Implementation of PCI Express v3.0 x16 on FPGA Virtex 7

Computers have long had a PCI Express v3.0 x16 bus; Tests of modern video adapters show a speed of about 12 GB / s on this bus. I would like to make a module on the FPGA that has the same speed. However, the available FPGAs have a HARDWARE controller only for PCIe v3.0 x8; There are SOFT IP Core implementations, but they are very expensive. But there is a way out.
FPGA Virtex 7 VX330T has two controllers PCI Express v3.0 x8; The obvious solution is to place a switch that has an x16 connector on the side and two x8 buses that are connected to the FPGA. It turns out this structure:
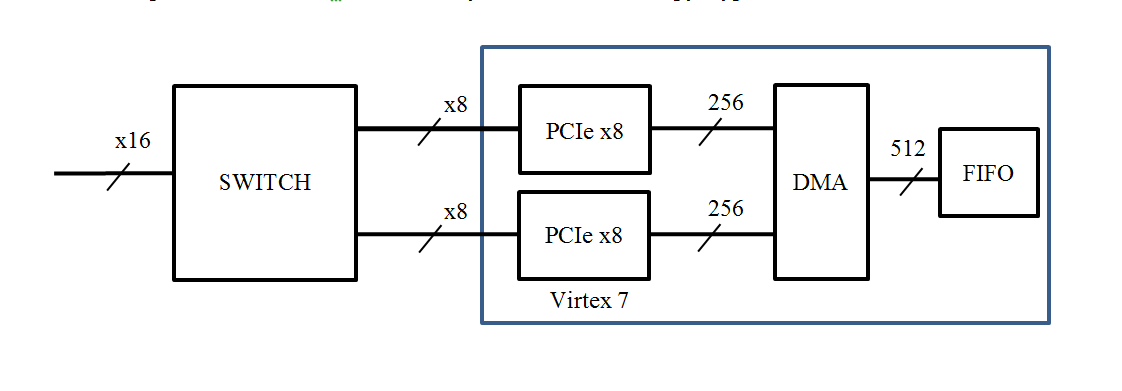
According to this scheme, the HighTechGlobal HTG-728 module was built.
')
Another way is Alpha-Data. The ADM-PCIE-KU3-X16 does not have a switch. But the x16 connector displays two x8 tires. In FPGA it is possible to implement two independent controllers. To do this, two reset signals and two reference frequencies are set on the FPGA. But this module will work only in special motherboards, where two x8 are also output to the x16 connector. I did not meet such motherboards, but apparently they are.
Our company made a decision on the implementation of the FMC122P module with an internal switch. The main task was to check the maximum exchange rate. Another equally important task is to achieve compatibility with existing software and FPGA components.
The PCI Express controller for Virtex 7 is radically different from the controller for Virtex 6, Kintex 7. It has become more convenient, but it is different. The figure shows the block diagram of the controller:

The controller has two parts Completer and Requester, each of which has two AXI_Stream buses. Through the node Completer come requests from the bus PCI Express. These requests are sent to the m_axis_cq bus. On the s_axis_cc bus, a response must come from the User’s component. This is usually the access point to the internal registers of the FPGA.
Through the Requester node, the DMA controller sends requests for the PCI Express bus over the s_axis_rq bus. Answers come through the m_axis_rc bus.
Tire simulation
The IP Core includes an example project by which you can understand how it works. The project is written in Verilog and, unfortunately, it can also serve as an example of how not to develop. Let's look at the block diagram of the example.
