Deconstruction of the myth of deep learning. Lecture in Yandex
Optimism about neural networks is not shared by everyone - or, at least, the level of such optimism is different. Sergey Bartunov , senior lecturer in the computer science department at the Higher School of Economics, agrees that the neural network area is on the rise. On the other hand, he wants to bring some clarity to what is happening, to determine the real potential of neural networks. Regardless of the speaker’s point of view, deep learning doesn’t really penetrate into our sphere at a very rapid pace. Traditional teaching methods are still working and will not necessarily be supplanted by machine intelligence in the near future.
Under the cut - a decoding of the lecture and part of Sergey’s slides.
In recent years, we have witnessed a series of major victories or, as far as we can, took part in them. These victories are expressed in the fact that the set of important machine learning tasks are unprecedentedly precisely solved using neural networks. As a result, there was a lot of noise far outside the scientific community, and many people paid attention to the area of deep learning.
')
Such attention can be very useful in terms of research funding, some start-ups. But it also stimulates the growth of expectations, some of which are frankly inadequate, and a bubble is inflated around deep learning.
My thesis is this: today, deep learning in the form in which it is presented to us by journalists or by some not very conscientious or not very knowledgeable experts in the subject is a modern myth. Today I want to deconstruct it, talk about what is really real, what is working, what is unlikely to work, what conclusions we can draw - or at least what conclusions I have drawn - and what can replace deep learning.
We are presented with a myth that has much in common with other well-known myths. For example, it has a story about a dark time, when true light knowledge is almost lost, is kept by only a few initiates, and chaos reigns in the world.
Even in this myth there are heroes who perform great epic feats.

In this myth there are also great feats themselves - they then remain in history and are told to each other by word of mouth.

And in this myth there is a taboo, a great ban. Having broken it, you can free up some powerful forces beyond the control of humanity.
Finally, this myth has its followers, who preferred serving the cult instead of objective reality.

Let's talk about what deep learning is in the mass consciousness. Firstly - a completely new technology, which had no analogues before.
Secondly - an attempt to reproduce the principles of the human brain or even surpass them.
And finally, this is a universal magic black box that can be downloaded, inserted somewhere between effort and profit, and which itself will work so that everything will become much better.
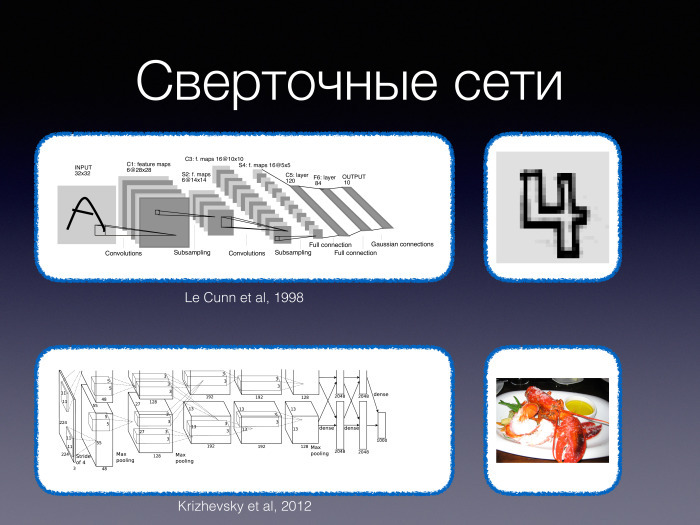
Let's talk about the novelty. There is such an example that many of the successes of deep learning - primarily related to computer vision tasks, and all the rest - began with the historical work of 2012, when two graduate students and one scientific leader trained a large convolutional network and with a large margin won the image recognition competition ImageNet. Many conversations that this is our future began with this work. And many people began to perceive the technology under discussion as something completely new - while the first articles on convolutional networks date back to the mid-90s. Of course, then they were much smaller, and the images with which they worked were much simpler, but nonetheless.

