Deep Learning: Transfer learning and fine tuning of deep convolutional neural networks
In a previous article in the Deep Learning series, you learned about comparing frameworks for symbolic deep learning. This material will focus on deep tuning of convolutional neural networks to increase the average accuracy and efficiency of medical image classification.

1. Comparison of frameworks for symbolic deep learning .
2. Transfer learning and fine tuning of deep convolutional neural networks .
3. A combination of a deep convolutional neural network with a recurrent neural network .
Note: further narration will be conducted on behalf of the author.
')
A common cause of vision loss is diabetic retinopathy (DR) - an eye disease in diabetes. Examining patients with fluorescent angiography has the potential to reduce the risk of blindness. Existing research trends show that deep convolutional neural networks (GNSS) are very effective for automatically analyzing large sets of images and for identifying the distinctive features by which you can distribute images into different categories with virtually no errors. Learning for GNSS rarely occurs from scratch due to the lack of predetermined sets with a sufficient number of images pertaining to a specific area. Since it takes 2–3 weeks to train modern GNSS, the Berkley Vision and Learning Center (BVLC) has released final control points for GNSS. In this publication, we use a previously trained network: GoogLeNet. GoogLeNet is trained on a large set of natural ImageNet images. We transfer the recognized ImageNet weights as initial ones for the network, then we set up a previously trained universal network for recognizing images of fluorescent angiography of the eyes and improving the accuracy of prediction of PD.
At the moment, extensive work has been done on the development of algorithms and image processing techniques for explicitly identifying the distinctive features characteristic of patients with DR. The standard image classification uses the following universal workflow:
Oliver Faust and his other colleagues provide a very detailed analysis of models using explicit identification of the distinctive features of the DR. Vuyosevich and his colleagues created a binary classifier on the basis of a set of data from 55 patients, clearly identifying individual distinguishing signs of lesions. Some authors used the methods of morphological image processing to extract the distinctive signs of blood vessels and bleeding, and then trained the reference vector machine on a data set of 331 images. Other experts report 90% accuracy and 90% sensitivity in the binary classification problem on a data set of 140 images.
Nevertheless, all these processes are associated with significant time and effort. To further improve the accuracy of predictions, huge amounts of tagged data are required. Image processing and the identification of distinctive features in image data sets is a very complex and lengthy process. Therefore, we decided to automate image processing and the stage of identifying distinctive features using GNSS.
To highlight the distinctive features in the images requires expert knowledge. The selection functions in the GPSS automatically generate images for specific areas without using any distinctive feature processing. Thanks to this process, the GPSS is suitable for image analysis:

Layers C - convolutions, layers S - pools and selections
Convolution . Convolutional layers consist of a rectangular network of neurons. The weights are the same for each neuron in the convolutional layer. The weights of the convolutional layer determine the convolution filter.
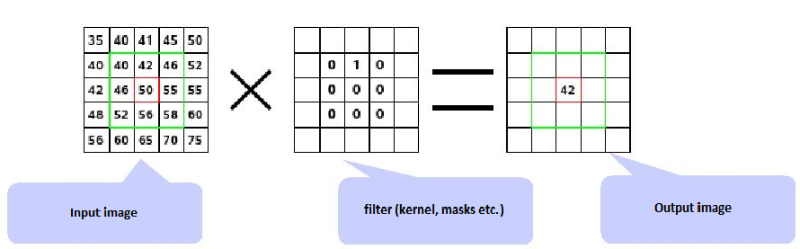
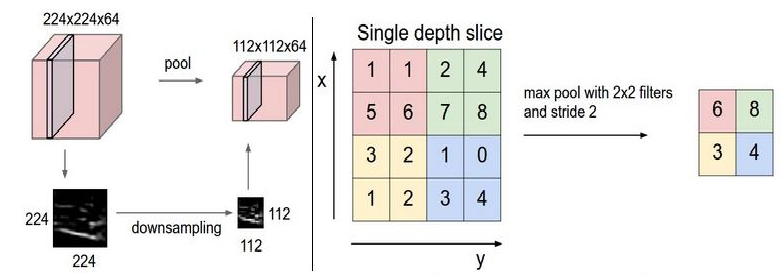
Poll The pooling layer takes small rectangular blocks from the convolutional layer and conducts a subsample to make one exit from this block.
