Make a simple and convenient site relevance map - DONE
Everyone who has worked with seo-promotion has heard the following statements: “The site needs a semantic core (S)”, “There is no semantic core — there is no promotion”, “S A is the basis of the site”, etc. etc. Soon they began to say that SJ is, of course, good, but we also need a “relevance map” (it is also a link map, a map for entering key requests). But with the definition of this concept creates some kind of confusion. Even detailed guidelines for mapping the relevance of leading agencies do not add clarity. It is difficult to understand how with the fact that they are shown in the examples you can work systematically.
In the article we will share our vision of this tool and development experience.
What does the relevance map say on the Internet?
Little has been written about this tool, one of the most comprehensive definitions can be found on the Texterra agency website:
')
“The relevance map is a file in .excel format, which is created by our promotion department specialists before the start of promotion work. The relevance map is essentially a semantic core spanned by the site structure. In addition, the relevance map contains information on:
Perelinkov, ie internal links from the donor page to the acceptor page (the links that already exist and which will only be put down in the future) are reflected
Relevance of elements such as H1, Title, Description. ”(Texterra)
Here's what it looks like with them:

Why do we need a relevancy map?
In the same source we read:
“This document is constantly addressed when working with our seo-optimizers and copywriters. Thanks to it, there is no confusion and random errors, no sections appear that are relevant to those or other keys that should be present on completely different pages. For example, the relevant page is not yet available, but it is already displayed in the plan, and we know that on another page it is impossible to “pump up” text relevance on keys that are “booked” by another, as yet non-existent page. ” (Texterra)
Everything that is said is true, but we look at the example of the map in the screenshot and absolutely do not understand how you can work systematically with this tool:
In general, there are more questions than answers. Probably the article is outdated or a simplified version is used as an example.
Our relevance map option
First we decide what we need in this document:
1. Joint editing. Must be able to edit a few employees.
2. Filtering. The map contains a lot of different data, and therefore without filtering and sorting anywhere.
3. Visibility of the general structure of the site. This means that in the map it is clear which query to which section and subsection of the site is relevant.
4. Full information on semantics. Frequencies, pages on the site, meta tags, location according to sections of the site - it's convenient to see all this in one place.
The first requirement is easily solved with the help of Google SpreadSheet. A magic tool for collaborative editing, does almost everything the same as Excel, but also online.
Match the rest of the items more difficult. For this you have to turn to the theory of relational databases :)
Work with filtering
To conveniently work with filtering (again, there is no point in using tables! Write in notebook — you don’t feel the difference) you need to have a table in a normalized form, in this case it’s “1 normal form”.
“A table is in the first normal form (1NF) if and only if none of its rows contain more than one value in any of its fields and none of its key fields are empty.”
Simply put, a table should not have composite fields and empty important fields. In any row of the table you should understand what the data reflected in it belong to.
This is done easily, and looks like this:

In this case, we can use standard filtering and sorting. Each line separately contains all the necessary data for its identification. In the highlighted line it is clear that the request “bctp” refers to the group “BKTP”, which, in turn, refers to the section “Equipment”. The request has a frequency of 255.
Visibility of the general structure of the site
To do this, we built a pivot table for the source data. Below is a small piece of it.

In the agency, we are constantly working with the card, so we quickly realized that this option is not an option. And that's why:
In one document you need to store a lot of different data, but they all belong to two different entities. For example, the frequency refers to each request separately, but the page url refers to a group of requests. And so that everything in the table is correct, for all requests relating to the same page, specify the same url. A copywriter and a project manager are important map in the context of site pages, and for seo optimizer keywords are more important. In short nestykovochka.

