How to avoid excessive complexity of the application state [translation]

Flux implementations, such as Redux, motivate us to pay more attention to designing the state of the application. It turns out that this is not a trivial task. This is similar to a classic example from the theory of chaos, when a seemingly innocuous flap of butterfly wings leads to far-reaching consequences. Below are tips to help you better organize the state of the application.
What is application state?
According to Wikipedia , the program stores the data in the variables represented in the computer's memory. The values of these variables at a certain point in time are the state of the application.
It is important to add the word “minimum” to the definition. When designing the state of the application, you should try to work with the minimum data set, and ignore those variables that can be calculated based on it.
')
In unidirectional data flow ( Flux ) applications, the state is in stores. Performing actions (actions) leads to a change of state, as a result of which the views (views) that subscribe to its changes are updated in accordance with new data.
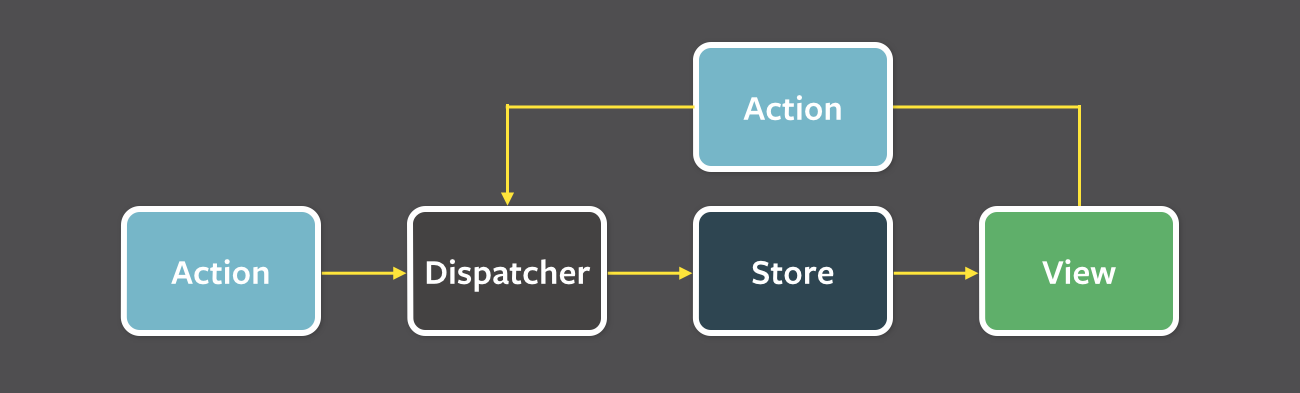
Redux , which will be discussed further, adds several strict restrictions. First of all, the state is stored in a single immutable and serializable storage.
Below are tips that will be helpful even if you are not using Redux. They can be useful to those who do not use Flux at all.
1. The state is not required to repeat the server response structure.
The local state of the application is often based on data received from the server. If the application is used to display server data, there is a temptation to use the same structure on the client.
As an example, take an application to manage an online store. The manager will use it to manage the goods. The list of products comes from the server and must be stored in the local state of the application in order to be drawn in the views. Let's say the following JSON comes from the server:
{ "total": 117, "offset": 0, "products": [ { "id": "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0", "title": "Blue Shirt", "price": 9.99 }, { "id": "aec17a8e-4793-4687-9be4-02a6cf305590", "title": "Red Hat", "price": 7.99 } ] } The product list comes as an array of objects, so why not save it in this form in a local state?
In this case, the choice by the server of an array for transferring a list of goods may be associated with pagination, with the list being split into pieces for batch loading, with avoiding re-sending data to save traffic. These are all valid considerations, but, in general, they are not related to those considerations that guide us in modeling the local state of the application.
2. The object is preferable to the array.
In general, arrays are not the best data structure to use in application state. Imagine getting or updating a specific product from the list. If we want to change the price, or we need to apply an update from the server, iterating over the array to search for a specific product will not be as convenient as receiving it by the ID in the product object.