Another good example is recurrent networks. The well-known model of seq to seq, sequence to sequence of learning, allows, for example, machine translation or build interactive systems. She also made a lot of noise. When I read examples of philosophical dialogues with this system, my chill ran down my back, because the example from the article has some meaning. And again, many spoke that we were approaching some kind of artificial intelligence, and there was also a feeling that we were talking about something completely new.
It really was a new model, a new neural network architecture, and the result is, in fact, unique. However, it can be noted that the components of this network, which are responsible for recognizing, say, the input question and generating the answer, are a rather well-known recurrent architecture, and it is known as long short-term memory or LSTM. It was proposed as much as in 1997 - almost 20 years ago.
And here, quite a fresh breakthrough, dispelling all doubts about whether strong artificial intelligence is waiting for us. This is a flexible network, a system from Google DeepMind, which on raw frames from the Atari game emulator was able to learn how to play them, and better than individuals. This, of course, also caused a lot of noise.
Interestingly, this is a historical result, but another is also true: the part of this system that is directly responsible for intelligence, for making decisions, for the principles of Q-learning, was proposed already in 1989 in the dissertation, in my opinion, by Christopher Watkins.

What has changed in these 20 years? Why did neural networks once be an outsider technology, everyone joked and mocked researchers in this area, and now everything is a little bit the other way around?
In the first place, computers became faster and cheaper, and parallel computing technologies — including computing on graphics accelerators — appeared and became mainstream. This made it possible to train large models.
There is more data. The mentioned ImageNet contest and data set for it consists of 14 million tagged objects in 21 thousand categories. Objects are marked up by people. Although this data set was created for only one task, for classifying images, thanks to it, such cool applications as Prisma appeared, transfer of styles, and not all of the potential was probably extracted. A qualitative transition in the availability of training data was needed.
Finally, some experience in machine learning has become commonplace. For example, works have appeared on how to properly train and initialize such networks; there is more understanding of how they actually work and structure.

Let's see how a neural network is a black magic box. Suppose you need to solve the problem of sorting all arrays of real numbers of four elements. Imagine a universal approximator, a universal black network capable of coping with such tasks — your favorite architecture.
Now imagine that the same architecture solves the problem of determining the rank of a matrix using its heat map, which you obtained using your favorite data analysis tool - MATLAB or some Python library. I don’t know what you think, but it seems to me very unlikely that the same neural network architecture will effectively solve many different tasks, equally effectively analyze the most different types of data and generally work in the most different modes.
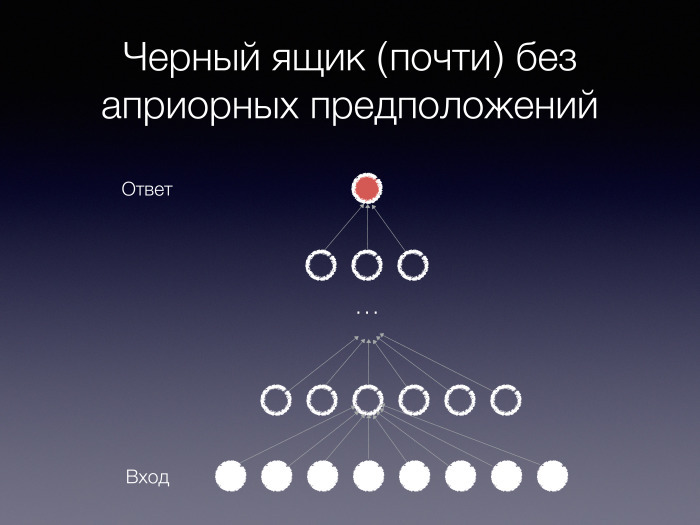
In fact, there really is such a black box - it is called a multilayer perceptron. This is the simplest neural network architecture that uses very few a priori assumptions about the problem to be solved. It is arranged simply as several layers of neurons. Each neuron accepts inputs from all neurons of the previous layer, performs some transformations on them and transmits them on the same principle further, upward. At the end we calculate the answer.
It is known that such an architecture is theoretically a universal approximator for continuous functions. There are many different universal approximants, not just multilayer perceptrons. There are different classes of functions in which they can approximate everything. And there is such a fact.
It is interesting that in practice it turns out that such universal black boxes are, first of all, excessively parameterized, that is, this connectivity of each neuron with each neuron from the previous layer is deeply redundant. A part of these links, if not harmful, is absolutely superfluous. By the weights of individual neurons, weights of other neurons can be predicted.
In addition, we expect that the deeper this box, the better it works. In theory, probably it is, but in practice it often turns out that its expressive ability can fall with increasing depth, the number of layers.
Strangely enough, such a black box is relatively rarely used in practical applications.

