Song of the Mighty Deploy: nonstop transparent web service deployment

Prologue
The time came when we, the team of Elba, wanted to share with the world the details of some magical and mysterious details of our product. We decided to start with one of the most difficult projects, which is a matter of special pride and light worship. It is covered with a touch of mystery and shrouded in a halo of dark magic. Legends about him are passed from mouth to mouth. Only a small part of the knowledge is documented in a wiki or yutrek, a large one is hidden in the source code of the version control system. The wise old men who can decipher this secret code are less and less in the project. It's time to write down all the magic spells in the detailed manuscript. It will focus on the system of deployment of the Elbe - the mighty Deploy .
Elba is a web service for entrepreneurs that helps to run a business. And the work of the mighty Deploy is to renew the Elbe. When the new version of the service is ready, Depla should show it to the world, i.e. users. This means that all parts of the system must be updated and running, and all data converted and prepared. Our Depla copes with its work well - the Elbe updates are completely unnoticeable to users, without interrupting their work. This allows you to post new releases as often as needed - as they become available. How we have achieved this, how the web service is updated non-stop and transparent for users, and will be described below.
Chapter one. Origin
In ancient times, Elba consisted of a small web application on ASP.Net Web Forms and a database on MS SQL Server. The application allowed entrepreneurs with the help of a small wizard to prepare and submit the SST declaration to the tax office. Since that time, many epochs have changed - now the Elbe allows you to do much more. What exactly it can do and how it helps entrepreneurs, our marketing and an exciting reading of the promo site will tell.
')
We are more interested in the technical side. When Elba was small, the delivery process was simple and naive. The application lived in a datacenter on two hosts hidden behind the balancer. To update both applications, the programmer went over the RDP to the production server and copied pre-compiled code into folders on both hosts. Good IIS immediately picked up the changes and restarted the system. To update the data in the database, you had to manually run the scripts on the SQL server.
Over time, the code base grew and gained momentum. Many fronts have appeared, services that live on their own hosts, robots replacing humans and dreaming to take over the world once appeared separately, integration with third-party products and services, and much more different and interesting have been added. First, for releases was written a pack of batch file, which simplified manual labor when copying. Batniki laid out a new distribution kit on all hosts and started. But soon the code became so much that the time it was copied to all hosts increased indecently. It became difficult to manage batniki: maintain an up-to-date list of services and topology. In addition, with the increase in the number of users, the amount of data that needed to be updated before the new release also increased. The time has come for automation.
Those ancient times were very harsh. No one knew the ready tools, could not google and still wouldn’t use someone else’s. Programmers love to write code. We decided to write it yourself. And they wrote.
Deploy’s first versions acted like an ax. The man launched the console, which first collected the entire product in the release form. This included compiling the code and statics of services / robots / fronts and Deploy itself. Then they prepared production settings for all this stuff: the topology of the site, addresses, turnout, passwords, flags, toggle switches and magic constants. The prepared distribution was transferred to the data center to a specially trained remote service, which only knew how to run that magic Depla after the end of the transfer.
First of all, a stub appeared on the fronts for the outside world “Technical work is going on”. Under her cover, Depla was killing everything he could reach. Extinguished the whole area. He killed robots, services, fronts, all working processes, sparing neither parental nor affiliated, leaving behind him scorched earth. Elba no longer worked. And on these ruins Depla began to build a new, better world. Slowly I scattered the distribution in accordance with the given topology, changed the settings, executed the scripts to update the data in the database. Then slowly started the whole farm back. After the start of the service itself, the stub was removed, and happy users could finally get into the updated system.
Obviously, not all users and not always were happy. In the most successful case, the downtime took 10-20 minutes late in the evening ... And it was good when everything went well. In the unfortunate position of the stars, Depla unexpectedly died in the most inappropriate place, without completing the work, and the team remained with the ground broken into the trash. Somewhere something worked, somewhere not, but something did not work as intended. And in the coming hours of another sleepless night, we had to urgently put everything in order. Technical support barely restrained the anger of users, soothed the most upset, otpaivaya their valerian directly on the telephone hotline.
