How ABBYY technologies help improve data leak detection systems
 Despite predictions about the imminent onset of a bright paperless future, the volume of paper documents is still huge. Some of them are scanned and continue their “life” already in electronic form - but only in the form of images. On average, organizations have scanned copies of 30% of all documents that are stored electronically. In the public sector, it reaches 41.5%, in retail - 17%, in the service sector - 23%, in banks and the telecom sector is approaching 45%. When scans of documents are in the right folder for themselves or do the work for which they are intended, this is good. It is bad when someone tries to use data from these scans in fraudulent schemes or otherwise abuse them. To keep confidential information from leaking, DLP leak prevention systems are installed in company information systems.
Despite predictions about the imminent onset of a bright paperless future, the volume of paper documents is still huge. Some of them are scanned and continue their “life” already in electronic form - but only in the form of images. On average, organizations have scanned copies of 30% of all documents that are stored electronically. In the public sector, it reaches 41.5%, in retail - 17%, in the service sector - 23%, in banks and the telecom sector is approaching 45%. When scans of documents are in the right folder for themselves or do the work for which they are intended, this is good. It is bad when someone tries to use data from these scans in fraudulent schemes or otherwise abuse them. To keep confidential information from leaking, DLP leak prevention systems are installed in company information systems.Today we will explain how the ABKY FineReader Engine SDK product was integrated into one of such programs, the Information Security Circuit of SearchInform, and what came of it.
We believe that not all readers of the ABBYY blog are well versed in information security, so we first briefly describe how the Information Security Contour works in general. If you are a frequenter of the “IB” hub and are familiar with the principles of operation of DLP systems, you can skip this section.
How DLP works
The information security contour SearchInform is designed to control information flows within the local area network. Control is possible in two ways, depending on the server component used: on the network or on users' workstations. Server components are the platforms on which data interception modules are running. Each interception module acts as a traffic analyzer and monitors its data transmission channel.
')
The first module intercepts and, if necessary, blocks information flows at the network level. It allows you to work with mirrored traffic, proxy servers, mail servers and other corporate software, for example, Lyn. Network traffic is intercepted at the network protocol level (mail, Internet, instant messengers, FTP, cloud storage). The second one intercepts and blocks information with the help of agents that are installed on employees' computers. It controls: Internet, corporate and personal e-mail, all popular instant messengers (Viber, ICQ, etc.), Skype, cloud storages, FTP, Sharepoint, output of documents to printers, the use of external storage devices. The file system, the activity of processes and sites are monitored, the information displayed on the PC monitors and captured by the microphones, keystrokes, remote online monitoring of the PC is available.
The system also allows you to index documents "alone" - on users' workstations or network devices - and can index any textual information from any sources that have an API or the ability to connect via ODBC.
The system searches for confidential information that should not “leak out” in different ways: by keywords, taking into account morphology and synonyms, by phrases, by taking into account the word order and distance between them, by attributes or by featured documents (format, sender or recipient name, etc. ). The analysis algorithms are so sensitive that they are able to find even a seriously modified document, if it is close in meaning or content to the “standard”
The system can set security policies and monitor their execution. DLP is able to collect statistics and creates reports on cases of violation of security policies.
The system architecture - for those interested - is well described in this review , we will not repeat.
The information security contour SearchInform is designed to control information flows within the local area network. Control is possible in two ways, depending on the server component used: on the network or on users' workstations. Server components are the platforms on which data interception modules are running. Each interception module acts as a traffic analyzer and monitors its data transmission channel.
')
The first module intercepts and, if necessary, blocks information flows at the network level. It allows you to work with mirrored traffic, proxy servers, mail servers and other corporate software, for example, Lyn. Network traffic is intercepted at the network protocol level (mail, Internet, instant messengers, FTP, cloud storage). The second one intercepts and blocks information with the help of agents that are installed on employees' computers. It controls: Internet, corporate and personal e-mail, all popular instant messengers (Viber, ICQ, etc.), Skype, cloud storages, FTP, Sharepoint, output of documents to printers, the use of external storage devices. The file system, the activity of processes and sites are monitored, the information displayed on the PC monitors and captured by the microphones, keystrokes, remote online monitoring of the PC is available.
The system also allows you to index documents "alone" - on users' workstations or network devices - and can index any textual information from any sources that have an API or the ability to connect via ODBC.
The system searches for confidential information that should not “leak out” in different ways: by keywords, taking into account morphology and synonyms, by phrases, by taking into account the word order and distance between them, by attributes or by featured documents (format, sender or recipient name, etc. ). The analysis algorithms are so sensitive that they are able to find even a seriously modified document, if it is close in meaning or content to the “standard”
The system can set security policies and monitor their execution. DLP is able to collect statistics and creates reports on cases of violation of security policies.
