Java Programmer Cheat Sheets 9: Java SE - Cheat Sheet for Interviews and Repetitions
This article is primarily intended to prepare for interviews for the position of Java developer (in fact, this is a cheat sheet, which I wrote for myself for many years, and repeat with each new job search).
It is assumed. That you are familiar with many of the features of Java SE, so basically the information is briefly given. Of course, you can use this article and just to learn the basics of the Java SE platform (but in this case, after reading the article, you will most likely have to turn to other sources).

')
So, you are trying to remember everything that you know before the interview and no matter how many years of experience, without preparation they can still catch you on the question you seemed to remember, but it was you who forgot it during the interview. This cheat sheet will allow you to refresh some of your knowledge.
Attention : I will not touch on questions on the Java language itself (such as why you need the word final or how overriding differs from overloading), this will require a separate article, these are questions about the Java SE (6-9) platform.
There are always a lot of questions about collections, regardless of your level. Therefore, let us briefly recall all the features about the collections.
More on this in my article , for example, the section on collection operations or the use of collections from guava, apache commons and Eclipse (GS Collections).
Functional programming, lambdas, and features added to Java 8 are also very often seen in interviews. I described in detail in this crib , here I will give only a brief description:
If something above is not clear, I advise you to look at a separate article.
On this topic, too, there are quite often questions at interviews.
Here on this topic questions are very rare (I don’t remember a single issue on this topic), however, just in case, it is worth remembering about them.
But about Reference objects, there are questions and very often developers float on them, since these are rarely used classes. In fact, these are classes for more flexible memory management than the usual “strong” pointers.
Again, a rare topic for interviews, but worth remembering.
There are two main classes for working with regular expressions and one interface:
1. Pattern - Compiled regular expression to be used in the Matcher.
Matcher. Class for executing compiled regular expression (Pattern class) over CharSequence.
2. MatchResult - Used to return Matcher results
I also don’t remember questions on this topic, but it’s still useful to repeat the standard logging in SE.
Thanks for attention. Other cheat sheets can be found in my profile.
It is assumed. That you are familiar with many of the features of Java SE, so basically the information is briefly given. Of course, you can use this article and just to learn the basics of the Java SE platform (but in this case, after reading the article, you will most likely have to turn to other sources).
')
So, you are trying to remember everything that you know before the interview and no matter how many years of experience, without preparation they can still catch you on the question you seemed to remember, but it was you who forgot it during the interview. This cheat sheet will allow you to refresh some of your knowledge.
Attention : I will not touch on questions on the Java language itself (such as why you need the word final or how overriding differs from overloading), this will require a separate article, these are questions about the Java SE (6-9) platform.
I. Collections
There are always a lot of questions about collections, regardless of your level. Therefore, let us briefly recall all the features about the collections.
Lots of information about collections
1) JDK Collection Interfaces
2) A table with a very brief description of all collections
3) Obsolete collections in the JDK
4) Collections that implement the List interface
5) Collections that implement the Set interface (set)
6) Collections that implement the Map interface (associative array)
7) Collections based on Queue / Deque interfaces
8) Other collections
9) Methods of working with collections
10) How are different types of JDK collections inside arranged?
11) Other useful entities of the standard collections library
Beginner's Note on Collections
Sometimes it is quite difficult for beginners (especially if they came from other programming languages) to understand that only references / pointers are stored in the Java collection and nothing more. It seems to them that when calling add or put objects are actually stored somewhere inside the collection, this is true only for arrays, when they work with primitive types, but not for collections that store only links. Therefore, very often the beginners begin to answer something like “It depends on the type of objects that they store in” to interview questions like “Is it possible to call the exact size of the ArrayList collection”? This is absolutely not true, since collections never store objects themselves, but only links to them. For example, you can add the same object to the List a million times (more precisely, create a million references to one object).
1) JDK Collection Interfaces
JDK Collection Interfaces
Collection interfaces
Interfaces from the java.util.concurrent package
If you are interested in more detailed information about interfaces and collections from java.util.concurrent I advise
read here this article .
| Title | Description |
|---|---|
| Iterable | An interface means that the collection has an iterator and can be circumvented with for (Type value: collection). There are almost all collections (except Map) |
| Collection | The main interface for most collections (except Map) |
| List | The list is an ordered collection, also known as a sequence. (sequence). Duplicate elements in most implementations are allowed. Allows access by item index Extends the Collection interface. |
| Set | Interface that implements work with sets (similar to mathematical sets), duplicating Items are prohibited. It may or may not be orderly. Extends the Collection interface. |
| Queue | A queue is a collection designed to store objects before processing, in contrast to the usual operations on collections, a queue provides additional methods for adding, retrieving, and viewing. Fast access on an index of an element, as a rule, does not contain. Extends the Collection interface |
| Deque | Two-way queue, supports adding and removing items from both ends. Expands Queue interface. |
| Map | Works with matching key - value. Each key corresponds to only one value. AT unlike other collections does not extend any interfaces (including Collection and Iterable) |
| SortedSet | Automatically sorted set, or in natural order (for details, see Comparable interface), or using the Comparator. Extends the Set Interface |
| SortedMap | This is a map whose keys are automatically sorted, either in natural order, or using comparator Extends the Map interface. |
| NavigableSet | This is SortedSet, to which additionally added methods for finding the closest value to the specified search value. NavigableSet can be accessed and accessed or in order. descending values or in ascending order. |
| NavigableMap | This is SortedMap, to which additionally added methods for finding the closest value to the specified search value. Available for access and bypass either in descending order of values or in ascending order. |
Interfaces from the java.util.concurrent package
| Title | Description |
|---|---|
| BlockingQueue | A multi-threaded Queue implementation containing the ability to set the queue size, condition locks, various methods that handle overflows differently when adding or missing data when received (throw an exception, block the stream continuously or temporarily, return false, etc.) |
| TransferQueue | This multi-threaded queue can block the insertion stream until the receiving thread pulls the element out of the queue, so that it can be used to implement synchronous and asynchronous message passing between threads. |
| Blockingdeque | Similar to BlockingQueue, but for a two-way queue |
| Concurrentmap | Interface, extends the Map interface. Adds a number of new atomic methods: putIfAbsent, remove, replace, which make it easier and more secure to make multi-threaded programming. |
| ConcurrentNavigableMap | Extends the NavigableMap interface for the multi-threaded version. |
If you are interested in more detailed information about interfaces and collections from java.util.concurrent I advise
read here this article .
2) A table with a very brief description of all collections
A table with a very brief description of all the collections.
* - in fact, although BitSet is called Set'om, the Set interface does not inherit.
| Type of | Single threaded | Multithreaded |
|---|---|---|
| Lists |
|
|
Queues / Deques |
|
|
| Maps |
|
|
| Sets |
|
|
* - in fact, although BitSet is called Set'om, the Set interface does not inherit.