At that time, the evolution of development in Elbe reached the stage when it would be desirable to release more, more often and better. They no longer wanted to build a queue of releases, especially to strain users and technical support.
Formed new requirements for Deploy :
- minimum Elbe downtime, ideally its absence;
- transparent data update;
- the system should continue to work in case of an unsuccessful release;
- full automation or a minimum of manual actions to eliminate the human factor;
- simple code for further improvement and development.
Understanding the requirements quickly led to the realization that without support in the main application the idea was doomed to failure. It will not be possible to make a stand-alone deployment system. It is necessary in the system itself, in the most basic code, to support release scripts, to add infrastructure, it is necessary to establish requirements for code, data, topology.
Most of the work on the deployment of the new version of the Elbe can be performed in parallel with the working one. Depla will receive a compiled distribution kit and a topology pointing to the host and port where the specific service lives, after which it scatters and launches all the necessary services. At the right moment, it remains only to pull the switch and switch the entire area.
On the shore, everything sounded like magic, beyond the control of mortals.
The moment came when programmers once again had to roll up their sleeves and show the world a new, “better” Depla , with greater magic power, free from the shortcomings and weaknesses of their predecessors.
Long or short, with the help of the great gusev_p and your humble servant, from dust and ash, he was born - the mighty unstoppable Depla .
Chapter two Environment
Before describing the deployment process and purely technical details, it’s worth mentioning what we dealt with:
- Elba - a web service, a product for a Windows stack, the code is written in C #;
- main application (front) - ASP.Net website for IIS. Partly Web Forms, partly MVC;
- a dozen constantly raised standalone services with http-interface. Services replicated for balancing and fault tolerance;
- a dozen robots launched by the scheduler on a schedule;
- main storage - MS SQL Server DB;
- MongoDB for denormalized data and aggregations;
- ElasticSearch for full-text search;
- RabbitMQ for messaging.
The SQL base is used as append-only. In the application code, UPDATE and DELETE are not used, and the modification and deletion of entities occurs through the addition of a new revision with modified fields or a deletion flag. Revision number - incremental counter, pass-through for one type of entities. With the help of the ORM, inside the application code, only the last unreleased revisions of each specific entity are selected from the repository. As a result of this scheme, versioning and the history of changes in all data are obtained, which gives +86 to magic, which will be described below.
Chapter Three School of Magic
We proceed to the description of the work Deploy . To begin with, the entire process of deploying a release was broken into about 40 steps. Each step does a small part of the big work and is responsible only for it. The next step starts only after successful completion of the previous one. Most steps can be carried out in parallel with the working Elbe. In case of failure, the step, if possible, returns the system to its original state.
As before, a small, specially trained remote service receives a new Elba distribution and launches Depla . He, without losing time, begins to take his first steps.
