Using memcached and redis in high-load projects

Vyacheslav Moskalenko (Lenvendo)
I will tell you about the tools of high-load projects, caching, in particular, about memcached, Redis, and about the RabbitMQ queue service or in the common rabbit.
In the first part of the report, I will talk about what memcached is - the basic concepts, what Redis is, its features, and how these two services differ. I will tell about practical application in our projects of both services.
')
And in the second part I will talk about the message broker RabbitMQ, about the basic concepts that are in the "rabbit", about how the routing of messages between producers and consumers works. Also I will tell about practical application in our projects of this broker of messages.
About caching. I think many of you have cached at least something in your web projects, so everything will be very simple and accessible.
What is cache? This is an intermediary between the client who requests data, and the main, as a rule, slow, storage. Such an intermediary allows us to receive our data very quickly. As a rule, data is stored in RAM in the case of memcached and Redis. Efficient use of the cache allows us to reduce the load on our database servers.
The question arises - when and what should we cache? It is clear that it is useful to cache frequently requested data, i.e. if we have a small garden and there are 100 users per hour, then there will not be a large load on the base, and caching will be ineffective. Here, in large high-load projects, when we want to reduce the load on the database, we use the cache.
It is also necessary to understand what data we can / cannot cache. A simple example: when a user places an order in an online store, and we need to get the remaining goods from external systems, we have to do it online, because we cannot cache this data, because it may happen that the next user takes the data from the cache and there will be an error. Accordingly, only data that can be stored can be cached, for example, several hours, a day, etc.
The caching tools that will be discussed are memcached and Redis.
Let's start with the first. Memcached is a service for caching data in RAM with high performance. His story begins in 2003. Brad Fitzpatrick developed it for Livejournal, where it was successfully implemented and accelerated its service.
Opportunities of memcached: it is very fast, regardless of the amount of data that we store, it has a simple interface - you can set (set) data, you can get it, after a lifetime, you can delete the key, etc .; memcached supports atomic operations - incr / decr, append / prepend; allows you to easily expand the number of servers, and even the fall of one of the servers is simply calculated as a cache non-hit, i.e. there is simply no data in the cache.
The limitations of memcached: the key length is a maximum of 250 bytes, the amount of data that can be stored under one key is limited to 1 MB. Loss of keys in memcached can occur in a lifetime, by a memory limit, or in the event of server failure.
Since I am a PHP programmer, I gave an example of how to use memcached in PHP.

For PHP, there are 2 extensions - one uses the libmemcached library, and the second is just the php-memcache extension. Libmemcached has more opportunities to implement data, by default it serializes it using PHP, but you can define a JSON serializer, for example. We create a memcached object, we add our server to the localhost, the default port is 11211. We can add a string, set an array as a turnkey array, set the lifetime, when the data should be swelled. With a simple get operation, we get our data. Those. nothing complicated. Ask your system administrators, who have not yet used it, to install memcached, a php extension, to write their literacy wrapper for memcached, and to use frequently cached data for caching that loads your database and which can be cached.
Next, I will talk about what Redis is, how it differs from memcached.
Redis has support for a large number of data types, including strings, hashes, lists, sets, and sorted sets. Also Redis can periodically dump its data to disk - after, for example, thousands of updates of our data can be dropped all of it to disk. Redis supports LRU cleansing, there you can define different key cleaning strategies, you can randomly, for example, clear, you can not use them for a long time, or delete only those keys that have a lifetime, etc. You can also make sure that he doesn’t clear his memory at all, but then when you update the data, your Redis client will generate an error. It is better to let it clear the most unused data.
Redis supports master-slave replication, supports simple queues, i.e. can create channels, subscribe to them, publish in them some messages, read. It supports transactions using the MULTI / EXEC command, LUA scripts. Redis also has excellent documentation - go to the redis.io website and everything is available there, with examples, everything is written.
Next, I want to talk about data types, and what commands we have in Redis.

