How to choose algorithms for machine learning Microsoft Azure
In the article, you will find the Microsoft Azure Machine Learning Cheat Sheet , which will help you choose the appropriate algorithm for your predictive analytics solutions from the Microsoft Azure Algorithm Library. And also you will learn how to use it.

The answer to the question “Which machine learning algorithm to use?” Always sounds like this: “Depending on the circumstances.” The choice of algorithm depends on the volume, quality and nature of the data. It depends on how you manage the result. It depends on how instructions were created from the algorithm for the computer that implements it, and also on how much time you have. Even the most experienced data analysts will not tell you which algorithm is better until they try it themselves.
Download the cheat sheet on Microsoft Azure machine learning algorithms here .
')
It is designed for novice data analysts with sufficient machine learning experience who want to choose an algorithm for use in Azure Machine Learning. This means that the information in the cheat sheet is generalized and simplified, but it will show you the right direction for further action. Also, it contains not all algorithms. As Azure Machine Learning develops and offers more methods, the algorithms will be complemented.
These recommendations are based on the feedback and advice of many data analysts and machine learning experts. We do not fully agree with each other, but tried to summarize our opinions and reach a consensus. Most controversial moments begin with the words "Depending on the circumstances ..." :)
Read the labels of the path and the algorithm on the diagram should be as follows: "For < path label > use <a algorithm> ". For example, "For speed use two class logistic regression ". Sometimes you can use multiple branches. Sometimes none of them will be the perfect choice. This is just a recommendation, so do not worry about inaccuracies. Some data analysts, who I managed to communicate with, say that the only sure way to find the best algorithm is to try them all.
Here is an example of an experiment from the Cortana Intelligence Gallery , in which several algorithms are tried with the same data and the results are compared.
Download and print a chart with an overview of the capabilities of the Machine Learning Studio in this article .
Teacher-learning algorithms make predictions based on a set of examples. So, in order to predict prices in the future, you can use the stock price in the past. Each example used for training gets its own distinctive value label, in this case the stock price. The learning algorithm with the teacher is looking for patterns in these value labels. The algorithm can use any important information - the day of the week, the season of the year, the company's financial data, the type of industry, the presence of serious geopolitical events, and each algorithm looks for different types of patterns. After the algorithm finds a suitable pattern, with its help it makes predictions using unallocated test data to predict prices in the future.
This is a popular and useful type of machine learning. With one exception, all Azure machine learning modules are teacher-learning algorithms. Azure Machine Learning Services provides several specific types of machine learning with a teacher: classification, regression, and anomaly detection.
In the framework of training without a teacher, data objects have no tags. Instead, the learning algorithm without a teacher should organize the data or describe its structure. To do this, they can be grouped into clusters to make them more structured, or find other ways to simplify complex data.
In the framework of reinforcement learning, the algorithm selects an action in response to each incoming data object. After a while, the learning algorithm receives a reward signal that indicates how correct the solution was. On this basis, the algorithm changes its strategy to get the highest reward. There are currently no reinforcement learning modules in Azure machine learning. Reinforcement training is common in robotics, where a set of sensor readings at a particular point in time is an object, and the algorithm must choose the next action of the robot. In addition, this algorithm is suitable for applications on the Internet of things.
Not always need the most accurate answer. Depending on the purpose, it is sometimes enough to get an approximate answer. If so, then you can significantly reduce the time of mining by choosing approximate methods. Another advantage of approximate methods is that they eliminate retraining .
The number of minutes or hours needed to train a model depends heavily on the algorithms. Often, learning time is closely related to accuracy - they define each other. In addition, some algorithms are more sensitive to the training sample size than others. A time limit helps to choose an algorithm, especially if a large sample of training samples is used.
Many machine learning algorithms use linearity. Algorithms for linear classification suggest that classes can be divided by a straight line (or its more multidimensional analogue). Here we are talking about logistic regression and the support vector machine (in Azure machine learning). The linear regression algorithms assume that the distribution of data is described by a straight line *. These assumptions are suitable for solving a number of problems, but in some cases reduce accuracy.