The system architecture - for those interested - is well described in this review , we will not repeat.
Most of the tasks in DLP are solved by text analysis. But, as we remember, in many companies a large number of scans (images) of documents are stored and transmitted through different channels. If you leave the picture "as is" - the picture, the DLP-system will not be able to work with it.
In order for the system to understand what information is contained in the image and whether it can be stored / transmitted in one way or another, the image needs to be recognized and received text. In this case, the entrance serves a variety of images, and their quality can be completely different. If a fuzzy picture falls into the interception, you have to work with what you have, not to ask the user to send it again, in a higher quality.
SearchInform DLP system was previously equipped with OCR technology. But this engine had serious drawbacks both in recognition quality and speed. I had no sense in developing my own engine for SearchInform, so we started looking for ready-made technologies. Now in the SearchServer module, ABBYY technologies can be used as a full-text recognition engine.
How did the FineReader Engine integrate into the system?
The development is divided into two directions. First, it was necessary to integrate ABBYY technologies seamlessly and create a user-friendly DLP recognition module. Secondly, to adapt the recognition and classification of ABBYY documents for applied tasks.
The first problem was solved quickly: it was implemented through its own pre-configured installer in the DLP system. Deploying an OCR module based on ABBYY technology comes down to installing an additional component in the “next - next” style, and activating the necessary “tick” in the DLP. The component is installed on the DLP server, so no configuration for the “connection” of DLP and OCR is required in principle; the user doesn’t need to do anything else.
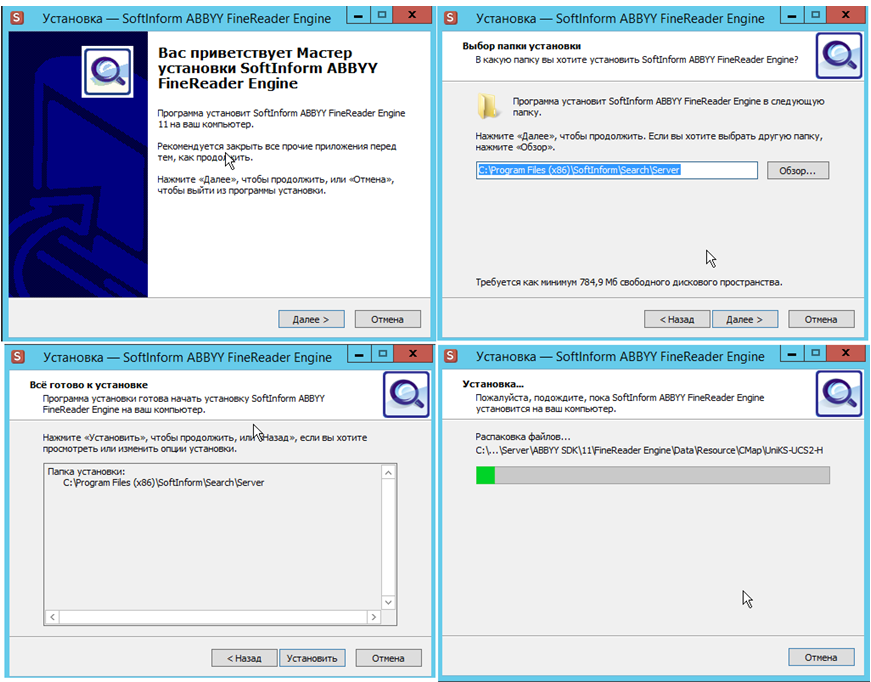
The inclusion of the FineReader Engine is implemented via the DLP interface; it is activated in one click by selecting the corresponding item from the drop-down list. More detailed settings are also available here (if desired).

Moreover, the user does not need to interact with ABBYY, the licensing of the FineReader Engine is performed by SearchInform at the license level to DLP. The implementation turned out to be really user friendly and the customers liked SearchInform.
With the second task - adaptation of the ABBYY technology for applied tasks - there was much more work.
When the programmers of SearchInform began to study technologies, they revealed a lot of opportunities potentially useful for solving information security tasks. Everyone is used to the fact that ABBYY is, above all, OCR. But FineReader Engine can also classify documents by appearance and content. To set up the classification process, at the first stage it is necessary to set the categories for which the documents will be distributed (for example, “Passport”, “Agreement”, “Check”). After this, the program must be trained: “show” documents corresponding to each class in all possible design options.