The first data type is strings. The interface is simple. We can set some value using a specific key. The slide shows an example screenshot from the console client to Redis. We just as to SQL connect to a specific port, to a specific host, and we can work with Redis, setting values, getting their data, setting life time in seconds, you can request the remaining time.
The next data type is hashes. A hash is a structure in which you can save the fields and their values of an object.
To work with hashes, use HSET, HMSE commands. To get the value of the hash fields, we use the HGETALL command and get all the properties of our hash.
A particular example is that a user session can be stored in hashes.

The next data type is Sets. Redis allows you to store a specific set of elements for a specific key, and the set in Redis is responsible for its uniqueness. Those. if we add to the set two identical elements, then it will always be there alone. To add an element to the set, use the SADD command, to get all the elements of the set, use the SMEMBERS command. We can set keys with the EXPIRE command, the lifetime, delete keys, etc.
Another data type is sorted sets. They work almost the same as Sets, but with the exception that we can set up the so-called "glasses" of each element in our set. As points in the example on the slide above - TIMESTAMP is transmitted in the comments to article 13, i.e. we name our key so that it is clear that this is a commentary on article 13.
We add 2 elements to the set and we can get a sorted list in descending order or in ascending order of our points.
There is also such a data type in Redis as lists. Here you can push into our set of elements to the left, to the right, to take elements from a specific index to a specific index.
What are the clients for PHP?
There is an extension phpredis, it is written in C. There are also libraries Predis, written in PHP, Rediska, RedisServer - a class that opens a socket on a specific port and just communicates with Redis, Resident - fork RedisServer, but it also uses the extension phpredis for acceleration and for better performance.
My recommendations are, of course, to use phpredis, because it is faster in all benchmarks and tests, it is written in C, and all php implementations are often slower.
The following slide shows the differences between memcached and Redis.

In fact, both Redis and memcached should be used for specific tasks, i.e. if we need to store some of our data structures, some sets, sorted sets, and we cannot lose data, then of course Redis comes to the rescue. It is necessary to take into account the fact that Redis is single-threaded.
Now about the examples.

We somehow had a task on the project just to show a quick view card of our product, i.e. On the page there are miniatures of our products and when clicked we must show a detailed description of our product. The task has become in such a way as to reduce the maximum load on the backend, i.e. less to contact the database, etc.
We decided in this way:

Those. when an AJAX request arrives at our Ngnix frontend, Ngnix has a module that can work with memcached, i.e. we first request the data in memcached by key, and if there is data (and there JSON is stored with us for the products), then we immediately return this JSON. It works very fast.
If there is no data, our request is proxied in PHP and there we have two situations - the product card may lie in Redis, also in the form of JSON, then we take from Redis, save it to memcached and give it to the client.
If we have neither there nor there - neither in Redis, nor in memcached, we request our product card from MySQL, save it in Redis, duplicate this data in memcached and also return. With the following requests, our commodity cards are already issued directly from memcached.
The following, more complex, example where most Redis data types are used is parametric search:

Our catalog has headings, each heading has its own set of filters, that is, a standard filter panel. Each filter group has its own options, and when selecting specific options, we must show users a list of products that satisfy these filters.
Previously, this was all done by queries in MySQL, there were complex samples, analysis and all sorts of properties, such as filters in this category, etc. It all worked very slowly. We decided to completely change the storage model and decided to use Redis. At the same time, for each option of filters in the category we decided to store product IDs that satisfy each option.

