How to stop being afraid and fall in love with syntactic analysis?
As often when programming another business feature, you caught yourself thinking: there are people on Earth who write databases, recognize faces in photos, make frameworks and implement interesting algorithms. Why in my work it all comes down to shifting from one database table to another, calling http-services, html-form layout and other “business noodles”? Maybe I'm doing something wrong or working in the wrong company?

The good news is that interesting challenges surround us everywhere. Strong desire and courage work wonders on the way to the goal - a task of any scale will be up to you, if you just start doing it.
Recently we have written the 1C query language parser and its translator into plain SQL. This allowed us to fulfill requests to 1C without the participation of 1C :) The minimum working version on regexp-ah turned out for two weeks. Another month went to a full-fledged parser through grammars, digging out the nuances of the database structure of different 1C objects and implementing specific operators and functions. As a result, the solution supports almost all language constructs, the source code is uploaded to GitHub .
')
Under the cut, we will tell you why we needed it, how we did it, and also touch on some interesting technical details.
We work in a large accounting company Button . We have 1005 clients serviced, 75 accountants and 11 developers work. Our accountants keep records of thousands of client bases in1C: Accounting . To manage databases, we use the cloud technology 1cFresh, the data for it is stored in PostgreSQL.
 The most difficult stage in the work of an accountant is reporting. It would seem that 1C can prepare any reporting, but for this it needs the current state of the database. Someone must enter all primary documents into the system, import a bank statement, create and carry out the necessary accounting documents. At the same time, the deadlines for submitting reports in our beloved state are strictly limited, so accountants usually live from one sleepless time trouble to another.
The most difficult stage in the work of an accountant is reporting. It would seem that 1C can prepare any reporting, but for this it needs the current state of the database. Someone must enter all primary documents into the system, import a bank statement, create and carry out the necessary accounting documents. At the same time, the deadlines for submitting reports in our beloved state are strictly limited, so accountants usually live from one sleepless time trouble to another.
We thought: how can accountants make their lives easier?
It turned out that a lot of problems with reporting arise due to minor errors in the accounting database:
 These problems are easy to find using the 1C query language, so there was an idea to do an automated audit of client databases. We wrote several requests and began to execute them every night on all 1C bases. We showed the problems we found to the accountants in a convenient google-tablet, and in every possible way called for the tablet to remain empty.
These problems are easy to find using the 1C query language, so there was an idea to do an automated audit of client databases. We wrote several requests and began to execute them every night on all 1C bases. We showed the problems we found to the accountants in a convenient google-tablet, and in every possible way called for the tablet to remain empty.
Performing these queries through standard COM api 1C is not the best idea. First, it takes a long time - to go around a thousand bases and run all requests on each of them takes 10 hours. Secondly, it significantly loads the server 1C, which usually and so hard lives. It is unpleasant for the sake of auditing to slow down people's daily work.
Meanwhile, a typical 1C query looks like this:
Despite the fact that it is very similar to SQL, such a thing will not work just like that and run directly through the database.
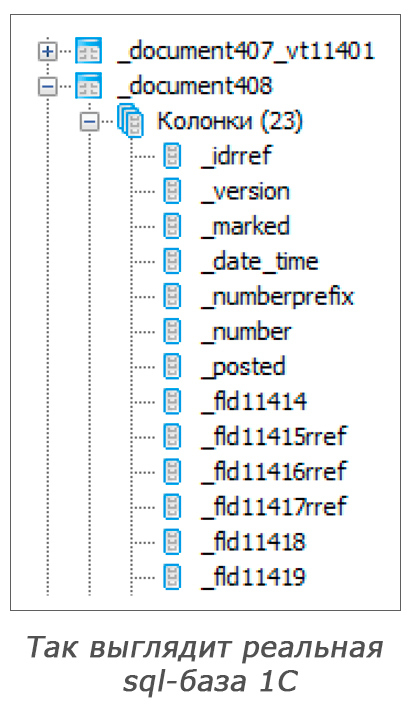 There are three real reasons for this:
There are three real reasons for this:
Realizing all this, we wrote a utility that converts a query from 1C dialect into ordinary SQL, runs it in parallel on all PostgreSQL physical servers, the result combines and adds to a separate table in MS SQL. As a result, the data collection time was reduced from 10 hours to 3 minutes.
