A boring one-line calculator on sed
Writing boring manuals, as I used to believe, has a negative impact on the nature of the character and therefore my body from time to time resists the discipline as much as it can. So recently I was under the impression of the listened stories of Zoshchenko, I decided to convey as much as possible on the pages of Habra a style, and most importantly a spirit that is very close to me and which I think does not diminish the value of the stated fact, but acts as a catalyst and guarantees the connoisseur the presence of intelligence. I changed the subject accordingly, and that's what I got from this.
Sed, according to some adepts, is an unpredictable language with a muddy, Old Testament syntax, with edits on the fields personally made by Cyril and Methodius. I always respect the opinions of opponents, but I don’t have to divide them at all, so I decided for myself that sed is what you need to quickly get calluses and not be a black sheep in discussions when mysterious characters other than regular literals appear in the lines of the sed code expressions.
What is the availability of tools? The first is bash (version 4.3.42). The second is sed (4.2.2). Judging by the versions, if a little fantasy, then we can assume that our racers started at about the same era and go, though not nostrils, into the nostril, but with a difference of no more than half of the body. All this stuff is located in fedora 24 on my computer.
After refreshing and running the emulek tutorial in verses, I discovered that sed has a modifier that allows embedding shell commands and replacing the template with the value returned by this command. My first line in this field looked quite encouraging.
')
Everything turned out and at the exit a solid four was waiting for me! The " s " (substitution) command looks for a match by the pattern / ([0-9] +) ([- +]) ([0-9] +) / and replaces it with the output of the / expr ([0-9] +) command ([- +]) ([0-9] +) / e . Parameters in this command are defined in a template. The first block in parentheses corresponds to \ 1 second \ 2 and third \ 3 . Go ahead and expand the functionality by adding the arithmetic signs " *% / ".
And we immediately get a syntax error in the " expr " command. We begin to analyze and understand that in the expression \ 2 during the substitution, the asterisk has a special meaning and sed replaces its value with its own, that is, emptiness. We'll have to escape this symbol before the Bashy team takes it into circulation. We write another substitution command and modify the template somewhat.
Four again! A masterpiece and asks for the painting "again, two"! Here we have introduced another substitution command. We precede the first template with an asterisk with a backslash icon in order to deprive the super villain of her abilities, and in the substitute line do not forget to screen the backslash icon itself. As a result, this part grows to such a scary look / \\\ * / .
Also in the second pattern, namely, in the second round brackets, a backslash is added and in order not to make a fuss to the character class [- + *% / \] defined by square brackets, we substitute the quantifier " + ", which gives us a match on the pattern of two characters " \ * ". It was certainly possible to more accurately determine the pattern, but in the context of this is quite enough.
Bash is good because almost any thing available in it can be done in several different ways. By the way, this is his apparent confusion. To perform arithmetic operations with integers, a more modern form of writing is provided and I will, as a peer of the Pepsi generation, be offended with the alternative construction " echo $ (()) ", and leave " expr " only in lines for example. The new design allows us to get rid of part of the code and thoroughly simplify the program. There is no need for shielding asterisks. Since we will simplify the code, it is possible to introduce additional functionality, maintaining the level of complexity at a level acceptable for a beginner.
I sent only one line to the editor and the program stopped working on it. Conditional and unconditional jumps are available in sed. Those who are familiar with the assembler, immediately find the perfect similarity of transitions or jumps on the labels. The principle is the same. And it already becomes interesting because the work in the editor begins to look like work
with this program.
There is an established opinion that html is a markup language, I agree with that. So, I think, without transitions and some built-in functions, the language of the sed editor could also be brought under this definition. But there are transitions and functions in the editor, which means we can fully engage in the programming of his work with the text.
The next release of our program with the introduction into circulation of transitions, acquires the shape of the present code.
Having run such a code in the terminal, we can only type arithmetic expressions with two numbers and press " enter ". By the marks " again " immediately see the beginning and end of the cycle. The conditional jump command " t " by the " again " label will return us to the beginning of the next loop defined by this mark after the colon and the editor will wait for the next line to be entered.
Keep in mind, exit from the program is a well-known interrupt signal triggered by pressing the Ctrl + C key combination.
