Chatbot on the basis of a recurrent neural network do-it-yourself for 1 evening / $ 6 and ~ 100 lines of code
In this article I want to show how easy it is today to use neural networks. Around me, quite a few people are obsessed with the idea that only a researcher can use neurons. And in order to get at least some exhaust, you need to have at least a Ph.D. And let's take a real example to see how it really is, to take a chatbot from scratch in one evening. Yes, not just anyhow than the most that the tube TensorFlow . At the same time, I tried to describe everything so simply that it would be understandable even to a novice programmer! Let's hit the road!

Special thanks to my patrons who made this article possible:
Aleksandr Shepeliev, Sergei Ten, Alexey Polietaiev, Nikita Penzin, Karnaukhov Andrey, Matveev Evgeny, Anton Potemkin. You too can be one of them here .
TensorFlow includes an implementation of the RNN (Recurrent Neural Network), which is used to train the translation model for English / French language pairs . It is this implementation that we will use to train our chat bot.
')
Probably, someone might ask: “Why the hell are we looking at learning the translation model, if we do a chat bot?”. But this may seem strange only at the first stage. Think for a second what is a “translation”? Translation can be presented as a process in two stages:
Now think about it, but what if we train the same RNN model, but instead of Eng / Fre couples, we will substitute Eng / Eng dialogs from movies? In theory, we can get a chat bot that is able to answer simple single-line questions (without the ability to memorize the context of the dialogue). This should be quite sufficient for our first bot. Plus, this approach is very simple. Well, in the future, we can, starting from our first implementation, make the chat bot more reasonable.
Later we will learn how to train more complex networks that are more suitable for chat bots (for example retrieval-based models ).
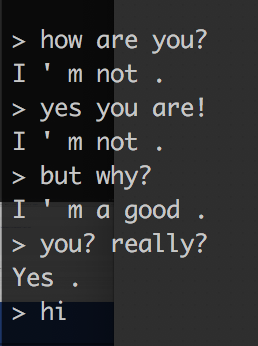
For the impatient: the picture at the beginning of the article is actually an example of a conversation with a bot after only 50 thousand educational iterations. As you can see, the bot is able to give more or less informative answers to some questions. The quality of the bot improves with the number of iterations of training. For example, here’s how stupid he answered after the first 200 iterations:
This simple approach also allows us to create bots with different characters. For example, it would be possible to teach him on the dialogues from the saga “Star Wars” or “Lord of the Rings”. Moreover, if a bot has a sufficiently large corpus of dialogue of the same hero (for example, all the Chandler dialogues from the film “Friends”), then you can create a bot of this hero.
To train our first bot, we will use the corpus of conversations from the movies “ Cornell Movie Dialogs Corpus ”. To use it, we need to convert the dialogues into the type necessary for learning. For this, I prepared a small script .
I would strongly recommend that you read the README file in order to understand more about the corpus and what this script does, and only then continue reading the article. However, if you just need commands that you can blindly copy and execute to get the data ready for learning, here they are:
By the end of the run, you will have 2 files that you can use for further study: train.a and train.b
This is the most exciting part. In order to train the model, we must:
In search of
In order to make this process as simple as possible, I will use the compiled AMI - “ Bitfusion TensorFlow AMI ”, which will be used with AWS. It has a pre-installed TensorFlow, which was compiled with GPU support. At the time of writing, Bitfusion AMI included TensorFlow version 0.11.
The process of creating an EC2 instance from an AMI image is fairly simple and is beyond the scope of this article. However, it is worth paying attention to two important details that are related to the process: the type of the instance and the size of the SSD. For the type I would recommend to use: p2.xlarge is the cheapest type that has an NVIDIA GPU with enough video memory (12 Gbps). As for the size of the SSD - I would recommend allocating at least 100GB.
At this stage, I hope I can assume that you have ssh access to the machine where you will train TensorFlow.
First, let's discuss why we need to modify the source script at all. The fact is that the script itself does not allow overriding the source of data that is used to train the model. To fix this, I created a feature-request . And I will try to prepare the implementation soon, but at the moment, you can participate by adding +1 to the “request”.
In any case, do not be afraid - the modification is very simple . But even such a small modification I have already done for you and created a repository containing the modified code . It remains only to do the following:
Rename the files “train.a” and “train.b” to “train.en” and “train.fr”, respectively. This is necessary because the training script still believes that he is learning to translate from English to French.