In the first version, we implemented the query conversion logic entirely through regexps. In COM api 1C, there is a function GetStructure Database Storage. It returns information about which tables and fields correspond to objects and properties in 1C request. Using several regexp templates, we simply replaced some names with others. This was achieved quite easily, provided that all references to objects and properties had pseudonyms.
Most of the trouble delivered nested properties. 1C stores them in related tables, so we had to replace the original name of the object in the
In addition to renaming the properties and generating the left
Using regexps turned out to be the right decision , as it allowed us to quickly get the final result and to understand that something useful is obtained from this whole undertaking. We all recommend the proof of concepts and experiments to do just that - as simple as possible means at hand. And what could be simpler and more effective when working with texts than regexp?
Of course, there are drawbacks. The first and obvious is the cut corners and syntax restrictions. Regexps for properties and tables required the arrangement of pseudonyms in the query and, in general, could accidentally get stuck with some other construct, for example, a constant string.
Another problem is mixing the logic of parsing text and converting it according to the necessary rules. Each time, implementing a new feature, it was necessary to invent a new hellish mixture of regexp-s with
So, for example, looked like a code that added a condition on the equality of domains to all joines:
In the code, I wanted to deal with the object model of the original request, with the
Agree that this option looks much simpler and clearer than the previous one:
Such an object model is called Abstract syntax tree ( AST ).
Interestingly, for the first time, AST did not appear when parsing the original request, but, on the contrary, when formatting the result in SQL. The fact is that the logic of constructing a subquery for nested properties became quite florid, and to simplify it (and in accordance with SRP ) we broke the whole process into two steps: first create a tree of objects describing the subquery, then separately serialize it into SQL. At some point, we realized that this is AST, and to solve problems with regexp, you just need to learn how to create it for the original request.
The term AST is widely used when discussing the nuances of parsing. It is called a tree because this data structure describes well the typical for programming languages constructs, usually with the property of recursiveness and absence of cycles (although this is not always true ).
For example, consider the following query:
In the form of AST, it looks like this:

In the figure, nodes — instances of classes, arrows, and captions — are properties of these classes.
Such an object model can be assembled through code as follows:
It is worth noting that the above example AST is not the only correct one. The specific structure of classes and the connections between them are determined by the specifics of the task. The main goal of any AST is to facilitate the solution of the problem, to make performing typical operations as convenient as possible. Therefore, the easier and more natural it is to describe the constructions of the desired language, the better.
The transition from regexp to AST allowed us to get rid of many hacks, to make the code cleaner and clearer. At the same time, our utility now had to be aware of all the constructs of the source language in order to create for them the corresponding node in the tree. For this, I had to write the grammar of the query language 1C and a parser for it.
So, at some point it became clear that we need the AST of the original request. There are many libraries on the Internet that can parse SQL and create an AST for it, but if you take a closer look, they either turn out to be paid , or they only support a subset of SQL. Besides, it is not clear how to adapt them for recognizing the 1C-dialect of SQL, because it contains a number of specific extensions.
Therefore, we decided to write our own parser. Syntax analyzers usually begin to do with the description of the grammar of the language that you want to recognize. Formal grammar is a classic tool for describing the structure of programming languages. Its basis is formed by the rules of inference, that is, the recursive definitions of each language construct.
For example, such rules can describe the language of arithmetic expressions:
This record can be read as follows:
The characters for which output rules are defined are called non terminals . Symbols for which rules are not defined and which are language elements - terminals . Applying the rules, you can get strings from non-terminals, consisting of other non-terminals and terminals, until only the terminals remain. In the example above,
There are special tools - syntax analyzer generators, which, according to the description of a language specified in the form of a grammar, are able to generate code recognizing this language. The most famous of them are yacc , bison and antlr . For C #, there is a less common Irony library. About her there was already a small article on Habré , but Scott Hanselman ’s post about her.
The main feature of the Irony library is that grammar rules can be described directly in
Symbol | means that any of the variants of the rule can be applied (logical or). The symbol + is a concatenation, the characters must follow each other.
