Semantic search: myths and reality

About semantic search speak for several years. Any technology that can shift Google from the top, is of general interest. Especially when it comes to the long-awaited and often discussed possibility of semantic search. However, we are not so much interested in the progress in this area, as the lack of real results of the research is sad, because the search results are not so different from the results of Google search. What is the matter?
For example, when you type “Capital of France” in the search bar, both methods give the same correct answer: “Paris”. In addition, most of the queries that we type into the search bar in the form of abbreviations, give the same results, if you enter the term completely. Obviously there is something wrong here. Everyone knows that semantic technologies are capable of much, but why? And how do they work? After reading this article, you will learn that in fact, we simply ask the wrong questions.
The mistake lies in the fact that semantic search engines, in fact, have a similar input line with Google, which allows us to enter free-form queries. Therefore, we enter requests as we are accustomed to - in the simplest form. We will never enter in the search string "What actor was filmed in the films" Pulp Fiction "and" Saturday Night Fever "? or "Which two US senators took bribes from foreign companies?" We always drive in simple phrases, but this is not the power of semantic search. To understand how everything works, we suggest you look at several semantic search technologies from Google, SearchMonkey, Powerset and Freebase.
What problem are we trying to solve?
')
The first difficulty arises when the semantic search is beginning to be considered the solution of various tasks - from the modern search system, where Google dominates, to tasks that cannot be solved by computation. Still more complicated by the fact that at present there are only a few areas of knowledge where semantic search really does better - these are complex requests for conclusions and reasoning about complex data systems.
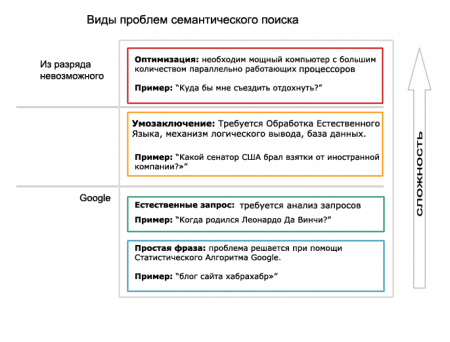
As can be seen from the above data, Google easily copes with the main types of requests. Unfortunately, the automatic processing of natural language gives only a slight advantage. Google will give the right answer to the question about the year of birth of Leonardo, without giving any chances to improve the search process with an understanding of nouns and verbs that the user drives into the search bar.
Before we consider the tasks that semantic search can easily handle, consider the most complex tasks. There are problems requiring computation that have nothing to do with understanding the semantics of a word. At the early stage of the existence of the Semantic Web, it was believed that with its help we will be able to solve even complex problems, but unfortunately this is not the case. There are limits to what we can calculate, and there is a class of problems with a huge number of possible solutions, and we cannot solve these problems in a magical way just because we have provided information in RDF.
But there is also a layer of tasks that the semantic web handles perfectly. We solved them with the help of a thematic database. But do not forget that semantic technologies help us to find thematic information dispersed throughout the network - therefore for us there is nothing surprising in the fact that semantic search engines will surpass thematic requests.
Overview of semantic search engines
The essence of semantic search is not only in the questions asked by us. Due to the fact that the web is a collection of unstructured HTML pages, the base information is also based on semantic search. The clearest and most comprehensible of all, we found Freebase - a semantic database. Freebase works not only through text search, but most importantly, through MQL (Metaweb Query Language). MQL is almost the same JSON (text data exchange format), but with more features. With it, you can create any query in Freebase and the answer will be the same query, but with inserted search results.

A powerset is essentially a thematic database that works with certain structured information. On the other hand, there is Google, which primarily focuses on the statistical frequency of queries and almost does not take into account the semantics. Of interest is the new SearchMonkey system from Yahoo! This system adds nothing to the results found, but uses semantic annotations for a more complete, interactive, and useful user interface.
Hakia and Powerset are clearly working with maximum efficiency. They try to create Freebase-like structures, and then search for top-level results in natural language. The difference is that Hakia (like others) uses technology to search the entire network, and Powerset closed its search on Wikipedia.
What is common and where are the differences?
In this regard, the question arises: “Which of these technologies are similar and which are radically different?” Let's start with a simple one. SearchMonkey is no different from Google and any other search engine, because they have one essence, and the difference is present only in appearance. SearchMonkey is good at allowing publishers to present search results in the best possible way.
As for Hakia, Powerset and Freebase, the situation is different. At first glance, they are completely different: Hakia uses the entire web in search, Powerset only Wikipedia and Freebase, and Freebase has two search interfaces: a search line and a search language. But there is one problem: natural language has nothing to do with the representativeness of basic information.
The fact is that all semantic search technologies allow users to drive in arbitrary complex questions, and then interpret them and apply them to existing databases. Hakia, Powerset, Freebase are such bases, and they all have an automatic natural language processing system that “translates” the question to a standard query that is understandable to the base.
To understand how this all works, imagine Freebase and its MQL search language. Unlike natural language, which allows you to ask a question in different ways, MQL does not imply ambiguity. This JSON-like language allows users to formulate clear queries for searching the Freebase database. The fact that the Powerset allows you to build questions in a natural language does not mean that the Powerset is not a database. Powerset is a base, because it is based on the Freebase search string. The difference between Freebase and Powerset is in the approaches to the search and the ways of providing its results.
Back to the future: the whole thing is in the user interface
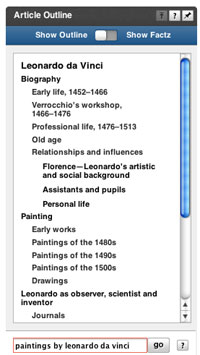
Perhaps the most important point in semantic search is the user interface. The Powerset understood that semantics should be reflected in it. After searching in Powerset, a contextual gadget that is familiar with the semantics of the results will help the user to complete the whole process.
The weak point of the Powerset is the interface. The search string with which everyone who has ever looked for something on the web is familiar is outdated. Powerset and Hakia’s too simple interface does not benefit them, but it doesn’t affect too much Freebase, which does not position itself as a search engine.
Recall the recent launch of the Powerset. The company has provided the best way to search in one of the most powerful sources of information on the web - on Wikipedia. But what do critics say? Can this system be called the main competitor of Google? The answer is unequivocal - no.
And what if some restrictions on the search are imposed on the Powerset? What if, instead of using the search line, another interface was used or the company told users not to search for something that they could easily find on Google? Maybe new companies should improve the search algorithm that has existed for over 10 years? In any case, any ideas should be aimed at solving problems that Google cannot solve today.
Conclusion
Semantic search is the technology of the future, which has set too high goals for itself. We all thought that it would help to overthrow Google and provide the highest quality search results. Both of these statements turned out to be false. The truth is that semantic search is a multifactorial phenomenon, and it will help us solve those problems that we cannot solve now: complex, logically sound queries that are very often found in the network.
In order for semantic search technologies to occupy their niche in the market, companies need to revise their goals and improve the user interface. The search string is not relevant and promises losses, because It is associated with simple questions that Google can easily handle. Developers need to offer a completely new interface so that users can fully experience the power of semantic search.
Source: https://habr.com/ru/post/31600/
All Articles