How does the classifier in FineReader Engine
In order for such a machine to work, the classifier must first be trained. You pick up a small database of documents representing each category that you go to define. With the help of this base you are training a classifier. Then you take another base, check the classifier’s work on it, and if you are satisfied with the results, you can start the classifier “into battle”.
During work and training, the classifier uses a set of features that help separate documents of one type from documents of another type. All signs can be divided into graphic and textual.
Graphic signs well divide groups of documents that are very different from each other. Relatively speaking, if you look at a document from a distance so that you cannot read the text on it, but you can understand what type it is, then the graphic signs here will work well.
So, graphic signs can well separate the fused and non-text text, for example, letters and payment receipts. They look at the size of the image, the density of colors in different parts of it, various other characteristic elements such as vertical and horizontal lines.
And if the documents are similar in appearance, or one group, without reading the text, cannot be separated from the other group, then textual signs help. They are very similar to those used in spam filters and allow for the characteristic words to determine whether a document belongs to a particular type. It is convenient to separate letters from contracts, checks from business cards with the help of text signs.
Also, text signs help to separate documents of a similar type, but differing in the value of one or several fields. For example, checks from McDonalds and Teremka look very similar, but if we consider them as text, the differences will be very noticeable.
As a result, the classifier for each training sample gives more weight to those text or graphic features that allow the best way to separate the documents from this sample by type.
During work and training, the classifier uses a set of features that help separate documents of one type from documents of another type. All signs can be divided into graphic and textual.
Graphic signs well divide groups of documents that are very different from each other. Relatively speaking, if you look at a document from a distance so that you cannot read the text on it, but you can understand what type it is, then the graphic signs here will work well.
So, graphic signs can well separate the fused and non-text text, for example, letters and payment receipts. They look at the size of the image, the density of colors in different parts of it, various other characteristic elements such as vertical and horizontal lines.
And if the documents are similar in appearance, or one group, without reading the text, cannot be separated from the other group, then textual signs help. They are very similar to those used in spam filters and allow for the characteristic words to determine whether a document belongs to a particular type. It is convenient to separate letters from contracts, checks from business cards with the help of text signs.
Also, text signs help to separate documents of a similar type, but differing in the value of one or several fields. For example, checks from McDonalds and Teremka look very similar, but if we consider them as text, the differences will be very noticeable.
As a result, the classifier for each training sample gives more weight to those text or graphic features that allow the best way to separate the documents from this sample by type.
How is the classification implemented in the DLP + ABBYY bundle?
The developers of SearchInform asked the program several categories of documents that users might need in the first place - different types of passports and bank cards.
The categorization of passports and credit cards begins to work for the user without learning the system, almost immediately after deploying the FineReader Engine. The user simply needs to include a classifier in the settings - and all new documents will be categorized; to classify documents from the archive, you just need to restart the check on them.
At the same time, the user is allowed to create additional categories. He can set any classes (categories), or add his documents to the existing ones (passports and credit cards). To do this, he needs to create subfolders with the names of classes in a special folder, put document standards there and start the learning process. This procedure is usually performed in conjunction with SearchInform engineers, who all clearly demonstrate and talk about the requirements for images, together with the customer form the base of standards, advise which documents are better suited as standards of a particular category. Immediately after tuning, a check is made on real data, often after checking, a reconfiguration is needed, a slight adjustment of settings or standards. Usually this procedure takes half an hour.
The accuracy of the classification depends on how much the system can “see” the difference between documents in different categories. If you apply for documents in two different categories that are similar in appearance and contain many identical keywords, the technology will become confused and the classification accuracy will decrease.
So, when detecting scans of only the main page of passports, SearchInform engineers encountered a large number of false positives. The ABBYY algorithm found in the archive of 10,000 images 300 pictures similar to passports, while there were only a few passports.
If for arbitrary categories this is a valid percentage of relevance, then for key objects, for example, credit cards, this is too large an error. To improve the level of relevance, SearchInform engineers have also developed their own verification algorithms, which are already applied to the results of the ABBYY classification. For each category of data, an individual validator was created that works only with its group.
