Deep Learning: Combining Deep Convolutional Neural Network with Recurrent Neural Network
We present to you the final article from the Deep Learning cycle, in which the results of the work of teaching the GNSS for images from certain areas are reflected on the example of recognition and tagging of clothing items. You will find the previous parts under the cut.

1. Comparison of frameworks for symbolic deep learning .
2. Transfer learning and fine tuning of deep convolutional neural networks .
3. A combination of a deep convolutional neural network with a recurrent neural network .
Note: further narration will be conducted on behalf of the author.
')
If we talk about the role of clothing in society, the recognition of things can have many applications. For example, the work of Liu and other authors on identifying and searching for unmarked items of clothing in images will help identify the most similar elements in an e-commerce database. Young and Yu look at the process of recognizing the elements of clothing from the other side: they believe that this information can be used in the context of video surveillance to identify suspects in crimes.
In this article, based on the materials of Wang and Vinyasa , we will create an optimized model for the classification of clothing items, a brief description of the images and the prediction of tags to them.
I was inspired by recent improvements in machine translation, the task of which is to translate individual words or sentences. Now it is possible to translate much faster using recurrent neural networks (PHC), while achieving high speed. The PHC coder reads the source tag or tag and converts it into a fixed-length vector representation, which, in turn, is used as the initial hidden state of the PHC decoder, which forms the tag or tag. We propose to follow the same path using the deep convolutional neural network (GNSS) instead of the RNS coder. In recent years, it has become clear that the GNSS networks can create a sufficient representation of the input image by embedding it in a vector of fixed length that can be used for various tasks. It is possible to naturally use the GNSS as an image encoder: to do this, you first need to conduct preliminary training on the task of classifying images using the hidden layer as an input to the PHC decoder, which generates tags.

RNS-SNS model for creating clothing image tags
In this work, the GoogLeNet model, previously trained in ImageNet, will be used to extract the SNA components from the DR data set. Then, the functions of the SNA for teaching the PHC model with a long short-term memory for predicting the DR tags.
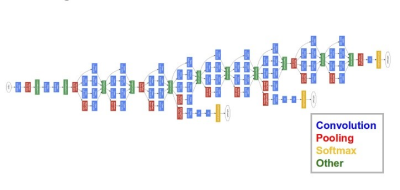
GoogLeNet architecture
Use the DR data set : full pipeline to recognize and classify people's clothing in vivo. This solution can be applied in various fields, for example, in e-commerce, in events, in Internet advertising and so on. The pipeline consists of several stages: recognition of body parts, various channels and visual attributes. The PD defines 15 classes of clothing and enters a reference set of estimates for its classification, consisting of more than 80,000 images. We also use the DR data set to predict clothing tags for images that have not previously been analyzed.
Images from training and test datasets have completely different indicators: resolution, aspect ratio, colors, and so on. Neural networks need input data of a fixed size, so we transferred all the images to the format: 3 × 224 × 224.
One of the drawbacks of irregular neural networks is their excessive flexibility: they are equally well trained in recognizing both garment details and interferences, which increase the likelihood of over-fitting. We apply Tikhonov's regularization (or L2 regularization) to avoid this. However, even after that, there was a significant performance gap between learning and verifying DR images, indicating an over-fit during the fine-tuning process. To eliminate this effect, we apply data addition to a set of image data DR.
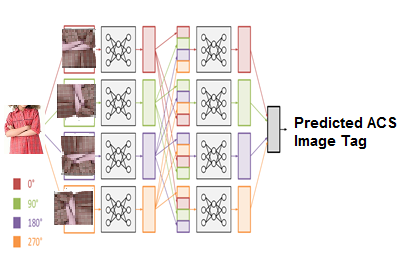
There are many ways to complement data, for example, mirroring horizontally, random cropping, changing colors. Since the color information of these images is very important, we apply only the rotation of the images to different angles: 0, 90, 180 and 270 degrees.

Augmented images of DR
To deal with the problem of predicting the DR tags, we follow the tweaking script from the previous section . The GoogLeNet model we used was initially trained on the ImageNet dataset. The ImageNet dataset contains about 1 million natural images and 1000 tags / categories. Our tagged DR data set contains about 80,000 images belonging to the clothing category, and 15 tags / categories. The data set of PD is not enough to train such a complex network as GoogLeNet. Therefore, we use weight data from the GoogLeNet model trained in the ImageNet data set. We carry out fine-tuning of all levels of a previously trained GoogLeNet model through continuous back propagation.