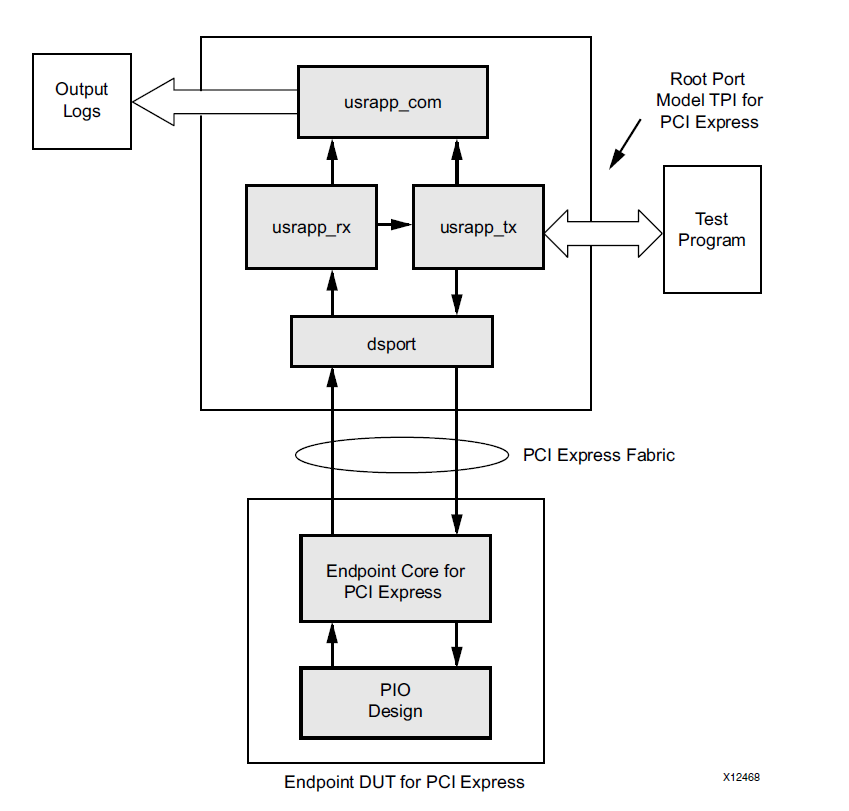
This diagram is taken from the description of IP Core. At first glance, everything is fine - this is a wonderful picture, it can be shown to managers, project managers, clients. Problems begin in implementation. In this system, there are a lot of places where Verilog features are used to access objects along the absolute path. In my opinion, in this system it is justified only in one place - this is a bypass of GTP nodes for modeling at the PIPE level. But to make the connection between userapp_tx and userapp_rx using absolute paths is completely unnecessary.
In the project it looks like this:
In the pci_exp_usrapp_tx component there is a TSK_SYSTEM_INITIALIZATION function which calls the function from pci_exp_userapp_cfg via an absolute path:
board.RP.cfg_usrapp.TSK_WRITE_CFG_DW (hereinafter I call the function that in Verilog is described through the task). We look at the pci_exp_userapp_cfg component that we see: cfg_ds_bus_number <= board.RP.tx_usrapp.RP_BUS_DEV_FNS [15: 8];
We look at the pci_exp_userapp_rc component, the same there: board.RP.com_usrapp.TSK_PARSE_FRAME (`RX_LOG);
This is not only not stylistically correct. This makes it difficult to apply the model in your project. Firstly, it is not at all necessary that the top-level file in your own project will be called board and the same hierarchy will remain there. Secondly, there may be two components. We have just happened both cases. I had to work with Verilog, although I didn’t like it at all. As it turned out, by a small permutation, the entire root_port component can be brought to a completely hierarchical form. The result was the component files:
- xilinx_pcie_3_0_7vx_rp_m2.v
- pci_exp_usrapp_tx_m2.v
- pci_exp_usrapp_cfg_m2.v
And files with functions:
- task_bar.vh
- task_rd.vh
- task_s1.vh
- task_test.vh
This made it possible to include two root_port components in the model. In the VHDL component, the inclusion of two root_port looks like this:
root_port
gen_rp0: if( is_rp0=1 ) generate rp0: xilinx_pcie_3_0_7vx_rp_m2 generic map( INST_NUM => 0 ) port map( sys_clk_p => sys_clk_p, sys_clk_n => sys_clk_n, sys_rst_n => sys_rst_n, -- cmd_rw => cmd_rw, -- -: 0 - , 1 - cmd_req => cmd_req, -- 1 - cmd_ack => cmd_ack, -- 1 - cmd_adr => cmd_adr, -- - cmd_data_i => cmd_data_i, -- cmd_data_o => cmd_data_o, -- cmd_init_done => cmd_init_done_0 -- 1 - ); end generate; gen_rp1: if( is_rp1=1 ) generate rp1: xilinx_pcie_3_0_7vx_rp_m2 generic map( INST_NUM => 1 ) port map( sys_clk_p => sys_clk_p, sys_clk_n => sys_clk_n, sys_rst_n => sys_rst_n, cmd_init_done => cmd_init_done_1 -- 1 - ); end generate; The rp0 component is used to write or read 32-bit words. The rp1 component only performs initialization.
Unfortunately, this has been modeled for a very long time, even if the modeling is done at the PIPE level. A typical simulation session is about ten minutes (and maybe more, I don’t remember). For operational work with DMA channel is not suitable. In this situation, a completely natural decision was made to remove the PCI Express controller from the model. Especially since it has already been studied.