But let's analyze the work of conditional transition. The " t " command is used in conjunction with the " s " (substitution) command and, based on the result of the latter, a transition is made or not. If the first (in the presence of several) command " s " makes a substitution in the buffer, then the conditional transition is performed.
There is also a command " T " which is executed if the first (with several) command " s " failed.
We analyzed the work program with the transition condition. Stop you say. And why do we need a transition by condition when an unconditional transition would be quite enough. Let's replace the " t " command with the unconditional " b " command. We are testing.
We enter data as it should be, but there is not any result at the output! Where are we wrong, because logically everything should work just as well? Let us return and again analyze the work program. As always, everything turned out to be elementary. We did not take into account one moment, the conditional jump command " t " is triggered and translates the execution of the program to the label in the event that a change occurs in the command " s ".
Apparently the construction with the extension " e " works a little differently. As I dare to suggest in our case, there is not any substitution. Our line is fully consistent with the pattern and appears unchanged, in the form of bash utility parameters. And here, apparently, the sacrament of substitution occurs, but alas, our editor believes that the " s " command has nothing to do with this, but the " e " extension team is involved. And since we know that if the label is missing or the transition condition is not fulfilled, the program will go to the end of the command line, and not by the label to its beginning. Repair the code.
The situation requires an explanation. Enter an additional two commands and one option that correct the situation. After recording the result of the calculation with the " p " command, we will print the buffer contents forcibly, and before returning to the beginning of the program, we will clear it with the " d " command. The " -n " option usually works in conjunction with the " p " command and suppresses automatic print buffer output. I feel that I have matured after such misadventures for several years, and if it goes on like this, I will quickly grow old and remain an old maid. I could not even imagine what would be so boring!
Our program works again, but it is still largely redundant. For example, the labels that I introduced with a greater degree to demonstrate the capabilities of the sed language and which unexpectedly added detective pepper, are superfluous here. They would make sense if in the line we had several commands separated by a semicolon and the label would allow to bypass one of the commands or blocks of commands. We'll have to roll back so hard mastered the bells and whistles. In fact, the editor is already waiting for the input of the next line and begins work on its input from the very beginning where we had the label. Without any damage, I can rewrite the line like this:
Or even like this:
This main cycle that we modeled earlier in the manual mode is already built into the program of the editor and we will use it in the future. Let's go back to the functional. If we recall the work of this calculator, then we will find an additional buffer for storing intermediate results. What about sed? It turns out that there is also an additional buffer and several commands for working with it. All that we did before this, it worked with the main buffer into which the string is loaded and actions are performed on it. We will activate an additional buffer for storing the result of calculations, as well as add a functional, when subsequent operations with an intermediate result of the calculation could be performed simply by typing the sign of the arithmetic operation and the second operand in the line. And we will also work with negative numbers. Also, we will not cut the functionality of the bash itself and add a little entropy to the algorithm of the “Not boring” calculator, embed the construction of the number in the power. Let me remind you that in the bash the exponentiation looks like NUMBER ** DEGREE. The sign is clear, a double asterisk is taken into account. At the same time we will immediately carry out all the optimization available to my understanding.
Although at first I poked my nose like a blind kitten looking for development for the code, in conclusion, he still acquired the following form.
I considered it unnecessary wastefulness to define a full-fledged template, which in fact does not do anything except as it provides with the help of such a design the ability to enter a shell command and reduced the template to a minimum of /.*/ , which essentially coincides with any string. I considered this to be acceptable and even imagined that I was insured for a million bucks from mistakes when entering. If you are not so sure of yourself as I can insert such a pattern s / ^ -? [0-9] + [- +% / *] \ *? -? [0-9] + $ / . I advise everyone else, blondes like me, not to bother, because even if there is an input error, the additional buffer is updated with the loss of intermediate results and this cycle is called very simply - “start over”. At the same time, restarting the program is completely unnecessary, just start entering the correct data.
Well, let's look at what we wrote in the last line of the code and start with the algorithm of the program. After launching the editor, it is in input standby mode. The first line we enter consists of two operands and an arithmetic sign in the middle. At the very beginning of the program code there is a template that “does not notice” all operations consisting of two operands, which means that this filter will skip our first line and the action will immediately go to the already familiar command of the calling shell utility to get the final result.
