How we started a failover cluster

Errors and difficulties that we encountered when running our own cluster based on VMmanager Cloud + Ceph .
Prehistory
Different people come to us at FirstVDS. Someone is enough hosting on the basis of CMS, someone virtual server. But sometimes a person asks for a productive server with increased reliability, while he is not too worried about the cost of the service.
We are confident in our usual VDS, but we decided to create a separate service that, for a higher price, would provide guaranteed resiliency supported by SLA. The problem is solved by creating a cluster of increased reliability, however, we had doubts about network technologies. Somehow they collected a cluster on a gigabit network - for myself to try. Nothing happened - the network was slowing down, the cluster was working very slowly, it was impossible to use it for practical tasks.
')
The impression was that distributed systems were inferior in speed to classic solutions. We knew about the InfiniBand technology, but we weren't ready to test it on ourselves - the equipment was expensive. The switch itself costs about $ 5000, a network card $ 780, and another cable $ 100. Total, connecting one server to an IB network costs $ 1,300. The idea was continued by lucky coincidence.
In May 2014, our director Alexey Chekushkin once again went to Khostobzor for the conference. This is such a private get-together where the representatives of hosting sites meet and share their experiences. At the conference, Alexey listened to a report on the experience of using InfiniBand, and then spoke to the speaker personally. It turned out that IB does an excellent job with its tasks - the network really works at a speed of 56 Gbit / s, and the network delays are so low that they are invisible against the background of disk delays. Those. it does not matter whether the disk is installed locally or the computer accesses it over the network. This is exactly what was required to create a distributed cluster.
In August 2014, we bought the necessary equipment and started assembling.
The first version of the cluster
Hosting FirstVDS has been cooperating with ISPsystem for 13 years. We use BILLmanager as a billing platform, install ISPmanager as a control panel on client servers, use VMmanager to manage virtual machines. Over the years of cooperation with ISPsystem, we have gained a lot of experience working with products, and have never doubted the professionalism of developers. Therefore, we decided to use VMmanager Cloud to build a cluster, especially since the specifications claim support for Ceph - that’s what we wanted to use for data storage.
The technology stack for building a high availability cluster is:
- VMmanager Cloud - running virtual machines "in the cloud"
- Ceph - Network Distributed Data Warehouse
- InfiniBand - network, communication between cluster machines
VMmanager Cloud actually supported Ceph, but we were the first to try it out. As the project progressed, ideas for improving the product emerged - ISPsystem met and modified VMmanager Cloud on the fly.
Especially for the cluster bought:
- Xeon 2630 machines. The same machines are used for our usual virtual server hosting.
- The InfiniBand SX6005 switch is a 12-port model, we calculated that this would be enough
- Maps for connecting computers to the HCA Mellanox InfiniBand network
- DAC cables - to connect components to the network
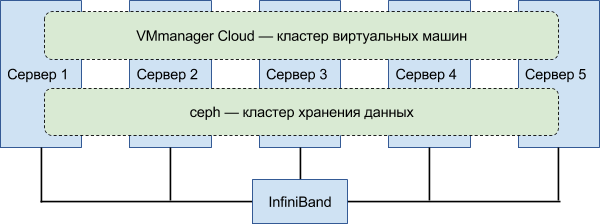
High availability hosting consists of two clusters — a storage cluster and a compute cluster.
The computing cluster is managed by VMmanager Cloud and is responsible for running client virtual servers on the physical machines of the cluster. The configurations of all VMmanager virtual machines are stored in the database, a replica of the base is stored on each node of the computing cluster. Therefore, when any of them fail, the client virtual server is simply restarted to another - rebalancing occurs.
The storage cluster runs Ceph and is responsible for storing information. The number of replicas of one data block (default pool size) was set to 3 — all data is stored in three copies. If a disk or entire node is disconnected and one of the copies is lost, Ceph creates a working copy of the files from the two remaining ones. In addition, in such cases, the system creates the missing copies of files on the existing disk space - this process is also called rebalancing.
Duplication of equipment and redundant data storage and provide increased fault tolerance.
The first version consisted of 5 servers networked with IB. Ceph did not support the IB protocol at that time, so they used IPoIB . Ceph is a multi-component software. We use two parts: a cluster monitor ( ceph-mon ) and a storage daemon ( ceph-osd ).
For storage on each server installed 2 disks of 2 TB and one SSD for 400 GB for caching. This concept — read-write caching on fast media — is supported by Ceph. We decided to use it in order not to raise the price for the end user due to SSD-drives.
In the first version, both tasks — computation and storage — were run on the same nodes.
First, we launched synthetic tests on a cluster: we created VDS blanks, watched how the system would work under load. To check the cluster connectivity, the disks and individual nodes were disconnected - they watched how the cluster would redistribute the load and the recorded data.
After the tests began to run on the cluster normal client VDS. So, we saw how the cluster behaves in a “combat” mode.
