Administrator abstract: corporate SAN and most importantly in the work of the architect (updated)

In the last article I talked about the basic concepts of SAN on the example of small installations. Today we dig a little deeper and understand the construction of storage networks for a large organization. Of course, one short article will not replace the bulk works of Brocade and HP, but at least it will help to navigate and choose the right course in the design.
When building large storage networks, the main headache is the architecture of the solution, rather than the types of optics and switch manufacturers. Consumer nodes are much larger and many of them are critical for business, so using a simple scheme “connected several servers to the storage directly, and everything” will not work.
A couple of words about topologies and reliability
If you simplify a little, the “big” SAN network differs from the small one only in reliability and, to a lesser extent, in performance. Basic technologies and protocols are similar to those used in networks of several servers. As a rule, separate SAN networks are called factories - in one organization there can be about a dozen factories.
Enterprise infrastructure is still dominated by the Fiber Channel protocol and optical links. Recent years have been actively expanding convergent solutions, but I'll talk about them a little later.
Cascade The most unreliable topology, which is sometimes used with a small number of nodes.
Devices are connected in series to each other, which gives more points of failure and an increase in load when scaling. A special case of the cascade is a point-to-point connection, when the storage system is connected directly to the server.Ring . The same cascade, but the terminating switch is connected to the first one. Reliability and performance more, because the FSPF protocol (Fabric Shortest Path First) will help you choose the shortest route. However, the performance of such a network is often violated in the process of scaling and is not guaranteed when several links are broken.
A full graph , where each switch is connected to each. This topology has high resiliency and performance, but the cost of solutions and scalability leave much to be desired.
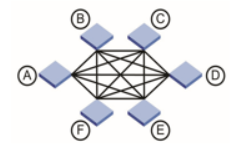
The graph is conveniently used to connect edge switches of several sites.- Core-edge. In practice, it is used most often and in its essence is similar to the usual star network topology.
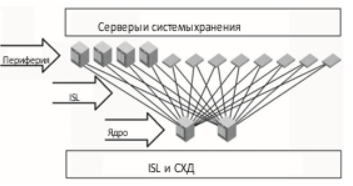
In the center there are several switches (network core), peripheral switches with terminal devices are connected to them. The solution goes fault tolerant, productive and well scalable.
The main scheme for building a SAN in most cases is a Core-Edge, with several reserved switches in the center. I recommend to use it in the first place, and to keep all exotic things for unusual cases. By the way, the ring, despite its moral decay, is actively used inside storage systems for connecting disks to controllers.
If you already had to build a cluster of any system, then you already know the concept of a single point of failure.
A single point of failure is any component of the system whose failure fails to work the entire system in a most radical way. This component can be an unreserved network connection, a single controller in a storage system, or a SAN switch.
The main job of a storage network designer is to build a network without a single point of failure, which optimally combines scalability and cost. As a starting point, they choose the construction of two independent factories to secure each other. Such a solution is called a “redundant factory”, and all its nodes are connected simultaneously to two factories using the Multipath technology.
If something happens to any important node of one of the factories, the exchange of data takes place through its backup, without any negative consequences. Of course, when building, it is necessary to lay a certain margin of productivity in each factory, usually two-fold. If this is not done, then in case of a crash, the performance of any SAN-using services can noticeably subside.
Another point to take into account is called SAN Oversubscription .

This difficult to translate term means the competition of several devices for a single communication line. A typical situation: 10 clients are connected to the switch that access storage in another segment through a single ISL link (Intersite Link, a channel between switches). In this scenario, the oversubscription will be 10: 1. If the number of ISL links is increased to two, then the ratio will be 5: 1.
That is, in a situation, the Oversubscription is trying to squeeze more traffic into the channel than this channel can handle. Of course, there are queues at the entrance and decreases the performance of specific applications. To prevent this from happening, always leave a margin of "tunnels" between factories. Most likely, maintaining the 1: 1 ratio in most cases will not be rational, but it is important to always control this point when expanding the network.
Choosing equipment for FC networks
As is usually the case, the preferences of a particular manufacturer is an ideological question. But there are several well-known players on the SAN market, whose systems you will encounter on a large network are more likely:
QLoqic network adapters, switches, and SAN routers from Brocade, HP, and Cisco .
- HP, NetApp, IBM storage systems. Of course, the list is not complete.
Despite the fact that FC services can boast of high standardization and a long history, the golden rule of the designer is still valid: build a network on the equipment of one manufacturer . That is, everything that provides communication between the client and the storage should be purchased from one manufacturer. So you will avoid compatibility issues and a variety of "floating glitches."
If for some reason the golden rule does not apply to your situation, be sure to check the compatibility tables from equipment manufacturers:
Personally, I only encountered compatibility problems twice, but each time it was rather unpleasant. In one of the cases, I don’t remember the specific participants, but the FC adapter of the rack server periodically and for no reason both optical links (main and backup) disappeared, had to be manually reconnected. It was decided, in my opinion, the installation of other transceivers. And the problem transceivers quietly worked in another network of one of the company's branches.
About distance
If you work in a factory or simply in a large office center, then the issue of geographically distributed networks becomes relevant. Banal several floors in a building can result in several hundred meters of fiber and you will have to take into account technological features:
You need to choose the right transceivers for single mode fiber, as it is suitable for use over long distances.
If we are talking about pulling optics between buildings (along poles), then FCoE based on conventional Ethernet over twisted pair can be much cheaper.
- Long segments of "dark optics" (a link between two clients that do not have active network devices) can be divided into short ones using the same switches. By the way, this is a popular option for building an optical network in a building: a pair of switches on each floor.
Based on practice, I would recommend using FCoE for distributed segments or even a normal TCP / IP network. Fault tolerance and synchronization in this case can be performed at the level of specific applications.

