ZFS on Linux: News from the Field 2017
ZFS is one of the most stuffed file systems (FS), and most importantly - it cares about the safety of our information. Yes, it is not a “silver bullet”, but it shows excellent results in its field.

The ZFS on Linux project was originally created to port existing code from Solaris. After closing its source code in conjunction with the OpenZFS community, the project continued to develop ZFS for Linux. The code can be compiled both as part of the kernel and as a module.

Now the user can create a pool with the latest compatible with Solaris version 28, as well as with the priority for OpenZFS version 5000, after which the application started feature feature flags (functional flags). They allow you to create pools that will be supported on FreeBSD, post-Sun Solaris OS, Linux, and OSX, regardless of implementation differences.
In 2016, the last frontier, which restrained ZFS on Linux, was overcome - many distributions included it in the regular repositories, and the Proxmox project already includes it in the basic distribution. Cheers, comrades!
Consider both the most important differences and pitfalls that are currently in the version of ZFS on Linux 0.6.5.10.
Getting started with ZFS is worth exploring the features of CopyOnWrite (CoW) file systems — when a data block changes, the old block does not change, but a new one is created. Translating into Russian - copying takes place while recording. This approach leaves an imprint on performance, but it gives the opportunity to store the entire history of data changes.
')
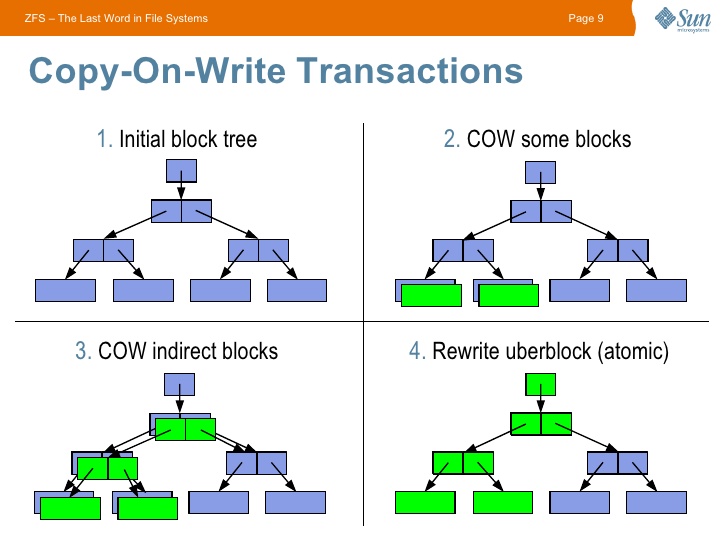
The ZFS CoW approach provides tremendous opportunities: this FS cannot have an incorrect state, since in case of problems with the last transaction (for example, when the power is turned off), the last one will be used correctly.
Also immediately worth noting that for all data is considered a checksum , which also leaves its mark on performance, but gives a guarantee of data integrity.
Data Protection:
Maximum flexibility of your storage:
In ZFS, the storage structure is as follows:
There can be an unlimited number of vdev in the pool, which allows you to create a pool of two or more mirrors, RAID-Z, or other combinations. Classic RAID10, etc. are also available.
Stripe is a regular RAID0.
Mirror - RAID1 in the manner of ZFS - only busy blocks are replicated, forget about the synchronization of empty space.
RAID-Z was created as a replacement for RAID5-6, but it has big differences:
- each data block is an analogue of a separate array (with a dynamic length);
- there is no write hole problem;
- when rebuild, only data is created (i.e., the risk of failure at this point is reduced). Also in the test branch are already improvements that will further speed up the process.
It is recommended to use RAID-Z2 (analog RAID6). When creating a RAID-Z, you should definitely study this article , the main nuances:
- IOPS is equal to the slowest disk (create a RAID-Z with the least number of disks);
- the efficiency of space utilization increases with a large number of disks in the array (the correct recordsize is required to be set, see the link above );
- it is impossible to add another disk to the existing RAID-Z array (yet), but you can replace the disks with more capacious ones. This problem is solved by creating several arrays within one vdev.
dRAID (in development) - is based on RAID-Z practices, but if it fails, it allows you to use all the disks in the read-write array.
CoW degrades performance. An adaptive replacement cache ( ARC ) was created to smooth the situation. Its main feature in advanced heuristics is to eliminate cache washout, while the usual Linux page cache is very sensitive to this.
As a bonus to ARC, it is possible to create a fast carrier with the next cache level - L2ARC. If necessary, it connects to fast SSDs and allows you to significantly improve IOPS HDD drives. L2ARC is similar to bcache with its own features.
L2ARC should be used only after increasing the RAM to the maximum possible amount .
It is also possible to make a journal entry - ZIL , which will significantly speed up write operations.
Compression - with the advent of LZ4 allows you to increase the speed of IO due to a small load on the processor. The load is so small that the inclusion of this option is already a widespread recommendation . It is also possible to use other algorithms (gzip works great for backups).
Deduplication - features: the deduplication process is performed synchronously when recording, does not require additional load, the main requirement is ~ 320 bytes of RAM for each data block (Use the command
It is recommended to use only on frequently repeated data . In most cases, the overhead is not justified, it is better to enable LZ4 compression.
