Artificial intelligence in the search. How Yandex learned to use neural networks in order to search by meaning, not by words
Today we announced a new search algorithm "Palekh". It includes all the improvements we have been working on lately.
For example, the search is now using neural networks for the first time in order to find documents not by words that are used in the query and in the document itself, but by the meaning of the query and header.

')
For many decades, researchers have been struggling with the problem of semantic search, in which documents are ranked based on the semantic match of the query. And now it becomes a reality.
In this post I will try to tell a little about how we did it and why it is not just another machine learning algorithm, but an important step in the future.
Almost everyone knows that modern search engines work through machine learning. Why is it necessary to talk about the use of neural networks for its tasks? And why only now, because the HYIP around this topic has not subsided for several years? I'll try to talk about the background.
Internet search is a complex system that appeared a long time ago. At first it was just a search for pages, then it turned into a problem solver, and now it becomes a full-fledged assistant. The larger the Internet, and the more people there are, the higher their requirements, the more difficult it becomes to find the search.
At first there was just a word search - an inverted index. Then there were too many pages, they became necessary to rank. Began to take into account various complications - the frequency of words, tf-idf .
Then there were too many pages on any topic, there was an important breakthrough - the links began to be taken into account, PageRank appeared.
The Internet has become commercially important, and there are many crooks trying to trick the simple algorithms that existed at the time. There was a second important breakthrough - search engines began to use their knowledge of user behavior to understand which pages are good and which are not.
Somewhere at this stage, the human mind is no longer enough to figure out how to rank the documents. There was a next transition - search engines began to actively use machine learning.
One of the best machine learning algorithms invented in Yandex - Matrixnet. We can say that the ranking helps the collective mind of users and the " wisdom of the crowd ." Information about websites and people's behavior is transformed into many factors, each of which is used by Matrixnet to build a ranking formula. In fact, the ranking formula is written by a car (it turned out about 300 megabytes).
But "classical" machine learning has a limit: it works only where there is a lot of data. A small example. Millions of users enter the query [VKontakte] to find the same site. In this case, their behavior is such a strong signal that the search does not force people to look at the issue, but prompts the address immediately when entering the request.
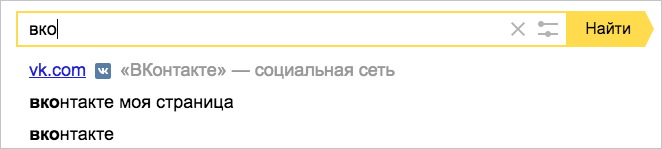
But people are more complicated, and they want more from the search. Now up to 40% of all requests are unique, that is, they are not repeated at least twice during the entire observation period. This means that the search has no data on user behavior in sufficient quantities, and the Matrixnet loses valuable factors. Such queries in Yandex are called the “ long tail ”, because together they make up a significant proportion of the hits to our search.
And then there is a time to talk about the latest breakthrough: a few years ago computers become fast enough, and there is enough data to use neural networks. Technologies based on them are also called machine intelligence or artificial intelligence - because neural networks are built in the image of neurons in our brain and try to emulate the work of some of its parts.
Machine intelligence is much better than the old methods of coping with tasks that people can do: for example, the recognition of speech or images in images. But how does this help search?
As a rule, low-frequency and unique queries are quite difficult to find - to find a good answer on them is much more difficult. How to do it? We have no hints from users (which document is better and which is worse), so in order to solve a search problem, you need to learn to better understand the semantic correspondence between two texts: the query and the document.
Strictly speaking, artificial neural networks are one of the methods of machine learning. Most recently, he was devoted to a lecture in the framework of the Small ShAD . Neural networks show impressive results in the analysis of natural information - sound and images. This has been happening for several years. But why are they still not so actively used in the search?
The simple answer is because talking about the meaning is much more complicated than about the image in the picture, or how to turn sounds into decoded words. Nevertheless, in the search for meanings, artificial intelligence really began to come from the area where he had been king for a long time - searching through pictures.
A few words about how it works in the search for pictures. You take an image and using neural networks transform it into a vector in N-dimensional space. Take a request (which can be either in text form or in the form of another image) and do the same with it. And then compare these vectors. The closer they are to each other, the more the picture matches the request.
Ok, if it works in pictures, why not use the same logic in a web search?
We formulate the problem as follows. We have a user request and a page header at the entrance. We need to understand how they fit together in meaning. For this, it is necessary to present the query text and the header text in the form of such vectors, the scalar multiplication of which would be the larger, the more relevant the document with this header to the query. In other words, we want to train the neural network in such a way that for similar texts it generates similar vectors, and for semantically unrelated queries and vector headers should be different.