For example, in the “Phones” category, which has ID = 100, we have two filter groups - “Manufacturers” and “Color”.
Suppose we have 4 products in Redis for Samsung - 201, 202, 203, 204, and for Philips - 301, 302, 303. The key, respectively, contains the rubric ID, filter and filter option. If the user selects in the Samsung filter panel, we request Redis, get the product IDs, put them in the product list component, and our component displays 4 products. If the user chooses another manufacturer Philips, we make two requests in Redis, take the union of these sets and, accordingly, show the seven elements in our catalog.
Further, if the user selects a filter variant from another filter group, we extract, for example, the color red, i.e. we want to see all the Samsung and Philips s in red, we take a lot of combining the first two options, intersect, respectively, with red phones and get two goods - 202, 303.
Features of this implementation - it is much faster than working with MySQL, but there is one thing: it is necessary for every change of our entities, i.e. when the properties of a product change - the product goes from one category to another, the manufacturer changes the product, the product is activated / deactivated, filters are created, changed, deleted, - we have to recalculate all these sets. Those. This is the main work that we have to do, and this is implemented through queues, i.e. we recount our sets using the RabbitMQ message broker, which will be discussed further.
Speaking of queues, I will talk about the "rabbit." RabbitMQ is a platform that implements the messaging system using the AMQP protocol. The features of this service are reliability, flexible message routing system, clustering support, support for various plugins, which allow us to view the status of our queues, see how many messages are in them, which consumer programs process them, you can also write custom plugins to change our standard behavior broker. Written by RabbitMQ on Erlang. And there are clients for working with “rabbit” for most languages - for Java, Ruby, Python, .NET, PHP, Perl, C / C ++, etc. The “rabbit” website has excellent tutorials, well-documented features. For each language there are even examples, everything is described in accessible language.
What are the basic concepts when working with the "rabbit"?
I will tell you about the types of exchangers in the “rabbit”, how the routing takes place, and I will show diagrams of how the messages from the producer to the concierge occur in the workflow.
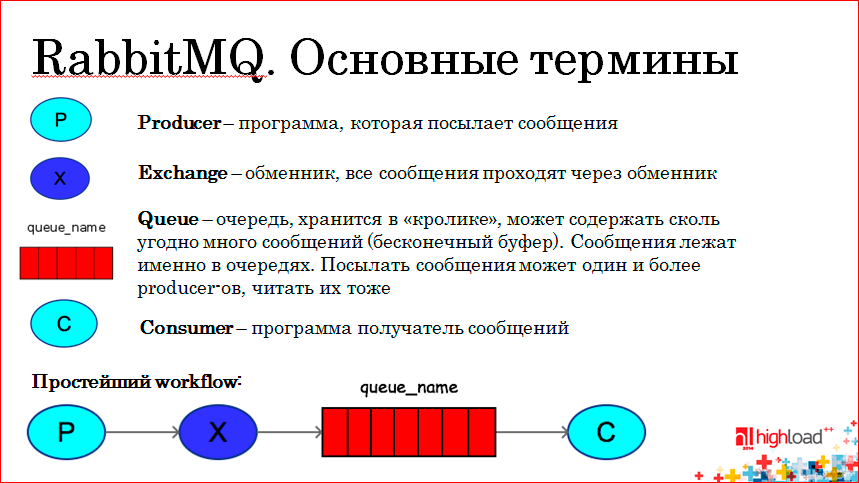
Producer (P) is a program that sends a message. Messages do not go directly to the queue, but through the exchanger - Exchange (X), and already the exchanger decides in which queue we should send this or that message. It is clear that there are queues in which messages are stored, and there are also consummers - programs that read these queues and somehow process them.
The simplest workflow - the producer sends the message to the exchanger, the exchanger decides which queue to send the message to via the binding key, and the costumer already reads the specific queue. Having received the message from the queue, the consumer can confirm that yes, I received this message, processed it, the message can be removed from the queue, i.e. there is a mechanism for confirming that messages are processed in a rabbit. If the consumer took the message and suddenly fell, the message will remain in the queue until we confirm that we have processed it.
You can configure reading from the queue so that any message taken by the consumer is always taken, i.e. We set auto-confirmation to true and you don’t need to confirm anything if it doesn't matter.
What exchange exchanges do we have?
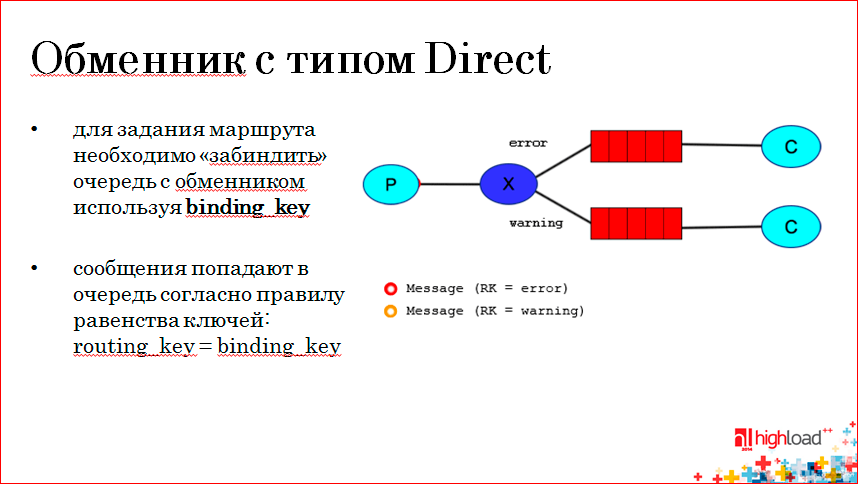
The first type is Direct Exchange, and its essence is as follows: the exchanger can be queued with different rules. For example, here the upper queue of the bindings with Exchange is through the binding-key error, and the lower queue of the bindings with the exchanger through the warning key. The producer, sending a message to the exchanger, sends the routing key of the message and, for example, on the slide, the red message has the routing key error, if it matches the binding key, then it goes to the top queue. If the message has a warning routing key, i.e. strict matching of the routing-key with the binding-key of a specific queue. We can give different messages to different consumers.
The next type of exchanger is Fanout.

