Formula of trust
Today we will talk about one of the key chips of our DLP-system - the level of trust. This is an indicator that is assigned to each person in the company and reflects the likelihood that the employee will be the violator.
Now analytics is coming to the fore in DLP solutions. A couple of years ago, all Russian vendors began gradually trying to “deploy” DLP systems from fighting leaks in order to identify and prevent other illegal actions of employees - fraud, kickbacks, collusion, etc. However, each person generates such amount of information per day that it is impossible to track the actions of each even in medium-sized companies, not to mention large business. Therefore, the ability of the system to make high-quality analytics in automatic mode and delineate the circle of persons “under suspicion” would be an obvious advantage. Thus, the idea of creating a level of trust arose, the main purpose of which was the transparency of the situation with internal threats in a company.
We wanted security personnel to quickly, without a long analysis of the data of the DLP system, understand who the company should take a closer look at. Very simple and elegant concept, right? It would seem that the idea lies on the surface. However, in order to create a formula of trust that would not cause a frantic number of false positives, it was necessary to do serious work and link the results of social engineering, statistics and business analysis into one whole. In this article we will discuss how to derive a formal expression of the magnitude of trust in employees in terms of protection against intentional or accidental leakage. Judging by the real statistics of the incidents taking place, this formula turned out to be quite accurate.
Some theory
The idea of automatic person profiling in DLP systems does not just hover in the air, but often appears in international standards and safety guidelines. But its implementation today has no generally accepted methodology. The natural way is to build such an indicator based on the analysis of a large amount of data (Big Data). In the language of Big Data technology, this problem is related to reputation and trust management (“Trust and reputation management” [1]).
')
By their nature, profiling refers to the field of behavioral analysis. From the point of view of business behavior, methods of modern psychology, physiology, and sociology are used here [2, 3].
The methods of mathematical statistics, random processes, statistical physics [4–9] are considered as a computing device. A separate branch of the models is based on the theory of neural networks [10, 11].
Formula of trust - accuracy and simplicity
Consultations with experts in the field of information security against leakage allowed us to single out the most effective among theoretical methods: sociology, mathematical statistics, business analysis. Even such a set of methods is very extensive, and their verification is very laborious, despite the fact that combining these methods is a fascinating exercise. Therefore, we began with the selection of the most appropriate techniques for our purpose. The main criteria for selection were accuracy and simplicity.
We decided that the best indicator of accuracy was how many people among the real intruders detected by the security officers, the system was able to automatically identify as potential violators. Thus, we compared the results of the work of a security officer and the calculations of various methods.
The second criterion, simplicity, is responsible for ensuring that there are no redundant variables (factors) in the trust level model. The fact is that each additional factor introduces uncertainty, as a result, the transparency of the result is lost. In other words, if the level of trust assigned to a person changes dramatically, it will be more difficult for a security officer to understand what caused these changes. This would nullify our efforts to achieve the main goal - to make the data of DLP-analytics as clear and transparent for the user as possible.
According to these criteria, the optimal algorithm was adopted, which was subsequently incorporated into the DLP system.
Initial data
We have a very extensive array of data on real security incidents. During each implementation and pilot project, reports on events and incidents are generated. These reports also contain information about offenders - personnel information, a list of events related to this employee, signs for placing a person at high risk.
As real data, there were data on incidents in 8 sectors:
- industry,
- IT & Telecom,
- government agencies
- energy,
- banks,
- oil and gas industry,
- trade and services
- transport.
Some measurable factors were also taken into account, including:
- volume of correspondence;
- the number of IS events and incidents;
- distribution of events according to groups of persons of special control;
- distribution of messages by communication channels;
- distribution of events by severity levels;
- the persons caught in the pilot or deployment report are real participants in the security incidents;
- other.
As a result, we chose three tools for creating a formula of trust - statistics, sociology, business specifics. These three "C" were supposed to provide us with a three-dimensional vision of the activity of employees.
“C” №1 - Statistics
As a statistical tool, we chose the traditional model of autoregression with an error in the form of white noise. This model allows you to choose the best line (law) on the graph of the factors taken into account. This model showed a good result on a number of similar tasks.
We began factor analysis by comparing the volume of the person's correspondence and the number of events found in this correspondence. Assuming that events linearly depend on the volume of correspondence, we obtain the following law of dependence of events on the number of messages:

The graph of the dependence function is indicated by a dotted line due to the fact that in a certain sense the “accuracy” of this law (R 2 value) is insufficient to consider this law to be somehow acceptable for all people. Usually for accuracy criteria, we take the lower threshold of this magnitude at 0.8.
