Own platform. Part 0.1 Theory. Little about processors
Hello world! Today we have a series of articles for people with average knowledge of the processor in which we will deal with processor architectures (I have a spell checker swears at the word Architectures / Architectures, I hope I write the word correctly), create my own processor architecture and much more.

Any comments are welcome!
A little about the processor architecture
Historically, there are many processors and many architectures. But many architectures have similarities. Especially for this appeared "Groups" of architectures such as RISC, CISC, MISC, OISC (URISC). In addition, they may have different memory addressing architectures (von Neumann, Harvard). Each processor has its own architecture. For example, most modern architectures are RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC **, etc.), but there are architectures that have won simply due to other factors (eg convenience / price / popularity / etc) which x86, x86-64 (It is worth noting that x86-64 and x86 in the latest processors use microcode and inside them stands the RISC core), M68K. What is the difference between them?
RISC
Reduced Instruction Set Computer - An architecture with a reduced instruction execution time (from decoding RISC you might think that this is a reduced number of instructions, but it is not). This direction developed as a result after it turned out that the majority of compilers of that time did not use all instructions and the processor developers decided to get more performance using Conveyors. In general, RISC is the golden mean between all architectures.
Vivid examples of this architecture: ARM, MIPS, OpenRISC, RISC-V
Tta
What is TTA? TTA is an architecture based on just one instruction moving from one memory address to another. This option complicates the operation of the compiler, but it gives great performance. This architecture has one drawback: Strong dependency on the data bus. This was the reason for its lesser popularity. It should be noted that TTA is a type of OISC.
Vivid examples: MOVE Project
OISC (URISC)?
One Instruction Set Computer - Architecture with a single instruction. For example SUBLEQ. Such architectures often have the form: Make an action and, depending on the result, make a jump or continue execution. Often its implementation is quite simple, the performance is small, while again limiting the data bus.
Vivid examples: BitBitJump, ByteByteJump, SUBLEQ thousands of them!
CISC
CISC - Complex Instruction Set Computer - its feature in increased numbers of actions per instruction. Thus, it was possible to theoretically increase the performance of programs by increasing the complexity of the compiler. But in fact, CISC had poorly implemented some instructions. they were rarely used, and productivity gains were not achieved. The peculiarity of this group is still a huge difference between architectures. And despite the names were architecture with a small number of instructions.
Vivid examples: x86, M68K
Memory addressing
Architecture Neumann Background

A feature of such architectures was a common data bus and instructions. Most modern architectures are software von Neumann, but no one forbids making Harvard hardware. In this architecture, a big disadvantage is the large dependence of processor performance on the bus. (Which limits overall processor performance).
Harvard architecture

The peculiarity of this architecture is a separate data bus and instructions. It gives greater performance than von Neumann due to the possibility to use both buses in one cycle (read instructions from the bus and simultaneously write to the data bus), but complicates the architecture and has some limitations. Mainly used in microcontrollers.
Processor features
Conveyors
What are conveyors? If you say a very stupid language, these are several parallel actions in one measure. This is very rude, but at the same time displays the essence. Conveyors due to the complexity of the architecture can improve performance. For example, the pipeline allows you to read the instructions, execute the previous one and write to the data bus at the same time.