In this part of the program, I not only simplified the pattern, but also simplified the formula for recording operands. Now we insert the operands not individually, but in a single line, one data block denoted as & . Ampersand, a synonym for this character denoting the entire string, is \ 0 . In this block of code ending with a semicolon, we change the values of the main buffer to the calculated value by the shell command. After the semicolon we have the command " h " which copies everything that is in the main buffer to the additional buffer. After that, the program displays the contents of the main buffer and goes to the beginning of the loop, waiting for the new line to be entered.
Now we know that we have the first operand in the buffer and enter only the sign of the arithmetic operation and the second operand. The first " s " command finds that the main buffer contains a string matching the pattern / ^ [- + /% *] \ *? -? [0-9] + $ / after which the action is passed to a block of commands enclosed in braces. The second command in the block, the " G ", adds to the end of the main buffer the new line " \ n " and copies the line from the additional buffer after it. As a result, we have two lines at once in the main buffer separated by a newline. The first is only that the entered operation sign and the second operand.
Immediately attracts attention is not the correct order of the operands. To correct this slight misunderstanding before adding a line from the additional buffer to the main one, we will use the knee in the form of the " x " command, which swaps the main buffer with the additional one and then after executing the " G " command everything will be in the correct order. As a result, after executing the two " x; G " commands , we will have a similar line 1 operand \ n SIGN 2 operand in the main buffer. A line break in the middle of an expression is superfluous. Remove it with the next substitution command s / \ n // . Well, and then on written, control passes to the "counting machine."
Those who previously were not familiar with the stream editor sed can independently look through the tutorial from emulek and see how the buffers are in reality called sed, well, they can still find a bunch of goodies.
For dessert, I will inform all DomSEDs that there still exists such a utility Super-sed in nature. In the repository, debian-testing has the package name ssed. This is a stream editor capable of understanding Perl regular expressions. This utility is missing from fedora 24 in the rpmfusion repository. But this is a completely different non-boring story.
Sed, according to some adepts, is an unpredictable language with a muddy, Old Testament syntax, with edits on the fields personally made by Cyril and Methodius. I always respect the opinions of opponents, but I don’t have to divide them at all, so I decided for myself that sed is what you need to quickly get calluses and not be a black sheep in discussions when mysterious characters other than regular literals appear in the lines of the sed code expressions.
What is the availability of tools? The first is bash (version 4.3.42). The second is sed (4.2.2). Judging by the versions, if a little fantasy, then we can assume that our racers started at about the same era and go, though not nostrils, into the nostril, but with a difference of no more than half of the body. All this stuff is located in fedora 24 on my computer.
After refreshing and running the emulek tutorial in verses, I discovered that sed has a modifier that allows embedding shell commands and replacing the template with the value returned by this command. My first line in this field looked quite encouraging.
')
sed -r 's/([0-9]+)([-+])([0-9]+)/expr \1 \2 \3/e' <<<"2+2" Everything turned out and at the exit a solid four was waiting for me! The " s " (substitution) command looks for a match by the pattern / ([0-9] +) ([- +]) ([0-9] +) / and replaces it with the output of the / expr ([0-9] +) command ([- +]) ([0-9] +) / e . Parameters in this command are defined in a template. The first block in parentheses corresponds to \ 1 second \ 2 and third \ 3 . Go ahead and expand the functionality by adding the arithmetic signs " *% / ".
sed -r 's/([0-9]+)([-+*%/])([0-9]+)/expr \1 \2 \3/e' <<<"2*2" And we immediately get a syntax error in the " expr " command. We begin to analyze and understand that in the expression \ 2 during the substitution, the asterisk has a special meaning and sed replaces its value with its own, that is, emptiness. We'll have to escape this symbol before the Bashy team takes it into circulation. We write another substitution command and modify the template somewhat.
sed -r 's/\*/\\\*/; s/([0-9]+)([-+*%/\]+)([0-9]+)/expr \1 \2 \3/e' <<<"2*2" Four again! A masterpiece and asks for the painting "again, two"! Here we have introduced another substitution command. We precede the first template with an asterisk with a backslash icon in order to deprive the super villain of her abilities, and in the substitute line do not forget to screen the backslash icon itself. As a result, this part grows to such a scary look / \\\ * / .
