configurator is here.
In our comparison, we do not touch upon the theme of comparing a platform with a platform, since These services are a completely different approach. IBM Bluemix focuses more on providing infrastructure services (Softlayer) and at the same time offers PaaS Bluemix services to its clients (Analytics, big data, virtual containers, etc.). AWS focuses on virtual services and PaaS, the KVM hypervisor is taken as the basis, and Azure in turn focuses on the entire Microsoft stack.
Obviously, it’s not fair to compare head-to-head prices of certain solutions from different providers, you need to understand what you get for this price! For example, if you go into details and study the documentation, it turns out that AWS and Azure charge you a client for each call to technical support, IBM Bluemix does not. If your services are located in different geographically separated data centers, in the case of Azure and AWS, the customer pays for traffic within the data center network, while in IBM Bluemix, the traffic within the network is free for customers, etc. You can still find all sorts of nuances in the functional, practical, and legal plane. In our opinion, if you need the most personalized solution, and we are talking about significant workloads, then the choice of Bluemix is optimal, because you completely administer and manage resources and any service is transparent, at the same time if you need several workstations as ready for use as possible (require minimal administration) and performance is not critical for you, then Azure and AWS are perfect for you.
Result
The result is that despite all the difficulties that we experienced, the first launch of the Deep Learning program can be considered successful. According to the results of our survey, we obtained the following results:
1. How much did your expectations for the course coincide with reality?
On a scale from 1 to 10: 1 - the expectations were not fully met, 10 - the course exceeded all my expectations.
2. What is the main result you got from the program?
3. How do you plan to apply the acquired knowledge and skills?
4. How did you like the format of the program: 2 full-time days with laboratory work?
5. How likely is it that you would recommend this program to your friends?
Based on this data, we consider the first launch of the Deep Learning program to be successful. Important metrics for us show that the participants are mostly satisfied with the result and are ready to recommend the program to their friends. It seems that we are not very hit with the format. We made conclusions on the pilot launch, and we will modify it to the next set . There are ideas!
Source: https://habr.com/ru/post/317766/
All Articles