The next step, which allows to make statistics, was the "blind" division of persons into groups. The dichotomous division - we divide all persons into 2 groups, and, if the accuracy of the model becomes sufficient, we accept such a partition. Otherwise, we divide each subgroup by another 2, and so on. In practice, 1-2 iterations are enough.
Statistical division into groups of people already at the first iteration gave convincing “accuracy” - more than 90%. Naturally, the question of the sufficiency of the sample size for such a conclusion is solved separately.
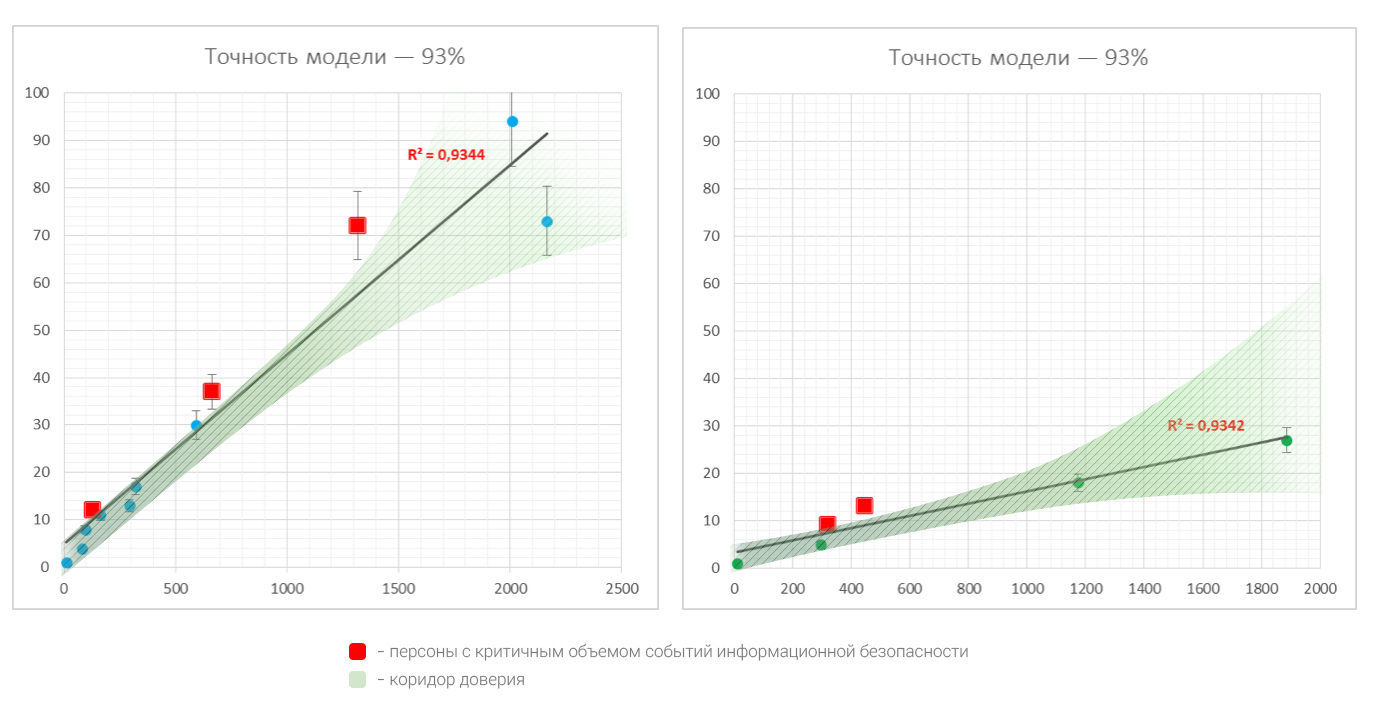
With a fairly good sample, the regression line (the law of dependence) can be used as a forecast for any person. And the deviations of persons from this law can be attributed to anomalies from the point of view of statistics.
Everything would be fine, but statistics that are not supported by business sense often give inappropriate results to the real state of affairs.
"C" №2 - Sociology
At the third stage, we somewhat adjusted our model. We needed to understand what binds people within each statistically allocated group. Therefore, it became necessary to search for features consistent with statistical partitioning. To do this, we used the methods of sociology and business analysis.
Monitoring of sociological research and their practical assessment were given by the following options for categories of people:
- negligent users;
- cautious users;
- advanced users;
Each group has its own pattern of behavior, which people unwittingly adhere to. At the same time, on the basis of each pattern of behavior, certain predictive threat models can be constructed. For example, the actions of users who are negligent with regard to the transfer and storage of data will incur a higher risk of accidental information being compromised, regardless of the communication channel. Cautious users, by contrast, are more likely to be a source of deliberate threats. Their activity usually affects communication channels that are not described in corporate rules.