We can update the data from the example like this:
{ "productsById": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "title": "Blue Shirt", "price": 9.99 }, "aec17a8e-4793-4687-9be4-02a6cf305590": { "title": "Red Hat", "price": 7.99 } } } But what if the order of the elements in the list is important? For example, if we have to display the goods in exactly the order that is specified in the array from the server response? In this case, we can save an additional array of identifiers:
{ "productsById": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "title": "Blue Shirt", "price": 9.99 }, "aec17a8e-4793-4687-9be4-02a6cf305590": { "title": "Red Hat", "price": 7.99 } }, "productIds": [ "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0", "aec17a8e-4793-4687-9be4-02a6cf305590" ] } Note: this structure works fine with the React Native ListView component. The recommended version of cloneWithRows expects exactly this format.
3. The state is not required to have the format in which the views accept data.
In the end, views are drawn based on state. The ability to avoid additional transformations, keeping the state data in the right form for the views, seems attractive.
Let's return to our example with an online store management system. Suppose that each product can either be available or absent. To do this, we can add the outOfStock field to the item object:
{ "id": "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0", "title": "Blue Shirt", "price": 9.99, "outOfStock": false } Our application should display a list of all missing products. As you remember, the React Native ListView component expects two arguments for the cloneWithRows method: an object with strings and an array of these row IDs. I would like to prepare such a structure in advance and store it in the state of the application so as not to convert the data during transmission to the component. The state structure will look like this:
{ "productsById": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "title": "Blue Shirt", "price": 9.99, "outOfStock": false }, "aec17a8e-4793-4687-9be4-02a6cf305590": { "title": "Red Hat", "price": 7.99, "outOfStock": true } }, "outOfStockProductIds": ["aec17a8e-4793-4687-9be4-02a6cf305590"] } Good idea, right? Not really.
The reason, as before, is that views are guided by other considerations. Their main task is to display the data in the most user-friendly form, and this may contradict our desire to store only the minimum necessary data in the application state. Moreover, different views can show one data set in a different form, and this can lead to duplication of data in the state.
This brings us to the next point.
4. Never duplicate data in the state
If the data update requires simultaneous changes in two places to maintain integrity, then the data in the state is duplicated. Suppose that in the example above, one product receives the status of "out of stock". To accommodate this update, we need to change the outOfStock field in the item object and add its ID to the outOfStockProductIds array — two updates.
The problem is solved simply - the excess entity is deleted. By updating data in only one place, we eliminate the risk of compromising integrity.
If we refuse the outOfStockProductIds array, we need to find a way to prepare the data for the views. A common practice in Redux is the use of selectors :
{ "productsById": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "title": "Blue Shirt", "price": 9.99, "outOfStock": false }, "aec17a8e-4793-4687-9be4-02a6cf305590": { "title": "Red Hat", "price": 7.99, "outOfStock": true } } } // selector function outOfStockProductIds(state) { return _.keys(_.pickBy(state.productsById, (product) => product.outOfStock)); } A selector is a pure function that receives the state of an application as input and returns the converted part for further use. Dan Abramov recommends that the selector be placed with the reducer, as they are usually closely related. We will use the selector inside the view in mapStateToProps.
A viable alternative to deleting an array is to remove the outOfStock property in each item object. In this case, a single source of information on the availability of goods is an array with an ID. However, in accordance with paragraph 2, it may be better to turn this array into an object:
{ "productsById": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "title": "Blue Shirt", "price": 9.99 }, "aec17a8e-4793-4687-9be4-02a6cf305590": { "title": "Red Hat", "price": 7.99 } }, "outOfStockProductMap": { "aec17a8e-4793-4687-9be4-02a6cf305590": true } } // selector function outOfStockProductIds(state) { return _.keys(state.outOfStockProductMap); } 5. Never save secondary data in the state.
Keeping data in state as a result of computations based on other data from the state violates the SSOT (Single source of truth) principle , since updating data requires changes in several places to preserve integrity.
Add to our application the ability to specify a discount on the product. It is necessary to display to the user a filtered list of products, in which either all products are presented, or goods with a discount, or without.