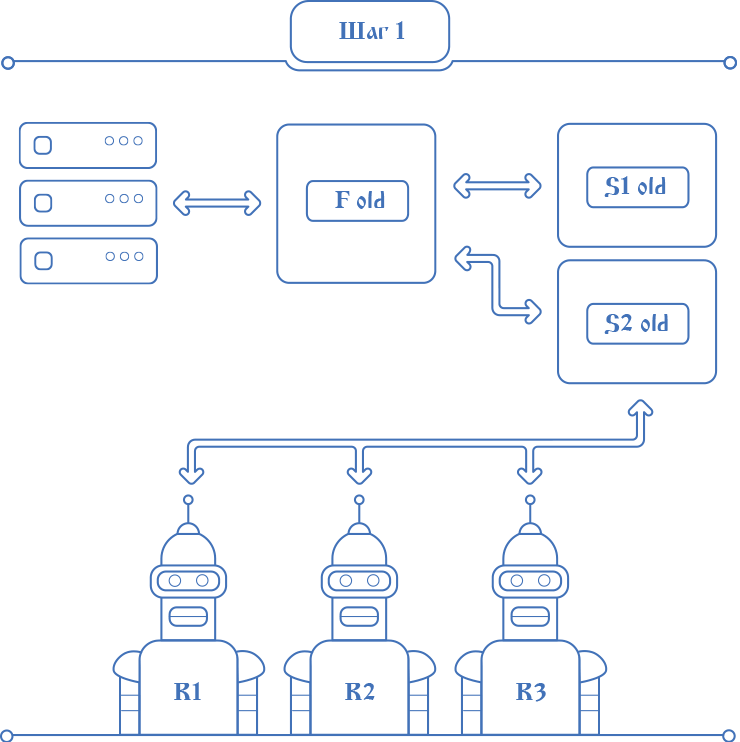 The initial steps are not so interesting. The current configuration is checked, the file system is prepared, the new service code is copied to the new folders on the respective hosts, tasks are prepared in the scheduler. The tasks of the same type are parallelized across all hosts.
The initial steps are not so interesting. The current configuration is checked, the file system is prepared, the new service code is copied to the new folders on the respective hosts, tasks are prepared in the scheduler. The tasks of the same type are parallelized across all hosts.Next Deplo need to do data migration. At this moment he enters the territory of magic.
In the new release, the programmers did a good job, wrote a lot of new code, created new entities, and notably refactored existing ones. In some of them, defaults changed, new properties appeared, or old ones were deleted. Now, instead of the old entity can be used a set of several new, related to each other, or vice versa. Where there was a one-to-one relationship, many-to-many could appear, etc. The problem is that the new code does not know how to work with old data. Before launching a new code, existing data must be prepared - migrated. When preparing a new release, programmers write relevant scripts and utilities that change the data structure in the repository, modify and transform the current entity.
But the old code also does not know how to work with new data. And if forward data is usually easy to migrate, then reverse migration is difficult, if not impossible. If the new code writes the entities in a new way, it will not be possible to convert them to the old ones. Roll back data migration is not worth it. Therefore, let the old code work with the old data, and the new with the new - as long as they do not overlap in time and space.
Thus was born the first postulate of Deploy : data migration should not break a working code. You can create new columns and tables; you cannot modify current data. If you need to convert them, you should make new columns and tables and put the result there. Fortunately, ORM in the application code abstracts well from the repository and allows you to ignore such changes.
Spell # 1
Very often, migration is a long and not always time-determined process. It may be necessary to transfer millions of rows of tables and gigabytes of data. But users do not want to wait, a simple service is bad. And here Depla used the first magic spell - versioned structure of the repository. The whole migration was divided into two stages.
The first stage - almost unlimited in time - updates the data scheme and is engaged in the migration of the main volume of entities. It adds columns and tables and remembers the current latest revisions of all types of entities. After it launches scripts and data transformation utilities that will prepare entities for working with new code. The main thing is that the first stage does not interfere with the operation of the existing code, and the modified data appear in new fields that are invisible from the old code.
Depla performs the second stage as a separate step just before switching versions. It is the domination of new revisions of entities that appeared after the first stage. To do this, all the same scripts and transformation utilities are executed, but with the indication of previously memorized revisions. This ensures that only accumulated changes are processed.