The complexity of this task lies in the selection of the correct architecture and method of training the neural network. From scientific publications there are quite a few approaches to solving the problem. Probably the simplest method here is the representation of texts in the form of vectors using the word2vec algorithm (unfortunately, practical experience suggests that for the task in question this is a rather unfortunate solution).
Next - about what we tried, how we achieved success and how we were able to train what we got.
In 2013, researchers at Microsoft Research described their approach, called the Deep Structured Semantic Model .
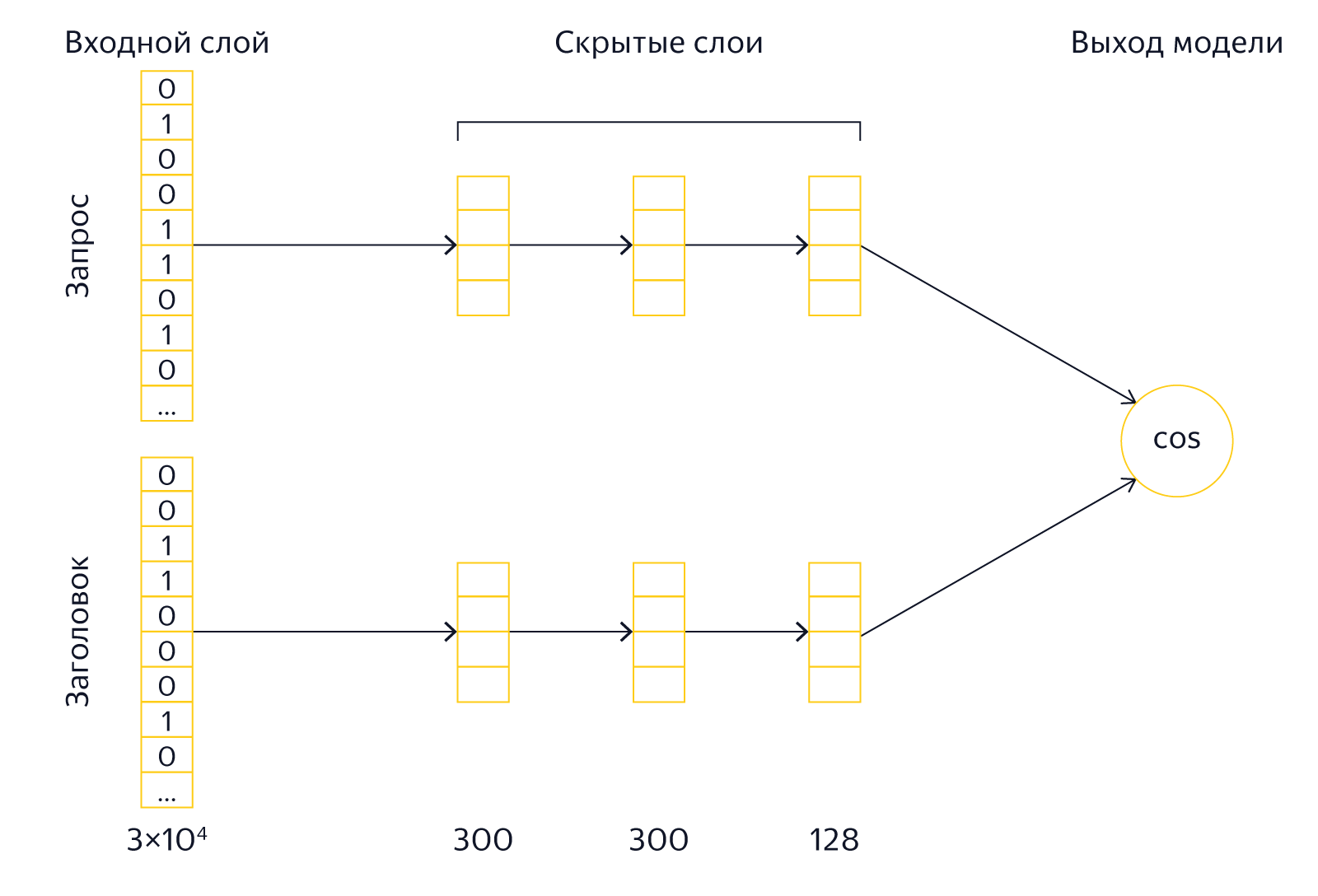
At the input of the model are the texts of the requests and headers. To reduce the size of the model, an operation is performed on them, which the authors call word hashing. Markers of beginning and end are added to the text, after which it is divided into alphabetic trigrams. For example, for the query [Palekh] we get trigrams [pa, ale, leh, ex]. Since the number of different trigrams is limited, we can present the query text as a vector of several tens of thousands of elements (the size of our alphabet is 3 degrees). The elements of the vector corresponding to the request trigrams will be equal to 1, the rest will be 0. In essence, we note in this way the entry of trigrams from the text into the dictionary, consisting of all known trigrams. If you compare these vectors, you can only find out about the presence of identical trigrams in the request and the header, which is not of particular interest. Therefore, now they need to be transformed into other vectors, which will already have the properties of semantic proximity we need.