Both files must be uploaded to remote hosts — this can be done using the rsync command:
Now let's connect to a remote host and start a tmux session. If you don’t know what tmux is, you can simply connect via SSH:
Let's check that TensorFlow is installed and it uses the GPU:
As you can see, TF version 0.11 is installed and it uses the CUDA library. Now let's bow the training script:
Note that we need the r0.11 branch. First of all, this thread is consistent with the version of the locally installed TensorFlow. Secondly, I did not transfer my changes to other branches, therefore, if necessary, I will have to do this with your own hands.
Congratulations! You have reached the stage of learning. Feel free to run this very training:
Let's discuss some of the keys that we use:
You have successfully started learning. But let's confirm that the process continues and everything is in order. We don’t want to find out after 6 hours that something was done wrong at the very beginning. Gleb and I have already somehow taught something half-sensible =)
First of all, we can confirm that the learning process “bit off” the memory of the GPU:
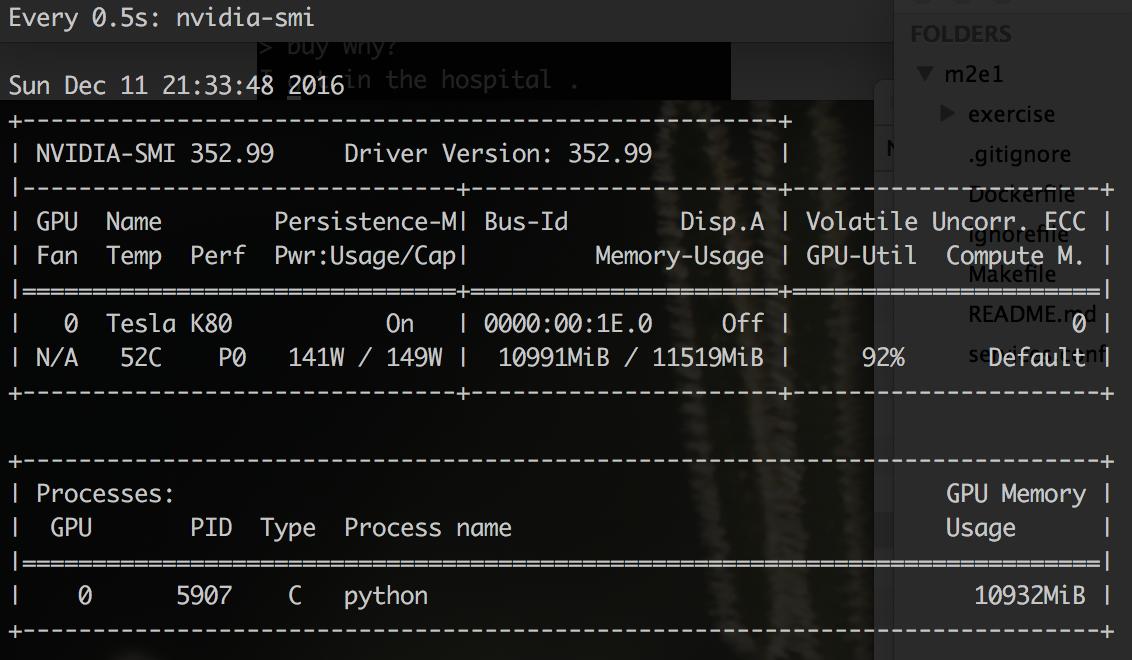
As you can see, I didn’t get sick so much, almost all the memory on the GPU is occupied. This is a good sign. And do not be afraid that your process is about to “kick back” with an OutOfMemory error. Just during the launch of TF, it takes up all the memory on the GPU that it can reach.
Then you can check the folder “train” - it should contain several new files:
Here it is important to look into the files vocab4000. * And train.ids40000. *. There should be atmospheric and soulful, look here:
Each line in the file is a unique word that was found in the source data. Each word in the source data will be replaced by a number that represents the line number from this file. You can immediately notice that there are some technical words: PAD (0), GO (1), EOS (2), UNK (3). Probably the most important of them for us is “UNK”, since the number of words marked with this code (3) will give us some idea of how correctly we choose the size of our dictionary.
Now let's look at train.ids40000.en:
I think you already guessed that this is data from input.en, but with all the words replaced with codes according to the dictionary. Now we can check how many words are marked as “unknowns” (UNK / 3):
You can try in subsequent experiments to increase the size of the dictionary from 40k to 45k, or even up to 50k. But, we will continue the “as is” process and will not interrupt it.
After waiting enough time, you can stupidly kill the learning process. Do not worry, the process saves the result every 200 steps of training (this number can be changed). I would recommend for training either to choose the period of time that you are willing to wait (it may depend on the amount you are willing to pay for the rental car), or the number of steps that you want the training process to complete.