Snapshots - because of the ZFS architecture, they have absolutely no effect on performance; we will not dwell on them in this article. I note only the excellent utility zfs-auto-snapshot , which creates them automatically at specified intervals. Performance is not reflected.
Encryption (in development) - will be built-in, designed to take into account all the flaws of the implementation from Oracle, and also allow staff send / receive and scrub to send and check data for integrity without a key .
- Consider the geometry of the array in advance, at the moment ZFS is not able to decrease, as well as expand existing arrays (you can add new ones or change disks to more voluminous ones);
- use compression:
- store extended attributes correctly, by default they are stored as hidden files (only for Linux):
- disable atime:
- set the required block size (recordsize), files smaller than recordsize will be recorded into a smaller block, files larger than recordsize will record the end of the file into a block with a size of recordsize (if
- limit the maximum size of ARC (to avoid problems with the amount of RAM):
- use deduplication only for obvious need;
- if possible, use ECC memory;
- configure zfs-auto-snapshot .
- most SSDs lie to the system about the block size, for reinsurance, control it (the ashift parameter). Link to exclusion list for SSD in ZFS code.
- many properties act only on new data, for example, when compression is enabled, it will not apply to already existing data. In the future, it is possible to create a program that automatically applies properties. Costly simple copying.
- ZFS console commands do not ask for confirmation, be careful when executing
- ZFS does not like filling the pool at 100%, like all other CoW FS, after 80% it is possible to slow down work without proper configuration.
- it is required to set the block size correctly, otherwise application performance may be suboptimal (examples - Mysql , PostrgeSQL , torrents ).
- make backups on any FS!
At the moment, ZFS on Linux is already a stable product, but tight integration into existing distributions will take some time.
ZFS is a great system that is very difficult to give up after dating. It is not a universal tool, but in the niche of software RAID arrays has already taken its place.
I, gmelikov , am in the ZFS on Linux project and are ready to answer any questions with pleasure!
Separately, I would like to invite you to participate, issues and PR are always happy, and also ready to help you with our mailing lists .
Useful links:
ZFS on Linux github page
FAQ
ZFS Performance tuning
Update (12.02.2018) : Added information about ashift SSD drives.
The ZFS on Linux project was originally created to port existing code from Solaris. After closing its source code in conjunction with the OpenZFS community, the project continued to develop ZFS for Linux. The code can be compiled both as part of the kernel and as a module.
Now the user can create a pool with the latest compatible with Solaris version 28, as well as with the priority for OpenZFS version 5000, after which the application started feature feature flags (functional flags). They allow you to create pools that will be supported on FreeBSD, post-Sun Solaris OS, Linux, and OSX, regardless of implementation differences.
In 2016, the last frontier, which restrained ZFS on Linux, was overcome - many distributions included it in the regular repositories, and the Proxmox project already includes it in the basic distribution. Cheers, comrades!
Consider both the most important differences and pitfalls that are currently in the version of ZFS on Linux 0.6.5.10.
Getting started with ZFS is worth exploring the features of CopyOnWrite (CoW) file systems — when a data block changes, the old block does not change, but a new one is created. Translating into Russian - copying takes place while recording. This approach leaves an imprint on performance, but it gives the opportunity to store the entire history of data changes.
')
The ZFS CoW approach provides tremendous opportunities: this FS cannot have an incorrect state, since in case of problems with the last transaction (for example, when the power is turned off), the last one will be used correctly.
Also immediately worth noting that for all data is considered a checksum , which also leaves its mark on performance, but gives a guarantee of data integrity.
Briefly about the main advantages of ZFS for your system.
Data Protection:
- checksums - guarantee the correctness of data;
- the ability to back up both at the level of creating mirrors and analog RAID arrays, and at the level of an individual disk (
copiesparameter); - Unlike many file systems with their fsck at the log level, ZFS checks all checksum data and can automatically restore them with the scrub command (if there is a live copy of the broken data in the pool);
- the first FS, the developers of which honestly admitted all possible risks during storage - everywhere at the mention of ZFS you can meet the requirement of RAM with ECC support (any FS has a risk of damage when there is no ECC memory, just everyone except ZFS prefer not to think about it);
- ZFS was created taking into account the unreliability of disks, just remember this and stop worrying about your
WD GreenSeagateetc(only if there is another surviving disk working side by side).
Maximum flexibility of your storage:
- is the place over? Replace the disk with a more voluminous one, and your humble ZFS will occupy the new room itself (by the parameter autoexpand);
- The best implementation of snapshots among file systems for Linux. You sit down on it . Incrementally over the network, into the archive,
/ dev / null, but at least split the identity of your dear Linux in real time (clone); - Need more
goldplace? 256 Zebibyt enough for everyone!
Structure.
In ZFS, the storage structure is as follows:
- pool -- vdev (virtual device) - ( mirror, stripe .) --- block device - , , There can be an unlimited number of vdev in the pool, which allows you to create a pool of two or more mirrors, RAID-Z, or other combinations. Classic RAID10, etc. are also available.