After the input layer, as it should be in deep architectures, there are several hidden layers for both the request and the header. The last layer is 128 elements in size and serves as a vector that is used for comparison. The output of the model is the result of the scalar multiplication of the last vectors of the header and query (to be perfectly accurate, the cosine of the angle between the vectors is calculated). The model is trained in such a way that for positive teaching examples the output value is large, and for negative ones - small. In other words, comparing the vectors of the last layer, we can calculate the prediction error and modify the model so that the error decreases.
We at Yandex are also actively exploring models based on artificial neural networks, so we became interested in the DSSM model. Further we will tell about our experiments in this area.
The characteristic feature of the algorithms described in the scientific literature is that they do not always work out of the box. The fact is that the “academic” researcher and researcher from the industry are in significantly different conditions. As a starting point (baseline), with which the author of a scientific publication compares his decision, there must be some well-known algorithm - this is how reproducible results are ensured. Researchers take the results of the previously published approach, and show how they can be surpassed. For example, the authors of the original DSSM compare their model on the NDCG metric with the BM25 and LSA algorithms. In the case of an applied researcher who deals with the quality of search in a real search engine, the starting point is not one specific algorithm, but the ranking in general. The goal of the Yandex developer is not to overtake the BM25, but to achieve improvement against the background of all the previously implemented factors and models. Thus, the baseline for a researcher at Yandex is extremely high, and many algorithms that have scientific novelty and show good results with the “academic” approach are useless in practice because they do not allow for a real improvement in the quality of search.
In the case of DSSM, we encountered the same problem. As is often the case, in “combat” conditions, the exact implementation of the model from the article showed rather modest results. It took a number of significant “file improvements” before we could get results that were interesting from a practical point of view. Here we will tell about the main modifications of the original model, which allowed us to make it more powerful.
In the original DSSM model, the input layer is a set of letter trigrams. Its size is 30,000. The trigram-based approach has several advantages. First, they are relatively small, so working with them does not require large resources. Secondly, their use simplifies the identification of typos and word errors. However, our experiments showed that the presentation of texts as a “bag” of trigrams noticeably reduces the expressive power of the network. Therefore, we have drastically increased the size of the input layer, including about 2 million words and phrases in addition to the letter trigrams. Thus, we present the texts of the request and the title in the form of a joint "bag" of words, verbal digrams and letter trigrams.