It turns out such a hell.
Torn between the presentation of data “one line - one request” or “one line - one page”, we found, well, just amazing, in our opinion, solution. Combining two levels of abstraction in one table using scripts, we made our relevance map a two-faced, so to speak. There were two options for the presentation of the map, I will describe each of them in detail, so that it is clear how this was done and for what.
The first view is “One line - one request” . If we work at the request level, then our map looks like this:
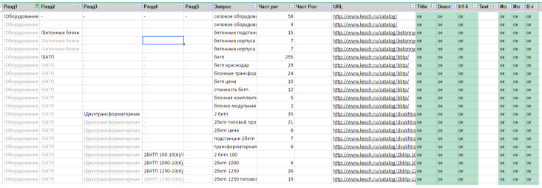
This view is “One line - one request”. All information is listed for each specific request. We can sort, filter them, do anything.
There are a number of chips that make it incredibly convenient:
In general, we filter everything up and down. We add new characteristics of requests, such as frequency, title, description and in general everything you need to know in terms of the request.
“One line - one page” view
Again, the previous view is great for working with queries, but as soon as we need to add data related to the page, there is an inconvenience. And here the idea “One line - one page” comes to the rescue. We write a small script, select the menu item “Group” in the Google Tables menu.
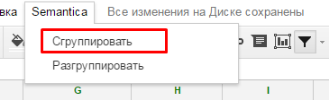
The script iterates over the rows in our table and groups all the data for each url. It turns out the following form:
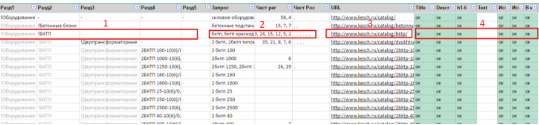
In this view, the data is indicated for each URL, that is, for each page.
Here:
The data sections (figure 1) - grouped
Request data (figure 2) - combined into one field separated by commas
URL Page Address (number 3) - grouped
Data on the page (figure 4) - grouped
Here's what you need from the presentation of the map in the context of pages:
Thus, in one file, all participants in the process see what has been done and planned.
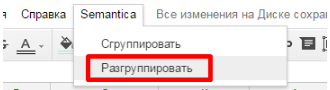
If we needed to return to the “One line - one request” view, but we click “Ungroup” and return to the previous view:
What did we get in the end?
We have a multi-level relevance map, which:
How do you work with semantics? Everyone has their own methods - let's share.
In the article we will share our vision of this tool and development experience.
What does the relevance map say on the Internet?
Little has been written about this tool, one of the most comprehensive definitions can be found on the Texterra agency website:
')
“The relevance map is a file in .excel format, which is created by our promotion department specialists before the start of promotion work. The relevance map is essentially a semantic core spanned by the site structure. In addition, the relevance map contains information on:
Perelinkov, ie internal links from the donor page to the acceptor page (the links that already exist and which will only be put down in the future) are reflected
Relevance of elements such as H1, Title, Description. ”(Texterra)
Here's what it looks like with them:
Why do we need a relevancy map?
In the same source we read:
“This document is constantly addressed when working with our seo-optimizers and copywriters. Thanks to it, there is no confusion and random errors, no sections appear that are relevant to those or other keys that should be present on completely different pages. For example, the relevant page is not yet available, but it is already displayed in the plan, and we know that on another page it is impossible to “pump up” text relevance on keys that are “booked” by another, as yet non-existent page. ” (Texterra)
Everything that is said is true, but we look at the example of the map in the screenshot and absolutely do not understand how you can work systematically with this tool:
- How to use multiple employees? If it is Excel, then to synchronize the changes will have to enter a separate position of the "Synchronizer".
- How to sort and filter? The structure of the document itself does not involve filtering, and this is very important when working with an array of data.
- How to understand which semantics belongs to which section of the site?
- How to select priority pages for work?
In general, there are more questions than answers. Probably the article is outdated or a simplified version is used as an example.
Our relevance map option
First we decide what we need in this document:
1. Joint editing. Must be able to edit a few employees.
2. Filtering. The map contains a lot of different data, and therefore without filtering and sorting anywhere.
3. Visibility of the general structure of the site. This means that in the map it is clear which query to which section and subsection of the site is relevant.
4. Full information on semantics. Frequencies, pages on the site, meta tags, location according to sections of the site - it's convenient to see all this in one place.
The first requirement is easily solved with the help of Google SpreadSheet. A magic tool for collaborative editing, does almost everything the same as Excel, but also online.
Match the rest of the items more difficult. For this you have to turn to the theory of relational databases :)
Work with filtering
To conveniently work with filtering (again, there is no point in using tables! Write in notebook — you don’t feel the difference) you need to have a table in a normalized form, in this case it’s “1 normal form”.
“A table is in the first normal form (1NF) if and only if none of its rows contain more than one value in any of its fields and none of its key fields are empty.”