Irony separates Parse Tree and Abstract Syntax Tree . Parse Tree is an artifact of the text recognition process, the result of consistent application of grammar rules. In its internal nodes are non terminals, and descendants get characters from the right parts of the relevant rules.
For example, the expression
corresponds to the Parse Tree:

Parse Tree does not depend on a specific language and in Irony is described by a single
Abstract Syntax Tree, on the contrary, is entirely determined by a specific task, and consists of classes specific to this task and the connections between them.
For example, the AST for grammar above can consist of just one

Irony allows you to create an AST sequentially, rising from the leaves to the root, while applying the rules of grammar. To do this, you can
When we thus reach the root nonterminal, the AST root node is formed in its
For the grammar of arithmetic expressions above, AstNodeCreator might look like this:
So, with the help of Irony, we learned how to construct an AST on an initial request. Only one big question remains - how to effectively structure the code for AST conversion, because ultimately we need to get an AST of the resulting SQL query from the source AST. The Visitor pattern will help us in this.
The Visitor (or double dispatch ) pattern is one of the most complex in GoF and, therefore, one of the most rarely used. For our experience, we have seen only one active application of it - to convert various AST. A specific example is the ExpressionVisitor class in .NET, which inevitably occurs when you make a linq provider or just want to tweak a little with the compiler-generated expression tree .
What problem is solved by visitor?
The most natural and necessary thing that you often have to do when working with AST is to turn it into a string. Take for example our AST: after replacing Russian table names with English ones, generating
A possible solution to this problem is as follows:
About this code, you can make two important observations:
Now consider another task. Suppose we need to add a condition for the equality of the
This means that if you follow the same code structure as above, we will need to:
The problem with this approach is clear - the more we have different logical operations on the tree, the more there will be methods in the nodes, and the more copy-paste between these methods.
Visitors solve this problem by:
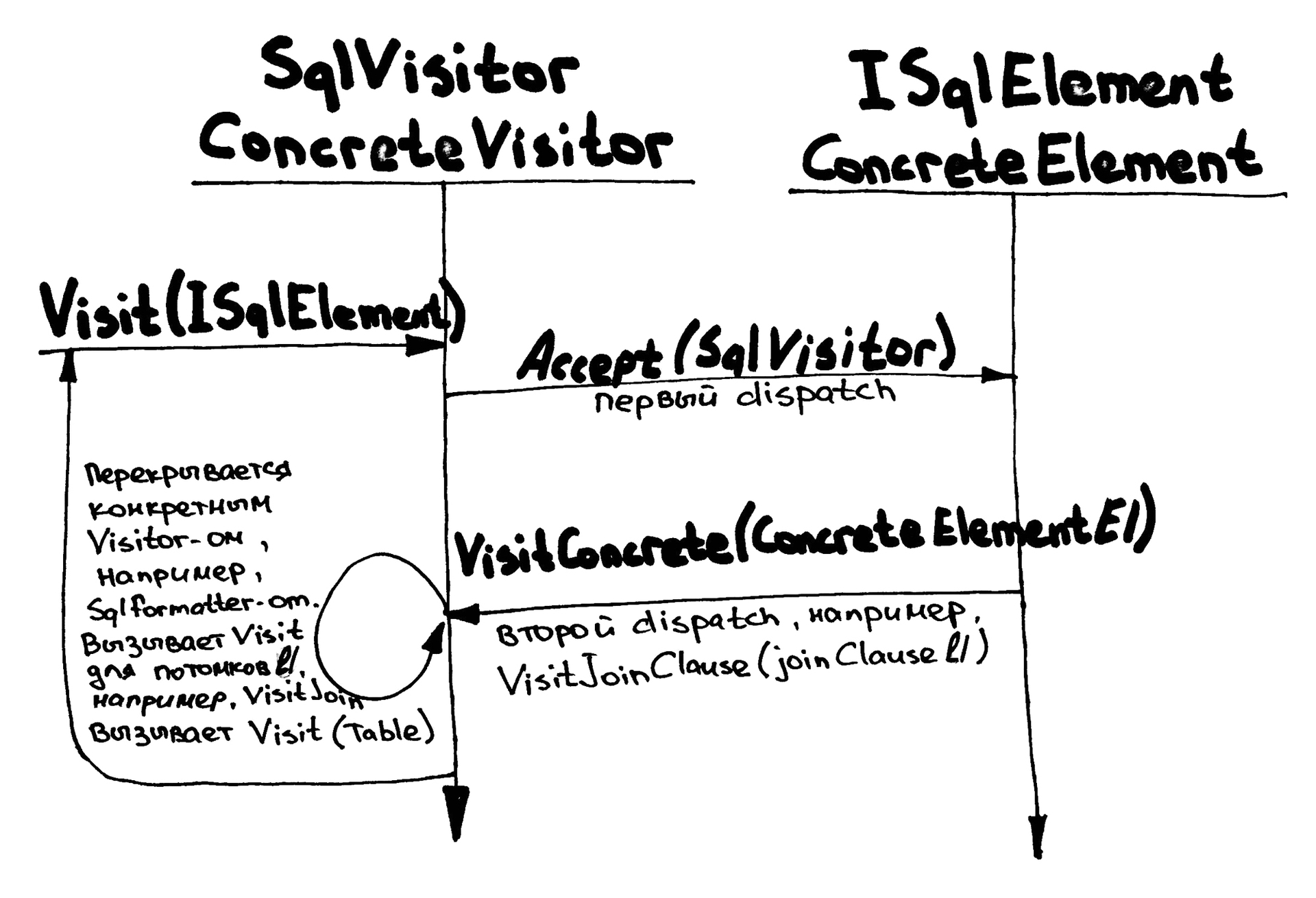
An example with serialization in SQL is adapted as follows:
The name double dispatch quite accurately describes this scheme:
The article describes in detail the recipe for making the translator of the 1C query language into SQL queries. We went through experiments with regular expressions, having received a working prototype and confirmation that the piece is useful and should move on. And when it became impossible to look at the code without shame and pain, and juggling with regexp did not lead to the desired result, we took a serious step - we switched to AST and grammars. Then, using visitor, we learned how to transform AST, thereby realizing the logic of translation from one language to another.