Block diagram of the controller
The generalized diagram of the controller is shown in the figure.
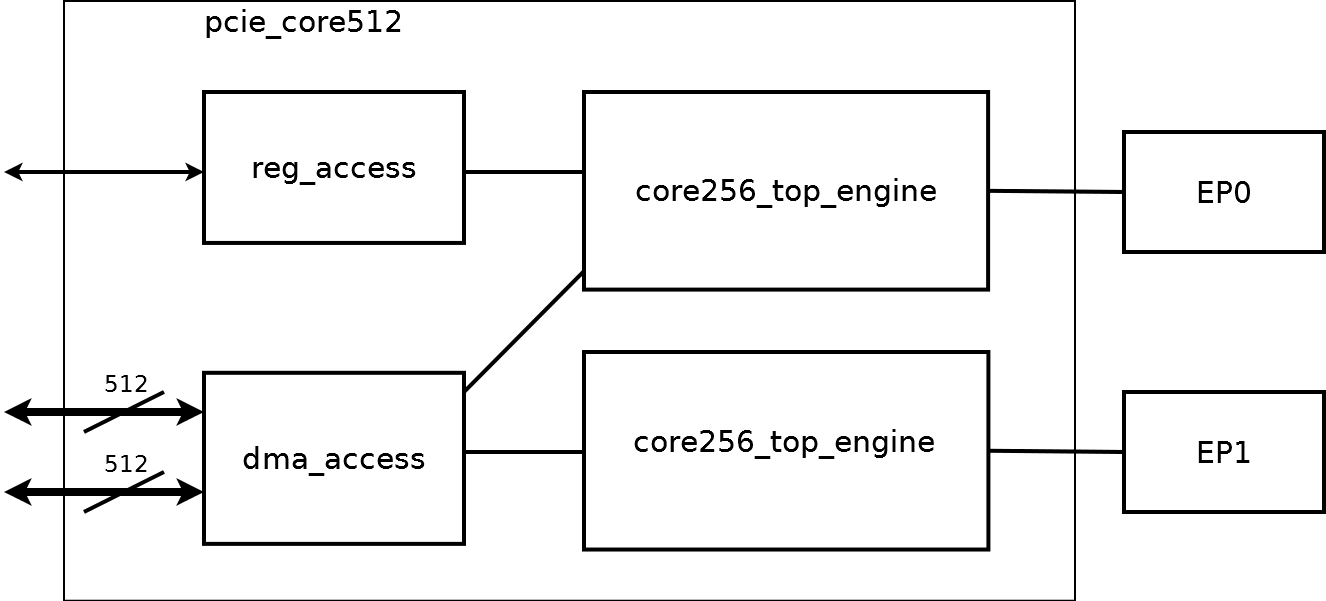
Two identical core256_top_engine components provide access to two EP0, EP1 controllers. core256_top_engine provides access to the registers from the side of PCI Express, for this purpose only EP0 and the reg_access component are used. The dma_access component contains the main control logic of the controller. Its block diagram is shown below:
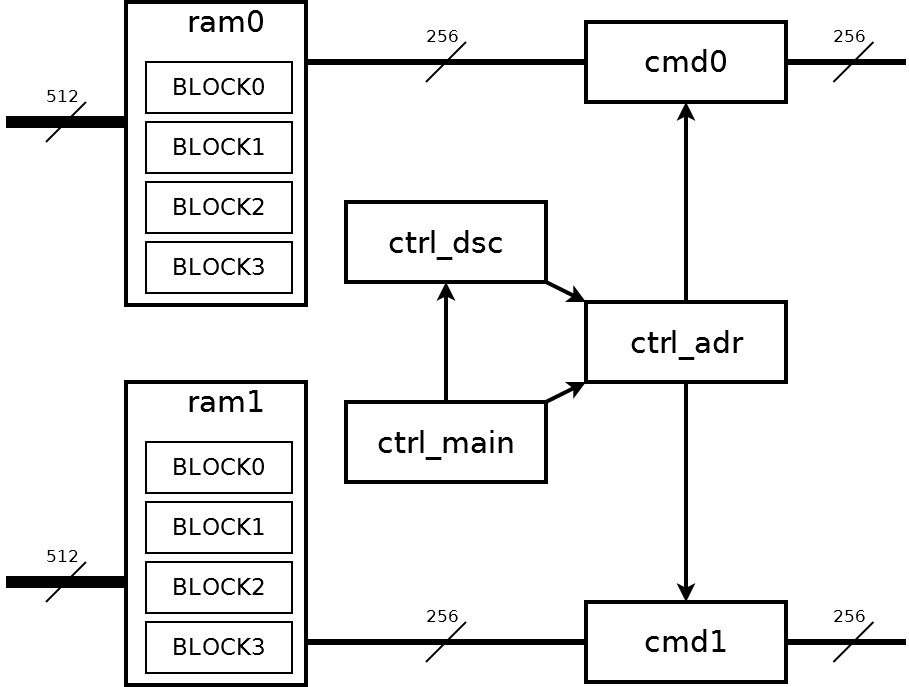
Everything is controlled by the ctrl_main node. The ctrl_dsc node contains a block of descriptors. The ctrl_adr node converts a descriptor into a sequence of addresses of four-kilobyte blocks. Addresses are sent to the cmd0 and cmd1 nodes for exchange with the core256_top_engine nodes;
From the user part of the FPGA there are two tires 512 bits wide. But the data on these buses should be transmitted in blocks of 4 kilobytes and strictly in turn. This is required for alternately filling the ram0, ram1 memory nodes. Each memory node contains four blocks of 4 kilobytes. On these nodes, the memory splits the source stream with a width of 512 bits into two streams of 256 bits each. In the future, two streams of 256 bits are already completely independent. The stream data will be found only in the computer’s RAM, where it will be located at the neighboring addresses.
Dma_access simulation
The dma_access node is the most complex part of the controller. Accordingly, it must be modeled very carefully. As I wrote above, modeling two PCI Express cores is very long. For acceleration, a model has been developed which is connected instead of core256_top_engine. For dma_access, the same interface remained, and the simulation speed increased by an order of magnitude. In this project, as well as in the PROTEQ project, automatic start of tests through the tcl file is used.
Here is a fragment of the tcl file:
run_test "stend_m4" "test_read_8kb " 6 "50 us" run_test "stend_m4" "test_read_16kb " 7 "100 us" run_test "stend_m4" "test_read_49blk " 8 "150 us" run_test "stend_m4" "test_read_8x4_cont " 9 "150 us" run_test "stend_m4" "test_read_128x1_cont " 12 "200 us" run_test "stend_m4" "test_read_16kbx2 " 13 "150 us" run_test "stend_m4" "test_read_step " 14 "200 us" run_test "stend_m4" "test_read_8kb_sg_eot " 15 "100 us" run_test "stend_m4" "test_read_64x1 " 16 "100 us" This is an automatic launch of nine tests. For example, here’s one test code:
test_read_4kb
procedure test_read_4kb ( signal cmd: out bh_cmd; --! signal ret: in bh_ret --! ) is variable adr : std_logic_vector( 31 downto 0 ); variable data : std_logic_vector( 31 downto 0 ); variable str : line; variable L : line; variable error : integer:=0; variable dma_complete : integer; variable data_expect : std_logic_vector( 31 downto 0 ); begin write( str, string'("TEST_READ_4KB" )); writeline( log, str ); ---- --- for ii in 0 to 127 loop adr:= x"00100000"; adr:=adr + ii*4; int_mem_write( cmd, ret, adr, x"00000000" ); end loop; int_mem_write( cmd, ret, x"00100000", x"00008000" ); int_mem_write( cmd, ret, x"00100004", x"00000100" ); -- int_mem_write( cmd, ret, x"00100080", x"00008000" ); -- int_mem_write( cmd, ret, x"00100084", x"00000100" ); int_mem_write( cmd, ret, x"001001F8", x"00000000" ); int_mem_write( cmd, ret, x"001001FC", x"762C4953" ); ---- DMA ---- block_write( cmd, ret, 4, 8, x"00000025" ); -- DMA_MODE block_write( cmd, ret, 4, 9, x"00000010" ); -- DMA_CTRL - RESET FIFO block_write( cmd, ret, 4, 20, x"00100000" ); -- PCI_ADRL block_write( cmd, ret, 4, 21, x"00100000" ); -- PCI_ADRH block_write( cmd, ret, 4, 23, x"0000A400" ); -- LOCAL_ADR block_write( cmd, ret, 4, 9, x"00000001" ); -- DMA_CTRL - START wait for 20 us; block_read( cmd, ret, 4, 16, data ); -- STATUS write( str, string'("STATUS: " )); hwrite( str, data( 15 downto 0 ) ); if( data( 8 )='1' ) then write( str, string'(" - " )); else write( str, string'(" - " )); error := error + 1; end if; writeline( log, str ); if( error=0 ) then ---- DMA ---- dma_complete := 0; for ii in 0 to 100 loop block_read( cmd, ret, 4, 16, data ); -- STATUS write( str, string'("STATUS: " )); hwrite( str, data( 15 downto 0 ) ); if( data(5)='1' ) then write( str, string'(" - DMA " )); dma_complete := 1; end if; writeline( log, str ); if( dma_complete=1 ) then exit; end if; wait for 1 us; end loop; writeline( log, str ); if( dma_complete=0 ) then write( str, string'(" - DMA " )); writeline( log, str ); error:=error+1; end if; end if; for ii in 0 to 3 loop block_read( cmd, ret, 4, 16, data ); -- STATUS write( str, string'("STATUS: " )); hwrite( str, data( 15 downto 0 ) ); writeline( log, str ); wait for 500 ns; end loop; block_write( cmd, ret, 4, 9, x"00000000" ); -- DMA_CTRL - STOP write( str, string'(" : " )); writeline( log, str ); data_expect := x"A0000000"; for ii in 0 to 1023 loop adr:= x"00800000"; adr:=adr + ii*4; int_mem_read( cmd, ret, adr, data ); if( data=data_expect ) then fprint( output, L, "%r : %r - Ok\n", fo(ii), fo(data)); fprint( log, L, "%r : %r - Ok\n", fo(ii), fo(data)); else fprint( output, L, "%r : %r : %r - Error \n", fo(ii), fo(data), fo(data_expect)); fprint( log, L, "%r : %r : %r - Error \n", fo(ii), fo(data), fo(data_expect)); error:=error+1; end if; data_expect := data_expect + 1; end loop; -- block_write( cmd, ret, 4, 9, x"00000010" ); -- DMA_CTRL - RESET FIFO -- block_write( cmd, ret, 4, 9, x"00000000" ); -- DMA_CTRL -- block_write( cmd, ret, 4, 9, x"00000001" ); -- DMA_CTRL - START fprint( output, L, "\nTest time: %r \n", fo(now) ); fprint( log, L, "\nTest time: %r \n", fo(now) ); -- -- writeline( log, str ); if( error=0 ) then write( str, string'("TEST finished successfully" )); cnt_ok := cnt_ok + 1; else write( str, string'("TEST finished with ERR" )); cnt_error := cnt_error + 1; end if; writeline( log, str ); writeline( log, str ); -- -- writeline( output, str ); if( error=0 ) then write( str, string'("TEST finished successfully" )); else write( str, string'("TEST finished with ERR" )); end if; writeline( output, str ); writeline( output, str ); end test_read_4kb The int_mem_write commands provide an entry in the computer's RAM HOST. In this test a block of descriptors is written there. The block_write and block_read commands provide access to the DMA registers of the controller. The controller is programmed, started and completed the exchange. After that, the int_mem_read commands read and check the received data. The code of this test almost completely coincides with the test from the PCIe_DS_DMA controller, which I published as an open source project on opencores.org; In comparison with the original, a check of the received data is added.
Logical controller organization
At the register level, the controller completely repeats our previous controllers for the FPGA Virtex 4, Virtex 5, Virtex 6, Kintex 7; The organization can be found in the project PCIe_DS_DMA.
A feature of all controllers is the integration of single descriptors into a block of descriptors. This gives a dramatic increase in speed when using fragmented memory.
Connection to tetrad
For us it is important to connect this controller to our tetrad. What is tetrad I wrote in a previous article: "ADM Interface: What is a tetrad . " Working with a 512-bit bus required a change in approach. To connect the tetrad I had to use an additional repacker node. The structural diagram is shown in the figure.