The system worked, but the performance was lower than expected. The data transfer rate over IB is only 20 Gbit / s instead of the stated 56 Gbit / s. Sinned on InfiniBand, but later found out that the matter was different. The whole system worked slowly: the data from the virtual servers did not have time to be recorded and got into the queue. Some processes were waiting for other processes to wait for writing to the disk in order to free up the processor. All this piled up like a snowball, increasing the cost of performing maintenance operations.
The cluster coped with the tasks - in case of failure of disks or nodes entirely, it continued to function. However, each rebalancing turned the situation into a critical one. When adding a new disc, the peak load was smoothed using weights. Weight is responsible for the degree of use of a particular physical carrier. Install the new disk, set the weight to 0 - the disk is not used. After that, we increase the weight gradually, and rebalancing occurs in small portions. If the disk fails, the weights do not work: ~ 1 TB of replicas must be “smeared” on the remaining disks right away, and Ceph permanently goes into the data recording mode, loading the disks with “empty” work.
During technical work, users noticed that the sites are slow. We tried to solve problems with iron as quickly as possible in order to maintain the quality of service at the proper level.
Experimenting with the configuration: added nodes, disks, RAM. Each configuration was tested first on synthetic tests, then the real virtuals of new clients were opened. With an increase in the number of VDS, the cluster started to work unstable, and we transferred client machines to ordinary nodes. Since such transfers were planned and took place in the normal mode, they did not cause any inconvenience to customers.
After several iterations, it became clear that the situation does not change drastically. Decided to transfer customers to ordinary nodes and disband the cluster.
Second version of the cluster
The first version of the cluster did not meet expectations. Clients faced disc brakes, and we devoted too much time to technical support of the cluster. They decided to take a break, but they didn’t refuse to launch the idea of launching their own high-availability service. And the IB switch is idle.
In the first version, the same nodes were responsible for data storage and the operation of virtual machines. The breakdown of a single physical server put too much stress on the system, since at the same time, rebalancing on the virtual machine nodes and creating missing data replicas started up. Classical architecture was used for load sharing:
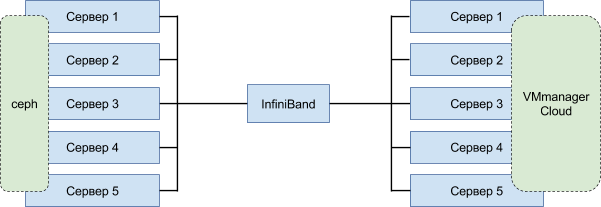
They organized two separate clusters : one for storing data, the other for running virtual machines.
In order to test the new architecture and get rid of the previous drawbacks, a test bench was assembled. And then it turned out interesting - specially purchased for the assembly of the first version of the servers were "burned." The system bus of all servers was slow. As a result, all devices connected to the north and south bridges — IB cards connected via PCI-E, disks, memory — also worked slowly. This explained most of the problems we faced. As a sample, we took several free nodes, on which we usually run client VDS. For those characteristics, they almost did not differ. Collected and launched a cluster on these machines, began to run tests. Everything flies! And even the IB network provides the claimed 56 Gbit / s.
Before launching, we reorganized disk storage: we bought new servers based on Xeon 2630 with a large number of disk baskets for growth. We got an external hard disk controller for more efficient operation of the disk subsystem. As a result, 6 disks worked on each storage cluster machine: 4 HDDs of 4-8 Tb + 2 SSDs of 500 GB each.
As a result, the entire assembly consisted of 12 machines: 3 in the storage cluster and 9 in the computing cluster. After running the test bench in September 2015, the cluster was launched as a separate service - a fault-tolerant virtual server.
About five months the system worked wonderfully, delighting us and customers. That was until the number of customers reached a critical value. Roomy 4-8 TB disks still got us sideways. When the disk was already half full, it turned into a bottleneck - a large number of files belonging to different VDS were located on the same physical medium, and it had to serve a large number of clients. When it fails, rebalancing was also difficult: a large amount of information must be redistributed. SSD-cache in such conditions poorly coped with their duties. Sooner or later, the cache disk was full and gave a signal - from now on I don’t cache anything, but only write the saved information to a slow HDD disk. The HDD is experiencing double load at this time - it processes direct calls that arrive bypassing the cache and records the data stored in the cache. The storage worked well until it came to changing the disk configuration. The loss of a disk or the addition of a new one greatly slowed down the total bandwidth of the storage.
The third version of the cluster
Misfortune never comes alone. On February 18, 2016, we encountered a critical Ceph bug: in the process of flushing the cache to disk, an incorrect data block write occurred. This led to the disconnection of the ceph-osd processes of all disks where replicas of the ill-fated block were stored. The system immediately lost three disks, and hence all the files placed on them. The rebalancing process started, but could not be completed to the end - after all, all three copies of at least one data block (and the corresponding file) that started the problem disappeared from the system. The storage consistency was compromised. We manually deleted the erroneous blocks, restarted the ceph-osd processes , but this did not help much for a while. The erroneous recording was repeated, the balancing began again, and the storage collapsed.