It is worth noting that this path we did not go alone, and did not even have to open the Dragon Book . For parsing and building AST, we used the ready-made library of Irony, which made it possible not to reinvent the wheel, but to go straight to solving an applied problem.
The bottom line for the company is to reduce the speed of receiving data from 10 hours to 3 minutes. This allowed our analysts to quickly set up experiments and test hypotheses about the clients' business and the work of accountants. This is especially convenient, since we have a lot of clients, and their bases are distributed among the five physical PostgreSQL servers.
Summarizing all the above:
Library code and usage examples are waiting for you on GitHub .
At leisure, we advise you to read:
The good news is that interesting challenges surround us everywhere. Strong desire and courage work wonders on the way to the goal - a task of any scale will be up to you, if you just start doing it.
Recently we have written the 1C query language parser and its translator into plain SQL. This allowed us to fulfill requests to 1C without the participation of 1C :) The minimum working version on regexp-ah turned out for two weeks. Another month went to a full-fledged parser through grammars, digging out the nuances of the database structure of different 1C objects and implementing specific operators and functions. As a result, the solution supports almost all language constructs, the source code is uploaded to GitHub .
')
Under the cut, we will tell you why we needed it, how we did it, and also touch on some interesting technical details.
How did it all start?
We work in a large accounting company Button . We have 1005 clients serviced, 75 accountants and 11 developers work. Our accountants keep records of thousands of client bases in
The most difficult stage in the work of an accountant is reporting. It would seem that 1C can prepare any reporting, but for this it needs the current state of the database. Someone must enter all primary documents into the system, import a bank statement, create and carry out the necessary accounting documents. At the same time, the deadlines for submitting reports in our beloved state are strictly limited, so accountants usually live from one sleepless time trouble to another.We thought: how can accountants make their lives easier?
It turned out that a lot of problems with reporting arise due to minor errors in the accounting database:
- duplicate counterparty or contract;
- duplicates of primary documents;
- counterparty without TIN;
- A document with a date from a distant past or future.