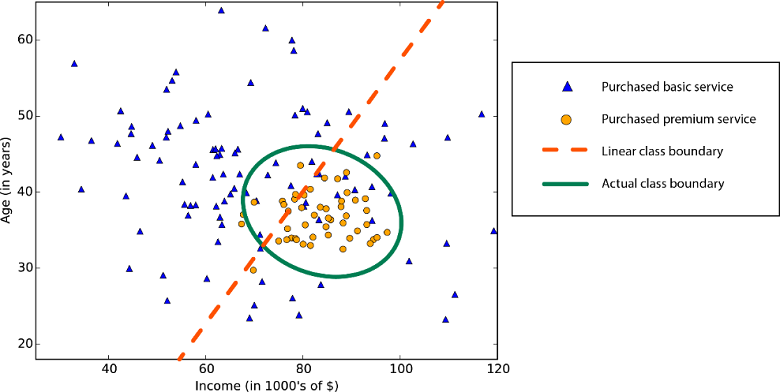
Limiting non-linear classes — using a linear classification algorithm reduces accuracy

Data with nonlinear regularity - when using the method of linear regression, there are more serious errors than is permissible
Despite the shortcomings, linear algorithms are usually addressed first. They are simple with an algorithmic point of view, and learning is fast.
Parameters are the levers with which data experts set up an algorithm. These are the numbers that influence the behavior of the algorithm, for example, error tolerance or the number of iterations, or differences in the behavior of the algorithm. Sometimes the learning time and the accuracy of the algorithm may vary depending on certain parameters. As a rule, a good combination of parameters for algorithms can be found through trial and error.
Also in Azure machine learning there is a modular parameter selection block that automatically tries all combinations of parameters with the level of detail you specify. Although this method allows you to try out a lot of options, but the more parameters, the more time is spent on training the model.
Fortunately, if there are a lot of parameters, this means that the algorithm is highly flexible. And with this method you can achieve excellent accuracy. But provided that you manage to find a suitable combination of parameters.
In some types of data attributes can be much more than objects. This usually happens with data from genetics or textual data. A large number of signs hinder the work of some learning algorithms, because of which the learning time is incredibly stretched. The support vector method is well suited for such cases (see below).
Some learning algorithms make assumptions about the data structure or the desired results. If you manage to find a suitable option for your purposes, it will bring you excellent results, more accurate predictions or shorten the training time.
Algorithm properties:
• - demonstrates excellent accuracy, short training time and the use of linearity.
○ - demonstrates excellent accuracy and average learning time.
As we have said, linear regression treats data linearly (either in the plane or in the hyperplane). This is a convenient and fast "workhorse", but for some problems it can be too simple. Here you will find a guide to linear regression.

Line Trend Data
Let the word "regression" in the title does not mislead you. Logistic regression is a very powerful tool for two-class and multi-class classification. It's quick and easy. Since instead of a straight line, an S-shaped curve is used here, this algorithm is perfect for dividing data into groups. Logistic regression restricts the linear class, so you will have to accept linear approximation.
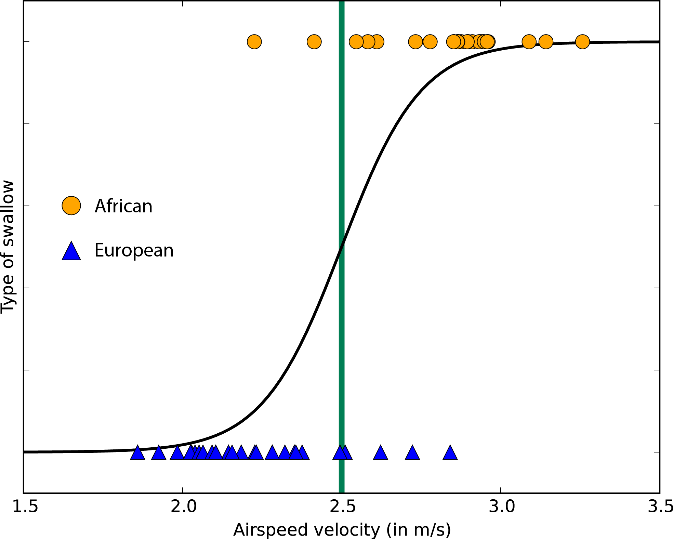
Logistic regression for two-class data with only one attribute — the class boundary is at the point where the logistic curve is close to both classes
Decisive tree forests ( regression , two-class and multi-class ), decision tree jungle ( two-class and multi-class ), and improved decision-making trees ( regression and two-class ) are based on decision trees, the basic concept of machine learning. There are many variants of decision trees, but they all perform the same function - they subdivide the feature space into regions with the same label. These can be areas of one category or a constant value, depending on whether you are using a classification or regression.