Replacing the input layer of the pre-trained GoogLeNet network with DR images
In this paper, we use the PHC model with long-term short-term memory, which has high performance when performing sequential tasks. The basis of this model is a memory cell encoding knowledge about the observed input data at each time point. The behavior of the cell is controlled by valves, in the role of which the layers used multiplicatively are used. It uses three shutters:
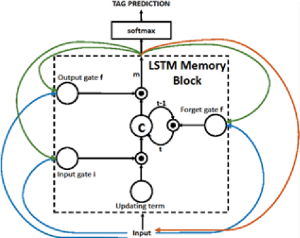
Recurrent neural network with long-term short-term memory
The memory block contains a cell "c", controlled by three gates. Recurrent connections are shown in blue: the output “m” at the moment of time (t – 1) is fed back to the memory at the time “t” through three shutters; the cell value is fed back through the “forget” gate; The predicted word at the time point (t – 1) is fed back in addition to the memory output “m” at the time point “t” in Softmax to predict the tag.
A model with a long short-term memory is trained to predict the main tags for each image. As an input, the GNSS DR functions (obtained using GoogLeNet) are used. Then, the model is trained with a long-term short-term memory (LSTM) based on combinations of these functions of GNSS and labels for pre-processed images.
A copy of the LSTM memory is created for each LSTM image and for each label in such a way that all LSTM use the same parameters. The (m) × (t − 1) LSTM output at time (t –1) is fed to the LSTM at time (t). All recurrent connections are converted to proactive connections in the final version. We have seen that feeding the image at each time step as an additional input yields unsatisfactory results, since the network perceives noise in the images and produces an excessive fit. Losses are reduced in relation to all parameters of LSTM, the upper level of the convolutional neural network of embedding images and embedding tags.
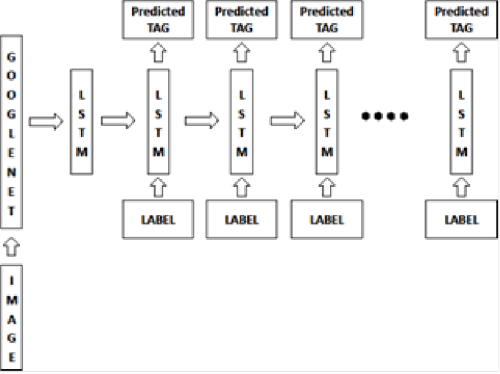
GNSS-RNS architecture for predicting DR tags
We use the model described above to predict DR tags. The accuracy of tag predictions in this model increases rapidly in the first part of the iterations and stabilizes after approximately 20,000 iterations.
Each image in the DR data set consists only of unique types of clothing, there are no images that combine different types of clothing. Despite this, when testing images with several types of clothing, our trained model rather accurately creates tags for these previously untreated test images (accuracy was about 80%).
Below is an example of the output of our prediction: on the test image you see a person in a suit and a person in a T-shirt.

Test image not previously analyzed
The figure below shows the prediction of GoogLeNet tags using the GoogLeNet model with ImageNet training.
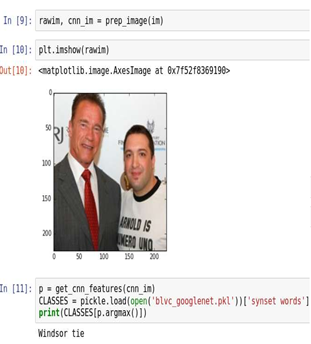
Predicting GoogLeNet tags for a test image using the GoogLeNet model with ImageNet training
As you can see, the prediction for this model is not very accurate, since the test image receives the "Windsor Tie" tag. The figure below shows the prediction of the DR tags using the RNS-GNSS model described above with long-term short-term memory. As you can see, the prediction for this model is very accurate, since our test image receives the tags “shirt, T-shirt, upper body, suit”.
