Scaling ClickHouse, managing migrations and sending requests from PHP to the cluster
In the previous article, we shared our experience in implementing and using ClickHouse in the media company2 . In the current article, we will address the scaling issues that arise with an increase in the amount of data being analyzed and an increase in workload, when data can no longer be stored and processed within a single physical server. We will also tell you about the tool we developed for migrating DDL queries to the ClickHouse cluster.
ClickHouse was specially designed to work in clusters located in different data centers. The DBMS is scaled linearly to hundreds of nodes. For example, Yandex.Metrika at the time of writing this article is a cluster of more than 400 nodes.
ClickHouse provides sharding and out-of-box replication; they can be flexibly configured separately for each table. Apache ZooKeeper is required for replication (version 3.4.5+ recommended). For higher reliability, we use a ZK cluster (ensemble) of 5 nodes. An odd number of ZK nodes (for example, 3 or 5) should be chosen to ensure quorum. Also note that ZK is not used in SELECT operations, but is used, for example, in ALTER queries for changing columns, keeping the instructions for each of the replicas.
Sharding
ClickHouse sharding allows you to write and store portions of data in a cluster distributedly and process (read) data in parallel on all nodes of the cluster, increasing throughput and reducing latency. For example, in queries with GROUP BY, ClickHouse will aggregate at remote nodes and pass the intermediate states of aggregate functions to the requesting node, where they will be aggregated.
For sharding, a special Distributed engine is used, which does not store data, but delegates SELECT queries to shard tables (tables containing chunks of data) with subsequent processing of the received data. Data can be written to shards in two modes: 1) via the Distributed table and an optional sharding key or 2) directly into shard tables from which further data will be read through the Distributed table. Consider these modes in more detail.
In the first mode, data is written to the Distributed table using the sharding key. In the simplest case, the sharding key can be a random number, that is, the result of a call to the rand () function. However, as a sharding key, it is recommended to take the hash value from the field in the table, which will, on the one hand, localize small data sets on one shard, and on the other, ensure a fairly even distribution of such sets across different shards in a cluster. For example, the session identifier (sess_id) of a user will allow localizing page impressions for one user on one shard, while sessions of different users will be distributed evenly across all shards in the cluster (provided that the sess_id field values have a good distribution). The sharding key can also be non-numeric or composite. In this case, you can use the built-in hash function cityHash64 . In this mode, the data written to one of the cluster nodes will be automatically redirected to the necessary shards by the sharding key, however, increasing traffic.
A more complicated way is to calculate the necessary shard outside ClickHouse and write directly to the shard table. The difficulty here is due to the fact that you need to know the set of available shard nodes. However, in this case, the recording becomes more efficient, and the sharding mechanism (determining the desired shard) can be more flexible.
Replication
ClickHouse supports data replication , ensuring data integrity on replicas. For data replication, special MergeTree-family engines are used:
- ReplicatedMergeTree
- ReplicatedCollapsingMergeTree
- ReplicatedAggregatingMergeTree
- ReplicatedSummingMergeTree
Replication is often used with sharding. For example, a cluster of 6 nodes can contain 3 shards of 2 replicas each. It should be noted that replication does not depend on sharding mechanisms and works at the level of individual tables.
Data recording can be performed in any of the replica tables, ClickHouse performs automatic data synchronization between all replicas.
Configuration examples ClickHouse-cluster
As examples, we will consider various configurations for four nodes: ch63.smi2, ch64.smi2, ch65.smi2, ch66.smi2 . Settings are contained in the /etc/clickhouse-server/config.xml configuration file.