The decision tree divides the feature space into areas with approximately the same values.
Since the feature space can be divided into small areas, this can be done so that there is one object in one area - this is a rough example of a false connection. To avoid this, large sets of trees are created so that the trees are not connected to each other. Thus, the “decision tree” should not produce false links. Decision trees can consume large amounts of memory. Decisive jungle trees consume less memory, but learning will take a little longer.
Improved decision trees limit the number of partitions and the distribution of data points in each area to avoid false links. The algorithm creates a sequence of trees, each of which corrects previously made errors. As a result, we get a high degree of accuracy without large memory costs. Full technical description, see the scientific work of Friedman .
Fast quantile regression forests are a variant of decision trees for those cases when you want to know not only the typical (average) value of data in a region, but also their distribution in the form of quantiles.
Neural networks are learning algorithms that are based on the human brain model and are aimed at solving multi-class , two-class and regression problems. There are so many of them, but in Azure machine learning, neural networks take the form of directional acyclic graphics. This means that the input features are transmitted forward through a sequence of levels and turned into output data. At each level, the input data is measured in various combinations, summarized and transmitted to the next level. This combination of simple calculations allows you to study the complex class boundaries and data trends as if by magic. These multi-level networks provide “deep learning” that serves as an inspiration for technical reports and science fiction.
But such performance is not free. Learning neural networks takes a lot of time, especially for large data sets with many features. They have more parameters than most algorithms, and therefore the selection of parameters significantly increases the learning time. And for perfectionists who want to specify their own network structure , the possibilities are practically unlimited.
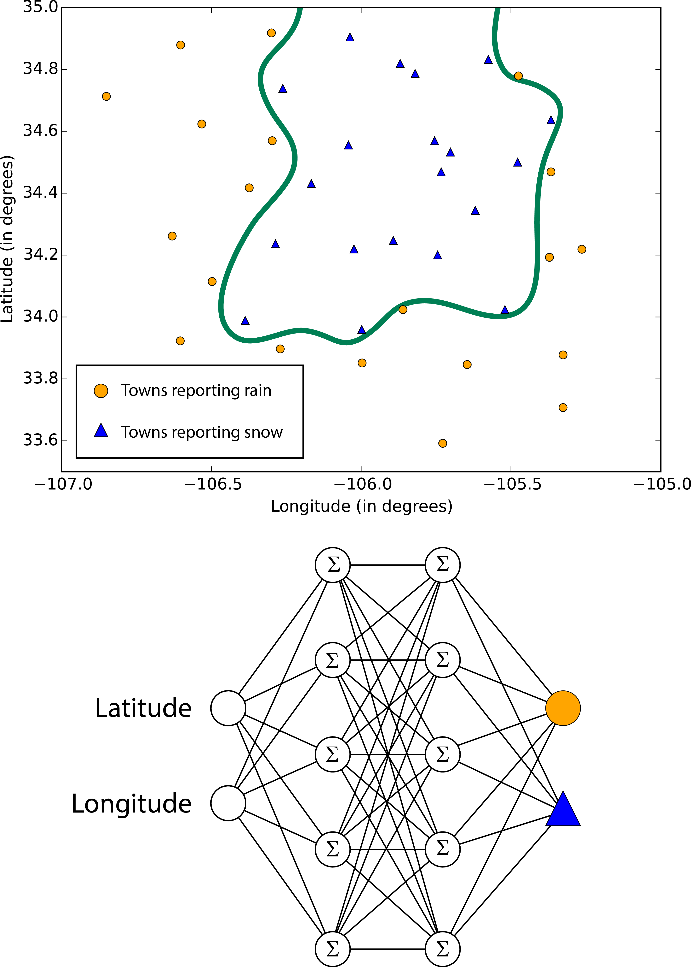
The boundaries studied by neural networks are complex and chaotic.