These problems are easy to find using the 1C query language, so there was an idea to do an automated audit of client databases. We wrote several requests and began to execute them every night on all 1C bases. We showed the problems we found to the accountants in a convenient google-tablet, and in every possible way called for the tablet to remain empty.Performing these queries through standard COM api 1C is not the best idea. First, it takes a long time - to go around a thousand bases and run all requests on each of them takes 10 hours. Secondly, it significantly loads the server 1C, which usually and so hard lives. It is unpleasant for the sake of auditing to slow down people's daily work.
Meanwhile, a typical 1C query looks like this:
select doc. as Date, doc. as Number, doc.. as Inn, doc.. as CounterpartyInn, (doc..) as CounterpartyType, doc. as Description, doc. as Sum from . doc where not doc.. and doc. and doc. = (..) and (doc.) = (&Now) Despite the fact that it is very similar to SQL, such a thing will not work just like that and run directly through the database.
There are three real reasons for this:- Magic names of tables and columns in the database. This is easily solved, since 1C documents their correspondence to the names from the request.
- Nested properties. For example,
doc..in SQL corresponds to theleft jointwo plates.doc..to thedoc..and.. - Specific for 1C operators and functions , such as
,. They also need to be further translated into the appropriate database design.
Realizing all this, we wrote a utility that converts a query from 1C dialect into ordinary SQL, runs it in parallel on all PostgreSQL physical servers, the result combines and adds to a separate table in MS SQL. As a result, the data collection time was reduced from 10 hours to 3 minutes.
Regular expressions
In the first version, we implemented the query conversion logic entirely through regexps. In COM api 1C, there is a function GetStructure Database Storage. It returns information about which tables and fields correspond to objects and properties in 1C request. Using several regexp templates, we simply replaced some names with others. This was achieved quite easily, provided that all references to objects and properties had pseudonyms.
Most of the trouble delivered nested properties. 1C stores them in related tables, so we had to replace the original name of the object in the
from construction with a subquery, which contained all the necessary left join- .Request example
select doc.. from . doc -- select doc.gen0 from (select tContractor.inn gen0 from tDoc left join tContractor on tDoc.contractorId = tContractor.id) doc In addition to renaming the properties and generating the left
join , the translator also applied a number of transformations. So, for example, all the joines in the original query had to be supplied with an additional condition for the equality of the field (area) . The fact is that in one PostgreSQL database, we have several 1C client bases, and the data of one client differs from the data of another with a special identifier, which 1C calls a domain . In base 1C creates a number of indexes by default. All of them have the first component of the key area, since all requests are executed within a single client. In order for our queries to use standard indexes, and in order not to think about it when writing them, we began to add this condition automatically when translating the query.Using regexps turned out to be the right decision , as it allowed us to quickly get the final result and to understand that something useful is obtained from this whole undertaking. We all recommend the proof of concepts and experiments to do just that - as simple as possible means at hand. And what could be simpler and more effective when working with texts than regexp?
Of course, there are drawbacks. The first and obvious is the cut corners and syntax restrictions. Regexps for properties and tables required the arrangement of pseudonyms in the query and, in general, could accidentally get stuck with some other construct, for example, a constant string.
Another problem is mixing the logic of parsing text and converting it according to the necessary rules. Each time, implementing a new feature, it was necessary to invent a new hellish mixture of regexp-s with
IndexOf calls on the rows, which would subtract the corresponding elements in the original query.So, for example, looked like a code that added a condition on the equality of domains to all joines:
private string PatchJoin(string joinText, int joinPosition, string alias) { var fromPosition = queryText.LastIndexOf("from", joinPosition, StringComparison.OrdinalIgnoreCase); if (fromPosition < 0) throw new InvalidOperationException("assertion failure"); var tableMatch = tableNameRegex.Match(queryText, fromPosition); if (!tableMatch.Success) throw new InvalidOperationException("assertion failure"); var mainTableAlias = tableMatch.Groups[3].Value; var mainTableEntity = GetQueryEntity(mainTableAlias); var joinTableEntity = GetQueryEntity(alias); var condition = string.Format("{0}.{1} = {2}.{3} and ", mainTableAlias, mainTableEntity.GetAreaColumnName(), alias, joinTableEntity.GetAreaColumnName()); return joinText + condition; } In the code, I wanted to deal with the object model of the original request, with the
ColumnReference and JoinClause , and instead there were only the substrings found and the JoinClause in the query text.Agree that this option looks much simpler and clearer than the previous one:
private void PatchJoin(SelectClause selectClause, JoinClause joinClause) { joinClause.Condition = new AndExpression { Left = new EqualityExpression { Left = new ColumnReferenceExpression { Name = PropertyNames.area, Table = selectClause.Source }, Right = new ColumnReferenceExpression { Name = PropertyNames.area, Table = joinClause.Source } }, Right = joinClause.Condition }; } Such an object model is called Abstract syntax tree ( AST ).
