Parsing Texts with SyntaxNet
For one of the tasks, I needed a parser for Russian texts. What it is. For example, we have the sentence “Mommy soap frame”. We need to get the connections of the words in this sentence in the form of a tree:

From this tree it is clear that the words "mother" and "soap" are connected, as well as "soap" and "frame", and the words "mother" and "frame" are not directly related.
The article will be useful to those who need a parser, but it is not clear where to start.
')
I dealt with this topic a few months ago, and at that time I didn’t find a lot of information on where to get a ready and preferably free analyzer.
On Habré there is an excellent article about the experience of working with MaltParser. But since then, some of the packages used for building have moved to other repositories, and in order to build a project with the right versions of libraries, you have to work hard.
There are other options, including SyntaxNet. On Habré, I did not find anything about SyntaxNet, so I fill in the gap.
In essence, SyntaxNet is a TensorFlow -based library for defining syntactic links, using a neural network. Currently 40 languages are supported, including Russian.
The entire installation process is described in the official documentation. I don’t see any sense in duplicating instructions here, I’ll just mention one thing. For assembly is used Bazel. I tried to build a project using it on my virtual machine with Ubuntu 16.04 x64 Server with 4 dedicated processors and 8 GB of RAM, and this was not successful - all the memory is being eaten and the swap is activated. After several hours, I interrupted the installation process, and repeated everything, allocating already 12 GB of RAM. In this case, everything went smoothly, with a swap of only 20 MB at the peak.
Perhaps there are some settings with which you can put the system in an environment with less RAM. Perhaps the assembly is performed in several parallel processes and it was worth allocating only 1 processor to the virtual machine. If you know, write in the comments.
After the installation is complete, I left 1GB of memory for this virtual machine and this is enough with enough margin to parse the texts successfully.
I chose Russian-SynTagRus as a marked body, it is more voluminous compared to Russian and with it the accuracy should be higher.
To parse the proposal, go to the directory
In the file result.txt we get about the output, I replaced the data in the 6th column with "_" so that the lines were not transferred here, otherwise it is inconvenient to read:
Data is presented in the format CoNLL-U . Here the most interesting are the following columns:
1. the ordinal number of the word in the sentence,
2. word (or punctuation character),
4. part of speech, here you can see a description of parts of speech,
7. the number of the parent word (or 0 for the root).
That is, we have a tree in which the word "soap" is the root, because it is in the line where column number 7 contains "0". The word "soap" has the sequence number 2. We are looking for all the lines in which column number 7 contains "2", these are child elements of the word "soap". Total, we get:

By the way, if you look in more detail, then the tree does not always successfully represent all dependencies. In ABBYY Compreno , for example, additional links are added to the tree, which indicate the connection of elements located in different branches of the tree. In our case, we will not receive such connections.
If the speed of parsing texts is critical for you, then you can try to figure out TensorFlow Serving , with the help of it you can load the model into memory once and then get answers much faster. Unfortunately, working through TensorFlow Serving was not as simple as it seemed initially. But overall this is possible. Here is an example of how this was done for the Korean language. If you have an example of how to do this for the Russian language, write in the comments.
In my case, the speed of parsing was not very critical, so I did not finish off the topic with TensorFlow Serving and wrote a simple API for working with SyntaxNet so that you can keep SyntaxNet on a separate server and access it via HTTP.
In this repository, there is also a web interface, which is convenient to use for debugging, to see how exactly the proposal has been parsed.