For example, convolution networks are often used for computer vision problems. And there is not such a black box. They use much more a priori knowledge about the problem being solved, a priori assumptions - let's look at an example of which ones.
To begin with, we want to ensure the invariance of relatively small displacements and rotations of the image. We want this to not affect the result of the classification. We achieve this, for example, using the pooling operation. We partially remove this question.
In addition, there is a powerful prior knowledge that we need to reuse the parameters. When we perform a convolution operation, we apply the same filter, the same weights, to different parts of the image. We could, of course, learn such a mechanism in a multilayer perceptron, but, apparently, so far very few people have succeeded, if it was possible at all. And here we impose very strong restrictions, we introduce a lot of structures into our model.
Finally, we assume that our image has a certain hierarchical nature and that the levels of this hierarchy are approximately the same.
Agree: all this can not be called a black box, where we build the minimum number of assumptions. We bring in a lot of a priori knowledge.
And here is an example of a convolutional network that shows some of the best results at the moment in the ImageNet competition. This is Inception-ResNet. The block marked in red actually looks like this. The next block looks like this and the next one.
Inception-ResNet has a very complex structure. It is not quite clear why such asymmetries are needed here, such a complex connectivity between network elements. And here we use even more a priori knowledge not only about the problem being solved, but also about the training method that we use to set up this network. Here we prokkidyvaem short links between the layers. They bypass several layers of the network so that the gradients spread better around the intermediate number of layers. Here we use the so-called principle of residual learning - we assume that each next layer does not just change the input of the previous one, but tries to correct, correct errors made to it. There are a lot of a priori assumptions.
In other words, a more efficient neural network architecture uses more accurate a priori assumptions, it is better with the information about the tasks to be solved.
In deep learning there was a level of increasing abstraction of a priori assumptions. If earlier we coded the signs manually, now we know approximately how interesting signs should be arranged, and they will learn. But we still do not have a black box that will decide everything for us.
The general trend is expressed in the following: we want to have trained black boxes, about which we understand little. Only this is not one big black box, but many small ones — linked together and working in a bundle. A good example is the model for image captioning, to generate a description. A rather complex convolutional network and a recurrent network that generates words work in the bundle. there is also a memory mechanism — many black boxes that we set up so that they work together.

There is also an interesting thesis that neural networks work better than humans. For some of the tasks, it is. In the same ImageNet competition, there are several categories where neural networks have higher accuracy than some people.
But neural networks are capable of making mistakes. I will give an example of a neural network error. Google Photos was used to automatically classify, and some black people in the photo were identified as gorillas. I do not really want to speculate on this example - there are many reasons why this could happen, and they do not necessarily have to do with deep learning, with neural networks.
But there is another example of a directional attack, when some special noise imperceptible to the human eye is added to the image of a panda, causing an advanced good neural network to define the image as a gibbon, and with a very high level of confidence.
Not that these examples should demonstrate some kind of helplessness of neural networks compared to human intelligence. It is also simple in computer vision - where, it would seem, many, if not all, tasks are solved, then many - there is something to be done even in fairly basic tasks.