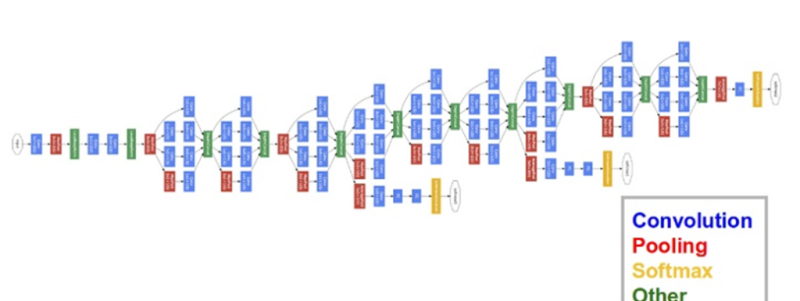
In this publication, we are using Google’s GoogLeNet. The neural network GoogLeNet won the ImageNet competition in 2014, setting a record for the best one-time results. The reasons for choosing this model are the depth of work and the economical use of architecture resources.
In practice, learning of whole GNSS is usually not performed from scratch with arbitrary initialization. The reason is that it is usually not possible to find a dataset of sufficient size required for the network of the desired depth. Instead, pre-learning of the GNSS on a very large data set most often occurs, and then using the weights of the trained GNSS either as initialization or as a distinction for the specific task.
Fine tuning . Learning transfer strategies depend on various factors, but two are the most important: the size of the new data set and its similarity to the original data set. If we consider that the nature of the work of the GNSS is more universal in the early layers and becomes more closely related to a specific data set on the subsequent layers, we can distinguish four main scenarios:
Fine-tuning the GNSS . Solving the question of predicting the DR, we act on scenario IV. We carry out the fine-tuning of the weights in advance by the trained GNSS, continuing the reverse propagation. You can either fine-tune all layers of the GPSN system, or leave some of the earlier layers unchanged (to avoid over-fitting) and configure only the high-level part of the network. This is because the early layers of the GNSS contain more versatile functions (for example, the definition of edges or colors) that are useful for a variety of tasks, and the later layers of the GNSS are already oriented towards the classes of the DR data set.
Limitations of transfer learning . Because we use a pre-trained network, our choice of model architecture is somewhat limited. For example, we cannot arbitrarily remove convolutional layers from a previously trained model. However, by sharing the parameters, you can easily launch a pre-trained network for images of different spatial sizes. This is most obvious in the case of convolutional and selective layers, since their redirection function does not depend on the spatial size of the input data. In the case of fully connected layers, this principle is preserved, since fully connected layers can be transformed into a convolutional layer.
Learning speed We use a reduced learning rate for GNSS weights that are finely tuned, assuming that the quality of the weights of a pre-trained GNSS is relatively high. These data should not be distorted too quickly or too much; therefore, both the learning rate and the drop rate should be relatively low.
Supplement data . One of the drawbacks of irregular neural networks is their excessive flexibility: they are equally well trained in recognizing both garment details and interferences, which increase the likelihood of over-fitting. We apply Tikhonov's regularization (or L2 regularization) to avoid this. However, even after that, there was a significant performance gap between learning and verifying DR images, indicating an over-fit during the fine-tuning process. To eliminate this effect, we apply data addition to a set of image data DR.
There are many ways to complement data, for example, mirroring horizontally, random cropping, changing colors. Since the color information of these images is very important, we apply only the rotation of the images to different angles: 0, 90, 180 and 270 degrees.
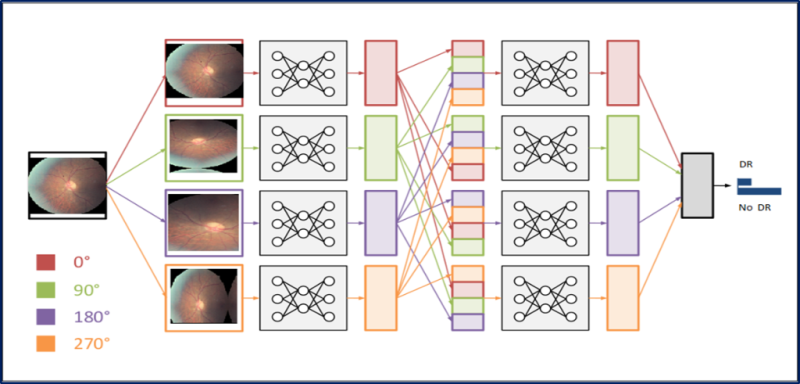
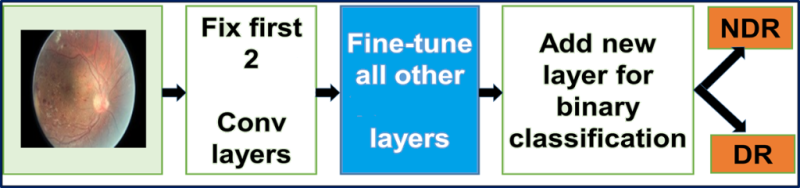
Replacing the input layer of the pre-trained GoogLeNet network with DR images. We perform fine tuning of all layers, except for the two upper pre-trained layers containing universal weights.