How the DLP + ABBYY system works with images
Data processing in DLP deals with a special component - SearchServer. When this component finds an image in the intercepted data (and it doesn’t matter whether it is part of a document or a separate picture), it transfers it to the FineReader Engine module, which performs optical recognition and classifies images into specified categories. Moreover, together with the category FineReader Engine gives and "percentage of similarity" of the image to the corresponding class, for example, image number 1 looks like a passport by 83%, image number 2 looks like a driver's license by 35%. The result is transmitted to SearchServer. In SearchServer, a special parameter is set, for ease of understanding, let's call it “the lowest possible percentage” - by default it is 40%. If the FineReader Engine has assigned a percentage less than this value, the class is deleted, and this document goes without a class to DLP. If the percentage is higher, there will be the following:
1. For passports and credit cards, the SearchInform validator works, it checks the document using both recognized text and a graphic component (for example, for passports it turns out whether there is a face on the image, where it is located, how much space it takes, whether there are graphic elements inherent only in passports (for the Russian Federation - a special pattern), other characteristic elements). The more “markers” are confirmed, the higher the resulting “multiplier” will be. For example, the FineReader Engine classifier is confident in image similarity to a passport by 63%, the validator found the keywords “Passport of the Russian Federation”, “Last Name”, “Issued by” and a photo on which a person was detected on it - in this case the factor is , for example, 1.5 - and the final relevance is 94.5%
The relevance of such a post-check has increased significantly, and the performance has remained the same. The ABBYY algorithm works fairly quickly and is applied to large data arrays, which allows the program to speed up several times, the SearchInform category validator works slower, but thanks to the ABBYY classification, it is used only when necessary and applied to a significantly smaller data array.
The complexity of this implementation was that we had to do validators for many types of data from scratch. After all, the same passports of different countries have their own unique features, and the algorithm for searching for a passport of the Russian Federation is absolutely not suitable for searching for a passport of a citizen of Ukraine. The same with credit cards - the characteristics for VISA differ significantly from MasterCard.
2.If the document is similar to some category, but it does not belong to passports or credit cards, the relevance assigned by the FineReader Engine module remains unchanged - the SearchInform validator for such categories does not apply at all.
After the final relevance is calculated, the rule once again works, in which the threshold is no longer the “minimum percentage of similarity” value, but the value configured by the user. The default is 70%. Total, if relevance is greater than or equal to this value - such documents confirm the class, and you can search for this class. If it is smaller, the class label is removed and the document is considered “without class”.
Solving applied problems
The Information Security Contour has specialized analytics tools that allow you to work with an archive of data or execute specified security policies.
Of course, passports and credit cards are critical data because they contain personal data, so their control is very important to customers. Moreover, it is usually extremely difficult to develop a blocking rule that will “cut” such data - when creating such rules in real projects, there are a lot of subtleties that become clear gradually, and each such case leads to a violation of the client’s business processes (because lock is activated). Therefore, most often customers just want to see all the movements of such documents within the organization and, especially, beyond its limits. And considering that it can be not only passports / credit cards, but also any other types of data - the method gives greater flexibility in the analysis.
Consider a real case. The customer’s company works with passport scans. It has a specific set of rules regulating where and how it is necessary to store such things, through which electronic channels and to whom it can be transmitted. Part of the data is blocked during transmission - for example, if it is outgoing mail that is not intended for an employee of the company and has a passport scan, passport data, or something even remotely resembling passport data. Send a scan of the passport out only in coordination with the IB.
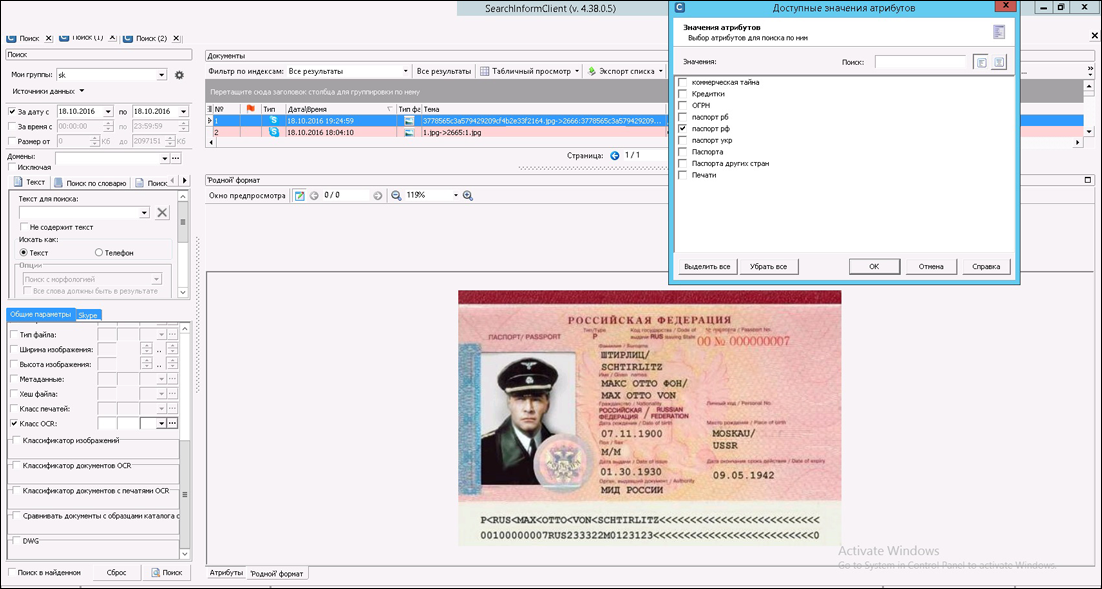
Also, information security specialists monitor the transfer of such data through “personal” channels and the storage of this data on media (storage is regulated, but if the transfer to third parties is considered a critical violation, then copying to the “wrong daddy” is a minor violation).