3) Obsolete collections in the JDK
Legacy Java Collections
Universal collections of general purpose, which are considered obsolete (legacy)
Specialized collections built on legacy collections
| Name | Description |
|---|---|
| Hashtable | Originally conceived as a synchronized analogue of HashMap, when it was not yet possible get the collection version using Collecions.synchronizedMap. At the moment, as a rule use ConcurrentHashMap. HashTable is slower and less thread-safe than synchronous HashMap, since it provides synchronism at the level of individual operations, and not entirely at the level collections. |
| Vector | Previously used as a synchronous version of ArrayList, but outdated for the same reasons as HashTable. |
| Stack | It used to be used as a queue, but since it is built on the basis of Vector, also considered obsolete. |
Specialized collections built on legacy collections
| Name | Based on | Description |
|---|---|---|
| Properties | Hashtable | As a data structure built on Hashtable, Properties is a rather outdated construction, it is much better to use a Map containing strings. Read more why Properties not recommended use can be found in this discussion . |
| UIDefaults | Hashtable | The collection that stores the default settings for the Swing component. |
4) Collections that implement the List interface
Collections that implement the List interface
Universal general purpose collections that implement the List:
Collections from the java.util.concurrent package
Highly specialized collections based on the List.
* - the size is given in bytes for 32 bit systems and Compressed Oops, where N is the capacity of the list
| Title | Based on | Description | The size* |
|---|---|---|---|
| ArrayList | List | Implementing a List Interface Based on a Dynamically Variable Array. In most cases, the best possible implementation of the List interface is memory consumption and performance. In extremely rare cases where frequent insertions are required in the beginning or middle of the list with very small by the number of moves through the list, LinkedList will win in performance (but I advise you to use TreeList from apache in these cases). If you are interested in the details of ArrayList I advise you to look at this article . | 4 * N |
| Linkedlist | List | Implementing a List of an interface based on a two-way linked list, i.e. when each item indicates the previous and next item. As a rule, it requires more memory and is worse in performance than an ArrayList, it makes sense to use only in rare cases when it is often necessary to insert / delete in the middle of the list with minimal movements in the list (but I advise you to use TreeList from apache in these cases). It also implements Deque interface. When working through the Queue interface, LinkedList acts as a FIFO queue. If you are interested in the details LinkedList I advise you to look at this article . | 24 * N |
Collections from the java.util.concurrent package
| Title | Based on | Description |
|---|---|---|
| CopyOnWriteArrayList | List | The implementation of the List interface, similar to ArrayList, but each time the list is modified, is created new copy of the entire collection. This requires very large resources with every change in the collection, However, this type of collection does not require synchronization, even if the collection is changed during iteration time. |
Highly specialized collections based on the List.
| Title | Based on | Description |
|---|---|---|
| Rolelist | ArrayList | Collection to store a list of roles (Roles). Highly specialized collection based on ArrayList with several additional methods |
| RoleUnresolvedList | ArrayList | Collection to store a list of unresolved roles (Unresolved Roles). Highly specialized ArrayList based collection with several additional methods |
| Attributelist | ArrayList | Collection for storing MBean attributes. A highly specialized collection based on ArrayList with several additional methods |
* - the size is given in bytes for 32 bit systems and Compressed Oops, where N is the capacity of the list
5) Collections that implement the Set interface (set)
Collections that implement the Set interface (set)
* - the size is given in bytes for 32 bit systems and Compressed Oops, where C is the capacity of the list, S is the size of the list
Highly specialized Set-based collections
Collections from the java.util.concurrent package
| Title | Based on | Description | The size* |
|---|---|---|---|
| Hashset | Set | Implementing a Set interface using hash tables. In most cases, the best possible implementation of the Set interface. | 32 * S + 4 * C |
| LinkedHashSet | Hashset | The implementation of a Set interface based on hash tables and a linked list. Ordered by adding a set that works almost as fast as HashSet. In general, it is almost the same as HashSet, only the order of iteration over the set is determined by the order of adding an element in set for the first time. | 40 * S + 4 * C |
| Treeset | NavigableSet | Implement the NavigableSet interface using a red-black tree. Sorted using Comparator or natural order, that is, traversal / iteration over the set will occur depending on the sorting rule. Based on TreeMap, just like HashSet is based on HashMap | 40 * S |
| Enumset | Set | A high-performance implementation of a Set vector based on a bit vector. All elements of an EnumSet object must belong to a single enum type. | S / 8 |
* - the size is given in bytes for 32 bit systems and Compressed Oops, where C is the capacity of the list, S is the size of the list
Highly specialized Set-based collections
| Title | Based on | Description |
|---|---|---|
| JobStateReasons | Hashset | A collection for storing information about print jobs (print job's attribute set). A highly specialized HashSet-based collection with several additional methods. |
Collections from the java.util.concurrent package
| Title | Based on | Description |
|---|---|---|
| CopyOnWriteArraySet | Set | Similarly, CopyOnWriteArrayList with each change creates a copy of the entire set, therefore recommended for very rare collection changes and thread-safe requirements |
| ConcurrentSkipListSet | Set | It is a multi-threaded analogue of the TreeSet |
6) Collections that implement the Map interface (associative array)
Collections that implement the Map interface
Universal general purpose collections that implement Map:
* - the size is given in bytes for 32 bit systems and Compressed Oops, where C is the capacity of the list, S is the size of the list
Collections from the java.util.concurrent package
| Title | Based on | Description | The size* |
|---|---|---|---|
| Hashmap | Map | Implementation of the Map interface using hash tables (works as a non-synchronous Hashtable, with support for keys and null values). In most cases, the best in performance and Memory Map implementation interface. If you are interested in the details of the device HashMap I advise you to look at this article . | 32 * S + 4 * C |
| LinkedHashMap | Hashmap | The implementation of the Map interface, based on the hash table and the linked list, that is, the keys in the Map stored and managed in the order of addition. This collection works almost as fast as HashMap. It can also be useful for creating caches (see removeEldestEntry (Map.Entry)). If you are interested in the details of the device LinkedHashMap I advise you to look at this article . | 40 * S + 4 * C |
| Treemap | NavigableMap | Implementing NavigableMap with a red-and-black tree, that is, while traversing the collection, keys will be sorted in order, also NavigableMap allows you to search for the closest value to the key. | 40 * S |
| Weakhashmap | Map | Same as HashMap, but all keys are weak links (weak references), that is, garbage collected can remove objects keys and objects values if there are no other references to these objects. WeakHashMap is one of the easiest ways to take full advantage of weak links. | 32 * S + 4 * C |
| Enummap | Map | High-performance implementation of the Map interface based on a simple array. All keys in Only one enum can belong to this collection. | 4 * C |
| IdentityHashMap | Map | Identity-based Map, like HashMap, is based on a hash table, but unlike HashMap it never compares objects to equals, only on whether they are really the same and the same object in memory. This is, firstly, greatly accelerates the work of the collection, secondly, it is useful for protection against “spoof attacks” when equals objects are consciously generated by another object. Third, this collection has many uses for traversing graphs (such as deep copying or serialization), when you need to avoid processing a single object several times. | 8 * C |
* - the size is given in bytes for 32 bit systems and Compressed Oops, where C is the capacity of the list, S is the size of the list
Collections from the java.util.concurrent package
| Title | Based on | Description |