Also in the second pattern, namely, in the second round brackets, a backslash is added and in order not to make a fuss to the character class [- + *% / \] defined by square brackets, we substitute the quantifier " + ", which gives us a match on the pattern of two characters " \ * ". It was certainly possible to more accurately determine the pattern, but in the context of this is quite enough.
Bash is good because almost any thing available in it can be done in several different ways. By the way, this is his apparent confusion. To perform arithmetic operations with integers, a more modern form of writing is provided and I will, as a peer of the Pepsi generation, be offended with the alternative construction " echo $ (()) ", and leave " expr " only in lines for example. The new design allows us to get rid of part of the code and thoroughly simplify the program. There is no need for shielding asterisks. Since we will simplify the code, it is possible to introduce additional functionality, maintaining the level of complexity at a level acceptable for a beginner.
I sent only one line to the editor and the program stopped working on it. Conditional and unconditional jumps are available in sed. Those who are familiar with the assembler, immediately find the perfect similarity of transitions or jumps on the labels. The principle is the same. And it already becomes interesting because the work in the editor begins to look like work
with this program.
There is an established opinion that html is a markup language, I agree with that. So, I think, without transitions and some built-in functions, the language of the sed editor could also be brought under this definition. But there are transitions and functions in the editor, which means we can fully engage in the programming of his work with the text.
The next release of our program with the introduction into circulation of transitions, acquires the shape of the present code.
sed -r ':again s/([0-9]+)([-+%/*])([0-9]+)/echo $((\1 \2 \3))/e; t again' Having run such a code in the terminal, we can only type arithmetic expressions with two numbers and press " enter ". By the marks " again " immediately see the beginning and end of the cycle. The conditional jump command " t " by the " again " label will return us to the beginning of the next loop defined by this mark after the colon and the editor will wait for the next line to be entered.
Keep in mind, exit from the program is a well-known interrupt signal triggered by pressing the Ctrl + C key combination.
But let's analyze the work of conditional transition. The " t " command is used in conjunction with the " s " (substitution) command and, based on the result of the latter, a transition is made or not. If the first (in the presence of several) command " s " makes a substitution in the buffer, then the conditional transition is performed.
There is also a command " T " which is executed if the first (with several) command " s " failed.
We analyzed the work program with the transition condition. Stop you say. And why do we need a transition by condition when an unconditional transition would be quite enough. Let's replace the " t " command with the unconditional " b " command. We are testing.
sed -r ':again s/([0-9]+)([-+%/*])([0-9]+)/echo $((\1 \2 \3))/e; b again' We enter data as it should be, but there is not any result at the output! Where are we wrong, because logically everything should work just as well? Let us return and again analyze the work program. As always, everything turned out to be elementary. We did not take into account one moment, the conditional jump command " t " is triggered and translates the execution of the program to the label in the event that a change occurs in the command " s ".
Apparently the construction with the extension " e " works a little differently. As I dare to suggest in our case, there is not any substitution. Our line is fully consistent with the pattern and appears unchanged, in the form of bash utility parameters. And here, apparently, the sacrament of substitution occurs, but alas, our editor believes that the " s " command has nothing to do with this, but the " e " extension team is involved. And since we know that if the label is missing or the transition condition is not fulfilled, the program will go to the end of the command line, and not by the label to its beginning. Repair the code.
sed -rn ':again s/([0-9]+)([-+%/*])([0-9]+)/echo $((\1 \2 \3))/e;p;d; b again' The situation requires an explanation. Enter an additional two commands and one option that correct the situation. After recording the result of the calculation with the " p " command, we will print the buffer contents forcibly, and before returning to the beginning of the program, we will clear it with the " d " command. The " -n " option usually works in conjunction with the " p " command and suppresses automatic print buffer output. I feel that I have matured after such misadventures for several years, and if it goes on like this, I will quickly grow old and remain an old maid. I could not even imagine what would be so boring!