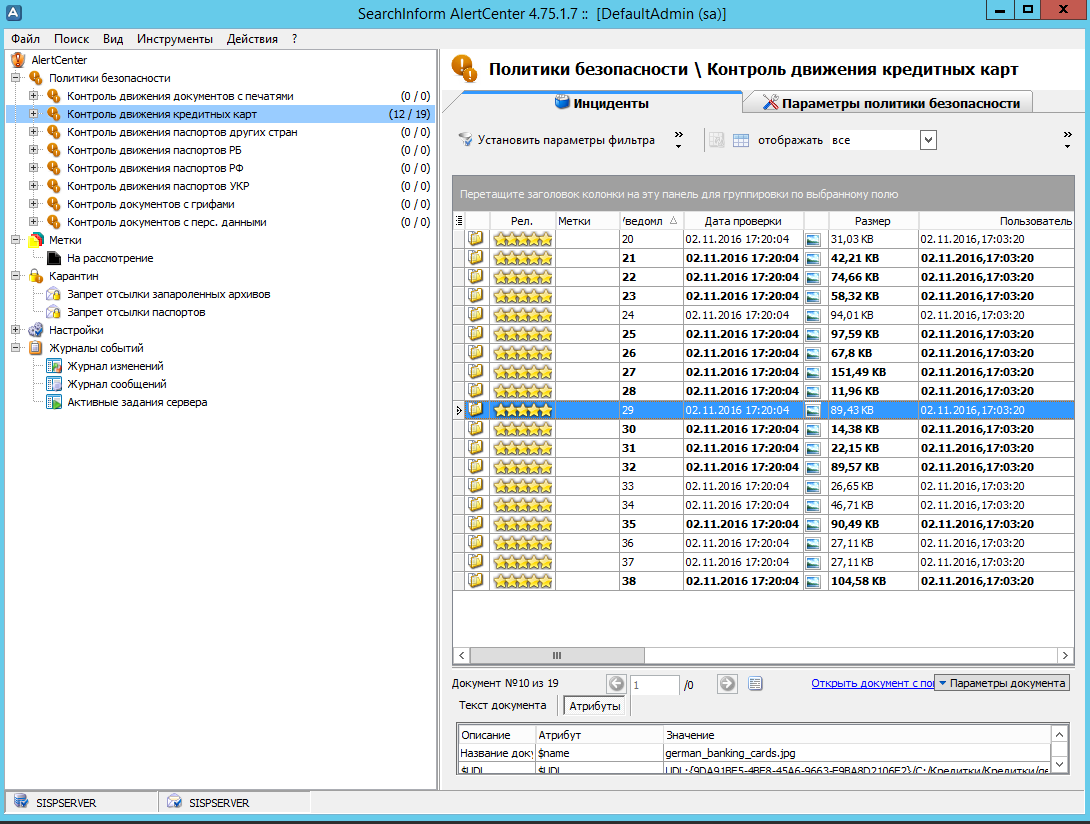
When working in normal mode, the IB relies on DLP automation and works exclusively with system reports. When some kind of investigation is underway, intent checks begin and the data flow begins to work manually. If it is necessary to identify all actions that take place with the object “passport”, the relevance of the policy is 70-80%, out of a million events 500 are filtered out, they are manually reviewed and appropriate measures are taken. If something serious happens, the policy is narrowed down to “employee \ date \ time” and relevancy greatly reduces (up to 1%) - irrelevant data will be an order of magnitude larger, but the probability of missing critical events is greatly reduced.
Svetlana Luzgina, ABBYY Corporate Communications Service,
Alexey Parfentiev, Technical Analyst, SearchInform
Source: https://habr.com/ru/post/314830/
All Articles