|---|---|---|
| Concurrenthashmap | Concurrentmap | Multi-threaded analogue of HashMap. All data is divided into separate segments and blocked only. individual segments when changing, which significantly speeds up work in a multi-threaded mode. Iterators never throw a ConcurrentModificationException for this type of collection. |
| ConcurrentSkipListMap | ConcurrentNavigableMap | It is a multithreaded analogue of TreeMap |
7) Collections based on Queue / Deque interfaces
Queue / Deque based collections
* - the size is given in bytes for 32 bit systems and Compressed Oops, where C is the capacity of the list, S is the size of the list
Multi-threaded Queue and Deque, which are defined in java.util.concurrent, require a separate article, so here I will not give them if you are interested in information about them I advise you to read this article
| Title | Based on | Description | The size* |
|---|---|---|---|
| ArrayDeque | Deque | Effective implementation of the Deque interface, based on a dynamic array, similar ArrayList | 6 * N |
| Linkedlist | Deque | The implementation of the List and Deque interface based on a two-way linked list, that is, when each item points to the previous and next item. When working through the Queue interface, LinkedList acts as a FIFO queue. | 40 * N |
| PriorityQueue | Queue | Unlimited priority queue based on heap (heap). Items sorted in natural order or using the comparator. Cannot contain null elements. |
* - the size is given in bytes for 32 bit systems and Compressed Oops, where C is the capacity of the list, S is the size of the list
Multi-threaded Queue and Deque, which are defined in java.util.concurrent, require a separate article, so here I will not give them if you are interested in information about them I advise you to read this article
8) Other collections
Other collections
| Title | Description | The size* |
|---|---|---|
| Bit set | Despite the name, BitSet does not implement the Set interface. BitSet is used for compact recording of an array of bits. | N / 8 |
9) Methods of working with collections
Methods of working with collections
Algorithms- The Collections class contains many useful statistical methods.
To work with any collection:
To work with lists:
In Java 8, there was also such a way of working with collections as stream Api, but we will look at examples of its use further in section 5.
To work with any collection:
| Method | Description |
|---|---|
| frequency (Collection, Object) | Returns the number of occurrences of this item in the specified collection. |
| disjoint (Collection, Collection) | Returns true if there are no common items in the two collections. |
| addAll (Collection <? super T>, T ...) | Adds all elements from the specified array (or listed in parameters) to the specified collection. |
| min (Collection) | Return the minimum item from the collection |
| max (Collection) | Returning the maximum item from the collection |
To work with lists:
| Method | Description |
|---|---|
| sort (List) | Sorting using the sorting algorithm by the compound (merge sort algorithm), whose performance in most cases is close to the performance of quick sorting (high quality quicksort), is guaranteed by O (n * log n) performance (unlike quicksort), and stability (unlike quicksort). Stable sorting is one that does not change the order of the same elements when sorting. |
| binarySearch (List, Object) | Search for an item in the list (list) using the binary search algorithm. |
| reverse (List) | Change the order of all elements of the list (list) |
| shuffle (list) | Shuffle all items in the list in random order |
| fill (List, Object) | Rewriting each item in the list with any value |
| copy (List dest, List src) | Copying one list to another |
| rotate (List list, int distance) | Moves all items in the list for a specified distance. |
| replaceAll (List list, Object oldVal, Object newVal) | Replaces all occurrences of one value with another. |
| indexOfSubList (List source, List target) | Returns the index of the first occurrence of the target list in the source list. |
| lastIndexOfSubList (List source, List target) | Returns the index of the last occurrence of the target list in the source list. |
| swap (List, int, int) | Swaps the items in the specified positions |
In Java 8, there was also such a way of working with collections as stream Api, but we will look at examples of its use further in section 5.
10) How are different types of JDK collections inside arranged?
How different types of JDK collections are arranged inside
| Collection | Description of the internal device |
|---|---|
| ArrayList | This collection is just a setting over the array + variable storing the size of the list. Inside just an array that is recreated every time there is no space to add a new item. AT case, adding or removing an item inside the collection, the entire tail shifts in memory new place. Fortunately, copying an array while increasing capacity or adding / removing elements produced fast native / system methods. If details are interesting I advise you to see this article . |
| Linkedlist | Inside the collection is the internal Node class, which contains a link to the previous element, the next element and the value of the element itself. The collection instance itself stores the size and links. on the first and last element of the collection. Considering that the creation of an object is expensive for performance and expensive memory, LinkedList often works slowly and takes much more memory than analogs. Usually ArrayList, ArrayDequery is the best solution for performance and memory, but in some rare cases (frequent insertions in the middle of the list with rare moves through the list), it can be useful (but in this case it is more useful to use TreeList from apache). If you are interested in the details I advise you to see this article . |
| Hashmap | This collection is built on a hash table, that is, inside the collection there is an array of the inner class (buket) Node equal to the collection capacity. When a new element is added, its hash function is calculated, divided by capacity HashMap by module, and thus the location of the element in the array is calculated. If there are no elements stored at this place, a new Node object is created with a link to the element being added and is written to the right place in the array. If there is already an element (s) in this place (a hash collision occurs), then so Node is essentially a simply linked list, that is, contains a link to the next element, then you can bypass all the elements in the list and check them on the equals element being added, if this no such match was found, a new Node object is created and added to the end of the list. If the number of elements in a linked list (buket) becomes more than 8 elements, a binary tree is created instead. For more information on hash tables, see the wiki (HashMap uses the chaining method to resolve collisions). If you are interested in the details of the device HashMap I advise you to look at this article . |
| Hashset | HashSet is just a HashMap, in which the fake Object is written instead of the value, and only the keys matter. Inside the HashSet is always stored collection HashMap. |
| IdentityHashMap | IdentityHashMap is an analogue of HashMap, but it does not require elements to be checked for equals, so how different are any two elements. pointing to different objects. Thanks to this, managed get rid of the internal class Node, storing all the data in one array, while with collisions a suitable free cell is searched until it is found ( method open addressing ). For more on hash tables, see the wiki. (IdentityHashMap uses an open addressing method to resolve collisions) |
| LinkedHashMap / LinkedHashSet | The internal structure is almost the same as with HashMap, except that instead of internal class Node, uses a TreeNode, which knows the previous and next value, this allows you to bypass LinkedHashMap in order of adding keys. Essentially LinkedHashMap = HashMap + LinkedList. If you are interested in the details of the device LinkedHashMap I advise you to look at this article . |
| TreeMap / TreeSet | The internal structure of these collections is built on a balanced red and black tree, more about it can be read on the wiki |
| Weakhashmap | Inside, everything is organized almost as in HashMap, except that instead of the usual links WeakReference is used and there is a separate ReferenceQueue queue that is required to remove Weakentries |
| EnumSet / EnumMap | In EnumSet and EnumMap, unlike HashSet and HashMap, bit vectors and arrays are used for compact data storage and accelerated performance. The limitation of these collections is the fact that EnumSet and EnumMap can store only the values of a single Enum as keys. |
11) Other useful entities of the standard collections library
Other useful entities of the standard collection library.