AST
Interestingly, for the first time, AST did not appear when parsing the original request, but, on the contrary, when formatting the result in SQL. The fact is that the logic of constructing a subquery for nested properties became quite florid, and to simplify it (and in accordance with SRP ) we broke the whole process into two steps: first create a tree of objects describing the subquery, then separately serialize it into SQL. At some point, we realized that this is AST, and to solve problems with regexp, you just need to learn how to create it for the original request.
The term AST is widely used when discussing the nuances of parsing. It is called a tree because this data structure describes well the typical for programming languages constructs, usually with the property of recursiveness and absence of cycles (although this is not always true ).
For example, consider the following query:
select p.surname as 'person surname' from persons p where p.name = '' In the form of AST, it looks like this:
In the figure, nodes — instances of classes, arrows, and captions — are properties of these classes.
Such an object model can be assembled through code as follows:
var table = new TableDeclarationClause { Name = "PersonsTable", Alias = "t" }; var selectClause = new SelectClause { FromExpression = table, WhereExpression = new EqualityExpression { Left = new ColumnReferenceExpression { Table = table, Name = "name" }, Right = new LiteralExpression { Value = "" } } }; selectClause.Fields.Add(new SelectFieldExpression { Expression = new ColumnReferenceExpression { Table = table, Name = "surname" } }); It is worth noting that the above example AST is not the only correct one. The specific structure of classes and the connections between them are determined by the specifics of the task. The main goal of any AST is to facilitate the solution of the problem, to make performing typical operations as convenient as possible. Therefore, the easier and more natural it is to describe the constructions of the desired language, the better.
The transition from regexp to AST allowed us to get rid of many hacks, to make the code cleaner and clearer. At the same time, our utility now had to be aware of all the constructs of the source language in order to create for them the corresponding node in the tree. For this, I had to write the grammar of the query language 1C and a parser for it.
Grammar
So, at some point it became clear that we need the AST of the original request. There are many libraries on the Internet that can parse SQL and create an AST for it, but if you take a closer look, they either turn out to be paid , or they only support a subset of SQL. Besides, it is not clear how to adapt them for recognizing the 1C-dialect of SQL, because it contains a number of specific extensions.
Therefore, we decided to write our own parser. Syntax analyzers usually begin to do with the description of the grammar of the language that you want to recognize. Formal grammar is a classic tool for describing the structure of programming languages. Its basis is formed by the rules of inference, that is, the recursive definitions of each language construct.
For example, such rules can describe the language of arithmetic expressions:
E → number | (E) | E + E | E - E | E * E | E / E This record can be read as follows:
- any number
(number)is an expression(E); - if the expression is enclosed in brackets, then all this, together with the brackets, is also an expression;
- two expressions joined by an arithmetic operation also constitute an expression.
The characters for which output rules are defined are called non terminals . Symbols for which rules are not defined and which are language elements - terminals . Applying the rules, you can get strings from non-terminals, consisting of other non-terminals and terminals, until only the terminals remain. In the example above,
E is a non-terminal, and the symbols +, -, *, / and number are the terminals that make up the language of arithmetic expressions.There are special tools - syntax analyzer generators, which, according to the description of a language specified in the form of a grammar, are able to generate code recognizing this language. The most famous of them are yacc , bison and antlr . For C #, there is a less common Irony library. About her there was already a small article on Habré , but Scott Hanselman ’s post about her.