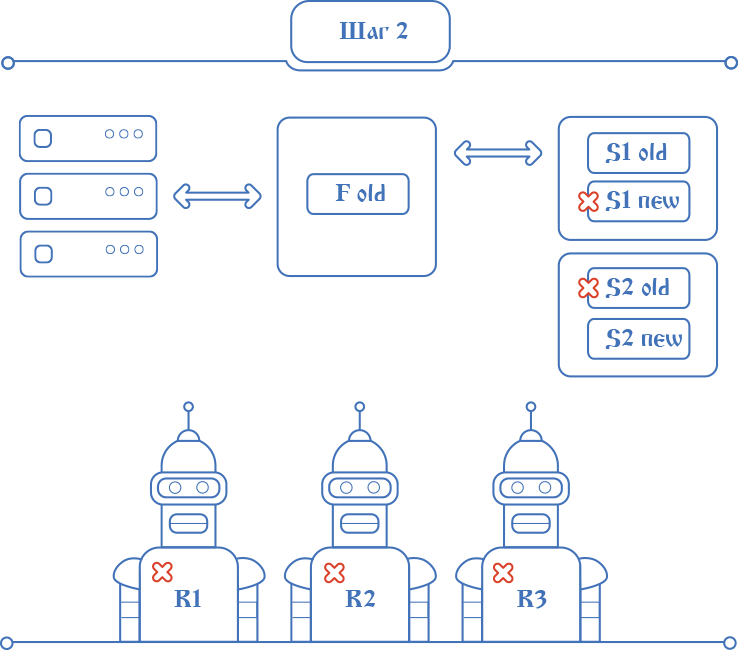 After the initial migration, Depla stops all robots - their work at the time of release can be sacrificed. Then services. But services are needed for the system, you can not stop them all. We did not want to change the topology and settings with each release. Almost always, the topology of the new release coincides with the topology of the already deployed and working Elbe. For most releases, this requirement does not interfere, because the topology rarely changes, and if necessary, some manual manipulations can easily be modified.
After the initial migration, Depla stops all robots - their work at the time of release can be sacrificed. Then services. But services are needed for the system, you can not stop them all. We did not want to change the topology and settings with each release. Almost always, the topology of the new release coincides with the topology of the already deployed and working Elbe. For most releases, this requirement does not interfere, because the topology rarely changes, and if necessary, some manual manipulations can easily be modified.This is how Deploya’s second postulate appeared - to launch a service with the new code instead of the old one on the same host. For simplicity, we decided to stop half of the replicas of the running services for the duration of the deployment and launch new ones instead. While the old service was working, the updated version was already copied nearby. The current service stops with Deploy , the new one starts. In this case, the entire system continues to operate on a temporarily reduced number of replicas.
Spell # 2
It was necessary to modify the basic network infrastructure of the system. Each service runs on a specific set of settings, in which the release version now appears, increasing with each new deployment. Correctly specify the version in the service settings and maintain the log - Deploy task. All services, including the front, are able to communicate only within the same version. If one service makes a request to another older or newer, a specific response is returned instead of processing the request. Then this service is blacklisted, and the request goes to another replica.
The fog thickens. Deploy came close to the territory of the dark magic. It was the turn to update the fronts. With them, for obvious reasons, major difficulties arose. First, because of the long start of the new application. It is unclear what IIS does, but raising all the assemblies into memory, caching, updating the metabase, and so on. eats up a decent amount of seconds. Secondly, due to http requests from users in a running application. We still do not want to tear them off, return a stub, an error or a timeout. All current requests should be processed, as well as all new ones.
Depla expands new fronts on IIS on all hosts where old ones are running. But on a separate port. The unheated application tupit at startup, so it has learned to warm itself up. To do this, at startup, user visits to the most popular pages are simulated, which allows IIS to make all the necessary actions for caching. Depla patiently waits until the new auxiliary fronts warm up. As a result, the old application continues to work on every front, constantly processing incoming user requests, and the new application has already started working, which is still waiting in the wings.
Release switching will start very soon. It is required to complete the data preparation for the new code and convert the existing revisions of all entities. Nobody and nothing should interfere with this process. No more recent entries should appear. To fix this postulate, it was decided to install a kind of “block” for all incoming user requests. This is a very strong spell, consisting of many different effects.