Let's see what other useful entities the official collection guide contains.
1) Wrapper implementations - Wrappers for adding functionality and changing the behavior of other implementations. Access exclusively through statistical methods.
2) Adapter implementations - this implementation adapts one collection interface to another
3) Convenience implementations - High-performance “mini-implementations” for collection interfaces.
4) Abstract interface implementations - Implementing common functions (skeleton collections) to simplify the creation of specific implementations of collections.
4) Infrastructure
5) Ordering
6) Runtime exceptions
7) Performance
8) Utilities for working with arrays
1) Wrapper implementations - Wrappers for adding functionality and changing the behavior of other implementations. Access exclusively through statistical methods.
- Collections.unmodifiableInterface — A wrapper for creating a non-modifiable collection based on the specified one, any attempt to modify this collection will be thrown UnsupportedOperationException
- Collections.synchronizedInterface — Creating a synchronized collection based on the specified, as long as access to the base collection goes through the wrapper collection returned by this function, thread safety is guaranteed.
- Collections.checkedInterface — Returns a collection with type validation dynamically.
(at runtime), that is, returns a type-safe view for this collection, which
throws a ClassCastException when trying to add an element of an erroneous type. Using
at the compilation level, the JDK’s generics mechanism checks type consistency; however, this mechanism
you can get around, dynamic type checking does not allow to use this feature.
2) Adapter implementations - this implementation adapts one collection interface to another
- newSetFromMap (Map) - Creates a Map interface implementation from any implementation of a Set interface.
- asLifoQueue (Deque) - returns the view from Deque as a queue operating on the principle of Last In First Out (LIFO).
3) Convenience implementations - High-performance “mini-implementations” for collection interfaces.
- Arrays.asList - Allows you to display an array as a list
- emptySet, emptyList and emptyMap - returns an empty unmodified implementation. empty set, list, or
map - singleton, singletonList and singletonMap - returns an unmodifiable set, list or map containing one specified object (or one key-value relationship)
- nCopies - Returns an unmodifiable list containing n copies of the specified object.
4) Abstract interface implementations - Implementing common functions (skeleton collections) to simplify the creation of specific implementations of collections.
- AbstractCollection - An abstract implementation of the Collection interface for collections that are neither a set nor a list (such as bag or multiset).
- AbstractSet - An abstract implementation of the Set interface.
- AbstractList - An abstract implementation of the List interface for lists that allow positional access (random access), such as an array.
- AbstractSequentialList - An abstract implementation of the List interface for sequential access lists (sequential access), such as a linked list.
- AbstractQueue - Abstract Queue implementation.
- AbstractMap - Abstract Map implementation.
4) Infrastructure
- Iterators - Similar to the usual Enumeration interface, but with great potential.
- Iterator - In addition to the functionality of the Enumeration interface, which includes the ability to remove items from the collection.
- A ListIterator is an Iterator that is used for lists, which adds to the functionality of a regular interface Iterator, such as iteration in both directions, replacing elements, inserting elements, and getting by index.
5) Ordering
- Comparable - Determines the natural sort order for the classes that implement them. This order can be used in sorting methods or to implement sorted set or map.
- Comparator - Represents an ordering of a set or a map. It is not possible to implement the Comparable interface.
6) Runtime exceptions
- UnsupportedOperationException - This error is thrown when the collection does not support the operation that was called.
- ConcurrentModificationException - throws out the iterators or list iterators, if the collection on which it was based was unexpectedly (for the algorithm) changed during the iteration, also thrown into views based on lists, if the main list was changed unexpectedly.
7) Performance
- RandomAccess - A marker interface that lists lists that allow quick (usually in constant time) access to an item by position. This allows you to generate algorithms that take this behavior into account for selecting sequential and positional access.
8) Utilities for working with arrays
- Arrays - A set of static methods for sorting, searching, comparing, resizing, getting a hash for an array. It also contains methods for converting an array into a string and filling the array with primitives or objects.
More on this in my article , for example, the section on collection operations or the use of collections from guava, apache commons and Eclipse (GS Collections).
Ii. Stream api
Functional programming, lambdas, and features added to Java 8 are also very often seen in interviews. I described in detail in this crib , here I will give only a brief description:
Stream api
The Java Stream API offers two kinds of methods:
1. Conveyor - return another stream, that is, they work as a builder,
2. Terminal - return another object, such as a collection, primitives, objects, Optional, etc.
For those who do not know what Stream Api is.
Stream API is a new way to work with data structures in a functional style. Most often, using stream in Java 8 works with collections, but in fact this mechanism can be used for a wide variety of data.
Stream Api allows you to write processing of data structures in the style of SQL, if earlier the task to get the sum of all odd numbers from the collection was solved by the following code:
Then with the help of Stream Api you can solve this problem in a functional style:
Moreover, Stream Api allows solving the task in parallel only by changing stream () to parallelStream () without any extra code, i.e.
Already makes the code parallel, without any semaphores, synchronizations, risks of deadlocks, etc.
Stream Api allows you to write processing of data structures in the style of SQL, if earlier the task to get the sum of all odd numbers from the collection was solved by the following code:
Integer sumOddOld = 0; for(Integer i: collection) { if(i % 2 != 0) { sumOddOld += i; } } Then with the help of Stream Api you can solve this problem in a functional style:
Integer sumOdd = collection.stream().filter(o -> o % 2 != 0).reduce((s1, s2) -> s1 + s2).orElse(0); Moreover, Stream Api allows solving the task in parallel only by changing stream () to parallelStream () without any extra code, i.e.
Integer sumOdd = collection.parallelStream().filter(o -> o % 2 != 0).reduce((s1, s2) -> s1 + s2).orElse(0); Already makes the code parallel, without any semaphores, synchronizations, risks of deadlocks, etc.