Here, the point is that our turn to bind with the exchanger no matter what key, just bind, and all the messages that fall into Exchange with the Fanout type fall into all the queues that are assigned to this exchanger. Accordingly, having sent one message, if it is necessary to send certain information to several services, we can use an exchanger with the Fanout type, and our message falls into both concumer.
The next type is exchangers with the type Topic.

Exchangers of this type can bind with queues using keys that can contain special characters such as asterisk (*) and pound sign (#). What does it mean? The asterisk in the binding key can be replaced by exactly one word, and the lattice can be replaced by 0 or more words.
In this example, the Q1 queue is zabinden using the * .orange. * Key, and the second zabinden queue is two keys, i.e. it will accept messages that start with lazy, and the rest is unimportant - there may be as many other words as you like, and words are separated by a dot, and the second binding key is three words: the first two are not important, the main thing is that “ rabbit".
If our producer sent a message with such a routig-key, like the first example on the slide, it falls into both queues, because it consists of three words, the second word contains orange, and at the end it has the word rabbit.
RabbitMQ in practice.
We use the “rabbit” a lot where, for example, to recalculate the data in our Redis-e (see above). Those. we have a lot of processes-producers who change some data, we send these commands to changes in our queues, there we don’t have two queues, there are more of them, and consumers already process specific messages. For example, product A has been deactivated, we must remove it. We send the message as JSON in our turn, the consumer reads it, connects to Redis, there we have master-slave replication, we write, respectively, to the master, parsim this JSON, we see that it is necessary to remove such and such the goods from such a heading, from such sets, are deleted, and our frontend already reads from the Redis slave and shows the updated data.
Actually, this is all that I wanted to tell about these simple tools - caching and queues. Have questions?
Question from the audience : Could you tell us in more detail how your cache “sweat” is implemented, i.e. How do you calculate it, what values do you set? For example, when you show a product card and, let's say, the price has changed - how quickly will your cache update?
Answer : In fact, everything is simple there - when updating the price, we do not update the cache, according to the conditions of the task it is not particularly important, we only cache for an hour, in an hour this data is “rotted”, i.e. The price will be updated in an hour.
Question from the audience : Then you can be more relevant? Suppose you have a product that is sold at a promotional price, obviously, it will quickly go away. Then how often does your balance update?
Answer : We do not cache balances. In the case of a product card, in fact, you can simply add some logic that, when the product price changes, will take the corresponding product card from memcached, knowing its ID, and update the price in it.
Question from the audience : Here it is just in more detail - about the logic of updating the caches in different situations?
Answer : If we need to update the data in the cache, we have handlers to change products. If the product changes the price, we simply connect to memcached in this handler, simply create a new product card and save it in memcached. Instantly the price will be updated for customers.
Question from the audience : Are there any built-in tools for understanding the frequency of using data in the cache in order to understand which ones are rarely used and should they be cleared in case of overflow? Or is it all you have to do manually?
Answer : I do not know such tools.
Question from the audience : What is the maximum quality of the queues you used in one project and for what?
Answer : We have about 20 queues in the "rabbit". There are queues that recalculate our data in Redis, there is a queue that keeps track of which sms to which clients to send, there is a queue according to the status scheme, the order life cycle also passes through the queues, there is a change of statuses ... About 20 queues, not so much . Our consignees manage to process all messages, we rest more on queries to MySQL.There are several consumer items, if you have a long queue, set on one, and he will make out this queue already two or three times faster.
Question from the audience : How does your pagination work in Redis? when the filter selects the value?