All fronts and operating services receive from Deploy a signal to start switching releases, which leads to noticeable metamorphoses in their work. From the moment the signal is received, the same “block” is installed inside the application code. All new http requests on the fronts pause, waiting for its removal. The “block” prohibits the addition of new records to the database in order to provide freedom for the final migration. If the current request that gets into the application before installing the “block” tries to write, then an exception flies out of the furthest depths of the infrastructure code, the request is repeated at the front, and it rests on the same “block” as all new ones.
Deploy performs the second, final, data migration phase. From now on, all available data is ready for processing by new code. After the migration is completed, a signal is given to the fronts to remove the “block”. All requests that are nervously crowded at the entrance to the “old” application are proxied to the already warmed “auxiliary” new, and its response is proxied back to the client. Thus, user requests are already processed by the new code in the new "auxiliary" application, and the old application is only involved in proxying. Old code does not work with new data. And no user request has been lost.
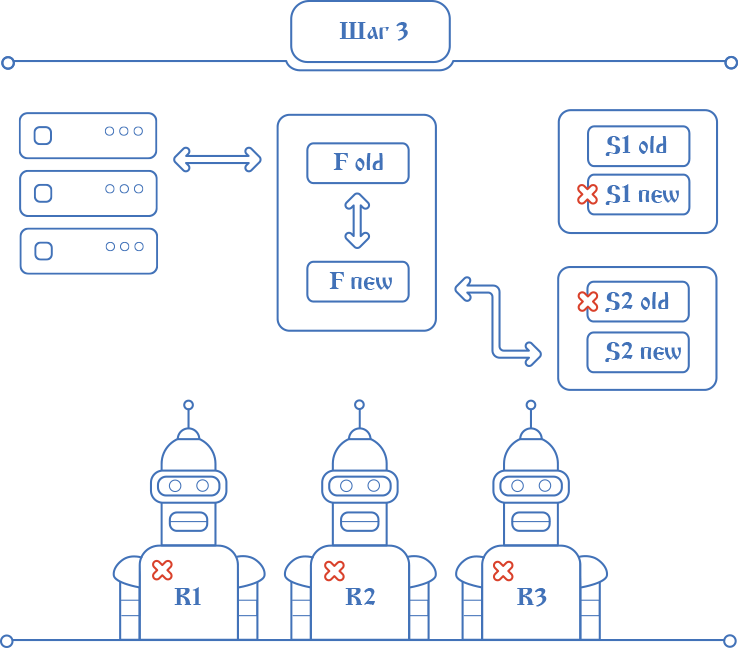 The whole process from installation to removal of the "block" takes just a couple of seconds. The whole idea serves to determine the only moment when it will be possible to start processing requests in a new application, and by this moment absolutely all existing data has been migrated. At each moment of time, new entries get into the database either from the old code or from the new one, but never at the same time. This eliminates the incompatibility of the code data, simplifies and accelerates the switching of releases.
The whole process from installation to removal of the "block" takes just a couple of seconds. The whole idea serves to determine the only moment when it will be possible to start processing requests in a new application, and by this moment absolutely all existing data has been migrated. At each moment of time, new entries get into the database either from the old code or from the new one, but never at the same time. This eliminates the incompatibility of the code data, simplifies and accelerates the switching of releases.Spell # 3
The step with the removal of the "block" for requests is considered the final step of deployment. The world has changed. A new code is working, and a return to the past is not possible. Any step to this can be rolled back without consequences. If any exceptional situation occurs before the moment of switching the fronts, Deploy rolls back the steps in the reverse order, from the current to the first one, returning the whole system to a workable form. New services are turned off, old ones are turned on, stopped robots are started, etc.
