Asynchronous processing of requests in the database in memory, or how to cope with a million transactions per second on one core

Hello! In my last two articles I talked about how in-memory DBMSs ensure data integrity. You can find them here and here .
In this article I would like to touch on the performance problem of the DBMS in RAM. Let's start the performance discussion with the simplest use case, where the value simply changes according to a given key. For even greater simplicity, assume that the server part is missing, i.e. there is no client-server interaction over the network (it will be clear further why we did this). So, the DBMS (if you can call it that) is completely in the RAM of your application.
In the absence of a database server, you might have stored key-value pairs in a hash table in the memory of your application. In C / C ++, this data structure would look like this:
std::unordered_mapTo check the speed of this structure, I created a
1.cpp file with the following contents:')
#include <map> #include <unordered_map> #include <iostream> const int SIZE = 1000000; int main() { std::unordered_map<int,int> m; m.reserve(1000000); long long c = 0; for (int i = 0; i < SIZE;++i) c += m[i*i] += i; std::cout << c << std::endl; } Then I compiled it and ran:
g++ -std=c++11 -O3 1.cpp -o 1 MacBook-Air-anikin:Downloads anikin$ time ./1 and got the following result:
real 0m0.465s user 0m0.422s sys 0m0.032s What can be learned from this? My conclusions are:
- I love C / C ++.
- I love my good old MacBook Air (actually, no, because it works slower and slower, but this is a different story).
- I love to use the optimization flag
-O3. Some are afraid to use it, but in vain, because, otherwise, the performance will be bad. To demonstrate this, let's run this command:MacBook-Air-anikin:Downloads anikin$ g++ -std=c++11 1.cpp -o 1 MacBook-Air-anikin:Downloads anikin$ time ./1
And make sure that the result without-O3twice as bad:real 0m0.883s user 0m0.835s sys 0m0.033s - The application mostly worked in user mode. The short time spent in kernel mode was most likely spent on pre-allocating pages for the hash table (and
-O3, by the way, this time was not optimized), making the mmap system call and loading the executable file. - This application inserts approximately one million keys into a hash table. Here, the word roughly means that in fact there may be less than a million keys in the hash table due to repetitions caused by overflow when i * i is multiplied. Thus, the insertion of new data can turn into an update of existing data. However, exactly one million operations are performed on the hash table.
- The application inserts a million keys and shuts down in about half a second, i.e. it produces about two million inserts of key-value pairs per second.
The last observation is of particular interest. We can assume that you already have a storage engine of key-value pairs in RAM represented by
std::unordered_map , capable of performing two million operations per second on one core of such good old MacBook Air: MacBook-Air-anikin:Downloads anikin$ uname -a Darwin MacBook-Air-anikin.local 13.4.0 Darwin Kernel Version 13.4.0: Mon Jan 11 18:17:34 PST 2016; root:xnu-2422.115.15~1/RELEASE_X86_64 x86_64 Notice that I used integer keys and values. I could use strings, but did not do this simply because I did not want memory allocation and copying to affect the test results. Another argument against strings: when using
std::unordered_map<std::string, …> greater likelihood of collisions affecting performance.You can see that the hash table in RAM is capable of performing two million operations per second on one core, however, I recall, I was going to talk about the DBMS in RAM. What is the difference between a DBMS in RAM and a hash table in RAM? A DBMS is a server application, whereas a hash table is a library, i.e. A DBMS is a hash table plus something else. And this something else includes at least the server harness itself.
Let's create a server application based on
std::unordered_map<int, int> . A naive approach might look something like this:- Accept connections in the main thread.
- Create a new thread for each accepted connection (or start a pool of previously created threads).
- We protect
std::unordered_mapwith the help of some synchronization primitive (for example, a mutex). - Do not forget about data integrity - we write each update operation to the transaction log.
I would not like to bore you with the writing of the application code, so let's imagine that we have already done this. Take any database server arranged on the principle of a “separate thread for each connection” (MySQL, MariaDB, Postgres, etc.): at best, it can execute tens of thousands of queries per second on one core (16 or 32). nuclear server, it can be under a million operations per second). This is well known from various benchmarks. The best performance indicator among traditional DBMS that I managed to find on the network is about a million queries per second and is owned by MariaDB, which runs on a computer with 20 cores. Detailed calculations can be found here . By simple calculations we get 50 thousand requests per second per core. One of the best DBMS on the market, which is optimized by perhaps the best specialists in the world, processes only 50 thousand simplest queries (in fact, a search by key) per second on a single core.