Tweaking GoogLeNet. The GoogLeNet network we used was initially trained on the ImageNet dataset. The ImageNet dataset contains about 1 million natural images and 1000 tags / categories. Our tagged DR data set contains about 30,000 images pertaining to the area in question, and four tags / categories. Consequently, this DR data set is not enough to train a complex network like GoogLeNet: we will use weights from GoogLeNet, trained on ImageNet. We perform fine tuning of all layers, except for the two upper pre-trained layers containing universal weights. The initial loss3 / classifier classification layer provides predictions for 1000 classes. We are replacing it with a new binary layer.
Thanks to the fine-tuning, it is possible to apply advanced GPSN models in new areas where it would be impossible to use them otherwise due to lack of data or time and cost constraints. This approach allows to achieve a significant increase in the average accuracy and efficiency of the classification of medical images.
If you see an inaccuracy of the translation, please let us know in your private messages.
The series of articles "Deep Learning"
1. Comparison of frameworks for symbolic deep learning .
2. Transfer learning and fine tuning of deep convolutional neural networks .
3. A combination of a deep convolutional neural network with a recurrent neural network .
Note: further narration will be conducted on behalf of the author.
')
Introduction
A common cause of vision loss is diabetic retinopathy (DR) - an eye disease in diabetes. Examining patients with fluorescent angiography has the potential to reduce the risk of blindness. Existing research trends show that deep convolutional neural networks (GNSS) are very effective for automatically analyzing large sets of images and for identifying the distinctive features by which you can distribute images into different categories with virtually no errors. Learning for GNSS rarely occurs from scratch due to the lack of predetermined sets with a sufficient number of images pertaining to a specific area. Since it takes 2–3 weeks to train modern GNSS, the Berkley Vision and Learning Center (BVLC) has released final control points for GNSS. In this publication, we use a previously trained network: GoogLeNet. GoogLeNet is trained on a large set of natural ImageNet images. We transfer the recognized ImageNet weights as initial ones for the network, then we set up a previously trained universal network for recognizing images of fluorescent angiography of the eyes and improving the accuracy of prediction of PD.
Use of explicit allocation of distinctive features to predict diabetic retinopathy
At the moment, extensive work has been done on the development of algorithms and image processing techniques for explicitly identifying the distinctive features characteristic of patients with DR. The standard image classification uses the following universal workflow:
- Image preprocessing techniques for removing noise and enhancing contrast.
- The method of selection of distinctive features.
- Classification.
- Prediction.
Oliver Faust and his other colleagues provide a very detailed analysis of models using explicit identification of the distinctive features of the DR. Vuyosevich and his colleagues created a binary classifier on the basis of a set of data from 55 patients, clearly identifying individual distinguishing signs of lesions. Some authors used the methods of morphological image processing to extract the distinctive signs of blood vessels and bleeding, and then trained the reference vector machine on a data set of 331 images. Other experts report 90% accuracy and 90% sensitivity in the binary classification problem on a data set of 140 images.
Nevertheless, all these processes are associated with significant time and effort. To further improve the accuracy of predictions, huge amounts of tagged data are required. Image processing and the identification of distinctive features in image data sets is a very complex and lengthy process. Therefore, we decided to automate image processing and the stage of identifying distinctive features using GNSS.
Deep convolutional neural network (GNSS)
To highlight the distinctive features in the images requires expert knowledge. The selection functions in the GPSS automatically generate images for specific areas without using any distinctive feature processing. Thanks to this process, the GPSS is suitable for image analysis:
- GNSS trains networks with multiple layers.
- Several layers work together to form an improved feature space.
- The initial layers study the primary signs (color, edges, etc.).
- Further layers are exploring features of a higher order (according to the input dataset).
- Finally, signs of the final layer are served in the layers of the classification.
Layers C - convolutions, layers S - pools and selections
Convolution . Convolutional layers consist of a rectangular network of neurons. The weights are the same for each neuron in the convolutional layer. The weights of the convolutional layer determine the convolution filter.
Poll The pooling layer takes small rectangular blocks from the convolutional layer and conducts a subsample to make one exit from this block.
In this publication, we are using Google’s GoogLeNet. The neural network GoogLeNet won the ImageNet competition in 2014, setting a record for the best one-time results. The reasons for choosing this model are the depth of work and the economical use of architecture resources.