Deep learning is really great that you can train large and very large models on large amounts of data. This is possible thanks to the use of the stochastic gradient optimization apparatus. If our task can be presented as the minimization of the expectation of a certain function — where we have some perfect value ξ and the norm of the parameters θ — then we want to find the best parameters for all possible values of θ. And such stochasticity, such expectation, can arise in different situations - for example, when we average over the entire training sample. In other words, a random variable is responsible for selecting an object from the sample. And if we average over all objects, it will be like going through all the objects, counting the loss function, and then averaging.
Or θ may be some internal noise or uncertainty. For example, in the generative models mentioned today, this principle is used. There is some random noise, which then turns into, say, a photograph of a human face. Here is also an example of such stochasticity.
It's great that almost nothing depends on the f function. We have a universal method of minimizing such functions, the so-called stochastic gradient descent, which many have heard about and which does not require us to calculate all this great expectation. The value of a function or its gradient at a single random point in a random variable suffices.
The use of gradient optimization methods allows us to decompose our entire machine learning system into such components: into a model, into a loss function, into an optimizer — which is a very important element of the success of our learning. Different optimization methods can give a radically different rate of convergence and a radically different quality after some number of iterations.
Interestingly, this is somewhat reminiscent of the model model-view controller, which is sometimes found in programming. Maybe something follows from here.

When we fixed loss functions and an optimizer, we can concentrate only on our model. We can give it to hungry graduate students, students or engineers and say that we want 95% quality. And they can, using their knowledge, their creative abilities, combine, compose different models from different pieces, try, change the model in a single framework of gradient optimization. And in the end they can overcome the threshold of the desired value.
How do people build neural networks in the modern world? If the network does not require a special approach, then it is enough to take some simple existing library like keras, as in this example, to determine the structure of the neural network, after which a computation graph will be automatically built to train this model. There is a model itself, data is coming in, gradients from the loss function are automatically considered. There is an optimizer - it updates the network weights. All this can work on different devices, not necessarily on your computer. It can even work on multiple computers in parallel. This is a great abstraction. It makes one wonder if, in general, do we need the metaphor of neural networks now?
If we know that we want to use a stochastic gradient descent or some other gradient methods for adjusting the weights, then why should we draw parallels with some supposed neurons in our head? I am not ready to talk in detail about this - I do not know how our brain works. But it seems to me that these metaphors are largely harmful and do not always correspond to the real state of affairs.
However, the rejection of the parallel with the real neural networks can give us more than it seems. If we move from the term “neural network” to the term “differentiable function,” we will greatly expand the basis of functions from which new models can be built. And maybe their expressive power will only increase.

There are a lot of initiatives where they are trying to make such a transition. This deserves a separate report. But I would like to convey a few things that seem very useful to me and that researchers in the field of deep learning should learn from related disciplines related to programming.
First of all, suppose that we either know that the function that we optimize must be, say, differentiable or smooth, or impose some other restrictions. We also assume that we know that this property is preserved in relation to closed operations — composition, addition, and something else. Under these conditions, we can, in a programming language with an advanced type system, test differentiability, smoothness, some other properties completely stochastically at the compilation stage.
Finally, I really like the idea of embedding small “black boxes”, differentiable functions, into ordinary programming languages. , , : , , , , . , . , .
— - , . , , .
Topcoder - , , , , — , . - . .
, , . .
, , , — , . ?
, , . , — , .
, , , . — - .
.

, . . , , . , : . , .
. ImageNet. : DQN AlphaGo. , . DQN , , , , . 10 , 10 , - .
AlphaGo ( — . .) 30 , . , .
. , «» , . -, - . , .