A single-layer perceptron is the response of neural networks to an increase in learning time. It uses a network structure that creates linear class boundaries. By modern standards, this sounds primitive, but this algorithm has been tested in practice for a long time and learns quickly.
Support vector methods find a boundary that separates classes as widely as possible. When it is impossible to clearly separate the two classes, the algorithms find the best border. According to Azure machine learning, the two-class support vector machine method does this using a straight line (speaking the language of the support vector machine, it uses the linear core). Due to the linear approximation, the training is carried out fairly quickly. Of particular interest is the function of working with objects with a multitude of features, for example, text or a genome. In such cases, support vector machines can divide classes more quickly and are distinguished by a minimal probability of creating a false connection, and also do not require large amounts of memory.

Standard class boundary of a vector support machine increases the field between two classes.
Another product from Microsoft Research is two-class local depth support vector machine methods . This is a non-linear variant of support vector methods, which is distinguished by the speed and efficiency of memory inherent in the linear version. It is ideal for cases where the linear approach does not provide sufficiently accurate answers. To ensure high speed, developers break the problem into several small tasks of the linear support vector machine method. Read more about this in the full description .
By extending non-linear support vector vectors, a single-class support vector machine creates a boundary for the entire data set. This is especially useful for filtering outliers. All new objects that are not within the boundaries are considered unusual and therefore are carefully studied.
Bayesian methods have a very good quality: they avoid false connections. To do this, they make assumptions about the possible distribution of the answer. Also, they do not need to configure many parameters. Azure machine learning offers Bayesian methods for both classification ( Bayes' two-class classification ) and regression ( Bayesian linear regression ). It is assumed that the data can be divided or positioned along a straight line.
By the way, Bayes point machines were developed by Microsoft Research. In their foundation lies a magnificent theoretical work. If you are interested in this topic, read the MLR article and Chris Bishop’s blog (Chris Bishop) .
If you are pursuing a specific goal, you are lucky. In the Azure machine learning collection, there are algorithms that specialize in rating forecasting ( order regression ), quantity forecasting ( Poisson regression ), and anomaly detection (one of them is based on the analysis of the main components and the other on support vector techniques ). And there is also a clustering algorithm ( k-means method ).

PCA-based anomaly detection — a huge amount of data falls under the stereotypical distribution; points that strongly deviate from this distribution fall under suspicion
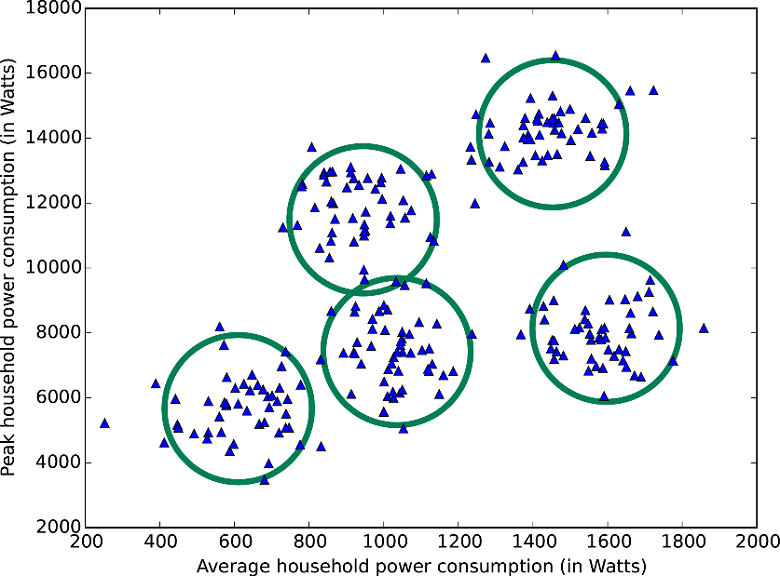
The data set is divided into five clusters by the k-means method.
