Stripe Service Discovery
Every year there are so many new technologies (such as Kubernetes or Habitat ) that it is easy to forget about those tools that quietly and imperceptibly support our systems in commercial operation. One such tool that we have been using in Stripe for several years is Consul . Consul helps in the discovery of services (that is, it helps to find thousands of servers running on us with thousands of different services running on them and to report which ones are available for use). This effective and practical architectural solution was not something completely new and especially noticeable, but it faithfully and truly serves the business of providing reliable services to our users around the world.
In this article we are going to talk about the following:
- What is service discovery and consul.
- How we managed the risks arising from the implementation of a critical software product.
- The challenges we face and our responses to these challenges.
It is well known that it is impossible to simply take and install new software, hoping that it will somehow magically work and solve all problems. Using new software is a process. And this article describes an example of how the process of using new software for industrial operation turned out for us.
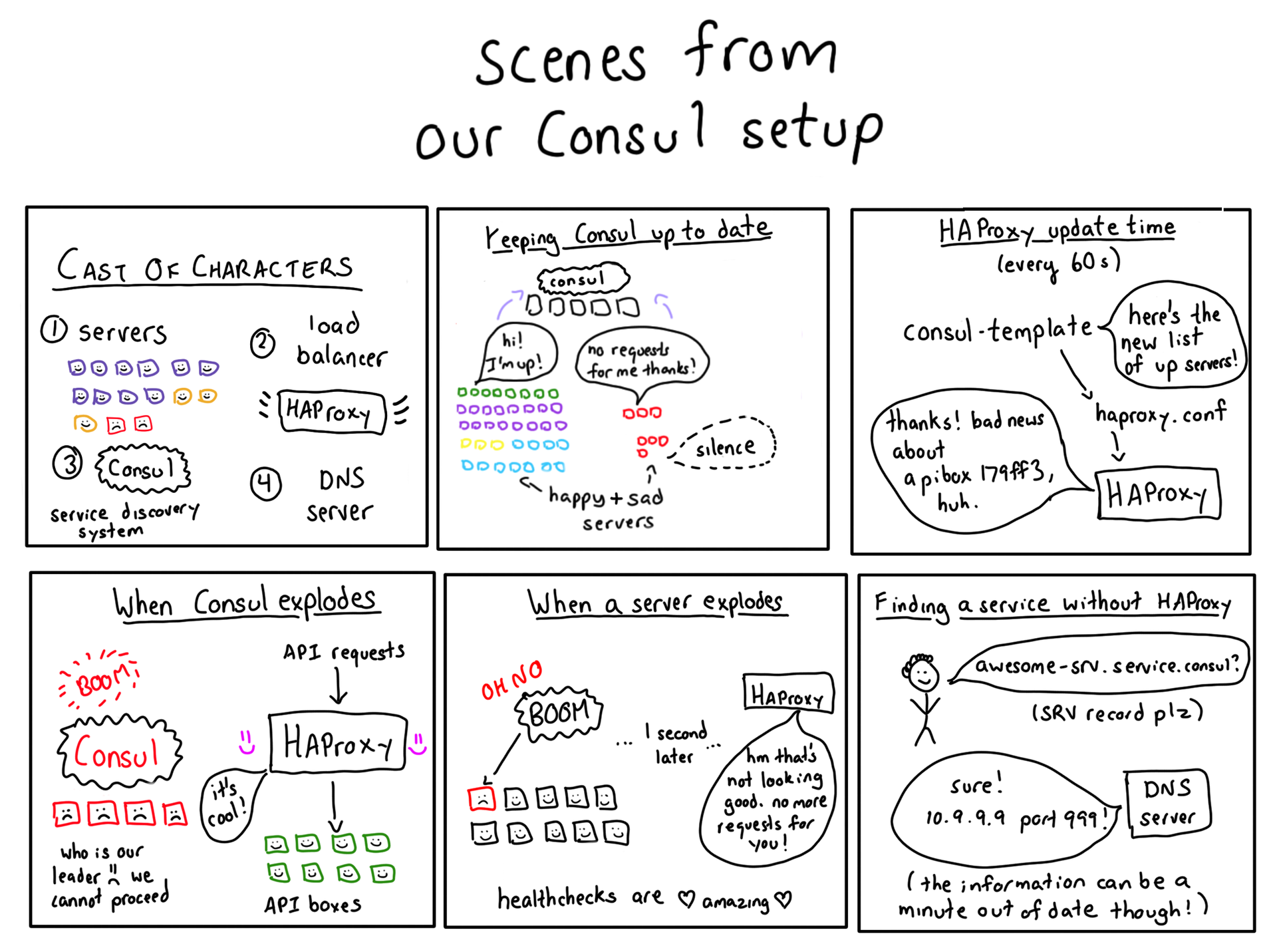
What is service discovery?
Great question! Imagine yourself being a Stripe load balancer. You are asked to make a payment, which you need to redirect to the API server. Any north API!