, , — . , . , , - .
— , - . . Thanks for attention.
Under the cut - a decoding of the lecture and part of Sergey’s slides.
In recent years, we have witnessed a series of major victories or, as far as we can, took part in them. These victories are expressed in the fact that the set of important machine learning tasks are unprecedentedly precisely solved using neural networks. As a result, there was a lot of noise far outside the scientific community, and many people paid attention to the area of deep learning.
')
Such attention can be very useful in terms of research funding, some start-ups. But it also stimulates the growth of expectations, some of which are frankly inadequate, and a bubble is inflated around deep learning.
My thesis is this: today, deep learning in the form in which it is presented to us by journalists or by some not very conscientious or not very knowledgeable experts in the subject is a modern myth. Today I want to deconstruct it, talk about what is really real, what is working, what is unlikely to work, what conclusions we can draw - or at least what conclusions I have drawn - and what can replace deep learning.
We are presented with a myth that has much in common with other well-known myths. For example, it has a story about a dark time, when true light knowledge is almost lost, is kept by only a few initiates, and chaos reigns in the world.
Even in this myth there are heroes who perform great epic feats.
In this myth there are also great feats themselves - they then remain in history and are told to each other by word of mouth.
And in this myth there is a taboo, a great ban. Having broken it, you can free up some powerful forces beyond the control of humanity.
Finally, this myth has its followers, who preferred serving the cult instead of objective reality.
Let's talk about what deep learning is in the mass consciousness. Firstly - a completely new technology, which had no analogues before.
Secondly - an attempt to reproduce the principles of the human brain or even surpass them.
And finally, this is a universal magic black box that can be downloaded, inserted somewhere between effort and profit, and which itself will work so that everything will become much better.
Let's talk about the novelty. There is such an example that many of the successes of deep learning - primarily related to computer vision tasks, and all the rest - began with the historical work of 2012, when two graduate students and one scientific leader trained a large convolutional network and with a large margin won the image recognition competition ImageNet. Many conversations that this is our future began with this work. And many people began to perceive the technology under discussion as something completely new - while the first articles on convolutional networks date back to the mid-90s. Of course, then they were much smaller, and the images with which they worked were much simpler, but nonetheless.
Another good example is recurrent networks. The well-known model of seq to seq, sequence to sequence of learning, allows, for example, machine translation or build interactive systems. She also made a lot of noise. When I read examples of philosophical dialogues with this system, my chill ran down my back, because the example from the article has some meaning. And again, many spoke that we were approaching some kind of artificial intelligence, and there was also a feeling that we were talking about something completely new.
It really was a new model, a new neural network architecture, and the result is, in fact, unique. However, it can be noted that the components of this network, which are responsible for recognizing, say, the input question and generating the answer, are a rather well-known recurrent architecture, and it is known as long short-term memory or LSTM. It was proposed as much as in 1997 - almost 20 years ago.
And here, quite a fresh breakthrough, dispelling all doubts about whether strong artificial intelligence is waiting for us. This is a flexible network, a system from Google DeepMind, which on raw frames from the Atari game emulator was able to learn how to play them, and better than individuals. This, of course, also caused a lot of noise.
Interestingly, this is a historical result, but another is also true: the part of this system that is directly responsible for intelligence, for making decisions, for the principles of Q-learning, was proposed already in 1989 in the dissertation, in my opinion, by Christopher Watkins.
What has changed in these 20 years? Why did neural networks once be an outsider technology, everyone joked and mocked researchers in this area, and now everything is a little bit the other way around?
In the first place, computers became faster and cheaper, and parallel computing technologies — including computing on graphics accelerators — appeared and became mainstream. This made it possible to train large models.
There is more data. The mentioned ImageNet contest and data set for it consists of 14 million tagged objects in 21 thousand categories. Objects are marked up by people. Although this data set was created for only one task, for classifying images, thanks to it, such cool applications as Prisma appeared, transfer of styles, and not all of the potential was probably extracted. A qualitative transition in the availability of training data was needed.
Finally, some experience in machine learning has become commonplace. For example, works have appeared on how to properly train and initialize such networks; there is more understanding of how they actually work and structure.