There is also a “one against all” multi-class classifier that breaks the problem of classifying an N-class into two-class problems of the N-1 class. Accuracy, training time and linearity properties depend on the two-class classifiers used.

Two two-class classifiers form a three-class classifier.
In addition, Azure offers access to a powerful machine learning platform called Vowpal Wabbit . VW refuses categorization because it can study the problems of classification and regression, and even learn from partially tagged data. You can choose any of the learning algorithms, loss functions and optimization algorithms. This platform is characterized by efficiency, the possibility of parallel execution and unsurpassed speed. It easily handles large data sets. VW was launched by John Langford (John Langford), a specialist from Microsoft Research, and is a Formula 1 car in the ocean of production cars. Not every problem is suitable for VW, but if you think that this is the right option for you, then the effort expended will certainly pay off. The platform is also available as a standalone open source code in several languages.
1. Azure plain language (cheat sheet).
2. Trucks and refrigerators in the cloud (case).
We remind you that you can try Microsoft Azure here .
If you see an inaccuracy of the translation, please report this to private messages.
* UPD
The answer to the question “Which machine learning algorithm to use?” Always sounds like this: “Depending on the circumstances.” The choice of algorithm depends on the volume, quality and nature of the data. It depends on how you manage the result. It depends on how instructions were created from the algorithm for the computer that implements it, and also on how much time you have. Even the most experienced data analysts will not tell you which algorithm is better until they try it themselves.
Microsoft Azure Machine Learning Cheat Sheet
Download the cheat sheet on Microsoft Azure machine learning algorithms here .
')
It is designed for novice data analysts with sufficient machine learning experience who want to choose an algorithm for use in Azure Machine Learning. This means that the information in the cheat sheet is generalized and simplified, but it will show you the right direction for further action. Also, it contains not all algorithms. As Azure Machine Learning develops and offers more methods, the algorithms will be complemented.
These recommendations are based on the feedback and advice of many data analysts and machine learning experts. We do not fully agree with each other, but tried to summarize our opinions and reach a consensus. Most controversial moments begin with the words "Depending on the circumstances ..." :)
How to use the cheat sheet
Read the labels of the path and the algorithm on the diagram should be as follows: "For < path label > use <a algorithm> ". For example, "For speed use two class logistic regression ". Sometimes you can use multiple branches. Sometimes none of them will be the perfect choice. This is just a recommendation, so do not worry about inaccuracies. Some data analysts, who I managed to communicate with, say that the only sure way to find the best algorithm is to try them all.
Here is an example of an experiment from the Cortana Intelligence Gallery , in which several algorithms are tried with the same data and the results are compared.
Download and print a chart with an overview of the capabilities of the Machine Learning Studio in this article .
Machine learning types
Teaching with a teacher
Teacher-learning algorithms make predictions based on a set of examples. So, in order to predict prices in the future, you can use the stock price in the past. Each example used for training gets its own distinctive value label, in this case the stock price. The learning algorithm with the teacher is looking for patterns in these value labels. The algorithm can use any important information - the day of the week, the season of the year, the company's financial data, the type of industry, the presence of serious geopolitical events, and each algorithm looks for different types of patterns. After the algorithm finds a suitable pattern, with its help it makes predictions using unallocated test data to predict prices in the future.
This is a popular and useful type of machine learning. With one exception, all Azure machine learning modules are teacher-learning algorithms. Azure Machine Learning Services provides several specific types of machine learning with a teacher: classification, regression, and anomaly detection.
- Classification . When data is used to predict a category, learning with a teacher is called a classification. In this case, the appointment of the image, for example, "cat" or "dog." When there are only two choices, this is called a two-class classification . When there are more categories, for example, when predicting the winner of the NCAA March Madness tournament, this is called multi-class classification .
- Regression . When a value is predicted, for example, in the case of a stock price, training with a teacher is called regression.