The last and most important thing for which we arranged this whole mess - this is to start a chat. To do this, we just need to add one key to the team that was used for training:
To help a project or simply create a bot with character, you can:
The steps to go on our thorny path
- It is necessary to find an implementation of a neuronny network that can be used for our purpose.
- Prepare data (corpus) that can be used for training.
- To train a model.
Special thanks to my patrons who made this article possible:
Aleksandr Shepeliev, Sergei Ten, Alexey Polietaiev, Nikita Penzin, Karnaukhov Andrey, Matveev Evgeny, Anton Potemkin. You too can be one of them here .
A neuron implementation that can be used for our purpose.
TensorFlow includes an implementation of the RNN (Recurrent Neural Network), which is used to train the translation model for English / French language pairs . It is this implementation that we will use to train our chat bot.
')
Probably, someone might ask: “Why the hell are we looking at learning the translation model, if we do a chat bot?”. But this may seem strange only at the first stage. Think for a second what is a “translation”? Translation can be presented as a process in two stages:
- Create a language-independent representation of the incoming message.
- Displaying the information received in the first step in the target language.
Now think about it, but what if we train the same RNN model, but instead of Eng / Fre couples, we will substitute Eng / Eng dialogs from movies? In theory, we can get a chat bot that is able to answer simple single-line questions (without the ability to memorize the context of the dialogue). This should be quite sufficient for our first bot. Plus, this approach is very simple. Well, in the future, we can, starting from our first implementation, make the chat bot more reasonable.
Later we will learn how to train more complex networks that are more suitable for chat bots (for example retrieval-based models ).
For the impatient: the picture at the beginning of the article is actually an example of a conversation with a bot after only 50 thousand educational iterations. As you can see, the bot is able to give more or less informative answers to some questions. The quality of the bot improves with the number of iterations of training. For example, here’s how stupid he answered after the first 200 iterations:
This simple approach also allows us to create bots with different characters. For example, it would be possible to teach him on the dialogues from the saga “Star Wars” or “Lord of the Rings”. Moreover, if a bot has a sufficiently large corpus of dialogue of the same hero (for example, all the Chandler dialogues from the film “Friends”), then you can create a bot of this hero.
Data preparation (corpus) for training
To train our first bot, we will use the corpus of conversations from the movies “ Cornell Movie Dialogs Corpus ”. To use it, we need to convert the dialogues into the type necessary for learning. For this, I prepared a small script .
I would strongly recommend that you read the README file in order to understand more about the corpus and what this script does, and only then continue reading the article. However, if you just need commands that you can blindly copy and execute to get the data ready for learning, here they are:
tmp# git clone https://github.com/b0noI/dialog_converter.git Cloning into 'dialog_converter'… remote: Counting objects: 59, done. remote: Compressing objects: 100% (49/49), done. remote: Total 59 (delta 33), reused 20 (delta 9), pack-reused 0 Unpacking objects: 100% (59/59), done. Checking connectivity… done. tmp# cd dialog_converter dialog_converter git:(master)# python converter.py dialog_converter git:(master)# ls LICENSE README.md converter.py movie_lines.txt train.a train.b By the end of the run, you will have 2 files that you can use for further study: train.a and train.b
Model training
This is the most exciting part. In order to train the model, we must:
- Find a machine with a powerful and supported TensorFlow (which is very important) video card (read: NVIDIA).
- Modify the original “translate” script, which is used to train the Eng / Fre. Translation model.
- Prepare the machine for training.
- Start learning.
- Wait.
- Wait.
- Wait.
- I'm serious ... You have to wait.
- Profit.
In search of Atlantis learning machines
In order to make this process as simple as possible, I will use the compiled AMI - “ Bitfusion TensorFlow AMI ”, which will be used with AWS. It has a pre-installed TensorFlow, which was compiled with GPU support. At the time of writing, Bitfusion AMI included TensorFlow version 0.11.
The process of creating an EC2 instance from an AMI image is fairly simple and is beyond the scope of this article. However, it is worth paying attention to two important details that are related to the process: the type of the instance and the size of the SSD. For the type I would recommend to use: p2.xlarge is the cheapest type that has an NVIDIA GPU with enough video memory (12 Gbps). As for the size of the SSD - I would recommend allocating at least 100GB.
Now we need to change the original “translate” script.
At this stage, I hope I can assume that you have ssh access to the machine where you will train TensorFlow.
First, let's discuss why we need to modify the source script at all. The fact is that the script itself does not allow overriding the source of data that is used to train the model. To fix this, I created a feature-request . And I will try to prepare the implementation soon, but at the moment, you can participate by adding +1 to the “request”.