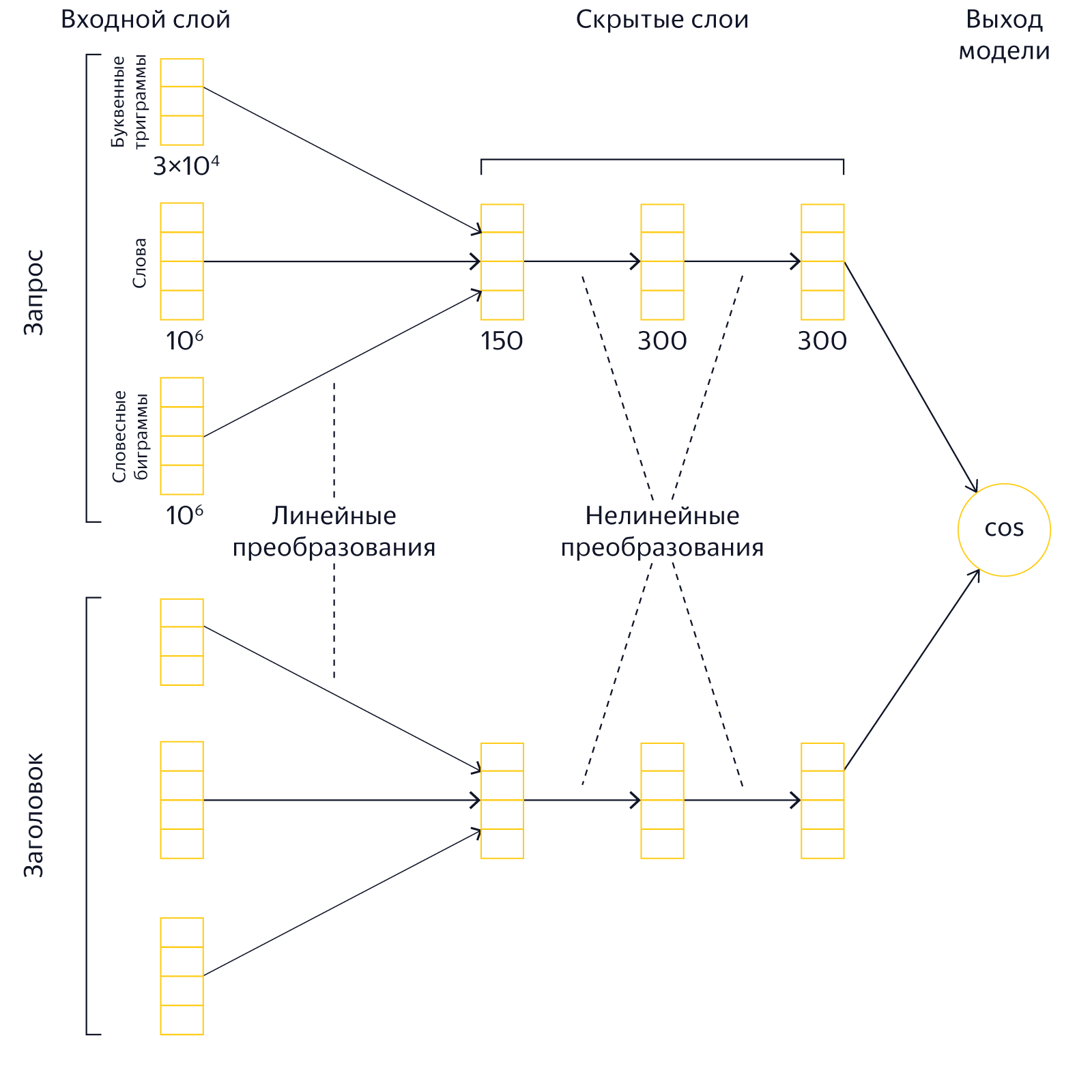
The use of a large input layer leads to an increase in the size of the model, the duration of training and requires significantly more computational resources.
Learning the original DSSM consists of demonstrating a network of a large number of positive and negative examples. These examples are taken from search results (apparently, the Bing search engine was used for this). Positive examples are the headers of clicked issuance documents, negative ones are the titles of documents on which there was no click. There are certain drawbacks to this approach. The fact is that the absence of a clique does not always indicate that the document is irrelevant. The converse is also true - the presence of a click does not guarantee the relevance of the document. In essence, by learning the way described in the original article, we strive to predict the attractiveness of the headings, provided that they are present in the issue. This, of course, is also not bad, but it is rather indirectly related to our main goal - to learn to understand semantic proximity.
During our experiments, we found that the result can be significantly improved by using a different strategy for choosing negative examples. To achieve our goal, good negative examples are such documents that are irrelevant to the request, but help the neural network to better understand the meanings of words. Where do you get them from?
First, as a negative example, just take the title of a random document. For example, for the request [Palekh painting], the random title may be the “Rules of the Road in Russia 2016”. Of course, it is impossible to completely exclude the fact that a document randomly chosen from billions will be relevant to the request, but it is not so likely that it can be neglected. Thus, we can very easily get a large number of negative examples. It would seem that now we can teach our network exactly what we want - to distinguish good documents that interest users from documents that have nothing to do with the request. Unfortunately, the model trained in such examples was rather weak. The neural network is a smart thing, and it will always find a way to simplify your work. In this case, she just started to look for the same words in the queries and headers: there is - a good pair, no - a bad one. But we ourselves are able to do this. For us, it is important that the network learns to distinguish non-obvious patterns.
The next experiment was to add negative words to the headers of the examples from the query. For example, for the request [Palekh painting] a random title looked like [Traffic regulations 2016 RF painting list]. The neural network had to be a little more complicated, but, nevertheless, it quickly learned how well to distinguish natural pairs from hand-made ones. It became clear that such methods we will not achieve success.