- Emission Filtration . Sometimes you need to define unusual data points. For example, if fraud is detected, any strange patterns of spending money from a credit card are suspected. There are so many options, and there are so few examples for training that it is almost impossible to know what fraudulent activity will look like. Filtration of emissions simply examines the normal activity (using the archive of permissible transactions) and all operations are found with noticeable differences.
Teaching without a teacher
In the framework of training without a teacher, data objects have no tags. Instead, the learning algorithm without a teacher should organize the data or describe its structure. To do this, they can be grouped into clusters to make them more structured, or find other ways to simplify complex data.
Reinforcement training
In the framework of reinforcement learning, the algorithm selects an action in response to each incoming data object. After a while, the learning algorithm receives a reward signal that indicates how correct the solution was. On this basis, the algorithm changes its strategy to get the highest reward. There are currently no reinforcement learning modules in Azure machine learning. Reinforcement training is common in robotics, where a set of sensor readings at a particular point in time is an object, and the algorithm must choose the next action of the robot. In addition, this algorithm is suitable for applications on the Internet of things.
Algorithm Tips
Accuracy
Not always need the most accurate answer. Depending on the purpose, it is sometimes enough to get an approximate answer. If so, then you can significantly reduce the time of mining by choosing approximate methods. Another advantage of approximate methods is that they eliminate retraining .
Studying time
The number of minutes or hours needed to train a model depends heavily on the algorithms. Often, learning time is closely related to accuracy - they define each other. In addition, some algorithms are more sensitive to the training sample size than others. A time limit helps to choose an algorithm, especially if a large sample of training samples is used.
Linearity
Many machine learning algorithms use linearity. Algorithms for linear classification suggest that classes can be divided by a straight line (or its more multidimensional analogue). Here we are talking about logistic regression and the support vector machine (in Azure machine learning). The linear regression algorithms assume that the distribution of data is described by a straight line *. These assumptions are suitable for solving a number of problems, but in some cases reduce accuracy.
Limiting non-linear classes — using a linear classification algorithm reduces accuracy
Data with nonlinear regularity - when using the method of linear regression, there are more serious errors than is permissible
Despite the shortcomings, linear algorithms are usually addressed first. They are simple with an algorithmic point of view, and learning is fast.
Number of parameters
Parameters are the levers with which data experts set up an algorithm. These are the numbers that influence the behavior of the algorithm, for example, error tolerance or the number of iterations, or differences in the behavior of the algorithm. Sometimes the learning time and the accuracy of the algorithm may vary depending on certain parameters. As a rule, a good combination of parameters for algorithms can be found through trial and error.
Also in Azure machine learning there is a modular parameter selection block that automatically tries all combinations of parameters with the level of detail you specify. Although this method allows you to try out a lot of options, but the more parameters, the more time is spent on training the model.
Fortunately, if there are a lot of parameters, this means that the algorithm is highly flexible. And with this method you can achieve excellent accuracy. But provided that you manage to find a suitable combination of parameters.
The number of signs
In some types of data attributes can be much more than objects. This usually happens with data from genetics or textual data. A large number of signs hinder the work of some learning algorithms, because of which the learning time is incredibly stretched. The support vector method is well suited for such cases (see below).
Special cases
Some learning algorithms make assumptions about the data structure or the desired results. If you manage to find a suitable option for your purposes, it will bring you excellent results, more accurate predictions or shorten the training time.
Algorithm properties:
• - demonstrates excellent accuracy, short training time and the use of linearity.