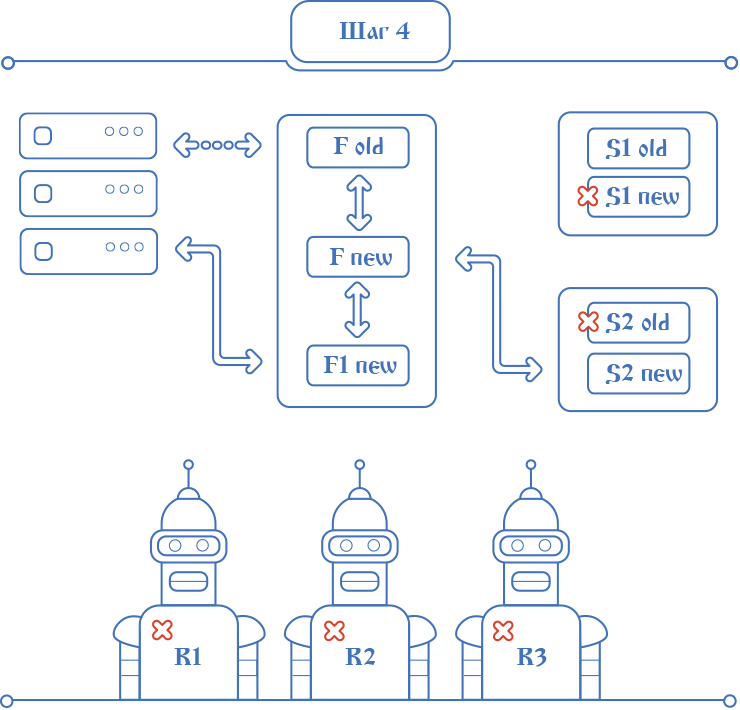 Deploy's work is not finished yet. Living with two applications and proxying is not very convenient. Deploy switches the default application in IIS to the folder with the new application - the one from which the "auxiliary" is running. This process again takes time in IIS, usually in seconds. All this time, requests are received in the old application and are proxied to the "auxiliary". In the meantime, a new “working” application starts, and, as usual after the start, it should be given time to “warm up”. Therefore, incoming HTTP requests do not process new applications, but for the entire time of warming up, they also proxy to “auxiliary”.
Deploy's work is not finished yet. Living with two applications and proxying is not very convenient. Deploy switches the default application in IIS to the folder with the new application - the one from which the "auxiliary" is running. This process again takes time in IIS, usually in seconds. All this time, requests are received in the old application and are proxied to the "auxiliary". In the meantime, a new “working” application starts, and, as usual after the start, it should be given time to “warm up”. Therefore, incoming HTTP requests do not process new applications, but for the entire time of warming up, they also proxy to “auxiliary”.Spell # 4In the last steps Deploy left to stop the still working half of the replicas of old services, start new ones instead, turn on new robots in the scheduler, wait for the new fronts to warm up and write in the log about the success of the release. Deploy done!
At some point, three Elbe applications run simultaneously on the same host in the same IIS. The old one that managed to accept the incoming request before switching to IIS and proxied it to the “auxiliary” new one. The third, also new, just launched after the switch,completely identical to the second "auxiliary". The third one proxies requests to the second while it is warming up. After the final “warm-up”, the application stops proxying and starts processing requests on its own. Other applications die when the flow of requests to them dries out. At the end there is only one.
Epilogue
This article describes the main ideas and rather specific techniques that allowed Elba to introduce the practice of fast non-stop updating in a short time.
It remains behind the scenes, as we migrate data in Mong and elastic, ensure the correct rollback of records, synchronize the notorious “block”, fight against IIS, create a UI for Deploy, and solve many other minor technical problems. If you are interested in details, we will be happy to answer in the comments.
Occasionally, Elba is updated under the “stub”, but this is usually associated with the relocation of hardware, upgrading the OS, infrastructure services and, almost never, with releases of new functionality.
As a result, the development of new Deploy, we got almost what we wanted - the non-stop deployment of a new release, completely transparent to users. The client can go to the page in the old application, update it and be in the new one. The entire deployment process takes less than 10 minutes, and the maximum delay time for responding to a request is no more than 3-4 seconds. In this case, the entire Deploy code is ours. We continue to refine and improve it, introduce new features and develop its functionality.

Source: https://habr.com/ru/post/314144/
All Articles