Efficient storage: as we did from 50 Pb, 32 Pb
Video report
Text Version
Changes in the ruble exchange rate two years ago made us think about ways to reduce the cost of iron for Mail.Ru Mail. We needed to reduce the amount of iron purchased and the price for hosting. To find where to save, let's see what the mail consists of.

Indexes and letter bodies make up 15% of the volume, files - 85%. The place for optimizations should be searched for in files (attachments in letters). At that time, we did not implement file deduplication; according to our estimates, it can save up to 36% of the total mail volume: many users receive the same emails (social networks with pictures, stores with price lists, etc.). In this post I will talk about the implementation of such a system, made under the leadership of PSIAlt .
Meta Information Store
There is a stream of files, and you need to quickly understand whether the file is duplicated or not. A simple solution is to give them names that are generated based on the contents of the file. We use sha1. The original file name is stored in the letter itself, so no need to take care of it.
')
We received a letter, got the files, counted from the contents of sha1 and the value of the calculation added to the letter. This is necessary so that when you return a letter, it is easy to find its files in our future storage.
Now fill in the file. We are interested to ask the repository: do you have a file with sha1? This means that all sha1 should be stored in memory. Let's name the place for storage fileDB.
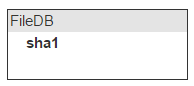
The same file may be in different letters; so we’ll keep a counter on the number of letters with such a file.
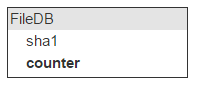
When you add a file counter increases. About 40% of files are deleted. Accordingly, when deleting a letter in which there are files uploaded to the cloud, it is necessary to reduce the counter. If it reaches 0, the file can be deleted.
Here we meet the first difficulty: information about the letter (indices) is in one system, and about the file - in another. This can lead to an error, for example:
- A request to delete a letter comes.
- The system raises the indexes of the letter.
- See that there are files (sha1).
- Sends a file delete request.
- There is a failure, and the letter is not deleted.
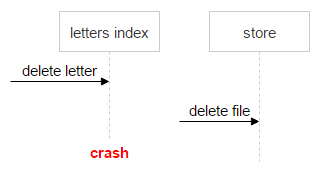
In this case, the letter remained in the system, and the counter decreased by one. When the second time comes the removal of this letter - we once again reduce the counter and get the problem. The file can be in one more letter, and its counter is zero.
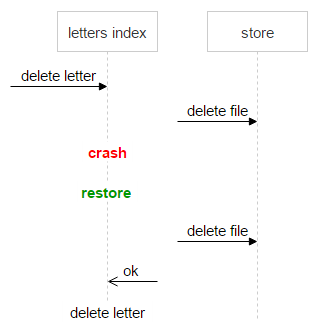
It is important not to lose data. We can not allow a situation when the user opens the letter, but the file is not there. At the same time, it is not a problem to store some extra files on the disks. It is enough to have a mechanism that clearly shows whether the counter is correct or not has gone down to zero. To do this, we have added another field - magic.
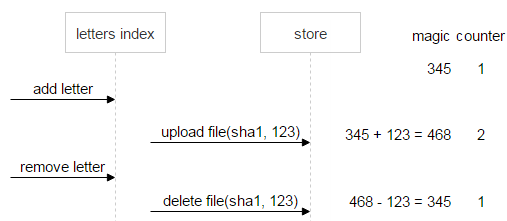
The algorithm is simple. In the letter together with sha1 from the file we generate and save one more arbitrary number. All requests for uploading or deleting a file are done with this number. If a request for a fill has arrived, then add this number to the stored magic. If on removal - we take away.
Thus, if all the letters have the correct number of times increased and decreased the counter, then the magic will also be equal to zero. If it is non-zero, the file cannot be deleted.
Let's look at this with an example. There is a sha1 file. It is filled once, and when you fill it, the letter generated a random number (magic) equal to 345 for it.

Now comes another letter with the same file. It generates its magic (123) and uploads the file. The new magic stacks with the old, and the counter is incremented by one. As a result, in FileDB, magic for sha1 is 468, and counter - 2.