Many obvious solutions become apparent only after their discovery. It happened this time too: after some time it was discovered that the best way to generate negative examples is to make the network “fight” against itself, learn from its own mistakes. Among the hundreds of random headers, we chose the one that the current neural network considered the best. But, since this heading is still random, with high probability it does not match the request. And we began to use such headings as negative examples. In other words, you can show the networks the best of random titles, train them, find new best random titles, show networks again, and so on. Repeating this procedure over and over again, we have seen how the quality of the model is noticeably improved, and more and more often the best of random pairs have become similar to real positive examples. The problem was solved.
Such a training scheme in the scientific literature is usually called hard negative mining. Also, it should be noted that solutions similar in idea were widely used in the scientific community to generate realistic-looking images, a similar class of models was called Generative Adversarial Networks.
Researchers from Microsoft Research used document clicks as positive examples. However, as already mentioned, this is a rather unreliable signal of the semantic conformity of the header to the request. In the end, our task is not to raise the most visited sites in search results, but to find really useful information. Therefore, we tried to use other characteristics of user behavior as a learning goal. For example, one of the models predicted whether the user will remain on the site or leave. Another is how long it lasts on the site. As it turned out, you can significantly improve the results if you optimize such a target metric, which indicates that the user found what he needed.
Ok, what does this give us in practice? Let's compare the behavior of our neural model and a simple text factor based on the correspondence between the words of the query and the text - BM25. He came to us from those times when ranking was simple, and now it is convenient to use it as a baseline.
As an example, take the query [The Book of Kells] and see what value factors take on different headings. For control, let's add an obviously irrelevant result to the list of headers.
All factors in Yandex are normalized to the interval [0; 1]. It is expected that BM25 has high values for headers that contain the words of the query. And it is quite predictable that this factor gets a zero value on the headers that do not have common words with the query. Now pay attention to how the neural model behaves. She is equally well aware of the connection request as with the Russian title of the relevant page from Wikipedia, and with the title of the article in English! In addition, it seems that the model “saw” the connection of the request with the title, in which the Kells book is not mentioned, but there is a phrase close in meaning (“Irish gospels”). The value of the model for an irrelevant header is significantly lower.
Now let's see how our factors will behave if we reformulate the query without changing its meaning: [the gospel of Kells].
For BM25, the query reformulation turned into a real catastrophe - the factor became zero on the relevant headings. And our model demonstrates excellent resistance to reformulation: relevant headings still have a high factor value, and an irrelevant heading is low. It seems that this is exactly the behavior we expected from the piece, which claims to be able to “understand” the semantics of the text.
Another example. Request [a story in which a butterfly was crushed].
As you can see, the neural model was able to appreciate the title with the correct answer, despite the complete absence of common words with the query. Moreover, it is clearly seen that the headers that do not respond to the request, but are still associated with it in meaning, receive a sufficiently high value of the factor. As if our model “read” the Bradbury story and “knows” that this is exactly what it is about in the request!
We are at the very beginning of a big and very interesting way. Apparently, neural networks have great potential for improving rankings. The main directions that need active development are already clear.
For example, it is obvious that the title contains incomplete information about the document, and it would be good to learn how to build a model using the full text (as it turned out, this is not a completely trivial task). Further, it is possible to imagine models that have a significantly more complex architecture than DSSM - there is reason to assume that in this way we will be able to better process some constructions of natural languages. We see our long-term goal in creating models that can “understand” the semantic correspondence of queries and documents at a level comparable to that of a person. On the way to this goal there will be many difficulties - the more interesting it will be to go through it. We promise to talk about our work in this area. Follow the following publications.
For example, the search is now using neural networks for the first time in order to find documents not by words that are used in the query and in the document itself, but by the meaning of the query and header.
')
For many decades, researchers have been struggling with the problem of semantic search, in which documents are ranked based on the semantic match of the query. And now it becomes a reality.
In this post I will try to tell a little about how we did it and why it is not just another machine learning algorithm, but an important step in the future.
Artificial intelligence or machine learning?
Almost everyone knows that modern search engines work through machine learning. Why is it necessary to talk about the use of neural networks for its tasks? And why only now, because the HYIP around this topic has not subsided for several years? I'll try to talk about the background.
Internet search is a complex system that appeared a long time ago. At first it was just a search for pages, then it turned into a problem solver, and now it becomes a full-fledged assistant. The larger the Internet, and the more people there are, the higher their requirements, the more difficult it becomes to find the search.
Era of the naive search
At first there was just a word search - an inverted index. Then there were too many pages, they became necessary to rank. Began to take into account various complications - the frequency of words, tf-idf .
Age of references
Then there were too many pages on any topic, there was an important breakthrough - the links began to be taken into account, PageRank appeared.