Simply put, a table should not have composite fields and empty important fields. In any row of the table you should understand what the data reflected in it belong to.
This is done easily, and looks like this:
In this case, we can use standard filtering and sorting. Each line separately contains all the necessary data for its identification. In the highlighted line it is clear that the request “bctp” refers to the group “BKTP”, which, in turn, refers to the section “Equipment”. The request has a frequency of 255.
Visibility of the general structure of the site
To do this, we built a pivot table for the source data. Below is a small piece of it.
In the agency, we are constantly working with the card, so we quickly realized that this option is not an option. And that's why:
In one document you need to store a lot of different data, but they all belong to two different entities. For example, the frequency refers to each request separately, but the page url refers to a group of requests. And so that everything in the table is correct, for all requests relating to the same page, specify the same url. A copywriter and a project manager are important map in the context of site pages, and for seo optimizer keywords are more important. In short nestykovochka.
It turns out such a hell.
Torn between the presentation of data “one line - one request” or “one line - one page”, we found, well, just amazing, in our opinion, solution. Combining two levels of abstraction in one table using scripts, we made our relevance map a two-faced, so to speak. There were two options for the presentation of the map, I will describe each of them in detail, so that it is clear how this was done and for what.
The first view is “One line - one request” . If we work at the request level, then our map looks like this:
This view is “One line - one request”. All information is listed for each specific request. We can sort, filter them, do anything.
There are a number of chips that make it incredibly convenient:
- Up to 5 levels of sections / subsections are displayed (if necessary, more is possible);
- the screenshot below shows that in the first line the section name is visually highlighted, and subsequent similar names are darkened. Such allocations are made automatically using banal conditional formatting and greatly simplify the perception of the site structure;
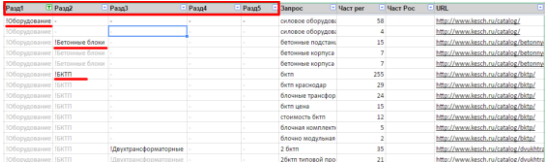
- You can filter so that requests are displayed only one section, or any subsection;
- It is possible to sort requests by frequency;
- We can easily copy the list of requests of interest and we don’t have to drag along a bunch of separate, unrelated lines. It is convenient, for example, to collect additional statistics in other services;
- You can see to which page which query belongs, you can filter queries related to only one page or group of pages.
In general, we filter everything up and down. We add new characteristics of requests, such as frequency, title, description and in general everything you need to know in terms of the request.
“One line - one page” view
Again, the previous view is great for working with queries, but as soon as we need to add data related to the page, there is an inconvenience. And here the idea “One line - one page” comes to the rescue. We write a small script, select the menu item “Group” in the Google Tables menu.
The script iterates over the rows in our table and groups all the data for each url. It turns out the following form:
In this view, the data is indicated for each URL, that is, for each page.
Here:
The data sections (figure 1) - grouped
Request data (figure 2) - combined into one field separated by commas
URL Page Address (number 3) - grouped
Data on the page (figure 4) - grouped
Here's what you need from the presentation of the map in the context of pages:
- You can copy pages as a list (for example, to check pages in the uniqueness check service);
- Mark the fact of doing any work related to the page. Anything can be added here: “Check for uniqueness”, “Check for text optimization”, “Check for page indexing”, etc. Do you check the texts according to the Zipf Law or are you passing through the Glavred service? Add a new field and record the fact of execution;
- The copywriter sees the required pages for which content has not yet been written.

Thus, in one file, all participants in the process see what has been done and planned.
If we needed to return to the “One line - one request” view, but we click “Ungroup” and return to the previous view:
What did we get in the end?
We have a multi-level relevance map, which:
- It is stored “in the cloud” and does not require additional synchronization;
- Allows you to conveniently work together;
- Allows you to visually see the entire structure of the site;
- Allows you to store information in the context of requests and at the same time work in the context of pages;
- With the help of scripts, you can change the presentation of data depending on the needs of each project participant;
- Using scripts, specify the data related to the page only once, and for each request of this page the data is duplicated automatically;
- Simplifies the dialogue with the copywriter. In fact, the map is a ready TK for each page of the site;
- gives all participants in the process a vision of the overall picture of the project.
How do you work with semantics? Everyone has their own methods - let's share.
Source: https://habr.com/ru/post/315576/
All Articles