Answer : In fact, our filter component does not deal with pagination; another component deals with this, to which we give the resulting product IDs, i.e. we give it to the component, and by ID it makes simple samples from our repository and paginates.
Question from the audience : You had a diagram - both memcached and Redis are used. I understand that the latter is used, because there are more possibilities on the sets and data types, but why is memcached used in this variant, what did it give you?
Answer: Memcached is used there, because we already have a module in ngnix that can work with memcached, and Redis is in the backend, because we also have other processes that can add a product card to Redis. Roughly speaking, the client enters the product card, in the usual, not popup. There the product card is already cached in Redis and the next time, if the user comes from another page, but, for example, opens a popup, we have no data in memcached, and our request has flown to PHP, then we are there without connecting a heavy framework, Directly first contact Redis. If there is data in it, then we give it away very quickly. Accordingly, if there is no data in Redis, then we connect the heavy framework, take the data from MySQL and add it to Redis and memcached.
Question from the audience: Tell me, do you somehow monitor the work of the queues?
Answer : Yes, system administrators are doing this, plus we have a plug-in for the “rabbit”, which displays the status of the queues, and with the help of munin, system administrators set up some critical values.
Question from the audience : There are situations when weakly related data are being processed, for example, an account, and several caches are attached to it. Sometimes cache key tagging is used. I would like to know how you solved this problem, as far as I know, memcached does not have this option and, in general, did you solve it?
Answer : We did not solve such a task, I didn’t see such support, but I think there’s already a Question from the audience at the level of your application.
: Does RabbitMQ have an event system so as not to drive the queue handler around in a circle each time, and so that the “rabbit” jerks the specific script itself at some event?
Answer : Yes, it is at the level of wrappers. You can send a callback to the consumer, and when a message arrives, it is automatically executed there.
Question from the audience : What about the fault tolerance of RabbitMQ? How often is your administrator, how intensely is he forced to monitor him, and how in your applications, in general, the queuing service failure policy is implemented, which unlike system queues in which messages can be recorded, can still fall off, and what happens?
Answer: Frankly speaking, I’m not going to tell you the details of administration, but your messages don’t go away if he suddenly refused. Plus there is clustering, with which system administrators can build a solution to these problems.
Question from the audience : You said that RabbitMQ has a guaranteed delivery mechanism, and is there a mechanism for notifying the producer that the message has been delivered to the concierge?
Answer : We did not do this, but I think you can implement such a mechanism at the level of your application.
Question from the audience : You say that Redis is better in all respects than memcached. Why then memcached use?
Answer: I'm not saying that in all respects parameters are better than memcached, it’s just that you can use either Redis or memcached for each of your tasks. The latter is faster, but Redis has more options. If something just needs to be cached, and this data is not so important, even if it disappears, then if you use memcached, then that's okay. It can be used, it is very reliable, high-performance server.
Question from the audience : How much faster is memcached on average? 10%, 20%, 50%?
Answer: Well, I watched various benchmarks, different data everywhere - someone in several threads makes reading records, someone shows that Redis is 10% better in some places than memcached, or vice versa. I did not conduct benchmarks myself, this is not the bottleneck in our applications, we have other problems. But there are such benchmarks, and the data varies. But the speeds are comparable.
This report is a transcript of one of the best speeches at the conference of developers of high-loaded systems HighLoad ++ .
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Well, the main news is that we have begun preparations for the spring festival " Russian Internet Technologies ", which includes eight conferences, including HighLoad ++ Junior . Of course, we are greedy commerce, but now we are selling tickets at cost price - you can make it before the price increase
Source: https://habr.com/ru/post/316652/
All Articles