Let's see how a neural network is a black magic box. Suppose you need to solve the problem of sorting all arrays of real numbers of four elements. Imagine a universal approximator, a universal black network capable of coping with such tasks — your favorite architecture.
Now imagine that the same architecture solves the problem of determining the rank of a matrix using its heat map, which you obtained using your favorite data analysis tool - MATLAB or some Python library. I don’t know what you think, but it seems to me very unlikely that the same neural network architecture will effectively solve many different tasks, equally effectively analyze the most different types of data and generally work in the most different modes.
In fact, there really is such a black box - it is called a multilayer perceptron. This is the simplest neural network architecture that uses very few a priori assumptions about the problem to be solved. It is arranged simply as several layers of neurons. Each neuron accepts inputs from all neurons of the previous layer, performs some transformations on them and transmits them on the same principle further, upward. At the end we calculate the answer.
It is known that such an architecture is theoretically a universal approximator for continuous functions. There are many different universal approximants, not just multilayer perceptrons. There are different classes of functions in which they can approximate everything. And there is such a fact.
It is interesting that in practice it turns out that such universal black boxes are, first of all, excessively parameterized, that is, this connectivity of each neuron with each neuron from the previous layer is deeply redundant. A part of these links, if not harmful, is absolutely superfluous. By the weights of individual neurons, weights of other neurons can be predicted.
In addition, we expect that the deeper this box, the better it works. In theory, probably it is, but in practice it often turns out that its expressive ability can fall with increasing depth, the number of layers.
Strangely enough, such a black box is relatively rarely used in practical applications.
For example, convolution networks are often used for computer vision problems. And there is not such a black box. They use much more a priori knowledge about the problem being solved, a priori assumptions - let's look at an example of which ones.
To begin with, we want to ensure the invariance of relatively small displacements and rotations of the image. We want this to not affect the result of the classification. We achieve this, for example, using the pooling operation. We partially remove this question.
In addition, there is a powerful prior knowledge that we need to reuse the parameters. When we perform a convolution operation, we apply the same filter, the same weights, to different parts of the image. We could, of course, learn such a mechanism in a multilayer perceptron, but, apparently, so far very few people have succeeded, if it was possible at all. And here we impose very strong restrictions, we introduce a lot of structures into our model.
Finally, we assume that our image has a certain hierarchical nature and that the levels of this hierarchy are approximately the same.
Agree: all this can not be called a black box, where we build the minimum number of assumptions. We bring in a lot of a priori knowledge.
And here is an example of a convolutional network that shows some of the best results at the moment in the ImageNet competition. This is Inception-ResNet. The block marked in red actually looks like this. The next block looks like this and the next one.
Inception-ResNet has a very complex structure. It is not quite clear why such asymmetries are needed here, such a complex connectivity between network elements. And here we use even more a priori knowledge not only about the problem being solved, but also about the training method that we use to set up this network. Here we prokkidyvaem short links between the layers. They bypass several layers of the network so that the gradients spread better around the intermediate number of layers. Here we use the so-called principle of residual learning - we assume that each next layer does not just change the input of the previous one, but tries to correct, correct errors made to it. There are a lot of a priori assumptions.
In other words, a more efficient neural network architecture uses more accurate a priori assumptions, it is better with the information about the tasks to be solved.
In deep learning there was a level of increasing abstraction of a priori assumptions. If earlier we coded the signs manually, now we know approximately how interesting signs should be arranged, and they will learn. But we still do not have a black box that will decide everything for us.
The general trend is expressed in the following: we want to have trained black boxes, about which we understand little. Only this is not one big black box, but many small ones — linked together and working in a bundle. A good example is the model for image captioning, to generate a description. A rather complex convolutional network and a recurrent network that generates words work in the bundle. there is also a memory mechanism — many black boxes that we set up so that they work together.
There is also an interesting thesis that neural networks work better than humans. For some of the tasks, it is. In the same ImageNet competition, there are several categories where neural networks have higher accuracy than some people.
But neural networks are capable of making mistakes. I will give an example of a neural network error. Google Photos was used to automatically classify, and some black people in the photo were identified as gorillas. I do not really want to speculate on this example - there are many reasons why this could happen, and they do not necessarily have to do with deep learning, with neural networks.