The user deletes the second letter. The magic memorized in the second letter is subtracted from the current magic, counter is decremented by one.
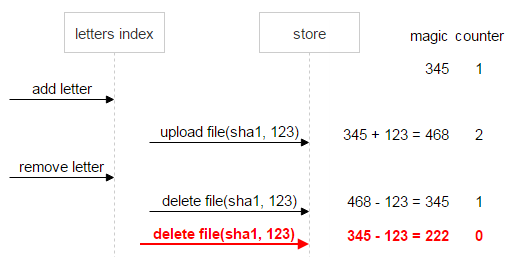
First, consider the situation where everything goes well. The user deletes the first letter. Then magic and counter will be equal to zero. This means that the data is consistent, you can delete the file.

Now suppose that something went wrong: the first letter sent two commands for deletion. Counter (0) indicates that there are no references to the file, however, magic (222) signals a problem: the file cannot be deleted until the data is brought to a consistent state.
Let's screw the situation to the end and assume that the first letter has been deleted. In this case, magic (–123) still speaks of inconsistency of data.
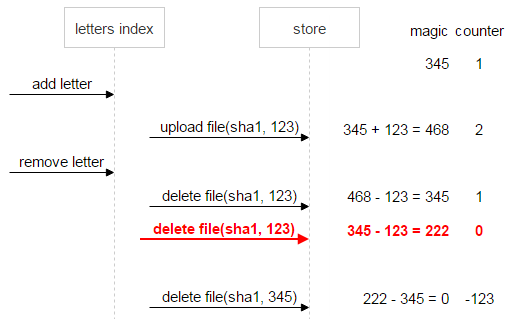
For reliability, immediately, as soon as the counter has become zero, and magic is not (in our case it is magic = 222, counter = 0), the “do not delete” flag is set for the file. So even if after a lot of additions and deletions by wild coincidence, magic and counter become equal to zero, we will still know that the file is problematic and cannot be deleted.
Let's go back to FileDB. Any entity has some flags. Whether you plan or not, they will be needed. For example, you need to mark a file as undeletable.
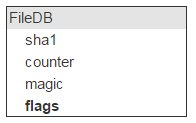
We have all the properties of the file, except for the main one: where it physically lies. This location identifies the server (IP) and disk. There should be two such servers with a disk.
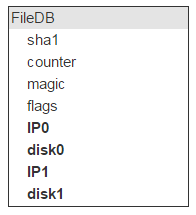
But there are many files on one disk (in our case, about 2,000,000). This means that these entries in FileDB will have the same disk pairs as storage locations. So storing this info in FileDB is wasteful. We bring it into a separate table, and in FileDB we leave the ID to indicate the entry in the new table.
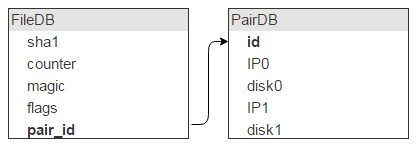
I think it is obvious that, in addition to such a description of the pair, we need another field flags. Looking ahead, I will say that the flags contain information that the disks are now locked, for example, one has flown out and the second is copied, so nothing new can be written on them.

We also need to know the amount of free space on each disk. We add these fields to the table.

For everything to work quickly, FileDB and PairDB must be in RAM. Take Tarantool 1.5. I must say that now you should use the latest version. In FileDB, there are five fields (20, 4, 4, 4, and 4 bytes each), for a total of 36 data bytes. Each record also contains a header of 16 bytes plus 1 byte for the length of each field. Total 57 bytes on one record turn out.

Tarantool allows you to set the minimum size for allocation in the config, so that you can reduce the amount of memory overhead to almost zero. We will allocate exactly as much as necessary under one record. We have 12 000 000 000 files.
(57 * 12 * 10^9) / (1024^3) = 637 Gb But that's not all, we need an index across the field sha1. And this is 12 more bytes to write.
(12 * 12 * 10^9) / (1024^3) = 179 Gb Total is about 800 Gb of RAM. But do not forget about the replica, which means × 2.