The main feature of the Irony library is that grammar rules can be described directly in
C# using operator overloading. The result is quite a nice DSL , the form is very similar to the classical form of writing rules: var e = new NonTerminal("expression"); var number = new NumberLiteral("number"); e.Rule = e + "+" + e | e + "-" + e | e + "*" + e | e + "/" + e | "(" + e + ")" | number; Symbol | means that any of the variants of the rule can be applied (logical or). The symbol + is a concatenation, the characters must follow each other.
Irony separates Parse Tree and Abstract Syntax Tree . Parse Tree is an artifact of the text recognition process, the result of consistent application of grammar rules. In its internal nodes are non terminals, and descendants get characters from the right parts of the relevant rules.
For example, the expression
1+(2+3) when applying the rules:e 1 : E → E + E
e 2 : E → (E)
e 3 : E → number
corresponds to the Parse Tree:
Parse Tree does not depend on a specific language and in Irony is described by a single
ParseTreeNode class.Abstract Syntax Tree, on the contrary, is entirely determined by a specific task, and consists of classes specific to this task and the connections between them.
For example, the AST for grammar above can consist of just one
BinaryOperator class: public enum OperatorType { Plus, Minus, Mul, Div } public class BinaryOperator { public object Left { get; set; } public object Right { get; set; } public OperatorType Type { get; set; } } Left and Right properties are of type object , since they can refer either to a number or to another BinaryOperator :Irony allows you to create an AST sequentially, rising from the leaves to the root, while applying the rules of grammar. To do this, you can
AstNodeCreator delegate to each non- AstNodeCreator , which Irony will call at the time of applying any of the rules associated with this non-terminal. This delegate should, on the basis of the passed ParseTreeNode create the corresponding AST node and put the link to it back in ParseTreeNode . By the time the delegate was called, all the Parse Tree child nodes were already processed and AstNodeCreator for them was already called, so we can use the already filled property AstNode child nodes in the delegate body.When we thus reach the root nonterminal, the AST root node is formed in its
AstNode , in our case the SqlQuery .For the grammar of arithmetic expressions above, AstNodeCreator might look like this:
var e = new NonTerminal("expression", delegate(AstContext context, ParseTreeNode node) { // E → number, if (node.ChildNodes.Count == 1) { node.AstNode = node.ChildNodes[0].Token.Value; return; } // E → E op E if (node.ChildNodes[0].AstNode != null && node.ChildNodes[2].AstNode != null) { node.AstNode = new BinaryOperator { Left = node.ChildNodes[0].AstNode, Operator = node.ChildNodes[1].FindTokenAndGetText(), Right = node.ChildNodes[2].AstNode }; return; } // node.AstNode = node.ChildNodes[1].AstNode; }); So, with the help of Irony, we learned how to construct an AST on an initial request. Only one big question remains - how to effectively structure the code for AST conversion, because ultimately we need to get an AST of the resulting SQL query from the source AST. The Visitor pattern will help us in this.
Visitor
The Visitor (or double dispatch ) pattern is one of the most complex in GoF and, therefore, one of the most rarely used. For our experience, we have seen only one active application of it - to convert various AST. A specific example is the ExpressionVisitor class in .NET, which inevitably occurs when you make a linq provider or just want to tweak a little with the compiler-generated expression tree .
What problem is solved by visitor?
The most natural and necessary thing that you often have to do when working with AST is to turn it into a string. Take for example our AST: after replacing Russian table names with English ones, generating
left join- and converting 1C-operators into database operators, we need to get a string at the output, which we can send for execution in PostgreSQL.A possible solution to this problem is as follows:
internal class SelectClause : ISqlElement { //... public void BuildSql(StringBuilder target) { target.Append("select "); for (var i = 0; i < Fields.Count; i++) { if (i != 0) target.Append(","); Fields[i].BuildSql(target); } target.Append("\r\nfrom "); From.BuildSql(target); foreach (var c in JoinClauses) { target.Append("\r\n"); c.BuildSql(target); } } } About this code, you can make two important observations:
- all tree nodes must have a
BuildSqlmethod for recursion to work; - The
BuildSqlmethod onSelectClausecallsBuildSqlon all child nodes.