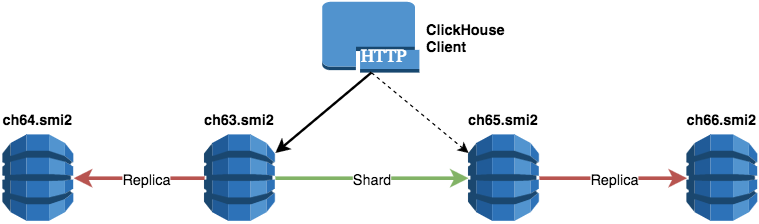
One shard and four replicas
<remote_servers> <!-- One shard, four replicas --> <repikator> <shard> <!-- replica 01_01 --> <replica> <host>ch63.smi2</host> </replica> <!-- replica 01_02 --> <replica> <host>ch64.smi2</host> </replica> <!-- replica 01_03 --> <replica> <host>ch65.smi2</host> </replica> <!-- replica 01_04 --> <replica> <host>ch66.smi2</host> </replica> </shard> </repikator> </remote_servers> Example of the table creation scheme:

An example of a SQL query to create a table for the specified configuration:
CREATE DATABASE IF NOT EXISTS dbrepikator ; CREATE TABLE IF NOT EXISTS dbrepikator.anysumming_repl_sharded ( event_date Date DEFAULT toDate(event_time), event_time DateTime DEFAULT now(), body_id Int32, views Int32 ) ENGINE = ReplicatedSummingMergeTree('/clickhouse/tables/{repikator_replica}/dbrepikator/anysumming_repl_sharded', '{replica}', event_date, (event_date, event_time, body_id), 8192) ; CREATE TABLE IF NOT EXISTS dbrepikator.anysumming_repl AS dbrepikator.anysumming_repl_sharded ENGINE = Distributed( repikator, dbrepikator, anysumming_repl_sharded , rand() ) The advantage of this configuration:
- The most reliable way to store data.
Disadvantages:
- For most tasks, an excess of copies of the data will be stored.
- Since there is only 1 shard in this configuration, a SELECT query cannot run in parallel on different nodes.
- Additional resources are required to replicate data multiple times between all nodes.
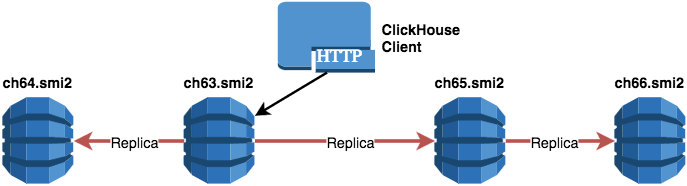
Four shards one replica
<remote_servers> <!-- Four shards, one replica --> <sharovara> <!-- shard 01 --> <shard> <!-- replica 01_01 --> <replica> <host>ch63.smi2</host> </replica> </shard> <!-- shard 02 --> <shard> <!-- replica 02_01 --> <replica> <host>ch64.smi2</host> </replica> </shard> <!-- shard 03 --> <shard> <!-- replica 03_01 --> <replica> <host>ch65.smi2</host> </replica> </shard> <!-- shard 04 --> <shard> <!-- replica 04_01 --> <replica> <host>ch66.smi2</host> </replica> </shard> </sharovara> </remote_servers> An example of a SQL query to create a table for the specified configuration:
CREATE DATABASE IF NOT EXISTS testshara ; CREATE TABLE IF NOT EXISTS testshara.anysumming_sharded ( event_date Date DEFAULT toDate(event_time), event_time DateTime DEFAULT now(), body_id Int32, views Int32 ) ENGINE = ReplicatedSummingMergeTree('/clickhouse/tables/{sharovara_replica}/sharovara/anysumming_sharded_sharded', '{replica}', event_date, (event_date, event_time, body_id), 8192) ; CREATE TABLE IF NOT EXISTS testshara.anysumming AS testshara.anysumming_sharded ENGINE = Distributed( sharovara, testshara, anysumming_sharded , rand() ) The advantage of this configuration:
- Since in this configuration there are 4 shards, a SELECT query can be executed simultaneously in parallel on all nodes of the cluster.
Disadvantage:
- The least reliable way to store data (loss of a node leads to the loss of a portion of data).
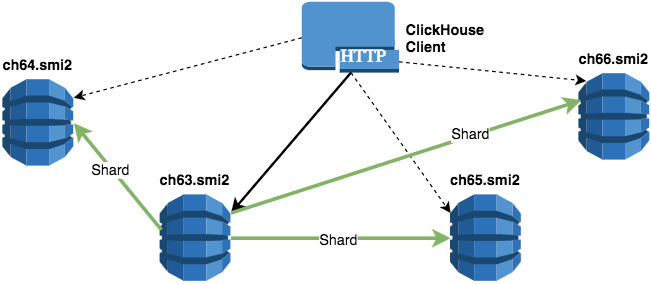
Two shard two replicas
<remote_servers> <!-- Two shards, two replica --> <pulse> <!-- shard 01 --> <shard> <!-- replica 01_01 --> <replica> <host>ch63.smi2</host> </replica> <!-- replica 01_02 --> <replica> <host>ch64.smi2</host> </replica> </shard> <!-- shard 02 --> <shard> <!-- replica 02_01 --> <replica> <host>ch65.smi2</host> </replica> <!-- replica 02_02 --> <replica> <host>ch66.smi2</host> </replica> </shard> </pulse> </remote_servers> An example of a SQL query to create a table for the specified configuration:
CREATE DATABASE IF NOT EXISTS dbpulse ; CREATE TABLE IF NOT EXISTS dbpulse.normal_summing_sharded ( event_date Date DEFAULT toDate(event_time), event_time DateTime DEFAULT now(), body_id Int32, views Int32 ) ENGINE = ReplicatedSummingMergeTree('/clickhouse/tables/{pulse_replica}/pulse/normal_summing_sharded', '{replica}', event_date, (event_date, event_time, body_id), 8192) ; CREATE TABLE IF NOT EXISTS dbpulse.normal_summing AS dbpulse.normal_summing_sharded ENGINE = Distributed( pulse, dbpulse, normal_summing_sharded , rand() ) This configuration embodies the best qualities of the first and second examples:
- Since in this configuration there are 2 shards, a SELECT query can be executed in parallel on each of the shards in the cluster.