The picture is more clear, is not it?
IF - receiving instructions
ID - decryption instructions
EX - execution,
MEM - memory access,
WB - write to the register.
It seems everything is simple? And no! The problem is that, for example, a jump (jmp / branch / etc) forces the pipeline to start execution (receiving the next instruction) again, thus causing a delay of 2-4 cycles before the execution of the next instruction.
Extend existing architectures
A rather popular technique is adding more instructions through extensions to an existing architecture. A prime example is SSE under x86. The same ARM and MIPS sin and almost everything. Why? Because it is impossible to create a universal architecture.
Another option is to use other architectures to reduce the size of the instructions.
Bright example: ARM with the Thumb, MIPS with MIPS16.
Techniques used in the GPU
Many cores are often found in video cards, and because of this feature, there is a need for additional solutions. If the pipelines can be found even in microcontrollers, then the solutions used in the GPU are rare. For example, Masked Execution (occurs in ARM instructions, but not in Thumb-I / II). There are other features: this is a bias towards Floating Number (Floating Point Numbers), a decrease in performance versus a larger number of cores, etc.
Masked Execution
This mode differs from the classic ones in that instructions are executed sequentially without using jumps. The instruction stores a certain amount of information about the conditions under which this instruction will be executed and if the condition is not met, then the instruction is skipped.
But why?
The answer is simple! That would not load the tire instructions. For example, in video cards you can load thousands of cores in one instruction. And if the jump system were used, then for each core we would have to wait for the instruction from the slow memory. Cache partially solves the problem, but still does not completely solve the problem.
Other
Here we will describe several techniques used in central processors and microcontrollers.
Interruptions
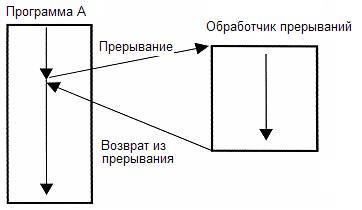
An interrupt is a technique in which the currently executing code is suspended to perform some other task under certain conditions. For example, when accessing a non-existent section of memory, HardFault or MemoryFault interrupts or exceptions are called. Or for example if the timer counted to zero. This allows you to not idle until you need to wait for some event.
What are the disadvantages? An interrupt call is a few idle cycles and a few when returning from an interrupt. Also, a few instructions at the beginning of the code will be occupied by the instructions for the Interrupt Table.
Exception
But besides interrupts, there are still exceptions that arise, for example, when dividing by zero. It is often combined with interrupts and system calls, such as in MIPS. Exceptions are not always present in the processor such as in the AVR or lower PIC
System calls
System calls are used in Operating Systems so that programs can communicate with the operating system, for example, ask the OS to read the file. Very similar to interrupts. Similarly, exceptions are not always present in the processor.
Memory Access Controllers and Other Program Restraints
It describes methods of prohibiting access of applications to hardware directly.
Privileged mode
This is the mode in which the processor starts. In this mode, the program or the OS have full memory access bypassing the MMU / MPU. All programs are launched in the unprivileged mode in order to avoid direct access to the hardware subsystems of the programs for this purpose not intended. For example, malware. In Windows, it is often called Ring-0, and in * nix it is called system. Do not confuse Privileged User and Privileged Mode because in the root you still cannot have direct access to the hardware (you can download a system module that allows you to do this, but more on that later :)
MPU and MMU
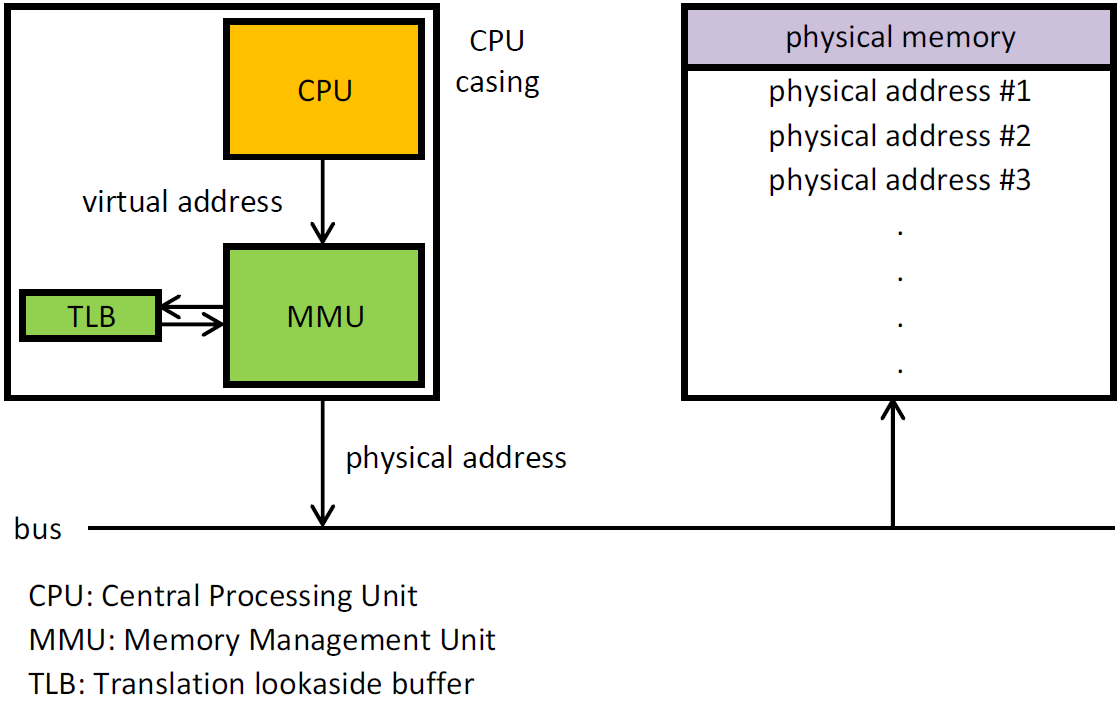
MPU and MMU are used in modern systems to isolate multiple applications. BUT, if the MMU allows you to "move" the memory, then the MPU only allows you to block access to memory / run code in memory.
PIC (PIE)
What is PIE? (I do not use PIC to avoid confusion with PIC MK). PIE is a technique by which the compiler generates code that will work anywhere in memory. This technique in combination with MPU allows you to compile high programming languages that will work with MPU.
SIMD
The popular SIMD technique is used to perform several actions on several registers in a single clock cycle. Sometimes there are as additions to the basic architecture, for example, as in MIPS, ARM with its NEON / VFP / etc, x86 with its SSE2.
Reposition for Optimization
This technique is used to optimize the code generated by the compiler by re-sorting instructions, increasing processor performance. This allows you to use the conveyor to the fullest.
Status register