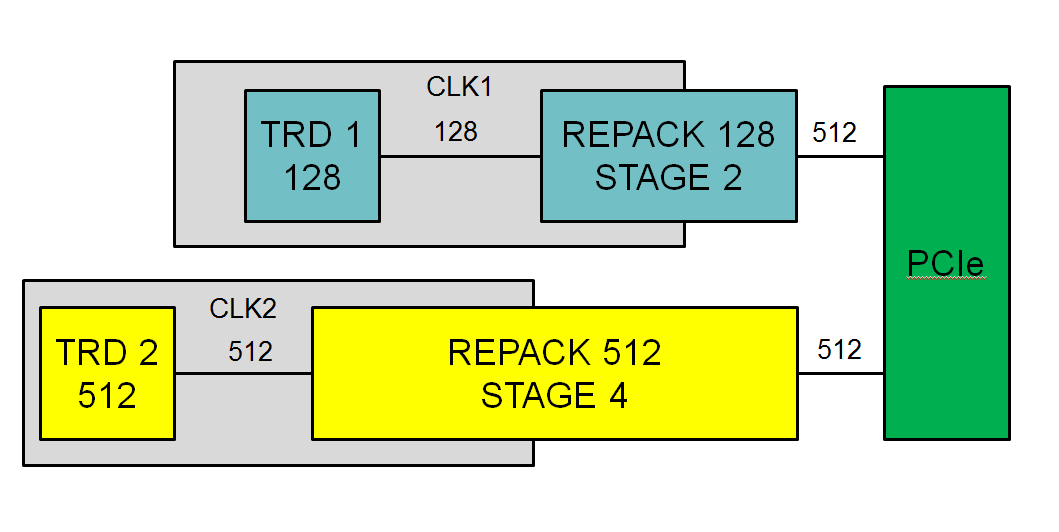
The repacker solves two problems:
- trace of the bus across the crystal, for this you can set the number of additional stages of the conveyor
- connection to tetradam with tires 64 and 128 bits
Memory usage
The ultimate goal of developing a controller and connecting to tetrad is to obtain a continuous stream of data from the ADC to a computer. And here we are faced with the fact that the PCI Express bus does not provide a stable speed. There may be delays on the tire. This is especially noticeable at high exchange rates. Delays occur due to the operation of other devices. The magnitude of the delay may be different, it may be 5 - 10 μs, and maybe more. A delay of 10 µs at a speed of 11 GB / s corresponds to a memory block of 110 kilobytes. For internal memory, even modern FPGAs are very much. But the delay may be more. If the data stream cannot be paused, and this is exactly the case when ADCs are used, the only way out is buffering in external memory. And the memory should be able to work at a speed of 22 GB / s. We have two SODIMM DDR3-1600 installed on the module. The memory runs at 800 MHz. This corresponds to a continuous data stream of 8400 MB / s. This figure is confirmed by experiment. I want to note that the speed of 8400 MB / s exceeds the speed of data output from our fastest submodule in which two ADCs are installed at 1800 MHz.
Tracing
The screenshot shows the result of tracing in the PlanAhead program:

The image shows two PCI Express controllers (highlighted in yellow and green) and two memory controllers (next to PCI Express).
As it turned out, such a project is very difficult for Vivado, it copes with it very badly. The project in Vivado divorces badly and often just does not work. ISE shows much more stable results. PCI Express nodes are divorced in accordance with the recommendations of Xilinx, while it turned out that they are spaced apart by crystal. And this already creates a problem for sharing other multi-gigabit lines.
results
The module was tested on several computers. The results are quite interesting.
| Intel Core i7 4820K | P9X79 WS | DDR3-1866 | 11140 MB / s |
|---|---|---|---|
| Intel Core i7 5820K | X99-A | DDR4-2400 | 11128 MB / s |
| Intel Core i7 3820K | P9X79 | DDR3-1600 | 11120 MB / s |
This is the data entry speed without verification. The data is continuously entered into a 1 GB buffer allocated in the system memory area, i.e., continuous by physical addresses. The average input rate is measured over an interval of at least 1 minute.
On a computer with DDR3-1600 memory, when the scan is turned on, the speed drops to 8500 MB / s.
On a computer with DDR3-1866, the speed with one module and the test enabled is not reduced.
Two FMC122P modules in a computer with DDR3-1866 without verification also show a maximum speed of about 11,000 MB / s for each module. But when you turn on the test speed drops.
With these measurements, it is assumed that 1 MB is 1024 KB, and 1 KB is 1024 bytes.
I would like to note that in this paper I present the result of the work of a large team. Special thanks to Dmitry Avdeev, who did a great job in this project.
PS While the development of Virtex 7 was outdated. Kintex Ultrascale is more convenient to use. And Kintex Ultrascale + already has a HARD PCI Express v3.0 x16 block - so this separation is no longer necessary.
PSS But Kintex Ultrascale + also has a HARD PCI Express v4.0 x8 block - can separation still come in handy?
Source: https://habr.com/ru/post/317194/
All Articles