In any case, do not be afraid - the modification is very simple . But even such a small modification I have already done for you and created a repository containing the modified code . It remains only to do the following:
Rename the files “train.a” and “train.b” to “train.en” and “train.fr”, respectively. This is necessary because the training script still believes that he is learning to translate from English to French.
Both files must be uploaded to remote hosts — this can be done using the rsync command:
➜ train# REMOTE_IP=... ➜ train# ls train.en train.fr ➜ train rsync -r . ubuntu@$REMOTE_IP:/home/ubuntu/train Now let's connect to a remote host and start a tmux session. If you don’t know what tmux is, you can simply connect via SSH:
➜ train ssh ubuntu@$REMOTE_IP 53 packages can be updated. 42 updates are security updates. ######################################################################################################################## ######################################################################################################################## ____ _ _ __ _ _ | __ )(_) |_ / _|_ _ ___(_) ___ _ __ (_) ___ | _ \| | __| |_| | | / __| |/ _ \| '_ \ | |/ _ \ | |_) | | |_| _| |_| \__ \ | (_) | | | |_| | (_) | |____/|_|\__|_| \__,_|___/_|\___/|_| |_(_)_|\___/ Welcome to Bitfusion Ubuntu 14 Tensorflow - Ubuntu 14.04 LTS (GNU/Linux 3.13.0-101-generic x86_64) This AMI is brought to you by Bitfusion.io http://www.bitfusion.io Please email all feedback and support requests to: support@bitfusion.io We would love to hear from you! Contact us with any feedback or a feature request at the email above. ######################################################################################################################## ######################################################################################################################## ######################################################################################################################## Please review the README located at /home/ubuntu/README for more details on how to use this AMI Last login: Sat Dec 10 16:39:26 2016 from 99-46-141-149.lightspeed.sntcca.sbcglobal.net ubuntu@tf:~$ cd train/ ubuntu@tf:~/train$ ls train.en train.fr Let's check that TensorFlow is installed and it uses the GPU:
ubuntu@tf:~/train$ python Python 2.7.6 (default, Jun 22 2015, 17:58:13) [GCC 4.8.2] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import tensorflow as tf I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcublas.so.7.5 locally I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcudnn.so.5 locally I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcufft.so.7.5 locally I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcuda.so.1 locally I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcurand.so.7.5 locally >>> print(tf.__version__) 0.11.0 As you can see, TF version 0.11 is installed and it uses the CUDA library. Now let's bow the training script:
ubuntu@tf:~$ mkdir src/ ubuntu@tf:~$ cd src/ ubuntu@tf:~/src$ git clone https://github.com/b0noI/tensorflow.git Cloning into 'tensorflow'... remote: Counting objects: 117802, done. remote: Compressing objects: 100% (10/10), done. remote: Total 117802 (delta 0), reused 0 (delta 0), pack-reused 117792 Receiving objects: 100% (117802/117802), 83.51 MiB | 19.32 MiB/s, done. Resolving deltas: 100% (88565/88565), done. Checking connectivity... done. ubuntu@tf:~/src$ cd tensorflow/ ubuntu@tf:~/src/tensorflow$ git checkout -b r0.11 origin/r0.11 Branch r0.11 set up to track remote branch r0.11 from origin. Switched to a new branch 'r0.11' Note that we need the r0.11 branch. First of all, this thread is consistent with the version of the locally installed TensorFlow. Secondly, I did not transfer my changes to other branches, therefore, if necessary, I will have to do this with your own hands.
Congratulations! You have reached the stage of learning. Feel free to run this very training:
ubuntu@tf:~/src/tensorflow$ cd tensorflow/models/rnn/translate/ ubuntu@tf:~/src/tensorflow/tensorflow/models/rnn/translate$ python ./translate.py --en_vocab_size=40000 --fr_vocab_size=40000 --data_dir=/home/ubuntu/train --train_dir=/home/ubuntu/train ... Tokenizing data in /home/ubuntu/train/train.en tokenizing line 100000 ... global step 200 learning rate 0.5000 step-time 0.72 perplexity 31051.66 eval: bucket 0 perplexity 173.09 eval: bucket 1 perplexity 181.45 eval: bucket 2 perplexity 398.51 eval: bucket 3 perplexity 547.47 Let's discuss some of the keys that we use:
- en_vocab_size - how many unique words will learn the “English language” model. If the number of unique words from the source data exceeds the size of the dictionary, all words that are not in the dictionary will be marked as “UNK” (code: 3). But I do not recommend making the dictionary more than necessary; but it should not be less;
- fr_vocab_size - the same, but for a different part of the data (for “French”);
- data_dir - directory with source data. Here the script will look for the files “train.en” and “train.fr”;
- train_dir - directory in which the script will record the intermediate result of training.