50 thousand and two million - forty times the difference, when compared with
std::unordered_map . How do you like it? We just added a server to the data structure to provide other applications with remote access to it - and our performance dropped 40 times! (Once again, this is a benchmark with the simplest operations, everything is in the cache, the DBMS is tuned by the best experts in the world - and tuned to the maximum throughput, minimizing all the overheads that can be in the DBMS.) It is so discouraging that it seems it is better to forget about multi-tier architecture and write all business logic and DBMS logic in one application within one process. This, of course, was a joke. Better to try to optimize the database server.Let's look through the prism of system calls on what happens when a server with the above architecture processes a transaction:
- Reading a request from the network.
- Lock hash table.
- Unlocking the hash table.
- Transaction logging.
- Write to the network.
We get at least five system calls to the DBMS per request. Each call requires you to enter and exit kernel mode.
When entering the kernel mode and leaving it, the modes are switched, which entails a certain amount of work. Details can be read, for example, here . In addition, switching modes can cause context switching and lead to even greater copying and delays. More information about this can be found on the link .
To show you all the evils of system calls (understand me correctly, I love system calls, but they are slow, so I try not to abuse them), I wrote another program (in C):
#include <stdio.h> #include <fcntl.h> #include <unistd.h> int main() { int fd = open(“/dev/zero”, O_RDONLY); for (int i = 0; i < 1000000; ++i) { unsigned char c; if (read(fd, &c, 1) == -1) { fprintf(stderr, “error on read\n”); break; } } close(fd); return 0; } This program only produces a million byte reads from the
/dev/zero file. The test results are as follows: MacBook-Air-anikin:Downloads anikin$ time ./2 real 0m0.639s user 0m0.099s sys 0m0.495s First, the program spends almost all the time in kernel mode. Secondly, it makes about one and a half million system calls per second. Recall that the performance of the hash table was approximately two million operations per second. Curiously, the read system call is 30% slower than a search in a hash table. And this is with all the simplicity of this call: he did not access the disk or the network, but simply returned zeros.
As I wrote above, when using a database server for a single search operation in a hash table, there are at least five system calls. This means that we need at least 6.5 times longer (5 * 1.3 =) only for system calls! If you translate the situation into the tax plane, then the system calls are like an 85% tax. Would you be happy with the 85% payroll tax, i.e. if only you received 15 of the 100 rubles you earned? After thinking about it, let's go back to read , write and other system calls. They perform a wide range of tasks: reading from a network buffer, allocating memory blocks in the Linux kernel, searching for and modifying internal nuclear structures, etc. Therefore, more than 85% tax actually looks very small. To check how many system calls MySQL or any other traditional DBMS produces when processing a request, you can use the strace utility on Linux.
So, system calls are evil. Is it possible to abandon them altogether and transfer the entire logic of the DBMS to the core? Sounds good, but difficult. Perhaps there is a more practical solution. Look at the example below:
#include <stdio.h> #include <fcntl.h> #include <unistd.h> int main() { int fd = open(“/dev/zero”, O_RDONLY); for (int i = 0; i < 1000; ++i) { unsigned char c[1000]; if (read(fd, &c, 1000) == -1) { fprintf(stderr, “error on read\n”); break; } } close(fd); return 0; } The result is as follows:
MacBook-Air-anikin:Downloads anikin$ time ./2 real 0m0.007s user 0m0.001s sys 0m0.002s This program does exactly the same as the previous one - it copies a million bytes from the
/dev/zero file — however, its execution time is only 7 ms, which is almost 100 times faster than the previous result of 639 ms! How is this possible? The trick is that we reduce the number of system calls and increase the amount of work that each of them performs. It turns out that system calls are not so evil, if you properly load them with work. You pay a fixed price for a call - and then you can use them almost for free. This is similar to overseas amusement parks: paid once for an entrance ticket - and enjoy all day rides. Well, or a little less than the whole day: the cost of the ticket will remain unchanged, although in terms of a separate attraction will be a little more expensive.So, to speed up the database server, we need to make fewer system calls and perform more operations within each such call. How to achieve this? Let's just combine requests and their processing:
- Read 1000 requests from the network with one call to read .
- Lock the hash table.
- We process 1000 requests.
- Unlock the hash table.
- Write 1000 transactions to the log with one call to write / writev .
- We write 1000 responses in a network by means of one call write .
Wonderful! But wait a second, the DBMS usually does not process requests in batches (at least, if they don’t ask for it explicitly), it works online: as soon as a request arrives, the DBMS immediately processes it with the lowest possible delay. She cannot wait for the receipt of a packet of 1000 requests, because this may never happen.