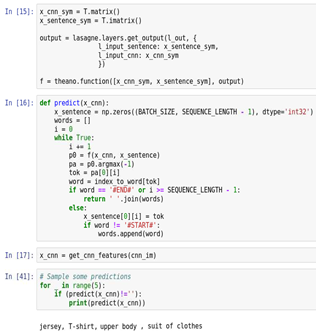
Prediction of GoogLeNet tags for a test image using the RNS-GNSS model with long-term short-term memory
Our goal is to develop a model capable of predicting tags of clothing categories for clothing images with high accuracy.
In this paper, we compare the accuracy of prediction of the GoogLeNet model tags and the RNS-GNSS model with long-term short-term memory. The accuracy of the prediction tags of the second model is much higher. For her training, a relatively small number of training iterations, of the order of 10,000, was used. The accuracy of the predictions of the second model quickly increases with the number of training iterations and stabilizes after approximately 20,000 iterations. For this work, we used only one GP.
Thanks to the fine-tuning, you can apply advanced models of GPSN in new areas. In addition, the combined model of the GNSS-RNS helps to expand the trained model to solve completely different tasks, such as the formation of tags for images of clothes.
I hope this series of publications will help you to train the GNSS for images from certain areas and to reuse already trained models.
If you see an inaccuracy of the translation, please let us know in your private messages.
The series of articles "Deep Learning"
1. Comparison of frameworks for symbolic deep learning .
2. Transfer learning and fine tuning of deep convolutional neural networks .
3. A combination of a deep convolutional neural network with a recurrent neural network .
Note: further narration will be conducted on behalf of the author.
')
Introduction
If we talk about the role of clothing in society, the recognition of things can have many applications. For example, the work of Liu and other authors on identifying and searching for unmarked items of clothing in images will help identify the most similar elements in an e-commerce database. Young and Yu look at the process of recognizing the elements of clothing from the other side: they believe that this information can be used in the context of video surveillance to identify suspects in crimes.
In this article, based on the materials of Wang and Vinyasa , we will create an optimized model for the classification of clothing items, a brief description of the images and the prediction of tags to them.
I was inspired by recent improvements in machine translation, the task of which is to translate individual words or sentences. Now it is possible to translate much faster using recurrent neural networks (PHC), while achieving high speed. The PHC coder reads the source tag or tag and converts it into a fixed-length vector representation, which, in turn, is used as the initial hidden state of the PHC decoder, which forms the tag or tag. We propose to follow the same path using the deep convolutional neural network (GNSS) instead of the RNS coder. In recent years, it has become clear that the GNSS networks can create a sufficient representation of the input image by embedding it in a vector of fixed length that can be used for various tasks. It is possible to naturally use the GNSS as an image encoder: to do this, you first need to conduct preliminary training on the task of classifying images using the hidden layer as an input to the PHC decoder, which generates tags.
RNS-SNS model for creating clothing image tags
In this work, the GoogLeNet model, previously trained in ImageNet, will be used to extract the SNA components from the DR data set. Then, the functions of the SNA for teaching the PHC model with a long short-term memory for predicting the DR tags.
GoogLeNet architecture
Data
Use the DR data set : full pipeline to recognize and classify people's clothing in vivo. This solution can be applied in various fields, for example, in e-commerce, in events, in Internet advertising and so on. The pipeline consists of several stages: recognition of body parts, various channels and visual attributes. The PD defines 15 classes of clothing and enters a reference set of estimates for its classification, consisting of more than 80,000 images. We also use the DR data set to predict clothing tags for images that have not previously been analyzed.
Images from training and test datasets have completely different indicators: resolution, aspect ratio, colors, and so on. Neural networks need input data of a fixed size, so we transferred all the images to the format: 3 × 224 × 224.
One of the drawbacks of irregular neural networks is their excessive flexibility: they are equally well trained in recognizing both garment details and interferences, which increase the likelihood of over-fitting. We apply Tikhonov's regularization (or L2 regularization) to avoid this. However, even after that, there was a significant performance gap between learning and verifying DR images, indicating an over-fit during the fine-tuning process. To eliminate this effect, we apply data addition to a set of image data DR.
There are many ways to complement data, for example, mirroring horizontally, random cropping, changing colors. Since the color information of these images is very important, we apply only the rotation of the images to different angles: 0, 90, 180 and 270 degrees.