I. Ways to create streams
Ways to create streams
Here are some ways to create a stream.
| The way to create stream | Creation Template | Example |
|---|---|---|
| 1. Classic: Creating a stream from the collection | collection. stream () | |
| 2. Creating a stream from values | Stream.of ( value1 , ... valueN ) | |
| 3. Creating a stream from an array | Arrays.stream ( array ) | |
| 4. Creating a stream from a file (each line in the file will be a separate element in the stream) | Files.lines ( file_path ) | |
| 5. Creating a stream from a string | "line". chars () | |
| 6. Using Stream.builder | Stream. builder (). add (...) .... build () | |
| 7. Creating a parallel stream | collection. parallelStream () | |
| 8. Creating endless streams using Stream.iterate | Stream.iterate ( start_condition , expression_generation ) | |
| 9. Creating Endless Stream with Stream.generate | Stream.generate ( generation_express ) | |
Ii. Streaming Methods
The Java Stream API offers two kinds of methods:
1. Conveyor - return another stream, that is, they work as a builder,
2. Terminal - return another object, such as a collection, primitives, objects, Optional, etc.
What are the differences between conveyor and terminal methods?
The general rule is that a stream can have as many pipeline calls as possible and at the end one terminal, all pipeline methods are lazily executed and until the terminal method is called no action actually occurs, just like creating a Thread or Runnable object , but do not call it start.
In general, this mechanism is similar to constructing SQL queries, there can be any number of nested Selects and only one result in the end. For example, in the expression collection.stream (). Filter ((s) -> s.contains ("1")). Skip (2) .findFirst (), filter and skip are pipelined, and findFirst is terminal, it returns the object Optional and this ends work with stream.
In general, this mechanism is similar to constructing SQL queries, there can be any number of nested Selects and only one result in the end. For example, in the expression collection.stream (). Filter ((s) -> s.contains ("1")). Skip (2) .findFirst (), filter and skip are pipelined, and findFirst is terminal, it returns the object Optional and this ends work with stream.
2.1 Brief description of conveyor methods of working with streams
Read more ...
| Stream method | Description | Example |
|---|---|---|
| filter | Filters records, returns only records that match the condition. | collection.stream (). filter ("a1" :: equals) .count () |
| skip | Lets skip the first N items. | collection.stream (). skip (collection.size () - 1) .findFirst (). orElse ("1") |
| distinct | Returns a stream without duplicates (for the equals method) | collection.stream (). distinct (). collect (Collectors.toList ()) |
| map | Converts every element of stream | collection.stream (). map ((s) -> s + "_1"). collect (Collectors.toList ()) |
| peek | Returns the same stream, but applies a function to each element of the stream. | collection.stream (). map (String :: toUpperCase) .peek ((e) -> System.out.print ("," + e)). collect (Collectors.toList ()) |
| limit | Allows you to limit the sample to a certain number of first elements. | collection.stream (). limit (2) .collect (Collectors.toList ()) |
| sorted | Allows you to sort the values either in natural order or by specifying the Comparator | collection.stream (). sorted (). collect (Collectors.toList ()) |
| mapToInt , mapToDouble , mapToLong | Analogue map, but returns a numeric stream (that is, a stream of numeric primitives) | collection.stream (). mapToInt ((s) -> Integer.parseInt (s)). toArray () |
| flatmap flatMapToInt , flatMapToDouble , flatMapToLong | It looks like a map, but it can create several | collection.stream (). flatMap ((p) -> Arrays.asList (p.split (",")). stream ()). toArray (String [] :: new) |
2.2 Brief description of terminal methods of working with streams
Read more ...
Pay attention to the methods findFirst, findAny, anyMatch are short-circuiting methods, that is, bypassing streams is organized in such a way as to find a suitable element as quickly as possible, and not to bypass the entire original stream.
| Stream method | Description | Example |
|---|---|---|
| findFirst | Returns the first element from the stream (returns Optional) | collection.stream (). findFirst (). orElse ("1") |
| findAny | Returns any suitable element from the stream (returns Optional) | collection.stream (). findAny (). orElse ("1") |
| collect | Presentation of results in the form of collections and other data structures | collection.stream (). filter ((s) -> s.contains ("1")). collect (Collectors.toList ()) |
| count | Returns the number of elements in the stream. | collection.stream (). filter ("a1" :: equals) .count () |
| anyMatch | Returns true if the condition is true for at least one element. | collection.stream (). anyMatch ("a1" :: equals) |
| noneMatch | Returns true if the condition is not met for one element. | collection.stream (). noneMatch ("a8" :: equals) |
| allMatch | Returns true if the condition is true for all items. | collection.stream (). allMatch ((s) -> s.contains ("1")) |
| min | Returns the minimum element, uses a comparator as a condition | collection.stream (). min (String :: compareTo) .get () |
| max | Returns the maximum element, uses a comparator as a condition | collection.stream (). max (String :: compareTo) .get () |
| forEach | Applies a function to each stream object, order when executed in parallel is not guaranteed. | set.stream (). forEach ((p) -> p.append ("_ 1")); |
| forEachOrdered | Applies a function to each stream object, preserving the order of the elements guarantees | list.stream (). forEachOrdered ((p) -> p.append ("_ new")); |
| toArray | Returns an array of stream values | collection.stream (). map (String :: toUpperCase) .toArray (String [] :: new); |
| reduce | Allows you to perform aggregate functions on the entire collection and return a single result. | collection.stream (). reduce ((s1, s2) -> s1 + s2) .orElse (0) |
Pay attention to the methods findFirst, findAny, anyMatch are short-circuiting methods, that is, bypassing streams is organized in such a way as to find a suitable element as quickly as possible, and not to bypass the entire original stream.
2.3 Brief description of additional methods for numeric streams
Read more ...
| Stream method | Description | Example |
|---|---|---|
| sum | Returns the sum of all numbers. | collection.stream (). mapToInt ((s) -> Integer.parseInt (s)). sum () |
| average | Returns the arithmetic average of all numbers. | collection.stream (). mapToInt ((s) -> Integer.parseInt (s)). average () |
| mapToObj | Converts a numeric stream back to an object. | intStream.mapToObj ((id) -> new Key (id)). toArray () |
2.4 Several other useful streaming methods
Read more ...
| Stream method | Description |
|---|---|
| isParallel | Find out if the stream is parallel |
| parallel | Return a parallel stream, if the stream is already parallel, it can return itself |
| sequential | Return a consecutive stream, if the stream is already consistent, it can return itself |
If something above is not clear, I advise you to look at a separate article.
Iii. Serialization
On this topic, too, there are quite often questions at interviews.
To read...
Main classes:
1. ObjectOutput - stream interface for “manual” serialization of objects. The main methods of writeObject (object) are writing an object to the stream, write (...) is writing an array, flush () is saving the stream. The main implementation of ObjectOutputStream
2. ObjectInput - a stream interface for manually restoring objects after serialization. The main methods of readObject () are reading objects, skip - skip n bytes. The main implementation of ObjectInputStream .
