How to avoid jumps in response time and memory consumption when taking state snapshots in a DBMS in RAM

Remember my recent article “What is a DBMS in RAM and how does it effectively store data” ? In it, I gave a brief overview of the mechanisms used in the in-memory DBMS to ensure data integrity. It was about two main mechanisms: logging transactions and taking snapshots. I gave a general description of the principles of working with the transaction log and only touched on the subject of images. Therefore, in this article about the snapshots, I will tell you more thoroughly: I will start with the simplest way to take state snapshots in the DBMS in memory, highlight several problems associated with this method and dwell in detail on how this mechanism is implemented in Tarantool .
So, we have a DBMS that stores all data in RAM. As I mentioned in my previous article, to take a snapshot it is necessary to write all this data to disk. This means that we need to go through all the tables and all the rows in each table and write it all to disk in one file via the write system call. Pretty simple at first glance. However, the problem is that the data in the database is constantly changing. Even if you freeze data structures when taking a snapshot, you can end up with a non-consistent state of the database on the disk.
How to achieve a consistent state? The easiest (and coarsest) way is to pre-freeze the entire database, take a snapshot of the state and defreeze it again. And it will work. The database may remain frozen for quite some time. For example, with a data size of 256 GB and a maximum hard disk performance of 100 MB / s, taking a snapshot will take 256 GB / (100 MB / s) - approximately 2560 seconds, or (again, approximately) 40 minutes. The DBMS will still be able to process read requests, but will not be able to fulfill data change requests. “What, seriously?” You exclaim. Let's calculate: at 40 minutes of downtime, say, on a day, the DBMS is fully operational 97% of the time at best (in fact, of course, this percentage will be lower, because many other factors will affect the duration of downtime).
What options can there be? Let's take a closer look at what is happening. We froze all the data just because it was necessary to copy it to a slow device. And what if you sacrifice memory to increase speed? The point is this: we copy all the data into a separate area of RAM, and then write the copy to a slow disk. This method seems to be better, but it entails at least three problems of different degrees of seriousness:
')
- We still need to freeze all data. Suppose we copy data to the memory area at a speed of 1 GB / s (which is again too optimistic, because in reality the speed can be 200-500 MB / s for more or less advanced data structures). 256 GB / (1 GB / s) is 256 seconds, or about 4 minutes. We get 4 minutes of downtime per day, or 99.7% of the time the system is available. This, of course, is better than 97%, but not by much.
- As soon as we copied the data to a separate buffer in RAM, we need to write them to disk. While the copy is being recorded, the original data in memory continues to change. These changes need to be monitored somehow, for example, saving the transaction identifier with a snapshot so that it is clear which transaction got into the snapshot last. There is nothing difficult in this, but nevertheless it is necessary to do it.
- Doubles the requirements for RAM. In fact, we constantly need memory twice the size of the data; I emphasize: not only to take snapshots, but constantly , because you can't just increase the amount of memory in the server, take a picture, and then pull out the memory bar again.
One way to solve this problem is to use the copy-on-write mechanism (hereinafter, for brevity, I will use the English abbreviation COW , from copy-on-write ) provided by the fork system call. As a result of this call, a separate process is created with its own virtual address space and a read-only copy of all the data. A read-only copy is used because all changes occur in the parent process. So, we create a copy of the process and slowly write the data to disk. The question remains: what is the difference from the previous copying algorithm? The answer lies in the COW mechanism itself, which is used in Linux. As mentioned a little above, COW is an abbreviation meaning copy-on-write, i.e. copy on write. The essence of the mechanism is that the child process initially uses page memory in conjunction with the parent process. As soon as one of the processes changes any data in the RAM, a copy of the corresponding page is created.
Naturally, copying the page leads to an increase in response time, because, in addition to the actual copy operation, a few more things happen. Typically, the page size is 4 KB. Suppose you change a small value in the database. First, an interruption occurs due to the absence of a page , since after calling fork, all pages of the parent and child processes are read-only. After that, the system switches to kernel mode, allocates a new page, copies 4 KB from the old page, and returns to user mode again. This is a very simplified description, more information about what is actually happening can be read here .
If the change affects not one, but several pages (which is very likely with data structures such as trees), the above sequence of events will be repeated again and again, which can significantly degrade the performance of the DBMS. With high loads, this can lead to a dramatic increase in response time and even short downtime; In addition, a large number of pages will be arbitrarily updated in the parent process, as a result of which almost the entire database can be copied, which, in turn, can lead to a doubling of the required amount of RAM. In general, if you are lucky, it will do without jumps in response time and database downtime, but if not, get ready for both; Oh yes, and do not forget about the double consumption of RAM too.