How to solve this problem?
Let's look at public transport. There, this problem was solved in the last century (if not the year before). A bus ticket is cheaper than a taxi ride, because the bus has a higher capacity - and therefore the price of a trip per passenger is lower. However, the delay (waiting time) of the bus (or subway train, depending on the specific city) is about the same as that of a taxi in a busy center (I observed this pattern at least in New York, Moscow, Paris, Berlin and Tokyo). How it works?
The bottom line is that the bus never waits until there are a hundred people at the bus stop. Passengers at the bus stop are usually always sufficient, because the center is a busy part of the city (read: the workload is high). Thus, one bus stops, takes passengers (until the cabin is filled or until there is no one left at the bus stop) and leaves. Then the next bus comes up and again takes a sufficient number of passengers, because in the time elapsed between the departure of the first bus and the arrival of the second, new people appeared at the bus stop. The bus never waits for filling. He works with a minimum delay: there are people — he took it, he drove on.
In order for the DBMS to work in the same way, it is necessary to consider the network subsystem, the transaction processor and the disk subsystem as independent buses (or, if you prefer, subway trains). Each of these buses operates asynchronously with respect to the other two. And each of these buses takes as many passengers as there are at the bus stop. If there are not enough passengers - well, yes, the processor is used inefficiently, because buses with a high fixed cost of travel remain almost empty. On the other hand, what's the big deal? We perfectly cope with the existing load. The processor can be loaded up to 99% with 10 thousand requests per second, and with a million requests per second, but the response time will be equally good, because the number of system calls in both cases is the same. And this indicator is more important than the number of bytes transferred in one system call. The processor is always loaded, but it miraculously scales under load, remaining equally loaded with both large and small volumes of work performed. Let me remind you: the response time practically does not change, even if the number of operations performed in the system call will differ 100 times. The reason for this is the very high fixed price of a single system call.
How to implement all this in the best way? Asynchronously. Consider the example of the Tarantool DBMS:
- Tarantool has three streams: a stream for working with the network, a stream for processing transactions (we use the abbreviation TX , transaction processing , but do not ask why there is X, not P!), And a stream for working with a disk.
- The network stream reads requests from the network (how many can read from the network buffer without blocking I / O, whether it is one request, a thousand or more) and then transmits them to TX. He also receives responses from TX and writes them to the network, and he does this in one network packet no matter how many responses the packet contains.
- Stream TX groups processes in-memory transactions received from the stream to work with the network. Having processed one group of transactions in memory, it transfers it to the stream for working with the disk; at the same time, the groups are transferred one by one, regardless of how many transactions are in one group or another. It's like a crowd of people coming off the train and heading for the bus stop. The bus will pick up from the bus stop all the passengers to one. If someone did not have time to get to the bus stop before the departure of the bus, he will have to wait for the next one. The bus does not wait for a single extra millisecond: if there is no one else behind the last passenger, he sets off. After processing the group, the stream for working with the disk returns it to the TX stream so that it commits the transaction and returns all the queries contained in this group to the stream for working with the network.
In this way, we significantly reduced the number of system calls in Tarantool. The link can read more about how our system works and copes with a million transactions per second on one core.
The image below schematically shows the entire workflow:
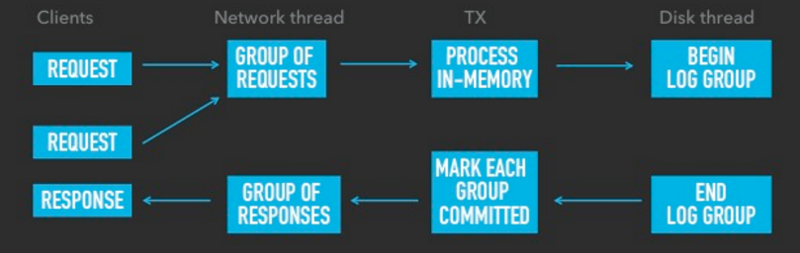
The main thing that you should pay attention to here is that each thread runs in parallel and does not interfere with the work of the remaining two. The more parallel and higher the load, the less system calls per request and the more requests the system can handle per second.
At the same time, we have a good response time, because the threads are not idle while waiting for other threads, but simply perform the work they currently have, and while this happens, a new batch of work is being prepared for them in parallel.
There will be more articles about the database in memory. Stay tuned!
All questions related to the content of the article can be addressed to the author of the original danikin , technical director of mail and cloud services Mail.Ru Group.
Source: https://habr.com/ru/post/317274/
All Articles