3. Serializable - an interface in which Object Serialization automatically saves and restores the state of objects.
Objects implementing this interface must:
1. have access to the constructor without arguments from the nearest non-serializable ancestor,
mark serializable and non-serializable fields using serialPersistentFields and transient.
Also such classes can implement methods (optional):
1. writeObject - to control the serialization or write additional information.
2. readObject - to control deserialization,
3. writeReplace - to replace an object. which has already been recorded in stream,
4. readResolve - definitions of objects to recover from stream.
4. Externalizable - an interface in which Object Serialization delegates the functions of saving and restoring objects to functions defined by programmers. Externalizable extends the interface Serializable.
Objects implementing this interface must:
1. have a public constructor with no arguments
2. implement the writeExternal and readExternal methods for reading and writing, respectively,
3. Also such classes can implement methods (optional):
- writeReplace - to replace an object. which has already been recorded in stream,
- readResolve - definitions of objects for recovery from stream.
1. ObjectOutput - stream interface for “manual” serialization of objects. The main methods of writeObject (object) are writing an object to the stream, write (...) is writing an array, flush () is saving the stream. The main implementation of ObjectOutputStream
2. ObjectInput - a stream interface for manually restoring objects after serialization. The main methods of readObject () are reading objects, skip - skip n bytes. The main implementation of ObjectInputStream .
3. Serializable - an interface in which Object Serialization automatically saves and restores the state of objects.
Objects implementing this interface must:
1. have access to the constructor without arguments from the nearest non-serializable ancestor,
mark serializable and non-serializable fields using serialPersistentFields and transient.
Also such classes can implement methods (optional):
1. writeObject - to control the serialization or write additional information.
2. readObject - to control deserialization,
3. writeReplace - to replace an object. which has already been recorded in stream,
4. readResolve - definitions of objects to recover from stream.
4. Externalizable - an interface in which Object Serialization delegates the functions of saving and restoring objects to functions defined by programmers. Externalizable extends the interface Serializable.
Objects implementing this interface must:
1. have a public constructor with no arguments
2. implement the writeExternal and readExternal methods for reading and writing, respectively,
3. Also such classes can implement methods (optional):
- writeReplace - to replace an object. which has already been recorded in stream,
- readResolve - definitions of objects for recovery from stream.
Iv. Maths
Here on this topic questions are very rare (I don’t remember a single issue on this topic), however, just in case, it is worth remembering about them.
To read...
There are only a few classes for implementing mathematical calculations in Java SE:
1. java.lang.Math - a class containing a large number of static mathematical functions, unlike StrictMath , mathematical functions do not always return exactly the same values for the same argument (the values of real numbers may differ by a very small value), This allows achieve better performance.
2. java.lang.StrictMath - a class containing a large number of static mathematical functions. In contrast to Math, for a single argument, the result is always exactly the same. Contain functions analogs that are not in Math.
3. java.math.BigDecimal and java.math.BigInteger - classes for working with numbers requiring high accuracy and dimension.
4. java.math.MathContext - settings that can be used in the BigDecimal or BigInteger classes.
1. java.lang.Math - a class containing a large number of static mathematical functions, unlike StrictMath , mathematical functions do not always return exactly the same values for the same argument (the values of real numbers may differ by a very small value), This allows achieve better performance.
2. java.lang.StrictMath - a class containing a large number of static mathematical functions. In contrast to Math, for a single argument, the result is always exactly the same. Contain functions analogs that are not in Math.
3. java.math.BigDecimal and java.math.BigInteger - classes for working with numbers requiring high accuracy and dimension.
4. java.math.MathContext - settings that can be used in the BigDecimal or BigInteger classes.
V. Reference Objects
But about Reference objects, there are questions and very often developers float on them, since these are rarely used classes. In fact, these are classes for more flexible memory management than the usual “strong” pointers.
To read...
Classes that allow you to create different Reference objects:
1. Reference - Abstract class for similar objects.
2. SoftReference - Soft links, objects will be deleted when the garbage collector detects that there is no free memory left.
3. WeakReference - Weak reference. On the next pass, the Garbage collector will delete an object that can only be accessed via such a link. Used for caches and temporary objects.
4. PhantomReference - Creates a phantom link, the link itself always returns null, but before removing the object, the link is placed in the ReferenceQueue queue and you can release the resources associated with the object, bypassing this queue, that is, it is an analogue of the finalizers.
5. ReferenceQueue - The queue where links are added when the garbage collector has deleted the objects they refer to.
1. Reference - Abstract class for similar objects.
2. SoftReference - Soft links, objects will be deleted when the garbage collector detects that there is no free memory left.
3. WeakReference - Weak reference. On the next pass, the Garbage collector will delete an object that can only be accessed via such a link. Used for caches and temporary objects.
4. PhantomReference - Creates a phantom link, the link itself always returns null, but before removing the object, the link is placed in the ReferenceQueue queue and you can release the resources associated with the object, bypassing this queue, that is, it is an analogue of the finalizers.
5. ReferenceQueue - The queue where links are added when the garbage collector has deleted the objects they refer to.
Vi. Regular expressions
Again, a rare topic for interviews, but worth remembering.
There are two main classes for working with regular expressions and one interface:
1. Pattern - Compiled regular expression to be used in the Matcher.
Matcher. Class for executing compiled regular expression (Pattern class) over CharSequence.
2. MatchResult - Used to return Matcher results
VII. Logging
I also don’t remember questions on this topic, but it’s still useful to repeat the standard logging in SE.
To read...
Basic logging scheme
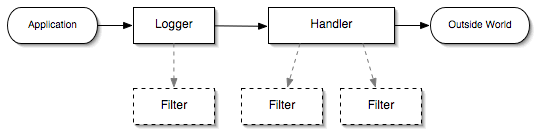
As can be seen from the diagram, when logging, the Logger applies filters and sends a message to Handler (or chains of Handlers), which also applies filters, formatting and gives the message to the outside world (displays to the console, saves to a file, etc.)
Each message has a level (Level class) from FINEST to SEVERE,
The main types of logging classes in Java SE:
I, handlers
There are several Handler in Java SE:
1. StreamHandler - Write to OutputStream,
2. ConsoleHandler - Write to System.err (console),
3. FileHandler - Write to file,
4. SocketHandler - Record in TCP ports,
5. MemoryHandler - Save logs in memory,
II, Formatters
Java SE provides two types of formatters:
1. SimpleFormatter - formatting as an easy-to-read person,
2. XMLFormatter - formatting xml structure
Iii. Service classes
1. LogManager - The LogManager class stores information about all system loggers and their properties,
2. The class LoggingPermission is used to determine the rights to change loggers, etc. for SecurityManager.
3. The Logger class is used to log messages, and the LogRecord class is used to transfer messages between the logging frameworks and Handlers.