Augmented images of DR
Tweaking GoogleNet for DR
To deal with the problem of predicting the DR tags, we follow the tweaking script from the previous section . The GoogLeNet model we used was initially trained on the ImageNet dataset. The ImageNet dataset contains about 1 million natural images and 1000 tags / categories. Our tagged DR data set contains about 80,000 images belonging to the clothing category, and 15 tags / categories. The data set of PD is not enough to train such a complex network as GoogLeNet. Therefore, we use weight data from the GoogLeNet model trained in the ImageNet data set. We carry out fine-tuning of all levels of a previously trained GoogLeNet model through continuous back propagation.
Replacing the input layer of the pre-trained GoogLeNet network with DR images
Learning PH with long-term short-term memory
In this paper, we use the PHC model with long-term short-term memory, which has high performance when performing sequential tasks. The basis of this model is a memory cell encoding knowledge about the observed input data at each time point. The behavior of the cell is controlled by valves, in the role of which the layers used multiplicatively are used. It uses three shutters:
- forget the current value of the cell (forget the shutter f),
- read the input cell value (enter gate i),
- output new cell value (output gate o).
Recurrent neural network with long-term short-term memory
The memory block contains a cell "c", controlled by three gates. Recurrent connections are shown in blue: the output “m” at the moment of time (t – 1) is fed back to the memory at the time “t” through three shutters; the cell value is fed back through the “forget” gate; The predicted word at the time point (t – 1) is fed back in addition to the memory output “m” at the time point “t” in Softmax to predict the tag.
A model with a long short-term memory is trained to predict the main tags for each image. As an input, the GNSS DR functions (obtained using GoogLeNet) are used. Then, the model is trained with a long-term short-term memory (LSTM) based on combinations of these functions of GNSS and labels for pre-processed images.
A copy of the LSTM memory is created for each LSTM image and for each label in such a way that all LSTM use the same parameters. The (m) × (t − 1) LSTM output at time (t –1) is fed to the LSTM at time (t). All recurrent connections are converted to proactive connections in the final version. We have seen that feeding the image at each time step as an additional input yields unsatisfactory results, since the network perceives noise in the images and produces an excessive fit. Losses are reduced in relation to all parameters of LSTM, the upper level of the convolutional neural network of embedding images and embedding tags.
GNSS-RNS architecture for predicting DR tags
results
We use the model described above to predict DR tags. The accuracy of tag predictions in this model increases rapidly in the first part of the iterations and stabilizes after approximately 20,000 iterations.
Each image in the DR data set consists only of unique types of clothing, there are no images that combine different types of clothing. Despite this, when testing images with several types of clothing, our trained model rather accurately creates tags for these previously untreated test images (accuracy was about 80%).
Below is an example of the output of our prediction: on the test image you see a person in a suit and a person in a T-shirt.
Test image not previously analyzed
The figure below shows the prediction of GoogLeNet tags using the GoogLeNet model with ImageNet training.
Predicting GoogLeNet tags for a test image using the GoogLeNet model with ImageNet training
As you can see, the prediction for this model is not very accurate, since the test image receives the "Windsor Tie" tag. The figure below shows the prediction of the DR tags using the RNS-GNSS model described above with long-term short-term memory. As you can see, the prediction for this model is very accurate, since our test image receives the tags “shirt, T-shirt, upper body, suit”.
Prediction of GoogLeNet tags for a test image using the RNS-GNSS model with long-term short-term memory
Our goal is to develop a model capable of predicting tags of clothing categories for clothing images with high accuracy.
Conclusion
In this paper, we compare the accuracy of prediction of the GoogLeNet model tags and the RNS-GNSS model with long-term short-term memory. The accuracy of the prediction tags of the second model is much higher. For her training, a relatively small number of training iterations, of the order of 10,000, was used. The accuracy of the predictions of the second model quickly increases with the number of training iterations and stabilizes after approximately 20,000 iterations. For this work, we used only one GP.
Thanks to the fine-tuning, you can apply advanced models of GPSN in new areas. In addition, the combined model of the GNSS-RNS helps to expand the trained model to solve completely different tasks, such as the formation of tags for images of clothes.
I hope this series of publications will help you to train the GNSS for images from certain areas and to reuse already trained models.
If you see an inaccuracy of the translation, please let us know in your private messages.
Source: https://habr.com/ru/post/316456/
All Articles