Now consider another task. Suppose we need to add a condition for the equality of the
area field between the main table and all the others to get into the PostgreSQL indexes. To do this, we need to run through all the JoinClause in the query, but, given the possible subqueries, we need to remember to look at all the other nodes.This means that if you follow the same code structure as above, we will need to:
- add the
AddAreaToJoinClausemethod to all tree nodes; - its implementations on all nodes except
JoinClausewill have to forward a call to their descendants.
The problem with this approach is clear - the more we have different logical operations on the tree, the more there will be methods in the nodes, and the more copy-paste between these methods.
Visitors solve this problem by:
- Logical operations cease to be methods on nodes, and become separate objects — heirs of the abstract class
SqlVisitor(see figure below). - Each node type has a separate
Visitmethod in the baseSqlVisitor-, for example,VisitSelectClause(SelectClause clause)orVisitJoinClause(JoinClause clause). - The
BuildSqlandAddAreaToJoinClauseare replaced with one commonAcceptmethod. - Each node implements it by forwarding to the corresponding method on
SqlVisitor-, which comes as a parameter. - Specific operations are inherited from
SqlVisitorand override only those methods that interest them. - Implementations of the
Visitmethods in the baseSqlVisitor-simply call theVisitfor all child nodes, thereby eliminating duplication of code.
An example with serialization in SQL is adapted as follows:
internal interface ISqlElement { void Accept(SqlVisitor visitor); } internal class SqlVisitor { public virtual void Visit(ISqlElement sqlElement) { sqlElement.Accept(this); } public virtual void VisitSelectClause(SelectClause selectClause) { } //... } internal class SqlFormatter : SqlVisitor { private readonly StringBuilder target = new StringBuilder(); public override void VisitSelectClause(SelectClause selectClause) { target.Append("select "); for (var i = 0; i < selectClause.Fields.Count; i++) { if (i != 0) target.Append(","); Visit(selectClause.Fields[i]); } target.Append("\r\nfrom "); Visit(selectClause.Source); foreach (var c in selectClause.JoinClauses) { target.Append("\r\n"); Visit(c); } } } internal class SelectClause : ISqlElement { //... public void Accept(SqlVisitor visitor) { visitor.VisitSelectClause(this); } } The name double dispatch quite accurately describes this scheme:
- The first dispatch occurs in the
SqlVisitorclass when moving fromVisittoAccepton a specific node, at which point the type of the node becomes known. - The second dispatch follows the first one when moving from
Accepton a node to a specific method onSqlVisitor, here the operation that needs to be applied to the selected node becomes known.
Total
The article describes in detail the recipe for making the translator of the 1C query language into SQL queries. We went through experiments with regular expressions, having received a working prototype and confirmation that the piece is useful and should move on. And when it became impossible to look at the code without shame and pain, and juggling with regexp did not lead to the desired result, we took a serious step - we switched to AST and grammars. Then, using visitor, we learned how to transform AST, thereby realizing the logic of translation from one language to another.
It is worth noting that this path we did not go alone, and did not even have to open the Dragon Book . For parsing and building AST, we used the ready-made library of Irony, which made it possible not to reinvent the wheel, but to go straight to solving an applied problem.
The bottom line for the company is to reduce the speed of receiving data from 10 hours to 3 minutes. This allowed our analysts to quickly set up experiments and test hypotheses about the clients' business and the work of accountants. This is especially convenient, since we have a lot of clients, and their bases are distributed among the five physical PostgreSQL servers.
Summarizing all the above:
- Set experiments and get proof of concept as quickly and cheaply as possible.
- Set ambitious goals, and move towards them in small steps, gradually honing the instrument to the desired state.
- For most tasks, there is already a ready-made solution, or at least a foundation.
- Parsing and grammar are applicable in normal business applications.
- Solve a specific problem, and the general solution will come by itself.
Library code and usage examples are waiting for you on GitHub .
At leisure, we advise you to read:
Source: https://habr.com/ru/post/314030/
All Articles