The era of machine learning
The Internet has become commercially important, and there are many crooks trying to trick the simple algorithms that existed at the time. There was a second important breakthrough - search engines began to use their knowledge of user behavior to understand which pages are good and which are not.
Somewhere at this stage, the human mind is no longer enough to figure out how to rank the documents. There was a next transition - search engines began to actively use machine learning.
One of the best machine learning algorithms invented in Yandex - Matrixnet. We can say that the ranking helps the collective mind of users and the " wisdom of the crowd ." Information about websites and people's behavior is transformed into many factors, each of which is used by Matrixnet to build a ranking formula. In fact, the ranking formula is written by a car (it turned out about 300 megabytes).
But "classical" machine learning has a limit: it works only where there is a lot of data. A small example. Millions of users enter the query [VKontakte] to find the same site. In this case, their behavior is such a strong signal that the search does not force people to look at the issue, but prompts the address immediately when entering the request.
But people are more complicated, and they want more from the search. Now up to 40% of all requests are unique, that is, they are not repeated at least twice during the entire observation period. This means that the search has no data on user behavior in sufficient quantities, and the Matrixnet loses valuable factors. Such queries in Yandex are called the “ long tail ”, because together they make up a significant proportion of the hits to our search.
The Age of Artificial Intelligence
And then there is a time to talk about the latest breakthrough: a few years ago computers become fast enough, and there is enough data to use neural networks. Technologies based on them are also called machine intelligence or artificial intelligence - because neural networks are built in the image of neurons in our brain and try to emulate the work of some of its parts.
Machine intelligence is much better than the old methods of coping with tasks that people can do: for example, the recognition of speech or images in images. But how does this help search?
As a rule, low-frequency and unique queries are quite difficult to find - to find a good answer on them is much more difficult. How to do it? We have no hints from users (which document is better and which is worse), so in order to solve a search problem, you need to learn to better understand the semantic correspondence between two texts: the query and the document.
Easy to say
Strictly speaking, artificial neural networks are one of the methods of machine learning. Most recently, he was devoted to a lecture in the framework of the Small ShAD . Neural networks show impressive results in the analysis of natural information - sound and images. This has been happening for several years. But why are they still not so actively used in the search?
The simple answer is because talking about the meaning is much more complicated than about the image in the picture, or how to turn sounds into decoded words. Nevertheless, in the search for meanings, artificial intelligence really began to come from the area where he had been king for a long time - searching through pictures.
A few words about how it works in the search for pictures. You take an image and using neural networks transform it into a vector in N-dimensional space. Take a request (which can be either in text form or in the form of another image) and do the same with it. And then compare these vectors. The closer they are to each other, the more the picture matches the request.
Ok, if it works in pictures, why not use the same logic in a web search?
Technology devil
We formulate the problem as follows. We have a user request and a page header at the entrance. We need to understand how they fit together in meaning. For this, it is necessary to present the query text and the header text in the form of such vectors, the scalar multiplication of which would be the larger, the more relevant the document with this header to the query. In other words, we want to train the neural network in such a way that for similar texts it generates similar vectors, and for semantically unrelated queries and vector headers should be different.
The complexity of this task lies in the selection of the correct architecture and method of training the neural network. From scientific publications there are quite a few approaches to solving the problem. Probably the simplest method here is the representation of texts in the form of vectors using the word2vec algorithm (unfortunately, practical experience suggests that for the task in question this is a rather unfortunate solution).
Next - about what we tried, how we achieved success and how we were able to train what we got.
DSSM
In 2013, researchers at Microsoft Research described their approach, called the Deep Structured Semantic Model .
At the input of the model are the texts of the requests and headers. To reduce the size of the model, an operation is performed on them, which the authors call word hashing. Markers of beginning and end are added to the text, after which it is divided into alphabetic trigrams. For example, for the query [Palekh] we get trigrams [pa, ale, leh, ex]. Since the number of different trigrams is limited, we can present the query text as a vector of several tens of thousands of elements (the size of our alphabet is 3 degrees). The elements of the vector corresponding to the request trigrams will be equal to 1, the rest will be 0. In essence, we note in this way the entry of trigrams from the text into the dictionary, consisting of all known trigrams. If you compare these vectors, you can only find out about the presence of identical trigrams in the request and the header, which is not of particular interest. Therefore, now they need to be transformed into other vectors, which will already have the properties of semantic proximity we need.
After the input layer, as it should be in deep architectures, there are several hidden layers for both the request and the header. The last layer is 128 elements in size and serves as a vector that is used for comparison. The output of the model is the result of the scalar multiplication of the last vectors of the header and query (to be perfectly accurate, the cosine of the angle between the vectors is calculated). The model is trained in such a way that for positive teaching examples the output value is large, and for negative ones - small. In other words, comparing the vectors of the last layer, we can calculate the prediction error and modify the model so that the error decreases.