If we take cars with 256 Gb of RAM, then we will need eight cars.
We can estimate the size of pairdb. But the average file size is 1 MB and 1 Tb disks. This allows you to store about 1,000,000 files on disk. So, we need about 28,000 disks. One record in PairDB describes two disks, therefore, in PairDB 14,000 records. This is negligible compared to FileDB.
File upload
With the structure of the database figured out, now move on to the API for working with the system. Like the upload and delete methods are needed. But let us recall deduplication: it is possible that the file that we are trying to upload is already in the repository. It makes no sense to fill it a second time. Hence, the following methods will be required:
- inc (sha1, magic) - increase the counter. If there is no file, return an error. Remember that we still need magic. This will protect against incorrect file deletions.
- upload (sha1, magic) - it should be called if inc returned an error. This means that there is no such file and it is necessary to fill it.
- dec (sha1, magic) - called if the user deletes the letter. First we reduce the counter.
- GET / sha1 - just download the file via http.
Let us analyze what happens during the upload. For the daemon that implements this interface, we chose the iproto protocol. Demons must scale to any number of machines, so they do not store state. A socket request comes to us:

By the name of the command, we know the length of the title and read it first. Now the length of the origin-len file is important to us. It is necessary to pick up a couple of servers to fill it. Just pumping out the entire PairDB, there are only a few thousand entries. Next, we apply the standard algorithm for selecting the desired pair. We make a segment, the length of which is equal to the sum of the free places of all pairs, and randomly choose a point on the segment. Which pair got a point on the segment is the one chosen.

However, choosing a pair in such a simple way is dangerous. Imagine that all disks are 90% full and you have added an empty disk. With great probability, all new files will be poured onto it. To avoid this problem, you need to take to build a common segment not the free space of the pair, but the root of the Nth power of the free space.
We chose a couple, but our daemon is streaming, and if we started streaming the file to the storage, then there is no way back. Therefore, before uploading a real file, we first send a small test file. If the test file has been uploaded, then subtract from the filecontent socket and stream it to the storage. If not, choose another pair. Sha1 can be counted on the fly, so we also check it immediately upon pouring.
Consider now the file upload from loader to the selected disk pair. On machines with disks, we raised nginx and use the webdav protocol. The mail has arrived. This file is not yet in FileDB, which means that you need to upload it through a loader to a couple of disks.
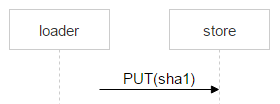
But nothing prevents another user from receiving the same letter: suppose the letter has two addressees. This file does not exist in FileDB yet; This means that another loader will upload the exact same file and can select the same pair.
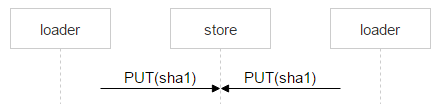
Most likely, nginx will solve the problem correctly, but we need to control everything, so we save the file with a complex name.
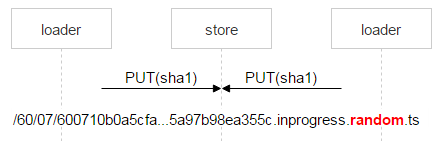
Red is the part of the name in which each loader writes a random number. Thus, the two PUTs do not intersect and upload different files. When nginx responded 201, the loader makes an atomic MOVE operation, indicating the final file name.
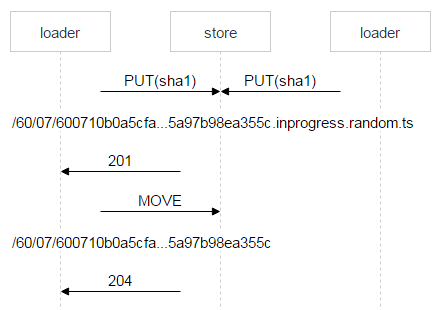
When the second loader completes its file and makes MOVE too, the file will be overwritten, but this is the same file - there will be no problems. When he will be on the disks, you need to add an entry to FileDB. Our tarantula is divided into two spaces. So far we only use zero.