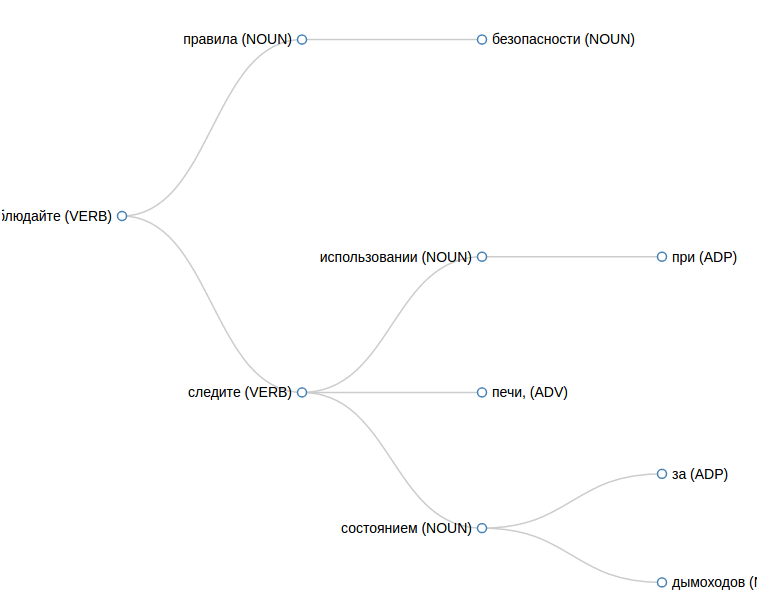
To get the result in JSON, do this query:
We get this answer:
I will clarify one point. Bazel installs packages in an interesting way, so that some of the binaries are stored in
There is also MaltParser, which I mentioned at the beginning. Later, I discovered that you can download the marked-up SynTagRus corpus and even successfully trained on it a fresh version of MaltParser, but I haven’t found time to finish the job and build MaltParser as a whole to get the result of parsing. This system builds a tree a little differently and for my task it is interesting to compare the results obtained with SyntaxNet and MaltParser. Maybe next time you can write about it.
If you already successfully use any tool for parsing texts in Russian, write in the comments what you use, it will be interesting for me and other readers to learn.
UPD
Very useful clarifications from buriy in the comments below:
Therefore, the input sentences must be submitted in such a way that the punctuation marks are separated from both sides by spaces.
From this tree it is clear that the words "mother" and "soap" are connected, as well as "soap" and "frame", and the words "mother" and "frame" are not directly related.
The article will be useful to those who need a parser, but it is not clear where to start.
')
I dealt with this topic a few months ago, and at that time I didn’t find a lot of information on where to get a ready and preferably free analyzer.
On Habré there is an excellent article about the experience of working with MaltParser. But since then, some of the packages used for building have moved to other repositories, and in order to build a project with the right versions of libraries, you have to work hard.
There are other options, including SyntaxNet. On Habré, I did not find anything about SyntaxNet, so I fill in the gap.
What is SyntaxNet
In essence, SyntaxNet is a TensorFlow -based library for defining syntactic links, using a neural network. Currently 40 languages are supported, including Russian.
SyntaxNet installation
The entire installation process is described in the official documentation. I don’t see any sense in duplicating instructions here, I’ll just mention one thing. For assembly is used Bazel. I tried to build a project using it on my virtual machine with Ubuntu 16.04 x64 Server with 4 dedicated processors and 8 GB of RAM, and this was not successful - all the memory is being eaten and the swap is activated. After several hours, I interrupted the installation process, and repeated everything, allocating already 12 GB of RAM. In this case, everything went smoothly, with a swap of only 20 MB at the peak.
Perhaps there are some settings with which you can put the system in an environment with less RAM. Perhaps the assembly is performed in several parallel processes and it was worth allocating only 1 processor to the virtual machine. If you know, write in the comments.
After the installation is complete, I left 1GB of memory for this virtual machine and this is enough with enough margin to parse the texts successfully.
I chose Russian-SynTagRus as a marked body, it is more voluminous compared to Russian and with it the accuracy should be higher.
Using SyntaxNet
To parse the proposal, go to the directory
tensorflow/models/syntaxnet and run (the path to the model is absolute): echo " " | syntaxnet/models/parsey_universal/parse.sh /home/tensor/tensorflow/Russian-SynTagRus > result.txt In the file result.txt we get about the output, I replaced the data in the 6th column with "_" so that the lines were not transferred here, otherwise it is inconvenient to read:
cat result.txt 1 _ NOUN _ _ 2 nsubj __ 2 _ VERB _ _ 0 ROOT _ _ 3 _ NOUN _ _ 2 dobj __ Data is presented in the format CoNLL-U . Here the most interesting are the following columns:
1. the ordinal number of the word in the sentence,
2. word (or punctuation character),
4. part of speech, here you can see a description of parts of speech,
7. the number of the parent word (or 0 for the root).
That is, we have a tree in which the word "soap" is the root, because it is in the line where column number 7 contains "0". The word "soap" has the sequence number 2. We are looking for all the lines in which column number 7 contains "2", these are child elements of the word "soap". Total, we get:
By the way, if you look in more detail, then the tree does not always successfully represent all dependencies. In ABBYY Compreno , for example, additional links are added to the tree, which indicate the connection of elements located in different branches of the tree. In our case, we will not receive such connections.
Interface
If the speed of parsing texts is critical for you, then you can try to figure out TensorFlow Serving , with the help of it you can load the model into memory once and then get answers much faster. Unfortunately, working through TensorFlow Serving was not as simple as it seemed initially. But overall this is possible. Here is an example of how this was done for the Korean language. If you have an example of how to do this for the Russian language, write in the comments.
In my case, the speed of parsing was not very critical, so I did not finish off the topic with TensorFlow Serving and wrote a simple API for working with SyntaxNet so that you can keep SyntaxNet on a separate server and access it via HTTP.
In this repository, there is also a web interface, which is convenient to use for debugging, to see how exactly the proposal has been parsed.
To get the result in JSON, do this query:
curl -d text=" ." -d format="JSON" http://<host where syntax-tree installed> We get this answer:
[{ number: "2", text: "", pos: "VERB", children: [ { number: "1", text: "", pos: "NOUN", children: [ ] }, { number: "3", text: "", pos: "NOUN", children: [ ] } ] }] I will clarify one point. Bazel installs packages in an interesting way, so that some of the binaries are stored in
~/.cache/bazel . To get access to their execution from PHP, I added the rights to this directory for the user of the web server on the local machine. Probably the same goal can be achieved in a more cultural way, but for experiments this is enough.What else
There is also MaltParser, which I mentioned at the beginning. Later, I discovered that you can download the marked-up SynTagRus corpus and even successfully trained on it a fresh version of MaltParser, but I haven’t found time to finish the job and build MaltParser as a whole to get the result of parsing. This system builds a tree a little differently and for my task it is interesting to compare the results obtained with SyntaxNet and MaltParser. Maybe next time you can write about it.
If you already successfully use any tool for parsing texts in Russian, write in the comments what you use, it will be interesting for me and other readers to learn.
UPD
Very useful clarifications from buriy in the comments below:
parsing would work much better there if there were no errors in the morphology model, which is not based on dictionaries, but is also a neural network
In the input format, punctuation marks are separate tokens.
Therefore, the input sentences must be submitted in such a way that the punctuation marks are separated from both sides by spaces.
Well, another point at the end of a sentence sometimes changes something
There must also be a space before the final point, so the input format is arranged and the model was trained on such examples
Source: https://habr.com/ru/post/317564/
All Articles