We at Yandex are also actively exploring models based on artificial neural networks, so we became interested in the DSSM model. Further we will tell about our experiments in this area.
Theory and practice
The characteristic feature of the algorithms described in the scientific literature is that they do not always work out of the box. The fact is that the “academic” researcher and researcher from the industry are in significantly different conditions. As a starting point (baseline), with which the author of a scientific publication compares his decision, there must be some well-known algorithm - this is how reproducible results are ensured. Researchers take the results of the previously published approach, and show how they can be surpassed. For example, the authors of the original DSSM compare their model on the NDCG metric with the BM25 and LSA algorithms. In the case of an applied researcher who deals with the quality of search in a real search engine, the starting point is not one specific algorithm, but the ranking in general. The goal of the Yandex developer is not to overtake the BM25, but to achieve improvement against the background of all the previously implemented factors and models. Thus, the baseline for a researcher at Yandex is extremely high, and many algorithms that have scientific novelty and show good results with the “academic” approach are useless in practice because they do not allow for a real improvement in the quality of search.
In the case of DSSM, we encountered the same problem. As is often the case, in “combat” conditions, the exact implementation of the model from the article showed rather modest results. It took a number of significant “file improvements” before we could get results that were interesting from a practical point of view. Here we will tell about the main modifications of the original model, which allowed us to make it more powerful.
Large entrance layer
In the original DSSM model, the input layer is a set of letter trigrams. Its size is 30,000. The trigram-based approach has several advantages. First, they are relatively small, so working with them does not require large resources. Secondly, their use simplifies the identification of typos and word errors. However, our experiments showed that the presentation of texts as a “bag” of trigrams noticeably reduces the expressive power of the network. Therefore, we have drastically increased the size of the input layer, including about 2 million words and phrases in addition to the letter trigrams. Thus, we present the texts of the request and the title in the form of a joint "bag" of words, verbal digrams and letter trigrams.
The use of a large input layer leads to an increase in the size of the model, the duration of training and requires significantly more computational resources.
It's hard to learn: how did the neural network fight with itself and learn from its mistakes
Learning the original DSSM consists of demonstrating a network of a large number of positive and negative examples. These examples are taken from search results (apparently, the Bing search engine was used for this). Positive examples are the headers of clicked issuance documents, negative ones are the titles of documents on which there was no click. There are certain drawbacks to this approach. The fact is that the absence of a clique does not always indicate that the document is irrelevant. The converse is also true - the presence of a click does not guarantee the relevance of the document. In essence, by learning the way described in the original article, we strive to predict the attractiveness of the headings, provided that they are present in the issue. This, of course, is also not bad, but it is rather indirectly related to our main goal - to learn to understand semantic proximity.
During our experiments, we found that the result can be significantly improved by using a different strategy for choosing negative examples. To achieve our goal, good negative examples are such documents that are irrelevant to the request, but help the neural network to better understand the meanings of words. Where do you get them from?
First try
First, as a negative example, just take the title of a random document. For example, for the request [Palekh painting], the random title may be the “Rules of the Road in Russia 2016”. Of course, it is impossible to completely exclude the fact that a document randomly chosen from billions will be relevant to the request, but it is not so likely that it can be neglected. Thus, we can very easily get a large number of negative examples. It would seem that now we can teach our network exactly what we want - to distinguish good documents that interest users from documents that have nothing to do with the request. Unfortunately, the model trained in such examples was rather weak. The neural network is a smart thing, and it will always find a way to simplify your work. In this case, she just started to look for the same words in the queries and headers: there is - a good pair, no - a bad one. But we ourselves are able to do this. For us, it is important that the network learns to distinguish non-obvious patterns.
One more attempt
The next experiment was to add negative words to the headers of the examples from the query. For example, for the request [Palekh painting] a random title looked like [Traffic regulations 2016 RF painting list]. The neural network had to be a little more complicated, but, nevertheless, it quickly learned how well to distinguish natural pairs from hand-made ones. It became clear that such methods we will not achieve success.
Success
Many obvious solutions become apparent only after their discovery. It happened this time too: after some time it was discovered that the best way to generate negative examples is to make the network “fight” against itself, learn from its own mistakes. Among the hundreds of random headers, we chose the one that the current neural network considered the best. But, since this heading is still random, with high probability it does not match the request. And we began to use such headings as negative examples. In other words, you can show the networks the best of random titles, train them, find new best random titles, show networks again, and so on. Repeating this procedure over and over again, we have seen how the quality of the model is noticeably improved, and more and more often the best of random pairs have become similar to real positive examples. The problem was solved.