However, instead of simply adding an entry for a new file, we use a stored procedure that either increments the file counter or adds an entry for the file. Why is that? During the time when the loader checked that the file is not in FileDB, uploaded it and went to add an entry, someone else could already upload this file and add an entry. Above, we considered just such a situation. One letter has two recipients, and two loaders began to fill it. When the second one finishes, it will also go to FileDB.
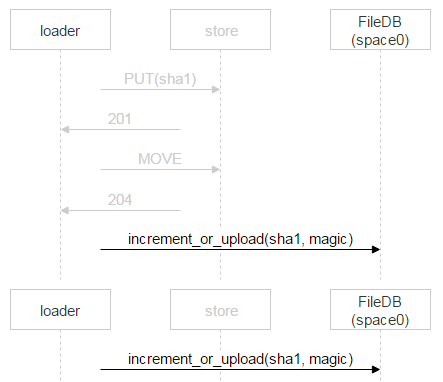
In this case, the second loader simply increments the counter.
We now turn to the procedure dec. For our system, two tasks are prioritized - guaranteed to write the file to disk and quickly give it to the client from disk. Physical file deletion generates a load on the disk and interferes with the first two tasks. Therefore, we transfer it offline. The dec procedure itself reduces the counter. If the latter is zero, like magic, then no one needs the file anymore. We transfer the record about him from space0 to space1 in a tarantula.
decrement (sha1, magic){ counter-- current_magic –= magic if (counter == 0 && current_magic == 0){ move(sha1, space1) } } Valkyrie
At each site we have a daemon Valkyrie, which monitors the integrity and consistency of the data, and it works with space1. One disk - one demon instance. The daemon enumerates the files on the disk one by one and checks if there is an entry about the file in space1, in other words - should it be deleted.
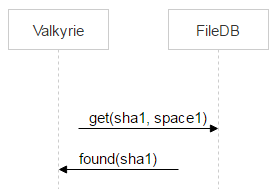
But time passes between transferring a file to space1 when performing the dec () operation and detecting the file by the valkyrie. So, between these two events, the file can be flooded again and again be in space0.
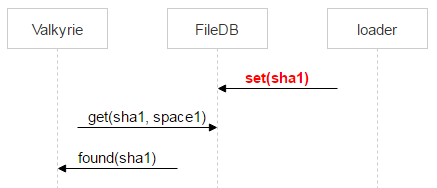
Therefore, Valkyrie immediately checks if the file has appeared in space0. If this happens and the record pair_id points to a pair of disks with which the current valkyrie works, then delete the record from space1.
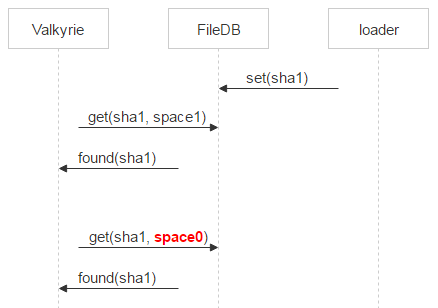
If there is no record, the file is a candidate for deletion. Yet there is a time gap between the request in space0 and the physical removal. Therefore, in this gap, again, there is the likelihood of an entry about the file in space0. Therefore, we quarantine the file.

Instead of deleting a file, rename it by adding in the name of the deleted and timestamp. That is, physically, we will delete the timestamp + file for some time specified in the config file. If a failure occurred and the file was decided to be deleted by mistake, the user will come for it. We will restore the file and correct the error without losing data.
Now we remember that there are two disks, each has its own Valkyrie. Valkyries do not synchronize with each other. The question arises: when to delete an entry from space1?
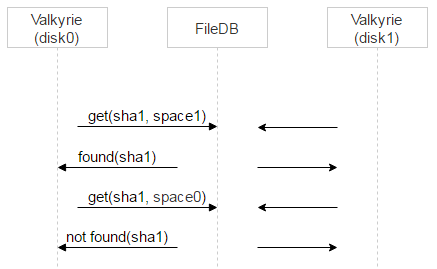
We do two things. First we assign one of the Valkyrie masters to a specific file. This is done very simply: on the first bit of the file name. If it is 0, then the master is disk0, if it is 1, then the master is disk1.