As can be seen from the diagram, when logging, the Logger applies filters and sends a message to Handler (or chains of Handlers), which also applies filters, formatting and gives the message to the outside world (displays to the console, saves to a file, etc.)
Each message has a level (Level class) from FINEST to SEVERE,
The main types of logging classes in Java SE:
I, handlers
There are several Handler in Java SE:
1. StreamHandler - Write to OutputStream,
2. ConsoleHandler - Write to System.err (console),
3. FileHandler - Write to file,
4. SocketHandler - Record in TCP ports,
5. MemoryHandler - Save logs in memory,
II, Formatters
Java SE provides two types of formatters:
1. SimpleFormatter - formatting as an easy-to-read person,
2. XMLFormatter - formatting xml structure
Iii. Service classes
1. LogManager - The LogManager class stores information about all system loggers and their properties,
2. The class LoggingPermission is used to determine the rights to change loggers, etc. for SecurityManager.
3. The Logger class is used to log messages, and the LogRecord class is used to transfer messages between the logging frameworks and Handlers.
Viii. Concurrency
To read...
Possible questions
- How can we make sure the last () is the last thread to finish in the Java Program?
- How can thread interact with each other?
- Why notify () and notifyAll () are in Object class?
- Why wait (), notify () and notifyAll ()?
- Why are thread sleep () and yield () methods static?
- How to ensure thread safety in Java?
- What is volatile keyword in java
- Which is preferable to the synchronized method or the synchronized block?
- What is ThreadLocal?
- What is Thread Group? Should I use them?
- What is Java Thread Dump, How to get a Java Thread dump program?
- What is Java Timer Class? How to start a task after a certain time interval?
- What is a thread pool? How to create a thread pool in java?
- What happens if the thread class does not override the run () method?
Thread
To read...
Processes and threads - the difference is that processes are independent applications (managed by the OS), thread are separate lightweight threads for parallel execution in Java (controlled by the JVM and the programmer).
The advantages of multi-threaded programming - a correctly written multi-threaded application works faster due to the use of multiple processors and the processor does not stand idle until one of the threads is waiting for resources.
daemon thread is a thread that runs in the background and the JVM does not need to wait for it to complete to complete the work. You can make any thread a daemon using setDaemon (true), but this method must be called before thread starts with start.
ThreadGroup is a deprecated API that provides information about a group of threads. Now not recommended for use.
Java Thread Dump - getting information about the status of all JVM threads and searching for deadlock situations or other problems with multithreading. There are many ways to generate Java Thread Dump, for example, in Java 8 you can generate it using the jcmd PID command file_name for dump or kill -3 PID, or using any profiler (VisualVM, jstack, etc.)
Ways to create thread in Java SE:
1. Create a class that implements the Runnable interface, implement the run method and start the thread by the start method, pay attention to call the run method incorrectly, in this case a new thread will not be created (although it will work).
2. Create a class-successor from the class Thread, also override the run method and start thread by the start method. Unlike method 1, the Thread class provides a number of already defined methods, but the interface implementation provides more flexibility (since multiple inheritance in Java is impossible),
3. Use Executors, which provides a high-level analogue of methods 1-2.
Methods for working with Thread
1. sleep - stops execution for the specified time, or until the moment when Thread was not interrupted,
2. interrupt - sends a signal to Thread, indicating that it should be terminated (soft interruption of the stream), the stream should support the processing of this signal (polling the Thread.interrupted flag periodically),
3. join - waits for the end of another thread or stop thread,
4. synchronized - the keyword before the methods or synchronized block (link) {...}
5. wait - stop the thread and wait for a notify or notifyAll call.
6. stop (deprecated) - immediately stopping the thread, it is not recommended to use it, because the state of shared variables may be in an incorrect state.
7. suspend (deprecated) and resume (deprecated) - temporarily stop the stream and restore it. It is not recommended to use as very often this leads to a deadlock “(resources with a temporary stop remain locked)
8. setUncaughtExceptionHandler - the ability to add an exception handler to this thread.
Special variables for thread:
ThreadLocal is a local variable for only one thread, each thread will see its value.
volatile is a keyword that marks variables that all threads read from memory (heap) and do not cache. This does not solve all synchronization problems, however, ordinary variable threads have the right to cache and not update at all for a long time. For more reliable work with several threads, you should use Atomic variables or synchronization blocks.
Possible questions
- What is the difference between Process and Thread?
- What are the benefits of multi-threaded programming?
- What is the difference between user thread and daemon thread?
- How to create Thread in Java?
- What are the different states of Thread?
- Is it possible to call the run () method of the Thread class?
- How can I stop the execution of Thread for a certain time?
- What is Thread Priority?
- What are Thread Scheduler and Time Slicing?
- What is context-switching in multi-threading?
- How to create daemon thread in java?
Processes and threads - the difference is that processes are independent applications (managed by the OS), thread are separate lightweight threads for parallel execution in Java (controlled by the JVM and the programmer).
The advantages of multi-threaded programming - a correctly written multi-threaded application works faster due to the use of multiple processors and the processor does not stand idle until one of the threads is waiting for resources.
daemon thread is a thread that runs in the background and the JVM does not need to wait for it to complete to complete the work. You can make any thread a daemon using setDaemon (true), but this method must be called before thread starts with start.
ThreadGroup is a deprecated API that provides information about a group of threads. Now not recommended for use.
Java Thread Dump - getting information about the status of all JVM threads and searching for deadlock situations or other problems with multithreading. There are many ways to generate Java Thread Dump, for example, in Java 8 you can generate it using the jcmd PID command file_name for dump or kill -3 PID, or using any profiler (VisualVM, jstack, etc.)
Ways to create thread in Java SE:
1. Create a class that implements the Runnable interface, implement the run method and start the thread by the start method, pay attention to call the run method incorrectly, in this case a new thread will not be created (although it will work).
2. Create a class-successor from the class Thread, also override the run method and start thread by the start method. Unlike method 1, the Thread class provides a number of already defined methods, but the interface implementation provides more flexibility (since multiple inheritance in Java is impossible),
3. Use Executors, which provides a high-level analogue of methods 1-2.
Methods for working with Thread
1. sleep - stops execution for the specified time, or until the moment when Thread was not interrupted,
2. interrupt - sends a signal to Thread, indicating that it should be terminated (soft interruption of the stream), the stream should support the processing of this signal (polling the Thread.interrupted flag periodically),
3. join - waits for the end of another thread or stop thread,
4. synchronized - the keyword before the methods or synchronized block (link) {...}
5. wait - stop the thread and wait for a notify or notifyAll call.