○ - demonstrates excellent accuracy and average learning time.
| Algorithm | Accuracy | Studying time | Linearity | Options | Note |
|---|---|---|---|---|---|
| Two class classification | |||||
| Logistic regression | • | • | five | ||
| Forest of decision trees | • | ○ | 6 | ||
| Jungle making trees | • | ○ | 6 | Low memory requirements | |
| Improved decision tree | • | ○ | 6 | High memory requirements | |
| Neural network | • | 9 | Additional configuration is possible. | ||
| Single layer perceptron | ○ | ○ | • | four | |
| Support Vector Machine | ○ | • | five | Good for large feature sets. | |
| Local Depth Methods of Support Vectors | ○ | eight | Good for large feature sets. | ||
| Bayesian methods | ○ | • | 3 | ||
| Multi-class classification | |||||
| Logistic regression | • | • | five | ||
| Forest of decision trees | • | ○ | 6 | ||
| Jungle making trees | • | ○ | 6 | Low memory requirements | |
| Neural network | • | 9 | Additional configuration is possible. | ||
| One against all | - | - | - | - | See the properties of the selected two-class method. |
| Multi-class classification | |||||
| Regression | |||||
| Linear | • | • | four | ||
| Bayesian linear | ○ | • | 2 | ||
| Forest of decision trees | • | ○ | 6 | ||
| Improved decision tree | • | ○ | five | High memory requirements | |
| Rapid Quantile Regression Forests | • | ○ | 9 | Prediction of distributions, not point values | |
| Neural network | • | 9 | Additional configuration is possible. | ||
| Poisson | • | five | Technically logarithmic. To calculate forecasts | ||
| Ordinal | 0 | To predict the rating | |||
| Emission Filtration | |||||
| Support vector methods | ○ | ○ | 2 | Great for large feature sets | |
| Emission Filtering Based on Principal Component Method | ○ | • | 3 | Great for large feature sets | |
| K-medium method | ○ | • | four | Clustering algorithm | |
Algorithm Notes
Linear regression
As we have said, linear regression treats data linearly (either in the plane or in the hyperplane). This is a convenient and fast "workhorse", but for some problems it can be too simple. Here you will find a guide to linear regression.
Line Trend Data
Logistic regression
Let the word "regression" in the title does not mislead you. Logistic regression is a very powerful tool for two-class and multi-class classification. It's quick and easy. Since instead of a straight line, an S-shaped curve is used here, this algorithm is perfect for dividing data into groups. Logistic regression restricts the linear class, so you will have to accept linear approximation.
Logistic regression for two-class data with only one attribute — the class boundary is at the point where the logistic curve is close to both classes
Trees, forests and jungle
Decisive tree forests ( regression , two-class and multi-class ), decision tree jungle ( two-class and multi-class ), and improved decision-making trees ( regression and two-class ) are based on decision trees, the basic concept of machine learning. There are many variants of decision trees, but they all perform the same function - they subdivide the feature space into regions with the same label. These can be areas of one category or a constant value, depending on whether you are using a classification or regression.
The decision tree divides the feature space into areas with approximately the same values.
Since the feature space can be divided into small areas, this can be done so that there is one object in one area - this is a rough example of a false connection. To avoid this, large sets of trees are created so that the trees are not connected to each other. Thus, the “decision tree” should not produce false links. Decision trees can consume large amounts of memory. Decisive jungle trees consume less memory, but learning will take a little longer.
Improved decision trees limit the number of partitions and the distribution of data points in each area to avoid false links. The algorithm creates a sequence of trees, each of which corrects previously made errors. As a result, we get a high degree of accuracy without large memory costs. Full technical description, see the scientific work of Friedman .
Fast quantile regression forests are a variant of decision trees for those cases when you want to know not only the typical (average) value of data in a region, but also their distribution in the form of quantiles.
Neural networks and perception
Neural networks are learning algorithms that are based on the human brain model and are aimed at solving multi-class , two-class and regression problems. There are so many of them, but in Azure machine learning, neural networks take the form of directional acyclic graphics. This means that the input features are transmitted forward through a sequence of levels and turned into output data. At each level, the input data is measured in various combinations, summarized and transmitted to the next level. This combination of simple calculations allows you to study the complex class boundaries and data trends as if by magic. These multi-level networks provide “deep learning” that serves as an inspiration for technical reports and science fiction.
But such performance is not free. Learning neural networks takes a lot of time, especially for large data sets with many features. They have more parameters than most algorithms, and therefore the selection of parameters significantly increases the learning time. And for perfectionists who want to specify their own network structure , the possibilities are practically unlimited.
The boundaries studied by neural networks are complex and chaotic.