Let's make sure the training goes on and everything goes according to plan.
You have successfully started learning. But let's confirm that the process continues and everything is in order. We don’t want to find out after 6 hours that something was done wrong at the very beginning. Gleb and I have already somehow taught something half-sensible =)
First of all, we can confirm that the learning process “bit off” the memory of the GPU:
$ watch -n 0.5 nvidia-smi As you can see, I didn’t get sick so much, almost all the memory on the GPU is occupied. This is a good sign. And do not be afraid that your process is about to “kick back” with an OutOfMemory error. Just during the launch of TF, it takes up all the memory on the GPU that it can reach.
Then you can check the folder “train” - it should contain several new files:
~$ cd train ~/train$ ls train.fr train.ids40000.fr dev.ids40000.en dev.ids40000.fr train.en train.ids40000.en vocab40000.fr Here it is important to look into the files vocab4000. * And train.ids40000. *. There should be atmospheric and soulful, look here:
~/train$less vocab40000.en _PAD _GO _EOS _UNK . ' , I ? you the to s a t it of You ! that ... Each line in the file is a unique word that was found in the source data. Each word in the source data will be replaced by a number that represents the line number from this file. You can immediately notice that there are some technical words: PAD (0), GO (1), EOS (2), UNK (3). Probably the most important of them for us is “UNK”, since the number of words marked with this code (3) will give us some idea of how correctly we choose the size of our dictionary.
Now let's look at train.ids40000.en:
~/train$ less train.ids40000.en 1181 21483 4 4 4 1726 22480 4 7 251 9 5 61 88 7765 7151 8 7 5 27 11 125 10 24950 41 10 2206 4081 11 10 1663 84 7 4444 9 6 562 6 7 30 85 2435 11 2277 10289 4 275 107 475 155 223 12428 4 79 38 30 110 3799 16 13 767 3 7248 2055 6 142 62 4 1643 4 145 46 19218 19 40 999 35578 17507 11 132 21483 2235 21 4112 4 144 9 64 83 257 37 788 21 296 8 84 19 72 4 59 72 115 1521 315 66 22 4 16856 32 9963 348 4 68 5 12 77 1375 218 7831 4 275 11947 8 84 6 40 2135 46 5011 6 93 9 359 6370 6 139 31044 4 42 5 49 125 13 131 350 4 371 4 38279 6 11 22 316 4 3055 6 323 19212 6 562 21166 208 23 3 4 63 9666 14410 89 69 59 13262 69 4 59 155 3799 16 1527 4079 30 123 89 10 2706 16 10 2938 3 6 66 21386 4 116 8 ... I think you already guessed that this is data from input.en, but with all the words replaced with codes according to the dictionary. Now we can check how many words are marked as “unknowns” (UNK / 3):
~/train$ grep -o ' 3 ' train.ids40000.en | wc -l 7977 You can try in subsequent experiments to increase the size of the dictionary from 40k to 45k, or even up to 50k. But, we will continue the “as is” process and will not interrupt it.
6 hours later ... “It came to life!”
After waiting enough time, you can stupidly kill the learning process. Do not worry, the process saves the result every 200 steps of training (this number can be changed). I would recommend for training either to choose the period of time that you are willing to wait (it may depend on the amount you are willing to pay for the rental car), or the number of steps that you want the training process to complete.
The last and most important thing for which we arranged this whole mess - this is to start a chat. To do this, we just need to add one key to the team that was used for training:
~/src/tensorflow/tensorflow/models/rnn/translate$ python ./translate.py --en_vocab_size=40000 --fr_vocab_size=40000 --data_dir=/home/ubuntu/train --train_dir=/home/ubuntu/train --decode ... Reading model parameters from /home/ubuntu/data/translate.ckpt-54400 > Hello! Hello . > Hi are you? Now , okay . > What is your name? My name is Sir Sir . > Really? Yeah . > what about the real name? N . . . real real . > are you a live? Yes . > where are you? I ' m here . > where is here? I don ' t know . > can I help you to get here? Yeah , to I ve ' t feeling nothing to me . This is just the beginning! Here are a couple of ideas for improving the bot.
To help a project or simply create a bot with character, you can:
- implement logic that finds the ideal size for EN / FR dictionaries;
- publish train.en / train.fr somewhere so that other people do not create them from scratch;
- to train the bot master Yoda (or Darth Vader);
- to train a bot who will speak like in the universe of the “Lord of the Rings”;
- train a bot who will speak like people from the StarWars of the universe;
- train the bot on its dialogues so that it speaks like you!
Source: https://habr.com/ru/post/317732/
All Articles