- A relatively reliable way to store data (the loss of a single cluster node does not lead to the loss of a piece of data).
An example of cluster configuration in ansible
The cluster configuration in ansible may look like this:
- name: "pulse" shards: - { name: "01", replicas: ["ch63.smi2", "ch64.smi2"]} - { name: "02", replicas: ["ch65.smi2", "ch66.smi2"]} - name: "sharovara" shards: - { name: "01", replicas: ["ch63.smi2"]} - { name: "02", replicas: ["ch64.smi2"]} - { name: "03", replicas: ["ch65.smi2"]} - { name: "04", replicas: ["ch66.smi2"]} - name: "repikator" shards: - { name: "01", replicas: ["ch63.smi2", "ch64.smi2","ch65.smi2", "ch66.smi2"]} PHP-driver for working with ClickHouse-cluster
In the previous article, we already talked about our open-source PHP driver for ClickHouse.
When the number of nodes becomes large, cluster management becomes inconvenient. Therefore, we have developed a simple and fairly functional tool for migrating DDL queries to a ClickHouse cluster. Next, we briefly describe with examples its capabilities.
To connect to the cluster, the class ClickHouseDB\Cluster :
$cl = new ClickHouseDB\Cluster( ['host'=>'allclickhouse.smi2','port'=>'8123','username'=>'x','password'=>'x'] ); The allclickhouse.smi2 DNS records list the IP addresses of all sites: ch63.smi2, ch64.smi2, ch65.smi2, ch66.smi2 , which allows using the Round-robin DNS mechanism.
The driver connects to the cluster and sends ping requests to each node listed in the DNS records.
Setting the maximum connection time to all nodes in the cluster is configured as follows:
$cl->setScanTimeOut(2.5); // 2500 ms Checking the status of cluster replicas is performed as follows:
if (!$cl->isReplicasIsOk()) { throw new Exception('Replica state is bad , error='.$cl->getError()); } The status of the ClickHouse cluster is checked as follows:
- Connections are checked against all cluster nodes listed in the DNS records.
- A SQL query is sent to each node, which allows you to determine the status of all replicas of the ClickHouse cluster.
The speed of the query can be increased if you do not read the values of the log_max_index, log_pointer, total_replicas, active_replicas when retrieving data from which queries are made to the ZK cluster.
For a light check in the driver, you need to set a special flag:
$cl->setSoftCheck(true); Listing all available clusters is done as follows:
print_r($cl->getClusterList()); // result // [0] => pulse // [1] => repikator // [2] => sharovara For example, to obtain the configuration of the clusters that were described above, you can do this:
foreach (['pulse','repikator','sharovara'] as $name) { print_r($cl->getClusterNodes($name)); echo "> $name , count shard = ".$cl->getClusterCountShard($name)." ; count replica = ".$cl->getClusterCountReplica($name)."\n"; } //: //> pulse , count shard = 2 ; count replica = 2 //> repikator , count shard = 1 ; count replica = 4 //> sharovara , count shard = 4 ; count replica = 1 Obtaining a list of nodes by cluster name or from shard tables:
$nodes=$cl->getNodesByTable('sharovara.body_views_sharded'); $nodes=$cl->getClusterNodes('sharovara'); Getting the size of the table or the size of all tables by sending a request to each node of the cluster:
foreach ($nodes as $node) { echo "$node > \n"; print_r($cl->client($node)->tableSize('test_sharded')); print_r($cl->client($node)->tablesSize()); } // $cl->getSizeTable('dbName.tableName'); Getting a list of cluster tables:
$cl->getTables() Cluster leader definition:
$cl->getMasterNodeForTable('dbName.tableName') // is_leader=1 Requests related, for example, to deleting or changing the structure, are sent to a node with the is_leader flag is_leader .