6. stop (deprecated) - immediately stopping the thread, it is not recommended to use it, because the state of shared variables may be in an incorrect state.
7. suspend (deprecated) and resume (deprecated) - temporarily stop the stream and restore it. It is not recommended to use as very often this leads to a deadlock “(resources with a temporary stop remain locked)
8. setUncaughtExceptionHandler - the ability to add an exception handler to this thread.
Special variables for thread:
ThreadLocal is a local variable for only one thread, each thread will see its value.
volatile is a keyword that marks variables that all threads read from memory (heap) and do not cache. This does not solve all synchronization problems, however, ordinary variable threads have the right to cache and not update at all for a long time. For more reliable work with several threads, you should use Atomic variables or synchronization blocks.
Atomic operations and classes
To read...
Atomic operations - operations that are performed or not performed as a whole.
The following atomic operations:
1. Reading and writing references and primitive types (except for long and double)
2. Reading and writing all variables marked as volatile (since writing and reading is performed as an happens-before relationship, that is, in guaranteed order),
Atomic variables for a simple way to create variables that are common to different threads with minimization of synchronization and errors. See javadoc for details.
Possible questions
- What data types in Java are atomic for read / write operations in terms of multithreading?
- What is atomic operation?
- What atomic classes in the Java Concurrency API do you know?
Atomic operations - operations that are performed or not performed as a whole.
The following atomic operations:
1. Reading and writing references and primitive types (except for long and double)
2. Reading and writing all variables marked as volatile (since writing and reading is performed as an happens-before relationship, that is, in guaranteed order),
Atomic variables for a simple way to create variables that are common to different threads with minimization of synchronization and errors. See javadoc for details.
Liveness problem
To read...
Problems running in multi-threaded applications (liveness problem):
1. Deadlock - blocking of two different resources by two threads with endless waiting for release,
2, Starvation - one of the threads blocks an often used resource for a long time, forcing the remaining streams to wait for release
3. Livelock - when two threads release and occupy the same resources in response to each other's actions, they cannot take all the necessary resources and continue execution.
Possible questions
- What is deadlock? How to analyze and avoid deadlock?
- What problems with multithreading besides Deadlock?
- What is Starvation and Livelock?
Problems running in multi-threaded applications (liveness problem):
1. Deadlock - blocking of two different resources by two threads with endless waiting for release,
2, Starvation - one of the threads blocks an often used resource for a long time, forcing the remaining streams to wait for release
3. Livelock - when two threads release and occupy the same resources in response to each other's actions, they cannot take all the necessary resources and continue execution.
Strategy for defining immutable objects
To read...
To create immutable objects is required to adhere to the following rules:
1. Do not provide "setter" methods, all fields must be final and private,
2. Do not allow inheritors to override methods, the simplest way is to define a class as final. A more complicated way is to define the constructor as private and create objects using the factory method.
3. Fields, including fields with links to mutable objects should not allow changes:
4. Do not provide methods for modifying mutable objects.
5. Do not give references to mutable objects, if necessary, create copies and transfer copies of objects.
1. Do not provide "setter" methods, all fields must be final and private,
2. Do not allow inheritors to override methods, the simplest way is to define a class as final. A more complicated way is to define the constructor as private and create objects using the factory method.
3. Fields, including fields with links to mutable objects should not allow changes:
4. Do not provide methods for modifying mutable objects.
5. Do not give references to mutable objects, if necessary, create copies and transfer copies of objects.
High Level Threading Tools
To read...
Possible questions
- What is the Lock interface in the Java Concurrency API? What are its advantages compared to synchronization?
- What is the Executors Framework?
- What is BlockingQueue? How to avoid Producer-Consumer problem using Blocking Queue?
- What is Callable and Future?
- What is the FutureTask class?
- What is the Concurrent Collection class?
- What is the Executors class?
- What improvements in the Concurrency API are there in Java 8?
To read...
Unlike synchronized blocks, etc. , J8SE .
:
1. Task scheduling framework ( Executor) — , ..
2. ForkJoinPool — , Executors ExecutorService .. , ( work-stealing).
3. Lock — ,
4. Executors ,
5. — , (Concurrent Collection, BlockingQueue, java.util.concurrent .),
6. Atomic . javadoc
7. ThreadLocalRandom ( JDK 7) .
:
1. Task scheduling framework ( Executor) — , ..
2. ForkJoinPool — , Executors ExecutorService .. , ( work-stealing).
3. Lock — ,
4. Executors ,
5. — , (Concurrent Collection, BlockingQueue, java.util.concurrent .),
6. Atomic . javadoc
7. ThreadLocalRandom ( JDK 7) .
Ix. Exceptions and Errors
To read...
Java :
1. Error — , , , OutOfMemoryError. catch, .
2. Exception — , . They are divided into:
— checked — Exception, catch throws ( Exception throws )
— unchecked — Exception, throws ,
:
1. Throwable — exception
1.1 Error — , ,
1.2 Exception — exception, checked exception ( RuntimeException)
1.2.1 RuntimeException — — unchecked exception,
Exception'. Exception , , NullPointerException ( , - ), „“ IllegalArgumentException ( , ).
- unchecked throws?
- , throws ?
- checked unchecked ?
- checked unchecked ?
- Exception Error?
- Exception?
- Error Throwable?
Java :
1. Error — , , , OutOfMemoryError. catch, .
2. Exception — , . They are divided into:
— checked — Exception, catch throws ( Exception throws )
— unchecked — Exception, throws ,
:
1. Throwable — exception
1.1 Error — , ,
1.2 Exception — exception, checked exception ( RuntimeException)
1.2.1 RuntimeException — — unchecked exception,
Exception'. Exception , , NullPointerException ( , - ), „“ IllegalArgumentException ( , ).
X. Strings
To read...
String , . , (immutable) (final), ( , , ), ( immutable, ), , , Map, immutable .
String — „abc“, new (new String(»abc")) , StringBuffer StringBuilder.
String Pool (, ). C intern() .
StringBuffer StringBuilder , , StringBuffer , StringBuilder — , — StringBuilder .
...
- String Java? String — ?
- String ?
- ?
- SubSequence String?
- java-?
- char ?
- String ?
- switch ?
- String, StringBuffer StringBuilder?
- String immutable final Java
- java?
- Char String ?
- , Java?
- String Pool?
- string ()?
- Java?
- String HashMap Java?
String , . , (immutable) (final), ( , , ), ( immutable, ), , , Map, immutable .
String — „abc“, new (new String(»abc")) , StringBuffer StringBuilder.
String Pool (, ). C intern() .
StringBuffer StringBuilder , , StringBuffer , StringBuilder — , — StringBuilder .
Thanks for attention. Other cheat sheets can be found in my profile.
Source: https://habr.com/ru/post/314386/
All Articles