Using Intel technology to transfer network traffic from a physical adapter to a virtual one
Hello! I want to share an analysis of existing Intel technologies that allow you to quickly transfer traffic from a physical card to a virtual machine. In principle, all methods have been tested in reality on Intel XL710 cards, so I will also say about their pros and cons. And since our company is engaged in the development of a virtual switch, all of this is in terms of a virtual switch.
Not exactly the technology from Intel, but only their implementation was able to touch. In short, the physical adapter (PF) is divided into several virtual (VF). The traffic inside one vlan by default does not go beyond the boundaries of the PF, and provides the most minimal delays compared to virtual adapters on soft bridges.
Using Intel FlowDirector in principle, you can change the behavior and specify the rules by which traffic should go between the VF or out of the PF. You can also make a manual distribution of traffic on RX queues or hardwired drop traffic immediately at the entrance to the map. Support for the configuration of the flow is in the drivers, but I did not find a specific api specifically for Flow Director. Who wants to play around - you can dig into the ethtool source, or use Intel DPDK, the API is implemented in it, but the card is unlinked from the kernel driver with all the consequences.
')
From my point of view, these technologies are mainly for admins who simply need to reduce delays in transferring traffic between virtual machines.
Pros : work in VMWare, and KVM. Everywhere is faster than software bridges both in terms of delays and throughput. And the CPU does not eat.
Minuses : virtual switch in this case - you need to turn it into a real one on a separate hardware, where PFs from the server with virtual machines are plugged into.
And 64 VF per PF is now quite small.
About this development kit on Habré there were already articles, so I will not particularly spread. But in the virtual machine contest, there is little information. I will analyze the main ways of using the Intel DPDK in case you need to transfer traffic between the physical adapter and the virtual one. This technology for us is the main, as we do the Openflow switch.
Well, further, under the virtual machine, I mean KVM with the DPDK application inside, since you don’t really put anything on the VMWare hypervisor, and there isn’t much choice inside the VMWare virtual machine, e1000 or vmxnet3. I advise vmxnet3.
Intel pleased us with the following features.
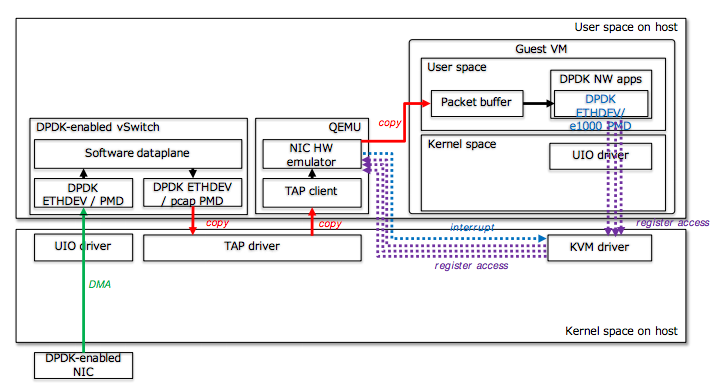
Technically it is one of the two. You can pick up your virtual switch via TAP, and use the e1000 as a virtual adapter, and if within the VM DPDK application you cling to it via igb pmd.
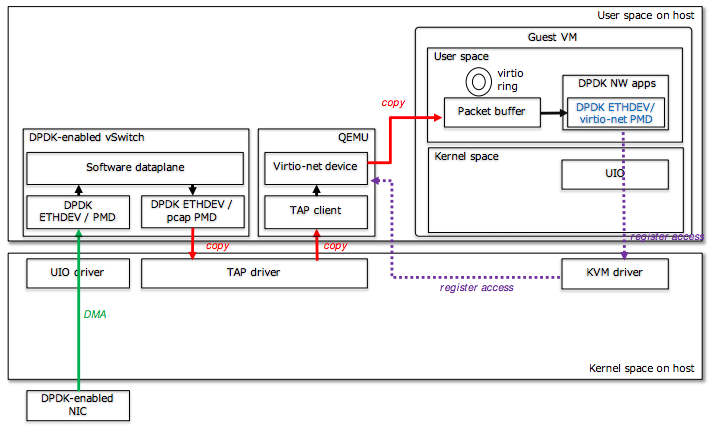
You can pick up your virtual switch via TAP, and use virtio-net as a virtual adapter, and if you have an application inside VM DPDK, you cling to it through virtio pmd.
Advantages of these methods: simplicity, works with both DPDK applications and conventional ones.
Cons: performance is just pain, a lot of copying, a lot of transitions inside the virtual machine and context switching.