What is a status register? This is the register that stores the state of the processor. For example, is the processor in privileged mode, which is how the last comparison operation ended.
Used in conjunction with the Masked Execution. Some developers specifically exclude the status register because it may be a bottleneck as they did at MIPS.
mov vs $ 0 reg
In MIPS there is no separate instruction for loading a constant into memory, but there is an instruction addi and ori which allows, in conjunction with a zero register ($ 0), to emulate the work of loading a constant into a register. In other architectures, it is present. I touched on this topic because it will be useful to us in articles with practice.
Rd, Rs vs Rd, rs, rt
There are a lot of controversy about how many operands there should be in arithmetic instructions. For example, in MIPS, a variant with 3 registers is used. 2 operands, 1 register of record. On the other hand, the use of two operands reduces the code by reducing the size of the instruction. An example of combining is MIPS16 in MIPS and Thumb-I in ARM. In terms of performance, they are almost identical (If we exclude the size of the instructions as a factor).
Endianness

Byte order You may know Big-Endian and Little-Endian expressions. They describe the byte order in instructions / in registers / in memory / etc. Here I think everything is simple :). There are processors that combine modes, like MIPS, or which use the same command system, but have different byte order, for example, ARM.
CPU Bit
So, what is the processor bit? Many people believe that this is the bit bus data, but it is not. Why? In the early periods of microcontrollers and microprocessors, the bus could be, for example, 4-bit, but transmitted in packets of 8 bits. It seemed to the program that it was an 8-bit mode, but it was an illusion, as it is now. For example, the ARM SoC-ah often uses a 128-bit data bus or instructions.
Coprocessors
What are coprocessors? Coprocessors are the elements of the processor or external chip. They allow you to execute instructions that are too cumbersome for the main part of the processor. As a prime example, MIPS coprocessors for division and multiplication. Or for example 387 for 80386, which added support for floating-point numbers. And there were a lot of coprocessors in MIPS and they fulfilled their roles: they controlled interrupts, exceptions and system calls. Often, coprocessors have their own instructions and on systems where there are no such instructions (ARM example) emulate it through Traps (traps?). Despite their crutches and low performance, they are often the only choice in microcontrollers.
Atomicity of operations
The atomic nature of operations provides a stream-independent execution due to instructions that perform several actions for one pseudo-tact.
Alternative solution atomic peripheral. For example, different registers are used to set the legs in the STM32 in the high and low states, which makes it possible to have atomicity at the periphery level.
Cache

You probably heard about L1, L2, L3 and registers. In short, the processor analyzes a piece of code to predict jumps and memory access and asks the cache to get this data from the memory in advance. Cache is often transparent to the program, but there are exceptions to this rule. For example, in software cores in the FPGA software cache is used.
And you’ve overly heard of a thing like Cache Miss or a cache miss. This is an operation that was not provided for by the processors or the processor did not manage to cache this part of the memory. What is often a problem of slowing down memory access. A slip passes unnoticed by the program, but drawdowns in performance will not remain unnoticeable. Similarly, context switches for example during interruptions also cause the cache to suffer because a small code knocks down the pipeline and the cache for its own needs.
Shadow registers
Modern processors often use shadow register technology. They allow you to switch between interrupts and user code with almost no delays associated with saving registers.
Stack

Stack? I saw Stack in .NET and in Java! Well, you are partially right. The stack exists, but it has never been hardware in most processors. For example, in MIPS it is simply not there. Ask AS SO THAT ?! The answer is simple. A stack is simply a memory access that does not need to be backed up (a very crude definition). The stack is used to call functions, pass arguments, save registers in order to restore them after function execution, etc.
Then ask what the heap is? A pile is a memory much larger than a stack (the stack is usually ~ 1MB). Everything is global in the hip. For example, all pointers obtained with Malloc point to a part of the heap. And pointers are stored on the stack or in registers. Using the instructions for loading data on the register, you can speed up the stack and other memory accesses by the type of stack, since you do not need to constantly use PUSH / POP, INC / DEC or ADDI, SUBI operations (add a constant) to get data deeper in the stack, and you can simply use access relative to the stack with a negative offset.
Registers

I will not describe registers in too much detail. This we will address in a practical article.
The x86 registers are quite small. MIPS uses an increased number of registers, namely, 31 ($ 0 has a value always equal to zero). The Berkeley University processor used register windows, which tightly limited the nesting of functions, while having better performance. In others, such as AVR, they restricted the use of registers. For example: three 16-bit can be interpreted as six eight-bit, where the first 16t are not available for some operations. I believe that the best method was chosen by MIPS. This is my personal opinion.
Alignment
What is alignment? I'll leave this question to you :)
the end
This is the end of the first chapter of part zero. The whole series will revolve around the theme of creating your own processor. Own operating system. Own assembler. Own compiler and much more.
The zero parts will be devoted to the theory. I doubt that I will bring the entire series to a victorious end, but the attempt is not torture! )
')
Source: https://habr.com/ru/post/316520/
All Articles