Array types:
Stripe is a regular RAID0.
Mirror - RAID1 in the manner of ZFS - only busy blocks are replicated, forget about the synchronization of empty space.
RAID-Z was created as a replacement for RAID5-6, but it has big differences:
- each data block is an analogue of a separate array (with a dynamic length);
- there is no write hole problem;
- when rebuild, only data is created (i.e., the risk of failure at this point is reduced). Also in the test branch are already improvements that will further speed up the process.
It is recommended to use RAID-Z2 (analog RAID6). When creating a RAID-Z, you should definitely study this article , the main nuances:
- IOPS is equal to the slowest disk (create a RAID-Z with the least number of disks);
- the efficiency of space utilization increases with a large number of disks in the array (the correct recordsize is required to be set, see the link above );
- it is impossible to add another disk to the existing RAID-Z array (yet), but you can replace the disks with more capacious ones. This problem is solved by creating several arrays within one vdev.
dRAID (in development) - is based on RAID-Z practices, but if it fails, it allows you to use all the disks in the read-write array.
ARC - smart caching in ZFS.
CoW degrades performance. An adaptive replacement cache ( ARC ) was created to smooth the situation. Its main feature in advanced heuristics is to eliminate cache washout, while the usual Linux page cache is very sensitive to this.
As a bonus to ARC, it is possible to create a fast carrier with the next cache level - L2ARC. If necessary, it connects to fast SSDs and allows you to significantly improve IOPS HDD drives. L2ARC is similar to bcache with its own features.
L2ARC should be used only after increasing the RAM to the maximum possible amount .
It is also possible to make a journal entry - ZIL , which will significantly speed up write operations.
Additional features.
Compression - with the advent of LZ4 allows you to increase the speed of IO due to a small load on the processor. The load is so small that the inclusion of this option is already a widespread recommendation . It is also possible to use other algorithms (gzip works great for backups).
Deduplication - features: the deduplication process is performed synchronously when recording, does not require additional load, the main requirement is ~ 320 bytes of RAM for each data block (Use the command
zdb -S _ to simulate an existing pool) or ~ 5GB for every 1 TB. RAM is stored so-called. Dedup table (DDT), with a shortage of RAM, each write operation will rest on the IO of the carrier (DDT will be read every time from it).It is recommended to use only on frequently repeated data . In most cases, the overhead is not justified, it is better to enable LZ4 compression.
Snapshots - because of the ZFS architecture, they have absolutely no effect on performance; we will not dwell on them in this article. I note only the excellent utility zfs-auto-snapshot , which creates them automatically at specified intervals. Performance is not reflected.
Encryption (in development) - will be built-in, designed to take into account all the flaws of the implementation from Oracle, and also allow staff send / receive and scrub to send and check data for integrity without a key .
Key recommendations (TL; DR):
- Consider the geometry of the array in advance, at the moment ZFS is not able to decrease, as well as expand existing arrays (you can add new ones or change disks to more voluminous ones);
- use compression:
compression=lz4- store extended attributes correctly, by default they are stored as hidden files (only for Linux):
xattr=sa- disable atime:
atime=off- set the required block size (recordsize), files smaller than recordsize will be recorded into a smaller block, files larger than recordsize will record the end of the file into a block with a size of recordsize (if
recordsize=1M , the 1.5mb file will be recorded as 2 blocks of 1mb each, while as a 0.5 mb file will be written into a 0.5 mb block). More is better for compression:recordsize=128K- limit the maximum size of ARC (to avoid problems with the amount of RAM):
echo "options zfs zfs_arc_max=___" >> /etc/modprobe.d/zfs.conf
echo ___ >> /sys/module/zfs/parameters/zfs_arc_max- use deduplication only for obvious need;
- if possible, use ECC memory;
- configure zfs-auto-snapshot .
- most SSDs lie to the system about the block size, for reinsurance, control it (the ashift parameter). Link to exclusion list for SSD in ZFS code.
Important points:
- many properties act only on new data, for example, when compression is enabled, it will not apply to already existing data. In the future, it is possible to create a program that automatically applies properties. Costly simple copying.
- ZFS console commands do not ask for confirmation, be careful when executing
destroy !- ZFS does not like filling the pool at 100%, like all other CoW FS, after 80% it is possible to slow down work without proper configuration.
- it is required to set the block size correctly, otherwise application performance may be suboptimal (examples - Mysql , PostrgeSQL , torrents ).
- make backups on any FS!
At the moment, ZFS on Linux is already a stable product, but tight integration into existing distributions will take some time.
ZFS is a great system that is very difficult to give up after dating. It is not a universal tool, but in the niche of software RAID arrays has already taken its place.
I, gmelikov , am in the ZFS on Linux project and are ready to answer any questions with pleasure!
Separately, I would like to invite you to participate, issues and PR are always happy, and also ready to help you with our mailing lists .
Useful links:
ZFS on Linux github page
FAQ
ZFS Performance tuning
Update (12.02.2018) : Added information about ashift SSD drives.
Source: https://habr.com/ru/post/314506/
All Articles