Our program works again, but it is still largely redundant. For example, the labels that I introduced with a greater degree to demonstrate the capabilities of the sed language and which unexpectedly added detective pepper, are superfluous here. They would make sense if in the line we had several commands separated by a semicolon and the label would allow to bypass one of the commands or blocks of commands. We'll have to roll back so hard mastered the bells and whistles. In fact, the editor is already waiting for the input of the next line and begins work on its input from the very beginning where we had the label. Without any damage, I can rewrite the line like this:
sed -r 's/([0-9]+)([-+%/*])([0-9]+)/echo $((\1 \2 \3))/e' - Or even like this:
sed -r 's/([0-9]+)([-+%/*])([0-9]+)/echo $((\1 \2 \3))/e' This main cycle that we modeled earlier in the manual mode is already built into the program of the editor and we will use it in the future. Let's go back to the functional. If we recall the work of this calculator, then we will find an additional buffer for storing intermediate results. What about sed? It turns out that there is also an additional buffer and several commands for working with it. All that we did before this, it worked with the main buffer into which the string is loaded and actions are performed on it. We will activate an additional buffer for storing the result of calculations, as well as add a functional, when subsequent operations with an intermediate result of the calculation could be performed simply by typing the sign of the arithmetic operation and the second operand in the line. And we will also work with negative numbers. Also, we will not cut the functionality of the bash itself and add a little entropy to the algorithm of the “Not boring” calculator, embed the construction of the number in the power. Let me remind you that in the bash the exponentiation looks like NUMBER ** DEGREE. The sign is clear, a double asterisk is taken into account. At the same time we will immediately carry out all the optimization available to my understanding.
Although at first I poked my nose like a blind kitten looking for development for the code, in conclusion, he still acquired the following form.
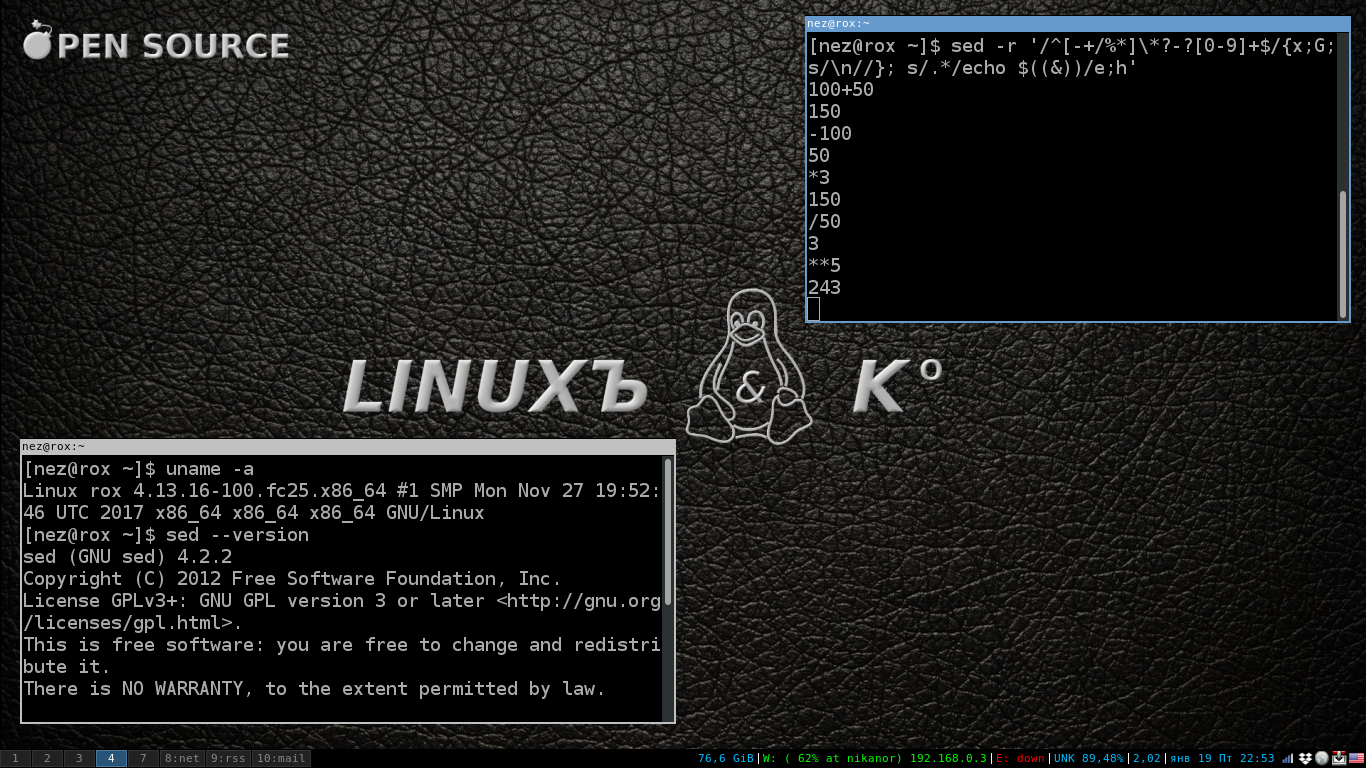
sed -r '/^[-+/%*]\*?-?[0-9]+$/{x;G;s/\n//}; s/.*/echo $((&))/e;h' I considered it unnecessary wastefulness to define a full-fledged template, which in fact does not do anything except as it provides with the help of such a design the ability to enter a shell command and reduced the template to a minimum of /.*/ , which essentially coincides with any string. I considered this to be acceptable and even imagined that I was insured for a million bucks from mistakes when entering. If you are not so sure of yourself as I can insert such a pattern s / ^ -? [0-9] + [- +% / *] \ *? -? [0-9] + $ / . I advise everyone else, blondes like me, not to bother, because even if there is an input error, the additional buffer is updated with the loss of intermediate results and this cycle is called very simply - “start over”. At the same time, restarting the program is completely unnecessary, just start entering the correct data.