A common mistake is to store data in the form of three arrays, each of which will contain a set of IDs for a particular filter. Since these sets can be calculated based on the list of products and information about the current filter, it would be more correct to generate them using the selector as before:
{ "productsById": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "title": "Blue Shirt", "price": 9.99, "discount": 1.99 }, "aec17a8e-4793-4687-9be4-02a6cf305590": { "title": "Red Hat", "price": 7.99, "discount": 0 } } } // selector function filteredProductIds(state, filter) { return _.keys(_.pickBy(state.productsById, (product) => { if (filter == "ALL_PRODUCTS") return true; if (filter == "NO_DISCOUNTS" && product.discount == 0) return true; if (filter == "ONLY_DISCOUNTS" && product.discount > 0) return true; return false; })); } Selectors are executed each time the application is updated before the view is redrawn. If you have complex selectors and you care about performance, use memoization for caching calculation results. This is already implemented in the Reselect library.
6. Normalize related objects.
Our task is to make it so comfortable to develop and maintain applications. At the same time it should be convenient to work with its state. The simplicity of the state is more convenient to maintain when objects with data are independent, but what happens if objects are connected to each other?
Imagine that in our example you need to add an order management system with which the buyer can select several products and place an order. Suppose we receive the following JSON from the server with a list of orders:
{ "total": 1, "offset": 0, "orders": [ { "id": "14e743f8-8fa5-4520-be62-4339551383b5", "customer": "John Smith", "products": [ { "id": "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0", "title": "Blue Shirt", "price": 9.99, "giftWrap": true, "notes": "It's a gift, please remove price tag" } ], "totalPrice": 9.99 } ] } The order contains several items. It turns out that we have two entities that need to be interconnected. We already know that it is not necessary for us to store data one-on-one with the structure provided by the server. It, in this case, will lead to duplication of data on goods.
A good approach in this case is to normalize the data and work with two objects: one for products and the other for orders. Since objects of both types have an ID, we can use this property to relate them. Thus, the state of the application takes the following form:
{ "productsById": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "title": "Blue Shirt", "price": 9.99 }, "aec17a8e-4793-4687-9be4-02a6cf305590": { "title": "Red Hat", "price": 7.99 } }, "ordersById": { "14e743f8-8fa5-4520-be62-4339551383b5": { "customer": "John Smith", "products": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "giftWrap": true, "notes": "It's a gift, please remove price tag" } }, "totalPrice": 9.99 } } } If we want to find all the products of a specific order, we go through the keys of the products object in the order. Each key is an ID that we can access in the productsById object to get more detailed information about the product. Order-specific product information, such as giftWrap, can be found in the products order item.
For data normalization there is a ready library - normalizr .
7. The status of the application can be treated as a database stored in memory.
Most of the tips above are probably familiar to you. We make similar decisions when designing traditional databases .
When designing the structure of a traditional database, we try to avoid duplication and storage of secondary data, index data in tables like objects using primary keys (ID) and normalize relations between several tables. All that we discussed above.
The attitude to the state of the application as to the database stored in memory helps to form the correct setting for making more informed decisions about the data structure.
Treat application state appropriately.
If you select the main idea of the article, then this is it.
In imperative programming, we tend to put code first and pay less attention to building “correct” models for internal data structures, such as state. The states of our applications can often be scattered among various managers / controllers as a collection of internal variables.
In the declarative paradigm, things are different. In React and in similar environments, our system responds to changes in state, so it becomes as important as the code that controls the behavior of the application. Both actions and representations for which it is a data source work with it. Redux and other Flux implementations are repelled by this idea and add new features and limitations for greater predictability of the application.
Designing an application state structure takes time. We must be attentive to how complicated it becomes and how much effort it takes to support and develop it. And, of course, as is the case with the code, the state of the application, which ceases to effectively cope with its tasks, refactoring is necessary from time to time.
From the translator:
Article author: Tal Kol. The original is available by reference .
Thanks bniwredyc for comments and tips on translation.
Source: https://habr.com/ru/post/316070/
All Articles