Clearing data in a table in a cluster:
$cl->truncateTable('dbName.tableName')` DDL Migration Tool
For the migration of DDL queries for relational DBMS in our company, MyBatis Migrations is used .
About tools of migration on Habré already wrote:
- Versional migration of database structure: basic approaches
- Simple migrations with PHPixie Migrate
- Managing migration scripts or MyBatis Scheme Migration Extended
To work with ClickHouse-cluster, we needed a similar tool.
At the time of this writing, ClickHouse has a number of features (limitations) associated with DDL queries. Quote :
INSERT, ALTER are replicated (see details in the ALTER query description). Compressed data is replicated, not the query text. CREATE, DROP, ATTACH, DETACH, RENAME requests are not replicated — that is, they belong to the same server. The CREATE TABLE query creates a new replicable table on the server where the query is being executed; and if on other servers such a table already exists, it adds a new replica. The DROP TABLE query deletes the replica located on the server where the query is executed. The RENAME query renames the table on one of the replicas — that is, the replicated tables on different replicas may be called differently.
The ClickHouse development team has already announced work in this direction, but at present it is necessary to solve this problem with an external toolkit. We have created a simple prototype of the phpMigrationsClickhouse tool for migrating DDL requests to the ClickHouse cluster. And in our plans - to abstract phpMigrationsClickhouse from the PHP language.
We describe the algorithm currently used in phpMigrationsClickhouse , which can be implemented in any other programming language.
Currently, the migration instruction for phpMigrationsClickhouse consists of:
- SQL queries that need to be rolled and rolled back in case of an error;
- name of the cluster in which you want to execute SQL queries.
Create a PHP file containing the following code:
$cluster_name = 'pulse'; $mclq = new \ClickHouseDB\Cluster\Migration($cluster_name); $mclq->setTimeout(100); Add SQL queries that need to be rolled:
$mclq->addSqlUpdate(" CREATE DATABASE IF NOT EXISTS dbpulse "); $mclq->addSqlUpdate(" CREATE TABLE IF NOT EXISTS dbpulse.normal_summing_sharded ( event_date Date DEFAULT toDate(event_time), event_time DateTime DEFAULT now(), body_id Int32, views Int32 ) ENGINE = ReplicatedSummingMergeTree('/clickhouse/tables/{pulse_replica}/pulse/normal_summing_sharded', '{replica}', event_date, (event_date, event_time, body_id), 8192) "); Add SQL queries to perform rollback in case of error:
$mclq->addSqlDowngrade(' DROP TABLE IF EXISTS dbpulse.normal_summing_sharded '); $mclq->addSqlDowngrade(' DROP DATABASE IF EXISTS dbpulse '); There are 2 strategies for rolling migrations:
- sending each separate SQL query to one server with the transition to the next SQL query;
- sending all SQL queries to one server with the transition to the next server.
If an error occurs, the following options are possible:
- execution of a downgrade request for all nodes on which upgrade-requests have already been made;
- waiting before sending upgrade requests to other servers;
- execution of downgrade request on all servers in case of an error.
A separate place is occupied by errors when the cluster status is not known:
- connection timeout error;
- communication error with the server.
The principle of the PHP code when migrating is as follows:
// IP- $node_hosts=$this->getClusterNodes($migration->getClusterName()); // downgrade- $sql_down=$migration->getSqlDowngrade(); // upgrade- $sql_up=$migration->getSqlUpdate(); // upgrade- , , downgrade- $need_undo=false; $undo_ip=[]; foreach ($sql_up as $s_u) { foreach ($node_hosts as $node) { // upgrade- $state=$this->client($node)->write($s_u); if ($state->isError()) { $need_undo = true; } else { // OK } if ($need_undo) { // , $undo_ip[$node]=1; break; } } } // upgrade- if (!$need_undo) { return true; // OK } In case of an error, a downgrade request is sent to all nodes of the cluster:
foreach ($node_hosts as $node) { foreach ($sql_down as $s_u) { try{ $st=$this->client($node)->write($s_u); } catch (Exception $E) { // downgrade- } } } We will continue the series of materials dedicated to our experience with ClickHouse.
In conclusion, we would like to conduct a short survey.
')
Source: https://habr.com/ru/post/317682/
All Articles