Such a training scheme in the scientific literature is usually called hard negative mining. Also, it should be noted that solutions similar in idea were widely used in the scientific community to generate realistic-looking images, a similar class of models was called Generative Adversarial Networks.
Different goals
Researchers from Microsoft Research used document clicks as positive examples. However, as already mentioned, this is a rather unreliable signal of the semantic conformity of the header to the request. In the end, our task is not to raise the most visited sites in search results, but to find really useful information. Therefore, we tried to use other characteristics of user behavior as a learning goal. For example, one of the models predicted whether the user will remain on the site or leave. Another is how long it lasts on the site. As it turned out, you can significantly improve the results if you optimize such a target metric, which indicates that the user found what he needed.
Profit
Ok, what does this give us in practice? Let's compare the behavior of our neural model and a simple text factor based on the correspondence between the words of the query and the text - BM25. He came to us from those times when ranking was simple, and now it is convenient to use it as a baseline.
As an example, take the query [The Book of Kells] and see what value factors take on different headings. For control, let's add an obviously irrelevant result to the list of headers.
| Page title | BM25 | Neural model |
|---|---|---|
| kells book wikipedia | 0.91 | 0.92 |
| scientists are researching kell book around the world | 0.88 | 0.85 |
| book of kells wikipedia | 0 | 0.81 |
| Irish Illustrated Gospels vii viii cc | 0 | 0.58 |
| ikea hypermarkets for home and office ikea | 0 | 0.09 |
All factors in Yandex are normalized to the interval [0; 1]. It is expected that BM25 has high values for headers that contain the words of the query. And it is quite predictable that this factor gets a zero value on the headers that do not have common words with the query. Now pay attention to how the neural model behaves. She is equally well aware of the connection request as with the Russian title of the relevant page from Wikipedia, and with the title of the article in English! In addition, it seems that the model “saw” the connection of the request with the title, in which the Kells book is not mentioned, but there is a phrase close in meaning (“Irish gospels”). The value of the model for an irrelevant header is significantly lower.
Now let's see how our factors will behave if we reformulate the query without changing its meaning: [the gospel of Kells].
| Page title | BM25 | Neural model |
|---|---|---|
| kells book wikipedia | 0 | 0.85 |
| scientists are researching kell book around the world | 0 | 0.78 |
| book of kells wikipedia | 0 | 0.71 |
| Irish Illustrated Gospels vii viii cc | 0.33 | 0.84 |
| ikea hypermarkets for home and office ikea | 0 | 0.10 |
For BM25, the query reformulation turned into a real catastrophe - the factor became zero on the relevant headings. And our model demonstrates excellent resistance to reformulation: relevant headings still have a high factor value, and an irrelevant heading is low. It seems that this is exactly the behavior we expected from the piece, which claims to be able to “understand” the semantics of the text.
Another example. Request [a story in which a butterfly was crushed].
| Page title | BM25 | Neural model |
|---|---|---|
| a movie in which a butterfly was crushed | 0.79 | 0.82 |
| and thunder struck wikipedia | 0 | 0.43 |
| bradbury ray wikipedia | 0 | 0.27 |
| time machine romance wikipedia | 0 | 0.24 |
| homemade raspberry jam recipe blanks for the winter | 0 | 0.06 |
As you can see, the neural model was able to appreciate the title with the correct answer, despite the complete absence of common words with the query. Moreover, it is clearly seen that the headers that do not respond to the request, but are still associated with it in meaning, receive a sufficiently high value of the factor. As if our model “read” the Bradbury story and “knows” that this is exactly what it is about in the request!
What's next?
We are at the very beginning of a big and very interesting way. Apparently, neural networks have great potential for improving rankings. The main directions that need active development are already clear.
For example, it is obvious that the title contains incomplete information about the document, and it would be good to learn how to build a model using the full text (as it turned out, this is not a completely trivial task). Further, it is possible to imagine models that have a significantly more complex architecture than DSSM - there is reason to assume that in this way we will be able to better process some constructions of natural languages. We see our long-term goal in creating models that can “understand” the semantic correspondence of queries and documents at a level comparable to that of a person. On the way to this goal there will be many difficulties - the more interesting it will be to go through it. We promise to talk about our work in this area. Follow the following publications.
Source: https://habr.com/ru/post/314222/
All Articles