Advanced users are familiar with the IT-infrastructure and are especially advanced in the modification, data substitution. This group requires special monitoring of workstations and used programs at the OS kernel level. Of interest are also the communications of advanced users and negligent users, since the former may take advantage of the insufficient information security competence of the latter. In the group of advanced users, cybersecurity incidents, avalanche events, events related to corporate workflow systems and databases are common.
"" №3 - Specificity of business
Regarding business factors, it is especially important to determine the degree of detail in order to avoid ineffectively complicating the model.
Of course, in the ideal case, the security officer has business process diagrams that involve commercially important data. In reality, this is extremely rare.
In these situations, it helps the DLP systems to determine the types of documents in the information flow and visualize their movement. At the same time, even during a short observation period, the accumulated information provides a clear picture of how data are transferred within the framework of a process. We have identified several groups of employees, including:
- persons approving documents;
- persons with privileged access rights;
- liable employees
- and some others.
From the point of view of labor characteristics, it is possible to distinguish persons in the following groups:
- outsourced employees, contractors;
- business active users;
- employees who are on probation or, on the contrary, who leave.
All these groups have certain features of working with information, and therefore require separate control. Thus, outsourced employees and business-active users differ not only in the volume of information security events generated, but also in communication channels.
A special position is used by a group of materially responsible employees. They are characterized by the predominance of events related to economic security events. In the field of accounting, some sectoral workflow is usually used, which can be successfully taken into account by the rules of the automated DLP system policies.
The final formula for the level of trust
During the evaluation of various models of the level of trust, it became clear that it should depend on:
- the number of events;
- risk groups, which include sources and senders of messages;
- the distribution of events by severity level - from low to high
Thus, the level of trust is a real-valued bounded function. You can formally define it like this:

where S is the number of events, GR n is the distribution of events on the set of risk groups, n is the dimension of GR n , D K is the distribution of events on the set of criticality levels, K is the number of criticality levels (in our case K = 5), t is the moment in question of time.
Using a model that takes into account these factors, we were able to automatically identify more than 60% of the total number of violators, independently identified by security officers during investigations and incident analyzes.
Such a result became a weighty argument in order to realize in practice a dynamic level of trust in a DLP solution.
Conclusion
Despite the fact that now the level of trust is working successfully and is one of the key elements of analytics in our DLP system, we are constantly working to improve the formula. Perhaps, sometime in the future, we will be able to write a continuation of this article entitled “How we made the formula of trust more precisely several times”.
Most likely, the development of technology will help and competition. While we are one of the DLP-vendors seriously playing on this field, however, as already mentioned at the beginning of the article, behavioral analysis is now in a trend, so surely soon other domestic developers will start looking in this direction as well.
Sources
- Omar Hasan, Benjamin Habegger, Lionel Brunie, Nadia Bennani, Ernesto Damiani. University of Lyon, Department of Computer Technology, University of Milan. A Big Data Techniques Case Study.
- George W. Fairweather, Louis G. Tornatzky. Experimental Methods for Social Policy Research.
- Long Jin, Yang Chen, Tianyi Wang, Pan Hui, Athanasios V. Vasilakos. Understanding User Behavior of Online Social Networks: A Survey // IEEE Communications Magazine September 2013.
- Lanouar Charfeddine Wadie Nasri. Banks 'Customer Intention of Customers' Using Internet Banking // International Journal of Innovations in the Digital Economy, 4 (1), 16-30, January-March 2013.
- Gunjan Mansingh & Lila Rao & Kweku-Muata Osei-Bryson & Annette Mills. Profiling internet banking users: a knowledge-based process model based approach // Springer Science + Business Media New York 2013.
- Rathindra Sarathy, Krishnamurty! Muralidhar. Evaluating Laplace Differential Privacy for Numeric Data // TRANSACTIONS ON DATA PRIVACY 4 (2011) 1 —17.
- Chang-Moo Lee. Criminal profiling and industrial security // Springer Science + Business Media New York 2014.
- Yanli Yu, Keqiu Li, Wanlei Zhou, Ping Li. Trust mechanisms in wireless networks: Attack analysis and countermeasures // Journal of Network and Computer Applications 35 (2012) 867–880.
- WT Luke Teacya, Michael Luckb, Alex Rogersa, Nicholas R. Jenningsa. Anatomical Approach to Trust and Reputation using Hierarchical Bayesian Modeling.
- Weihua Song, Vir V. Phoha. Neural Network-Based Reputation Model in Distributed System // Proceedings of the IEEE International Conference on E-Commerce Technology.
- Bo Zong, Feng Xu, Jun Jiao and Jian Lv. A Broker-Assisting Trust and Reputation System Based on the Artificial Neural Network // Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics.
I thank Solar-Alex for help in preparing the article.
Source: https://habr.com/ru/post/316980/
All Articles