But there is another example of a directional attack, when some special noise imperceptible to the human eye is added to the image of a panda, causing an advanced good neural network to define the image as a gibbon, and with a very high level of confidence.
Not that these examples should demonstrate some kind of helplessness of neural networks compared to human intelligence. It is also simple in computer vision - where, it would seem, many, if not all, tasks are solved, then many - there is something to be done even in fairly basic tasks.
Deep learning is really great that you can train large and very large models on large amounts of data. This is possible thanks to the use of the stochastic gradient optimization apparatus. If our task can be presented as the minimization of the expectation of a certain function — where we have some perfect value ξ and the norm of the parameters θ — then we want to find the best parameters for all possible values of θ. And such stochasticity, such expectation, can arise in different situations - for example, when we average over the entire training sample. In other words, a random variable is responsible for selecting an object from the sample. And if we average over all objects, it will be like going through all the objects, counting the loss function, and then averaging.
Or θ may be some internal noise or uncertainty. For example, in the generative models mentioned today, this principle is used. There is some random noise, which then turns into, say, a photograph of a human face. Here is also an example of such stochasticity.
It's great that almost nothing depends on the f function. We have a universal method of minimizing such functions, the so-called stochastic gradient descent, which many have heard about and which does not require us to calculate all this great expectation. The value of a function or its gradient at a single random point in a random variable suffices.
The use of gradient optimization methods allows us to decompose our entire machine learning system into such components: into a model, into a loss function, into an optimizer — which is a very important element of the success of our learning. Different optimization methods can give a radically different rate of convergence and a radically different quality after some number of iterations.
Interestingly, this is somewhat reminiscent of the model model-view controller, which is sometimes found in programming. Maybe something follows from here.
When we fixed loss functions and an optimizer, we can concentrate only on our model. We can give it to hungry graduate students, students or engineers and say that we want 95% quality. And they can, using their knowledge, their creative abilities, combine, compose different models from different pieces, try, change the model in a single framework of gradient optimization. And in the end they can overcome the threshold of the desired value.
How do people build neural networks in the modern world? If the network does not require a special approach, then it is enough to take some simple existing library like keras, as in this example, to determine the structure of the neural network, after which a computation graph will be automatically built to train this model. There is a model itself, data is coming in, gradients from the loss function are automatically considered. There is an optimizer - it updates the network weights. All this can work on different devices, not necessarily on your computer. It can even work on multiple computers in parallel. This is a great abstraction. It makes one wonder if, in general, do we need the metaphor of neural networks now?
If we know that we want to use a stochastic gradient descent or some other gradient methods for adjusting the weights, then why should we draw parallels with some supposed neurons in our head? I am not ready to talk in detail about this - I do not know how our brain works. But it seems to me that these metaphors are largely harmful and do not always correspond to the real state of affairs.
However, the rejection of the parallel with the real neural networks can give us more than it seems. If we move from the term “neural network” to the term “differentiable function,” we will greatly expand the basis of functions from which new models can be built. And maybe their expressive power will only increase.
There are a lot of initiatives where they are trying to make such a transition. This deserves a separate report. But I would like to convey a few things that seem very useful to me and that researchers in the field of deep learning should learn from related disciplines related to programming.
First of all, suppose that we either know that the function that we optimize must be, say, differentiable or smooth, or impose some other restrictions. We also assume that we know that this property is preserved in relation to closed operations — composition, addition, and something else. Under these conditions, we can, in a programming language with an advanced type system, test differentiability, smoothness, some other properties completely stochastically at the compilation stage.
Finally, I really like the idea of embedding small “black boxes”, differentiable functions, into ordinary programming languages. , , : , , , , . , . , .
— - , . , , .
Topcoder - , , , , — , . - . .
, , . .
, , , — , . ?
, , . , — , .
, , , . — - .
.
, . . , , . , : . , .
. ImageNet. : DQN AlphaGo. , . DQN , , , , . 10 , 10 , - .
AlphaGo ( — . .) 30 , . , .
. , «» , . -, - . , .
, , — . , . , , - .
— , - . . Thanks for attention.
Source: https://habr.com/ru/post/315138/
All Articles