A tense search on the Internet gave the result - a closed bug in the latest release of Ceph Hammer . Our repository is running on a previous version - Firefly. Fortunately, Ceph has a system of backports: fixes for critical bugs are added to previous versions in order to maintain compatibility during migration.
Warned customers about the inaccessibility of servers and started to upgrade. Switched to another repository, in which fix bugs were filled in, executed yum update, restarted Ceph processes - did not help. The error repeats. Localized the source of the problem - writing from the cache to the main storage - and turned off caching completely. Client servers were working, but each rebalancing was turning into hell. The disks did not cope with the maintenance of system balancing and client read-write.
Solved the problem fundamentally - abandoned the SSD-cache and put the SSD-drives as the main. Here helped nodes with a large number of disk baskets, prudently purchased for the storage cluster. They replaced them gradually: first, they added four SSDs to the remaining empty baskets on each server, and after balancing the data, they began replacing the old HDDs with SSDs one at a time. They did it according to the following scheme: removing a disk, installing a disk, balancing data, deleting, installing, balancing and so on in a circle, until only SSD remained in the nodes. Replaced with hot, because the loss of one drive does not affect the performance of the storage cluster.
Used industrial drives Samsung PM810 size of 1 TB. They did not use a larger SSD in order not to provoke a “narrow neck” situation, when there is a lot of data on one physical medium, and therefore it has a large number of hits.
Thus, we gradually replaced all drives with SSDs. And happiness came - the cluster began to work like a clock. Peak loads in the event of problems with iron ceased, rebalancing occurs unnoticed by customers. Later, we still had to compact the storage and replace the disks with 2-terabyte Samsung PM863. The replacement did not affect the operation of the storage cluster.
In this configuration, our failover cluster works to this day. And his name is Atlant :)
Cluster Technical Indicators
Comparison of a virtual machine in a cluster ( ceph ) with a virtual machine on a normal node with SSD-drives ( ssd ).
Record:
ceph: bw=393.181 KB/s, iops=3071 ssd: bw=70.371 KB/s, iops=549 Reading:
ceph: bw=242.129 KB/s, iops=1891 ssd: bw=94.626 KB/s, iops=739 Several days of cluster work in graphs:
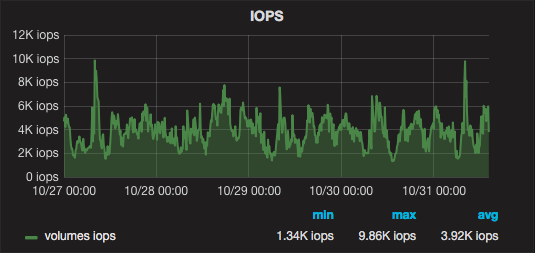
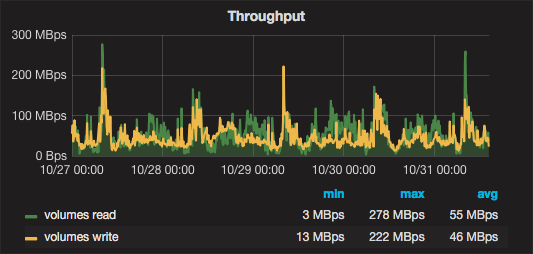
Development prospects
Now the IB switch is duplicated by a regular Gigabit Ethernet switch. This is necessary so that the cluster does not lose connectivity when the main switch fails. On the pickup, there is a standby IB switch, but it is necessary to switch cluster nodes to it in case of a problem manually. After a crash, the system will continue to work with performance degradation for 5-10 minutes. This time is necessary for physical switching to the backup IB switch.
We plan to fully duplicate the IB switch so that when the main one fails, the second instantly takes over the entire load. This is not as easy as it seems - you need to install a second HCA card in each server. Not all nodes have an additional PCI-E, so some will have to be replaced entirely. You can put one dual-port card, but this solution does not save from the failure of the card itself.
We plan to develop a cluster in width - sooner or later the nodes will fill up, and there are almost no ports left to connect new nodes. You need to add another IB switch and connect to the existing one in series.
Conclusion
We used VMmanager Cloud and Ceph to create a cluster of increased reliability. Here are our recommendations if you decide to use the same technologies:
- Use the LTS editions of Ceph. Do not expect that you will roll out a new version with each release. Updating is a potentially dangerous operation for the repository. Switching to the new version will result in changes in the configurations, and it’s not a fact that the storage will work after the update. Track bug fixes - they back up from new versions to old ones.
- Use fast SSDs as primary. No need to use large discs. It is better to put 2 disks on 1 TB than 1 on 2 TB. The caching approach is not worth it. We'll have to be very confused with the settings, and with the subsequent support.
- For storage use nodes with a large number of disk baskets. Or be ready to connect additional nodes as the cluster grows.
Source: https://habr.com/ru/post/314106/
All Articles