Another problem with fork is that this system call copies the page descriptor table . Say, when using 256 GB of memory, the size of this table can reach hundreds of megabytes, so your process may hang for a second or two, which again will increase the response time.
Using fork , of course, is not a panacea, but so far this is the best that we have. In fact, some popular in-memory DBMSs still use fork to take snapshots — for example, Redis .
Is it possible to improve something here? Let's take a closer look at the COW mechanism. Copying takes place there at 4 KB. If only one byte changes, the entire page is still copied (in the case of trees, there are many pages, even if rebalancing is not required). But what if we implement our own COW mechanism, which will copy only the actually changed parts of the memory, more precisely, the changed values? Naturally, such an implementation will not serve as a full-fledged replacement of the system mechanism, but will be used only for taking state snapshots.
The essence of the improvement is as follows: to make so that all our data structures (trees, hash tables, table spaces) can store many versions of each element. The idea is close to multi-version control of parallel access . The difference is that here this improvement is not used for the actual management of parallel access, but only for taking snapshots of the state. As soon as we started taking a snapshot, all data modification operations create a new version of the elements to be changed, while all old versions remain active and are used to create a snapshot. Look at the pictures below. This logic is valid for trees, hash tables and table spaces:
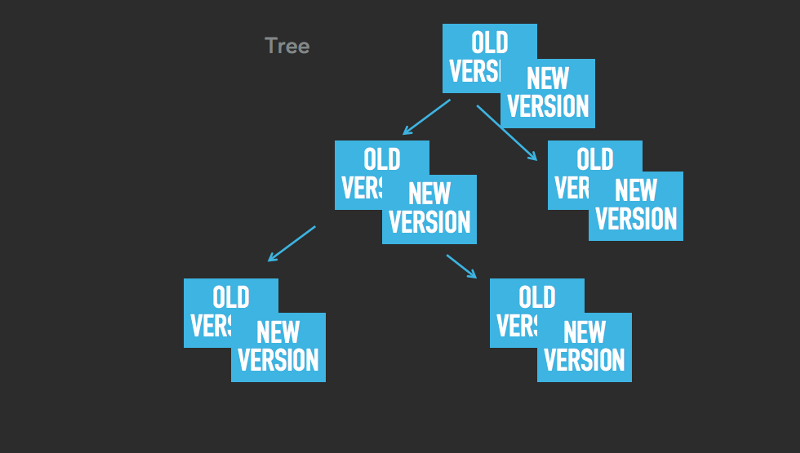
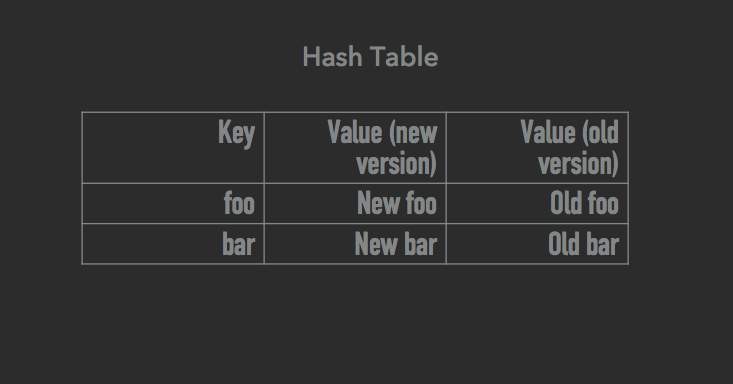

As you can see, elements can have both old and new versions. For example, in the last image in a tablespace, the values 3, 4, 5 and 8 have two versions (the old and the corresponding new one), while the rest (1, 2, 6, 7, 9) have one version.
Changes occur only in newer versions. Versions are more likely to be used for read operations when taking a snapshot. The main difference between our implementation of the COW mechanism and the system mechanism is that we do not copy the entire 4-KB page, but only a small part of the data that has been changed. Say, if you update a whole four-byte number, our mechanism will create a copy of this number, and only these 4 bytes will be copied (plus a few more bytes as a fee for maintaining two versions of one element). And now, for comparison, look at how the system COW behaves: 4096 bytes are copied, the page is interrupted, the context is switched (each such switch is equivalent to copying approximately 1 KB of memory) - and all this is repeated several times. Is it too much trouble to update just one whole four-byte number when taking a snapshot of the state?
We use our own implementation of the COW mechanism for taking snapshots in Tarantool since version 1.6.6 (before that, we used fork ).
New articles on this topic are coming up with interesting details and graphs from the working Mail.Ru Group servers. Follow the news.
All questions related to the content of the article can be addressed to the author of the original danikin , technical director of mail and cloud services Mail.Ru Group.
Source: https://habr.com/ru/post/317150/
All Articles