Now we will spread them in time. Recall that when a file entry is in space0, there is a magic field for consistency checking. When we transfer the record to space1, magic is not needed, so we write the timestamp of the transfer time into space1 into it. Now Valkyrie master will process the records in space1 immediately, and the slave will add a delay to the timestamp and process the records later + remove them from space1.
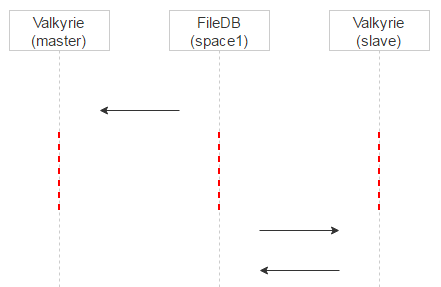
Due to this, we get another plus. If on the master the file went to quarantine by mistake, then when we request the master we will see it in the logs and figure it out. The client who requested the file, in the meantime, will fold on the slave, and the user will receive the file.
We looked at a case where Valkyrie finds a file on the disk named sha1 and this file (as a candidate for removal) has an entry in space1. Let's consider what other options are possible.
Example. The file is on disk, but there is no record about it in FileDB. If for some reason Valkyrie master did not work for some time in the above case, the slave managed to put the file into quarantine and delete the entry from space1. In this case, we also quarantine the file via sha1.deleted.ts.
Another example. There is a record, but it points to another pair. This can happen when uploading a file, if one letter is sent to two recipients. Let's remember the scheme.
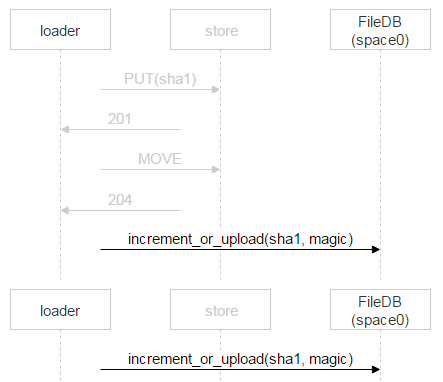
What happens if the second loader pours a file not on the same pair of disks as the first? It increments the counter into space0, but junk files will remain on a pair of disks where it went. We go to this pair and check that the files are read and sha1 matches. If everything is OK, then such files can be immediately deleted.
Valkyrie can also find the file in quarantine. If the quarantine has expired, the file is deleted.
Now Valkyrie stumbles upon a good file. It should be read from the disk and checked for integrity, compare with sha1. Then go to another disk of the pair and find out if there is a file there. A HEAD request is enough for this. The integrity of the file will be checked by the daemon running on that machine. If the integrity of the file on the current machine is violated, then it is immediately loaded from another disk. If there is no file on that disk, then upload it from the current disk to the second one.
It remains for us to consider the last case: problems with the disk. After monitoring, the admins understand that this has happened. They put the disk in the service (readonly) mode and on the second disk they start the razmuv procedure. All files from the second disk are scattered in other pairs.
Result
Let's go back to the beginning. Our mail looked like this:

After moving to a new scheme, we saved 18 Pb:

Mail began to occupy 32 PB (25% - indexes, 75% - files). The released 18 PB allowed us for a long time not to buy new hardware.
PS about sha1
Since there are a lot of questions in the comments, I will add here. Currently, there are no known, publicly calculated examples of the collision of SHA-1 itself. There are examples of collisions for initializing vectors for the compression function (SHA-1 freestart collision). The probability that a random collision occurs on 12 billion files is less than 10 ^ -38.
But suppose that is possible. In this case, when requesting a file by sha1, we will verify its size and crc32, which are stored in the indices of a particular letter when we fill it. Those. We will give the file only if it has been filled with this letter, or we will not give it back.
Source: https://habr.com/ru/post/316740/
All Articles