Method 2: Fast & Furios
You can pick up your virtual switch via IVSHMEM (in Qemu, you had to patch it before, now it’s kind of injected), and as a virtual adapter you can create a specialized DPDK Ring adapter, which is the fastest IPC mechanism between DPDK applications.

Pros : better performance
Cons : DPDK applications only
You can pick up your virtual switch through the vhost-user API, and use virtio-net as a virtual adapter.

Pros : works with both DPDK applications and ordinary ones, the performance is good (but worse than method 2, if there is an application inside the VM DPDK)
Cons : mainly related to link statuses and other straps, solvable
Intel DPDK also offers a way to create a KNI device. In a nutshell, there is a separate kernel module that organizes soft rx / tx queues, creates a virtual adapter with these queues and provides copying from skb_buf to mbuf and back, emulating the network.
We are still exploring it until there are no final results.
But already known:
Pros : you can combine with a DPDK ring, create a KNI for legacy, leave a ring for DPDK. You can create KNI on top of a physical map.
Cons : as it does not go very well, the CPU eats in tons and there are no special benefits.
But we are working on it.
Will keep you posted.
Intel SR-IOV
Not exactly the technology from Intel, but only their implementation was able to touch. In short, the physical adapter (PF) is divided into several virtual (VF). The traffic inside one vlan by default does not go beyond the boundaries of the PF, and provides the most minimal delays compared to virtual adapters on soft bridges.
Drivers
VF is a PCI device that runs into a virtual machine. The virtual machine must have an i40e driver, otherwise it will not be able to pick it up. True to the dockers you can stupidly throw in netns.
Using Intel FlowDirector in principle, you can change the behavior and specify the rules by which traffic should go between the VF or out of the PF. You can also make a manual distribution of traffic on RX queues or hardwired drop traffic immediately at the entrance to the map. Support for the configuration of the flow is in the drivers, but I did not find a specific api specifically for Flow Director. Who wants to play around - you can dig into the ethtool source, or use Intel DPDK, the API is implemented in it, but the card is unlinked from the kernel driver with all the consequences.
')
From my point of view, these technologies are mainly for admins who simply need to reduce delays in transferring traffic between virtual machines.
Pros : work in VMWare, and KVM. Everywhere is faster than software bridges both in terms of delays and throughput. And the CPU does not eat.
Minuses : virtual switch in this case - you need to turn it into a real one on a separate hardware, where PFs from the server with virtual machines are plugged into.
And 64 VF per PF is now quite small.
Intel DPDK
About this development kit on Habré there were already articles, so I will not particularly spread. But in the virtual machine contest, there is little information. I will analyze the main ways of using the Intel DPDK in case you need to transfer traffic between the physical adapter and the virtual one. This technology for us is the main, as we do the Openflow switch.
Well, further, under the virtual machine, I mean KVM with the DPDK application inside, since you don’t really put anything on the VMWare hypervisor, and there isn’t much choice inside the VMWare virtual machine, e1000 or vmxnet3. I advise vmxnet3.
Intel pleased us with the following features.
Method 1: Pain
Technically it is one of the two. You can pick up your virtual switch via TAP, and use the e1000 as a virtual adapter, and if within the VM DPDK application you cling to it via igb pmd.
You can pick up your virtual switch via TAP, and use virtio-net as a virtual adapter, and if you have an application inside VM DPDK, you cling to it through virtio pmd.
Advantages of these methods: simplicity, works with both DPDK applications and conventional ones.
Cons: performance is just pain, a lot of copying, a lot of transitions inside the virtual machine and context switching.
Method 2: Fast & Furios
You can pick up your virtual switch via IVSHMEM (in Qemu, you had to patch it before, now it’s kind of injected), and as a virtual adapter you can create a specialized DPDK Ring adapter, which is the fastest IPC mechanism between DPDK applications.
Pros : better performance
Cons : DPDK applications only
Method 3: One size fits all
You can pick up your virtual switch through the vhost-user API, and use virtio-net as a virtual adapter.
Pros : works with both DPDK applications and ordinary ones, the performance is good (but worse than method 2, if there is an application inside the VM DPDK)
Cons : mainly related to link statuses and other straps, solvable
Method 4: Arcane
Intel DPDK also offers a way to create a KNI device. In a nutshell, there is a separate kernel module that organizes soft rx / tx queues, creates a virtual adapter with these queues and provides copying from skb_buf to mbuf and back, emulating the network.
We are still exploring it until there are no final results.
But already known:
Pros : you can combine with a DPDK ring, create a KNI for legacy, leave a ring for DPDK. You can create KNI on top of a physical map.
Cons : as it does not go very well, the CPU eats in tons and there are no special benefits.
But we are working on it.
Will keep you posted.
Source: https://habr.com/ru/post/315914/
All Articles