A single-layer perceptron is the response of neural networks to an increase in learning time. It uses a network structure that creates linear class boundaries. By modern standards, this sounds primitive, but this algorithm has been tested in practice for a long time and learns quickly.
Support vector methods
Support vector methods find a boundary that separates classes as widely as possible. When it is impossible to clearly separate the two classes, the algorithms find the best border. According to Azure machine learning, the two-class support vector machine method does this using a straight line (speaking the language of the support vector machine, it uses the linear core). Due to the linear approximation, the training is carried out fairly quickly. Of particular interest is the function of working with objects with a multitude of features, for example, text or a genome. In such cases, support vector machines can divide classes more quickly and are distinguished by a minimal probability of creating a false connection, and also do not require large amounts of memory.
Standard class boundary of a vector support machine increases the field between two classes.
Another product from Microsoft Research is two-class local depth support vector machine methods . This is a non-linear variant of support vector methods, which is distinguished by the speed and efficiency of memory inherent in the linear version. It is ideal for cases where the linear approach does not provide sufficiently accurate answers. To ensure high speed, developers break the problem into several small tasks of the linear support vector machine method. Read more about this in the full description .
By extending non-linear support vector vectors, a single-class support vector machine creates a boundary for the entire data set. This is especially useful for filtering outliers. All new objects that are not within the boundaries are considered unusual and therefore are carefully studied.
Bayesian methods
Bayesian methods have a very good quality: they avoid false connections. To do this, they make assumptions about the possible distribution of the answer. Also, they do not need to configure many parameters. Azure machine learning offers Bayesian methods for both classification ( Bayes' two-class classification ) and regression ( Bayesian linear regression ). It is assumed that the data can be divided or positioned along a straight line.
By the way, Bayes point machines were developed by Microsoft Research. In their foundation lies a magnificent theoretical work. If you are interested in this topic, read the MLR article and Chris Bishop’s blog (Chris Bishop) .
Special algorithms
If you are pursuing a specific goal, you are lucky. In the Azure machine learning collection, there are algorithms that specialize in rating forecasting ( order regression ), quantity forecasting ( Poisson regression ), and anomaly detection (one of them is based on the analysis of the main components and the other on support vector techniques ). And there is also a clustering algorithm ( k-means method ).
PCA-based anomaly detection — a huge amount of data falls under the stereotypical distribution; points that strongly deviate from this distribution fall under suspicion
The data set is divided into five clusters by the k-means method.
There is also a “one against all” multi-class classifier that breaks the problem of classifying an N-class into two-class problems of the N-1 class. Accuracy, training time and linearity properties depend on the two-class classifiers used.
Two two-class classifiers form a three-class classifier.
In addition, Azure offers access to a powerful machine learning platform called Vowpal Wabbit . VW refuses categorization because it can study the problems of classification and regression, and even learn from partially tagged data. You can choose any of the learning algorithms, loss functions and optimization algorithms. This platform is characterized by efficiency, the possibility of parallel execution and unsurpassed speed. It easily handles large data sets. VW was launched by John Langford (John Langford), a specialist from Microsoft Research, and is a Formula 1 car in the ocean of production cars. Not every problem is suitable for VW, but if you think that this is the right option for you, then the effort expended will certainly pay off. The platform is also available as a standalone open source code in several languages.
The latest materials from our blog on this topic.
1. Azure plain language (cheat sheet).
2. Trucks and refrigerators in the cloud (case).
We remind you that you can try Microsoft Azure here .
If you see an inaccuracy of the translation, please report this to private messages.
* UPD
Since there is an inaccuracy in the text of the author, we supplement the material (thanks to @fchugunov)
Linear regression is applied not only to determine the relationship, which is described by a straight line (or plane), as indicated in the article. Dependency can be described by more complex functions. For example, a polynomial regression method (a kind of linear regression) can be applied to a function on the second graph. For this, the input data (for example, the x value) is converted into a set of factors [x, x², x³, ..], and the linear regression method already selects the coefficients for them.
Source: https://habr.com/ru/post/317512/
All Articles