Atomic-tests and performance upgrading
 Any software product more difficult “Hello, world!” Needs to be tested - it is an axiom of development. And the wider its functionality and more complex architecture, the more attention should be paid to testing. Especially carefully it is necessary to treat the granular measurement of performance. It often happens that in one part they accelerated, and in the other they slowed down, as a result the result was zero. To prevent this from happening, we are very actively using so-called atomic tests in our work. What is it and what they eat, read under the cut.
Any software product more difficult “Hello, world!” Needs to be tested - it is an axiom of development. And the wider its functionality and more complex architecture, the more attention should be paid to testing. Especially carefully it is necessary to treat the granular measurement of performance. It often happens that in one part they accelerated, and in the other they slowed down, as a result the result was zero. To prevent this from happening, we are very actively using so-called atomic tests in our work. What is it and what they eat, read under the cut. Prehistory
 As Parallels Desktop evolved, it became increasingly difficult for us to test individual functionalities, as well as to find, after the next updates and optimizations, the reasons for the virtual machine's performance degradation. Due to the complexity of the system, it was almost impossible to fully cover it with unit tests. And standard performance measurement packages work on algorithms unknown to us. In addition, they are sharpened by measurements not in virtual, but in real environments, that is, standard benchmarks are less “sensitive” to the changes being made.
As Parallels Desktop evolved, it became increasingly difficult for us to test individual functionalities, as well as to find, after the next updates and optimizations, the reasons for the virtual machine's performance degradation. Due to the complexity of the system, it was almost impossible to fully cover it with unit tests. And standard performance measurement packages work on algorithms unknown to us. In addition, they are sharpened by measurements not in virtual, but in real environments, that is, standard benchmarks are less “sensitive” to the changes being made.We needed a new tool that does not require gigantic labor, as in the case of unit tests, and has better sensitivity and accuracy compared to benchmarks.
')
Atomic tests
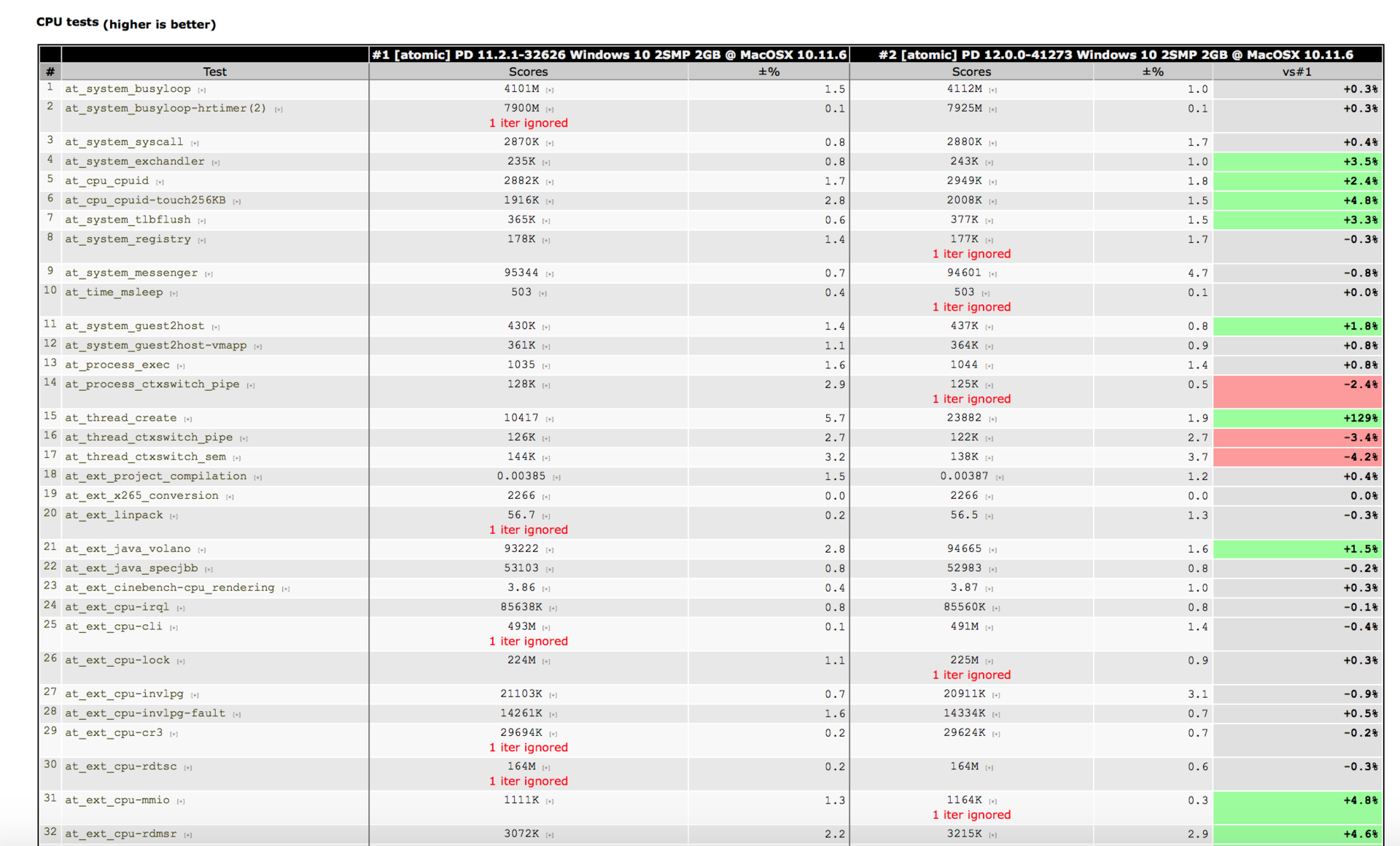
As a result, we have developed a set of highly specialized - atomic, atomic - tests. Each of them is designed to measure the performance of some typical hypervisor mechanics (for example, VM-exit processing) or an operating system (reset TLB caches from TLB-shootdown, context switching and the like). Also, with the help of atomic tests, we evaluate the execution of the simplest operations that are independent of the implementation of the operating system and the virtual machine: mathematical calculations, work with memory and disk in different initial conditions, and so on.