Well, let's look at what we wrote in the last line of the code and start with the algorithm of the program. After launching the editor, it is in input standby mode. The first line we enter consists of two operands and an arithmetic sign in the middle. At the very beginning of the program code there is a template that “does not notice” all operations consisting of two operands, which means that this filter will skip our first line and the action will immediately go to the already familiar command of the calling shell utility to get the final result.
In this part of the program, I not only simplified the pattern, but also simplified the formula for recording operands. Now we insert the operands not individually, but in a single line, one data block denoted as & . Ampersand, a synonym for this character denoting the entire string, is \ 0 . In this block of code ending with a semicolon, we change the values of the main buffer to the calculated value by the shell command. After the semicolon we have the command " h " which copies everything that is in the main buffer to the additional buffer. After that, the program displays the contents of the main buffer and goes to the beginning of the loop, waiting for the new line to be entered.
Now we know that we have the first operand in the buffer and enter only the sign of the arithmetic operation and the second operand. The first " s " command finds that the main buffer contains a string matching the pattern / ^ [- + /% *] \ *? -? [0-9] + $ / after which the action is passed to a block of commands enclosed in braces. The second command in the block, the " G ", adds to the end of the main buffer the new line " \ n " and copies the line from the additional buffer after it. As a result, we have two lines at once in the main buffer separated by a newline. The first is only that the entered operation sign and the second operand.
Immediately attracts attention is not the correct order of the operands. To correct this slight misunderstanding before adding a line from the additional buffer to the main one, we will use the knee in the form of the " x " command, which swaps the main buffer with the additional one and then after executing the " G " command everything will be in the correct order. As a result, after executing the two " x; G " commands , we will have a similar line 1 operand \ n SIGN 2 operand in the main buffer. A line break in the middle of an expression is superfluous. Remove it with the next substitution command s / \ n // . Well, and then on written, control passes to the "counting machine."
Those who previously were not familiar with the stream editor sed can independently look through the tutorial from emulek and see how the buffers are in reality called sed, well, they can still find a bunch of goodies.
For dessert, I will inform all DomSEDs that there still exists such a utility Super-sed in nature. In the repository, debian-testing has the package name ssed. This is a stream editor capable of understanding Perl regular expressions. This utility is missing from fedora 24 in the rpmfusion repository. But this is a completely different non-boring story.
Source: https://habr.com/ru/post/316106/
All Articles