Transfer learning and fine tuning of deep convolutional neural networks
In practice, learning of whole GNSS is usually not performed from scratch with arbitrary initialization. The reason is that it is usually not possible to find a dataset of sufficient size required for the network of the desired depth. Instead, pre-learning of the GNSS on a very large data set most often occurs, and then using the weights of the trained GNSS either as initialization or as a distinction for the specific task.
Fine tuning . Learning transfer strategies depend on various factors, but two are the most important: the size of the new data set and its similarity to the original data set. If we consider that the nature of the work of the GNSS is more universal in the early layers and becomes more closely related to a specific data set on the subsequent layers, we can distinguish four main scenarios:
- The new dataset is smaller and similar in content to the original dataset. If the amount of data is small, then it makes no sense to fine-tune the GNSS due to over-fitting. Since the data is similar to the original data, it can be assumed that the distinctive features in the GNSS will also be relevant for this data set. Therefore, the optimal solution is to train a linear classifier as a distinctive feature of the SNA.
- The new data set is relatively large and similar in content to the original data set. Since we have more data, you can not worry about over-fitting if we try to fine-tune the entire network.
- The new data set is smaller in size and differs significantly in content from the original data set. Since the amount of data is small, only a linear classifier will be sufficient. Since the data is significantly different, it is better to train the classifier not from the top of the network, which contains more specific data. Instead, it is better to train the classifier by activating it in the earlier layers of the network.
- The new data set is relatively large and differs significantly in content from the original data set. Since the data set is very large, you can afford to train the entire GNSS from scratch. However, in practice, it is often still more profitable to use to initialize weights from a pre-trained model. In this case, we will have enough data to fine-tune the entire network.
Fine-tuning the GNSS . Solving the question of predicting the DR, we act on scenario IV. We carry out the fine-tuning of the weights in advance by the trained GNSS, continuing the reverse propagation. You can either fine-tune all layers of the GPSN system, or leave some of the earlier layers unchanged (to avoid over-fitting) and configure only the high-level part of the network. This is because the early layers of the GNSS contain more versatile functions (for example, the definition of edges or colors) that are useful for a variety of tasks, and the later layers of the GNSS are already oriented towards the classes of the DR data set.
Limitations of transfer learning . Because we use a pre-trained network, our choice of model architecture is somewhat limited. For example, we cannot arbitrarily remove convolutional layers from a previously trained model. However, by sharing the parameters, you can easily launch a pre-trained network for images of different spatial sizes. This is most obvious in the case of convolutional and selective layers, since their redirection function does not depend on the spatial size of the input data. In the case of fully connected layers, this principle is preserved, since fully connected layers can be transformed into a convolutional layer.
Learning speed We use a reduced learning rate for GNSS weights that are finely tuned, assuming that the quality of the weights of a pre-trained GNSS is relatively high. These data should not be distorted too quickly or too much; therefore, both the learning rate and the drop rate should be relatively low.
Supplement data . One of the drawbacks of irregular neural networks is their excessive flexibility: they are equally well trained in recognizing both garment details and interferences, which increase the likelihood of over-fitting. We apply Tikhonov's regularization (or L2 regularization) to avoid this. However, even after that, there was a significant performance gap between learning and verifying DR images, indicating an over-fit during the fine-tuning process. To eliminate this effect, we apply data addition to a set of image data DR.
There are many ways to complement data, for example, mirroring horizontally, random cropping, changing colors. Since the color information of these images is very important, we apply only the rotation of the images to different angles: 0, 90, 180 and 270 degrees.
Replacing the input layer of the pre-trained GoogLeNet network with DR images. We perform fine tuning of all layers, except for the two upper pre-trained layers containing universal weights.
Tweaking GoogLeNet. The GoogLeNet network we used was initially trained on the ImageNet dataset. The ImageNet dataset contains about 1 million natural images and 1000 tags / categories. Our tagged DR data set contains about 30,000 images pertaining to the area in question, and four tags / categories. Consequently, this DR data set is not enough to train a complex network like GoogLeNet: we will use weights from GoogLeNet, trained on ImageNet. We perform fine tuning of all layers, except for the two upper pre-trained layers containing universal weights. The initial loss3 / classifier classification layer provides predictions for 1000 classes. We are replacing it with a new binary layer.
Conclusion
Thanks to the fine-tuning, it is possible to apply advanced GPSN models in new areas where it would be impossible to use them otherwise due to lack of data or time and cost constraints. This approach allows to achieve a significant increase in the average accuracy and efficiency of the classification of medical images.
If you see an inaccuracy of the translation, please let us know in your private messages.
Source: https://habr.com/ru/post/314934/
All Articles