A striking example is MS SQL. It is not necessary to build an 8 GB optical network between buildings in the industrial zone in order to ensure that all clients have access to a single database. It is enough to organize the connection at the terminal server level or the client part of the application that uses MS SQL (1C, for example). It is not always necessary to solve the problem "head on" and design a complex and expensive storage network.
Hyper Convergence Reboot
About 5 years ago the idea of converged infrastructure was actively promoted at many technology conferences. It was presented as an incredible innovation and technology for building the data center of the future, without really explaining what the essence is. And the essence is very simple - universal transport for both storage networks and ordinary LANs. That is, you need to build only 1 high-performance network, which can be used both for work with storages and for user access to 1C.
But the devil, as always, is in the details. For everything to work, you will need special network equipment and converged adapters for each client. Of course, these innovations are quite expensive and it is not advisable to install them in simple workstations. Therefore, the idea has been transformed a bit and is now applied only within the data center.
In general, convergence as an idea appeared much earlier, back in Infiniband. This is a high-speed (up to 300 Gbit) data bus with low latency. Of course, the solution based on Infiniband is much more expensive than the same FC and is used only in truly high-performance clusters.
The key features of Infiniband are support for direct memory access to another device (RDMA) and TCP \ IP, which allows these networks to be used for both SAN and LAN.

Convergent networks are often used in blade systems, as they fit perfectly into the idea of a set of servers with shared resources and a minimum of external connections. But now hyperconvergent systems are already in vogue, where modularity and more flexible scaling are added to the general idea of network virtualization — each node in such solutions is software-defined. As a prime example, we can mention Cisco ASAv and the OpenStack Neutron module.
If in convergent solutions the usual disk arrays can still be used, then in hyperconvergent systems their role is determined programmatically for each specific module. If you do not have any special storage requirements, such as support for specific replication, then I would recommend looking at SDS solutions (Software-Defined Storage).
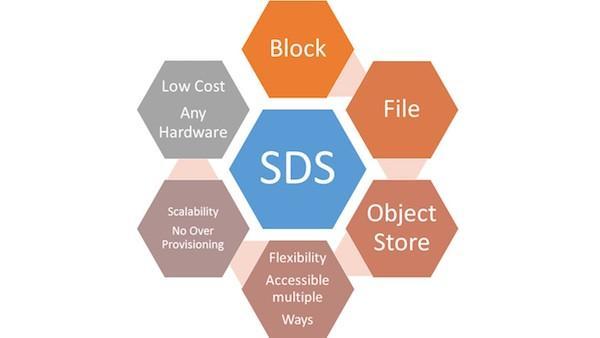
In fact, this is just a server with a set of disks and special software. Vivid examples: vSAN from VMware and Storage Spaces from Microsoft. As a hardware component, you can use something similar with a disk DAS-shelf . The main thing is to have a large disk basket and enough RAM.
SDS often has an interesting technology called Cache Tiering. Two or more disks of different speeds are combined into one disk pool, frequently used data from which is stored on separate SSD disks. Such a hybrid allows for a minimum of money to get the performance level of all-flash arrays, albeit with some reservations.
Total
The time of "pure classics" is gradually disappearing, and the gap between classic storage systems and SDS solutions is closing. For example, judging by some tests , the VMware vSAN storage lags behind ordinary classical arrays of the same level by less than 10%.
Traditionally, here is a short list of resources that once helped me a lot in learning SAN and SDS technologies:
')
Source: https://habr.com/ru/post/314374/
All Articles