The result of each test is the value of a particular metric. Some metrics are interconnected, others are not. We supplement the results of the atomic tests with the information obtained during the automatic run of standard benchmarks. After analyzing the data obtained during testing, you can get an idea of what happened to which subsystem and what.

Solvable tasks
Of course, testing the functionality by itself - works or does not work, and if it works, is it correct? - the thing is important and necessary. But this does not limit the range of tasks that we solve using atomic-tests.
First of all , we are looking for reasons for performance degradation. To do this, we regularly run atomic tests, and if any of them showed regression, then the standard bisect procedure is used: a fork from two commits is taken and a binary search is searched for a commit that introduced a regression.

It also happens that during the next test a regression was revealed, a bug was declared on it, but the developers didn’t immediately get around to finding out the reason. And when the hands still reach, conditions can already be lost under which the bug is easily reproduced. Some tasks have a very large backlog, and testing all changes in the reverse order is too long and time consuming. Sometimes it is even not clear when exactly the performance degradation occurred. In such cases, programmers work with what they have: they repeatedly test the corresponding functionality, examine the behavior of the system under different conditions, and analyze the logs of the debugging system to find the cause of the described test regression.
The second problem , solved with the help of atomic tests, is comparison with competitors. We take two systems and test on the same machine under different hypervisors. If our product in some area is inferior in performance, then the developers begin to carefully consider why.
And the third task is to determine the effectiveness of optimizations. Even when everything is fast, developers regularly have some ideas for improving the architecture and performance. And atomic-tests help to quickly find out whether the innovation went to the benefit of the products. Often it turns out that optimization does not improve the performance, and sometimes even worsen.
Features of using atomic tests
Atomic tests can be run anywhere — on a host or guest OS. But, like any performance test, they depend on the configuration of the operating system and hardware. So, if you run tests on a host OS that does not match the guest OS, then the results obtained will be useless.
Like any performance tests, they require certain conditions to produce reproducible results. The host OS is very complex (due to the virtualization system) and is not a real-time operating system. It can cause unpredictable delays associated with the equipment, various services are activated. A hypervisor is also a complex software product consisting of numerous components that run in user space, kernel space, and their own context. Guest OS is subject to the same problems as the host. So the most difficult thing when using atomic tests is to get repeatable test results.
How to do it?
The most important condition for obtaining stable results is the launch of tests by a robot, always under the same initial conditions:
• net system load
• the same virtual machine is restored each time from a backup to a physical disk, to the same place
• tests run directly using the same algorithms
If the measurement conditions have changed, then they are looking for some rational explanation, and always compare the results before and after the changes.
Life examples
When you need to perform some processing using components that are in user space, the hypervisor needs to switch from its own context to the context of the kernel, then to the context of the user space and back. And in order to send an interrupt guest OS requires:
1) First, bring the virtual processor stream out of rest by using a signal from the host OS
2) move from its context to its own hypervisor context
3) pass the interrupt to the guest OS
The problem is that switching processes from the hypervisor context to the kernel context and back are very slow. And when the virtual processor is at rest (idle), when returning control to it, very high costs are obtained.
Once in Parallels Desktop, we encountered a defect in MacOS X Yosemite 10.10. The system generated hardware interrupts with such intensity that we only did what they were processed, and, as a result, the guest OS hung. The situation was aggravated by the fact that hardware interrupts arriving in the context of the guest OS needed to be immediately transferred to the host OS. And for this you have to switch the context twice. And with a large number of such interrupts, the guest OS slowed down or hung up. This is where our atomic tests came in handy.
Despite the fact that the problem was fixed in 10.10.2, in order to prevent this from happening again, and to speed up the guest OS as a whole, we gradually optimized the context switch procedure by regularly measuring its current speed using a special atomic-test. For example, instead of being executed entirely in our own context, we moved the execution to a context more close to the context of the kernel space. As a result, the number of operations during switchings has decreased and the speed of processing requests to user-space components has increased and control transfer to the guest operating system from idle state has increased. In the end, everyone is happy!

We will be happy to answer questions in the comments to the article. Also ask if something seemed incomprehensible.
Source: https://habr.com/ru/post/314740/
All Articles