We have thousands of servers running various services. Which ones are API servers? What port is the API service running on? One of the great features of Amazon Web Services is that our instances can fail at any time, so we must be ready:
- lose any server api;
- add new servers to the turnover if additional power is needed.
Tracking changes in the availability status of network services is called service discovery. To do this, we use a tool called Consul, developed by HashiCorp .
The fact that our instances can fail at any moment actually helps a lot, since our infrastructure is constantly practiced, regularly losing instances and allowing such situations to occur automatically. Therefore, when an unexpected situation happens, nothing terrible happens. This is a common thing, routine. Moreover, it is much easier to work out failures when failures occur quite often.
Introduction to Consul
Consul is a service discovery tool that enables services to register and find other services. With the help of a special client, Consul records information about running services in the database, and other client software uses this database. There are a lot of component parts here - there is something to tinker with.
The most important part of Consul is the database. It contains entries of the type " api-service running on IP 10.99.99.99, port 12345. It is available."
Individual cars say Consul: “Hi! I'm running api-service , port 12345! I'm alive!"
Then, if you need to contact the API service, you can ask the Consul “Which of the api-services are available?” In response, it will return a list of the corresponding IP addresses and ports.
Consul itself is also a distributed system (remember that we can lose any machine at any time, and Consul as well!), Therefore, in order to keep the database in a synchronized state, Consul uses a consensus algorithm called Raft.
You can read about reaching a consensus in Consul here .
Consul in Stripe: Start
At the first stage, we limited ourselves to the configuration in which the machines with the Consul client on board wrote reports on their availability to the server. This information was not used to discover services. To set up such a system, we wrote the Puppet configuration, which was not so difficult!
In this way, we were able to identify potential problems with the Consul client and gain experience using it on thousands of machines. At the initial stage, we did not use Consul to detect any services.
What could go wrong here?
Memory leaks
If you put some kind of software on all the machines of your infrastructure, you definitely can start having problems. Almost immediately we ran into memory leaks in the Consul statistical library. We noticed that one of the machines took up more than 100 MB of RAM, and consumption was growing. All the fault was a mistake in the Consul, which we corrected .
100 MB is a small leak, but it has increased rapidly. In general, memory leaks pose a serious danger, since due to them only one process can completely paralyze the machine on which it is running.
It’s good that we didn’t use Consul to discover services from the very beginning! We managed to avoid serious problems and eliminate the errors found almost painlessly, because first we gave Consul to work on several combat servers, while monitoring memory consumption.
Getting started to discover services
Since we were confident that there would be no problem with the execution of Consul on our servers, we began to add clients polling Consul. To reduce risks, we did the following:
- for a start, Consul began to use limited;
- retained the backup system to continue to function during Consul interruptions.
Here are a few problems encountered. Here we are not trying to complain about the Consul, but rather we want to emphasize that when using a new technology, it is very important to deploy the system without haste and be careful.
A huge number of switching Raft. Remember that Consul uses a consensus protocol? It copies all data from one Consul cluster server to other servers in this cluster. The primary server had many problems with I / O: the disks were not fast enough and did not have time to fulfill all Consul wishes, which caused the primary server to hang completely. Raft said, “Oh, the primary server is again unavailable!”, Chose a new primary server, and this vicious cycle was repeated. While Consul was busy electing a new primary server, he blocked the database for writing and reading (as the default reads were set to consistent).
In version 0.3, SSL was completely broken. To ensure the secure exchange of data between our nodes, we used SSL Consul functionality (technically, TLS), which was successfully broken in the next release. We fixed it. This is an example of such problems that are easy to detect and which should not be feared (in the QA cycle, we realized that SSL is broken, and just did not begin to switch to a new release), but they are quite common in software that is in the early stages of development.
Goroutine leaks. We began to use the election of the leader Consul , and there was a leak goroutine, which led to the fact that Consul ate all the available memory. People from the Consul team helped us a lot in solving this problem, and we removed a few memory leaks (already others, not the ones we found earlier).
When all the problems were fixed, we were already in a much better position. The road from “our first customer Consul” to “we fixed all the problems in production” took a little less than a year of performing background work cycles.
Scale Consul to detect available services
So, we found and corrected several errors in Consul. Everything began to work much better. But remember what step we talked about at the beginning? Where do you ask Consul: “Hey, what machines are available for api-service ?” With such requests, we occasionally had problems: the Consul server responded slowly or did not respond at all.
This mainly occurred during raft switching or periods of instability. Since Consul uses a strictly consistent repository, its availability will always be worse than the availability of a system that does not have such limitations. Especially hard we had at the very beginning.
We were still switching, and the Consul interruptions became painful enough for us. In such situations, we switched to a hard-coded set of DNS names (for example, “apibox1”). When we first deployed Consul, this approach worked fine, but in the process of scaling and expanding the scope of Consul, it became less viable.
Consul Template to help
We could not rely on receiving from the Consul information about the availability of services (through its HTTP API). But in all other respects, he completely satisfied us!
We wanted to get information from Consul about available services not through its API. But how to do that?
OK, Consul takes a name (for example, monkey-srv ) and translates it into one or more IP addresses ("that's where monkey-srv lives"). Know who else gets the name of the input and returns the IP address? DNS server! In general, we replaced Consul with a DNS server. Here's how we did it: Consul Template is a Go program that generates static configuration files based on the Consul database.
We started using Consul Template to generate DNS records for Consul services. If monkey-srv was running on IP 10.99.99.99, we generated a DNS record:
monkey-srv.service.consul IN A 10.99.99.99 The code looks like this. And here you can find our working Consul Template configuration , which is a bit more complicated.
{{range service $service.Name}} {{$service.Name}}.service.consul. IN A {{.Address}} {{end}} If you say: “Wait, DNS records have only an IP address, and you also need a port!” Then you will be absolutely right! DNS A-records (the type that most often occurs) contain only an IP address. However, DNS SRV records can also have a port, so our Consul Template generates SRV records.
We run the Consul Template with cron every 60 seconds. The Consul Template also has a default watch mode (“watch” mode), in which configuration files are updated continuously as new information arrives in the database. When we first turned on the tracking mode, he put our Consul server on an excessive number of requests, so we decided to refuse it.
So, while our Consul server is unavailable, there are all the necessary records on the internal DNS server! Perhaps they are not quite fresh, but nothing terrible. Our DNS server has one remarkable feature: it is not a new-fashioned distributed megasystem, and relative simplicity makes it less prone to sudden breakdowns. That is, I can simply do nslookup monkey-srv.service.consul , get an IP and finally start working with my API service!
Since DNS is an inseparable, ultimately consistent system, we can cache and replicate it many times (we have 5 canonical DNS servers, each of which has a local DNS cache and information about the other 5 canonical servers). Therefore, our backup DNS system is simply by definition much more reliable Consul.
Add a load balancer for faster status checks
We just talked about updating DNS records based on Consul data every 60 seconds. So what happens when we lose the API server? Do we continue to send requests to this IP for about 45 seconds until the DNS is updated? Not! In this story there is another hero - HAProxy .
HAProxy is a load balancer. If you configure the appropriate checks, it can monitor the status of services to which requests are forwarded. All our API requests are actually going through HAProxy. Here is how it works.
- Consul Template every 60 seconds overwrites the HAProxy configuration file.
- Thus, HAProxy always has a more or less correct list of available internal servers.
- If the machine goes off-line, HAProxy finds out about it quickly enough (it performs checks every 2 seconds).
It turns out that we restart HAProxy every 60 seconds. But does this mean that we disconnect at the same time connections? Not. To avoid resetting connections during restarts, we use the HAProxy soft-restart function (graceful restart) . At the same time, there is a risk of losing a certain amount of network traffic ( according to this article ), but our traffic is not so large that it becomes a problem.
We use a standard endpoint for checking the status of services. Virtually every service has an end point / healthcheck , which will return 200 if the service is OK and will give errors if something went wrong. The presence of a standard is very important, as it helps us to easily set up state checks of services in HAProxy.
If Consul crashes, HAProxy remains in the presence of a slightly irrelevant, but quite workable configuration.
We change the consistency for availability
If you closely followed the narration, you might have noticed that the system we started with (strictly coordinated database, guaranteed to have all the updates), is very different from the system to which we arrived (DNS server, which may be late reaching up to one minute). The failure of consistency allowed us to create a much more responsive system, since the interruptions in the work of Consul have virtually no effect on our ability to discover services.
From here you can learn a useful lesson: consistency has its price! You need to be willing to pay for a system with good availability. And if you are going to use strict consistency, it is important to make sure that you need it.
What happens when you create a query
In this article, we have already managed to talk about a lot of things, so let's now look at the way in which the requests go, since we figured out how it works.
What happens when you request https://stripe.com/ ? How does this request get to the right server? Here is a somewhat simplified description.
- First, the request comes to one of our public load balancers, which runs HAProxy.
- Consul Template has already written a list of servers serving stripe.com in the /etc/haproxy.conf configuration file.
- HAProxy reloads its configuration every 60 seconds.
- HAProxy forwards the request to the stripe.com server, making sure it is available.
In real life, the process is not so simple (there is an additional layer, and Stripe API requests are more complicated, since we have systems that ensure compliance with the PCI standard), but the implementation is done according to the ideas described in this article.
This means that when we add or remove servers, Consul automatically updates the HAProxy configuration files. Hands do not need to do anything.
More than a year of peaceful life
There are still a lot of things left in our approach to discovering services that we would like to improve. To do this, first of all, we need active development, and we see opportunities to elegantly solve the integration of our planning infrastructure and query routing infrastructure.
However, we came to the conclusion that simple solutions are often also the most correct. The system described in the article has been reliably serving us for over a year without any incidents. While Stripe is far from Twitter or Facebook in terms of the number of requests processed, we try to achieve maximum reliability. Sometimes it happens that the most advantageous is not innovative, but a stable and well-performing solution.
')
Source: https://habr.com/ru/post/315468/
All Articles