Parsing JSON is a minefield

JSON is the de facto standard when it comes to (de) serialization, network data exchange and mobile development. But how well are you familiar with JSON? We all read specifications and write tests, test popular JSON libraries for our needs. I will show you that JSON is an idealized format, not an ideal one, as many people consider it. I have not found two libraries behaving the same way. Moreover, I found that extreme cases and harmful payloads can lead to bugs, crashes and DoS, mainly because JSON libraries are based on specifications that evolve over time, which leaves many things poorly or not documented at all.
Content
1. JSON specifications
2. Testing parsing
2.1. Structure
2.2. Numbers
2.3. Arrays
2.4. Objects
2.5. Strings
2.6. Dual RFC 7159 Values
3. Testing architecture
4. Test results
4.1. Full results
4.2. C-parsers
4.3. Objective-C parsers
4.4. Apple (NS) JSONSerialization
4.5. Freddy (Swift)
4.6. Bash json.sh
4.7. Other parsers
4.8. Json checker
4.9. Regular expressions
5. Content parsing
6. STJSON
7. Conclusion
8. Application
2. Testing parsing
2.1. Structure
2.2. Numbers
2.3. Arrays
2.4. Objects
2.5. Strings
2.6. Dual RFC 7159 Values
3. Testing architecture
4. Test results
4.1. Full results
4.2. C-parsers
4.3. Objective-C parsers
4.4. Apple (NS) JSONSerialization
4.5. Freddy (Swift)
4.6. Bash json.sh
4.7. Other parsers
4.8. Json checker
4.9. Regular expressions
5. Content parsing
6. STJSON
7. Conclusion
8. Application
1. JSON specifications
JSON is the de facto standard for serialization of data transmission over HTTP, lingua franca for exchanging data between heterogeneous applications in both web and mobile development.
')
In 2001, Douglas Crockford developed such a short and simple JSON specification that it gave rise to business cards, on the back of which they printed the full JSON grammar.

Almost all Internet users and programmers use JSON, but only a few really agreed on how JSON should work. The brevity of grammar leaves many aspects uncertain. In addition, there are several specifications and their muddy interpretations.
Crockford decided not to version JSON:
Probably, my most courageous design decision was the refusal to assign JSON number versions, so there is no mechanism for making changes. We are stuck with JSON: whatever its current form is, it’s just that.
In addition, JSON is defined in at least six different documents:
- 2002 - json.org and business cards.
- 2006 - IETF RFC 4627 , sets the application / json MIME environment type.
- 2011 - ECMAScript 262, section 15.12 .
- 2013 - ECMA 404 . According to Tim Bray (RFC 7159 editor), ECMA hurried with the release because:
Someone told the ECMA working group that IETF was crazy and was going to rewrite JSON without regard for compatibility and breakdown of the entire Internet, and something urgently needed to be done with this terrible situation. <...> This has nothing to do with complaints that affected the audit by the IETF.
- 2014 - IETF RFC 7158 . Creates a “Standard Tracks” specification instead of “Informational”; allows to use scalars (nothing but arrays and objects) like 123 and true at the root level, like ECMA; warns against using unsuccessful solutions like duplicate keys or broken Unicode strings, although it does not prohibit them explicitly.
- 2014 - IETF RFC 7159 . Released to correct typos in RFC 7158, which was dated March 2013 instead of March 2014.
Despite its clarity, RFC 7159 contains several assumptions and leaves a lot of poorly lit moments.
In particular, RFC 7159 mentions that the purpose of developing JSON was to create a “subset of JavaScript”, but in fact it is not. For example, JSON allows unescaped end of line characters from Unicode
U+2028 LINE SEPARATOR and U+2029 PARAGRAPH SEPARATOR . But the JavaScript specification states that string values cannot contain end-of-line characters ( ECMA-262 - 7.8.4 String Literals ), and generally these characters include U+2028 and U+2029 ( 7.3 Line Terminators ). The fact that these two characters can be used in JSON strings without escaping, and in JS they are not implied at all, suggests that JSON is not a subset of JavaScript, despite the stated development goals.Also, RFC 7159 does not clarify how a JSON parser should handle extreme numerical values (extreme number values), distorted Unicode strings, identical objects, or recursion depth. Some deadlock situations are clearly left without realizations, while others suffer from contradictory statements.
To illustrate the inaccuracy of RFC 7159, I wrote a collection of test JSON files and documented how specific JSON parsers handle them. Below you will see that it is not always easy to decide whether to parse this or that test file. In my research, I found that all parsers behave differently, and this can lead to serious compatibility issues.
2. Testing parsing
Next, I will explain how to create test files to check the behavior of parsers, talk about some interesting tests and substantively, should parsers that meet RFC 7159 criteria accept or reject files — or decide for themselves.
File names begin with a letter that indicates the expected result:
y(yes) - successful parsing;n(no) - parsing error;i(implementation) - depends on the implementation.
Also from the files it will be clear which component of the parser has been tested.
For example,
n_string_unescaped_tab.json contains ["09"] - this is an array with a string that includes the TAB 0x09 character, which MUST be escaped (u-escaped) according to JSON specifications. The file tests string parsing, so the name contains a string , not a structure , array or object . According to RFC 7159, this is an invalid string value, so n appears in the file name.Notice that some parsers do not allow scalars at the top level (
"test" ), so I embedded strings in arrays ( ["test"] ).More than 300 test files can be found in the JSONTestSuite repository.
Most of the files I did manually as I read the specifications, trying to pay attention to extreme situations and ambiguous points. I also tried to use developments from other people's test suites found on the Internet (mostly json-test-suite and JSON Checker ), but I found that most of them cover only basic situations.
Finally, I generated JSON files using American Fuzzy Lop fuzzing software. Then I removed redundant tests that lead to the same result, and then reduced the number of remaining ones to get the smallest number of characters that produce results (see section 3 ).
2.1. Structure
Scalars - it is obvious that it is necessary to parse scalars like 123 or “asd”. In practice, many popular parsers still implement RFC 4627 and will not parse single values. Thus, there are basic tests, for example:
y_structure_lonely_string.json "asd" Trailing commas , for example
[123,] or {"a":1,} , are not part of the grammar, so such files should not pass tests, right? But the fact is that RFC 7159 allows parsers to support "extensions" ( section 9 ), although no explanation is given about them. In practice, trailing commas are a common extension. Since this is not part of the JSON grammar, parsers are not required to support them, so file names begin with n. n_object_trailing_comma.json {"id":0,} n_object_several_trailing_commas.json {"id":0,,,,,} Comments are also not part of the grammar. Crockford removed them from earlier specifications. But this is another common extension. Some parsers allow the use of comments that close
[1]//xxx or even embedded [1,/*xxx*/2] . y_string_comments.json ["a/*b*/c/*d//e"] n_object_trailing_comment.json {"a":"b"}/**/ n_structure_object_with_comment.json {"a":/*comment*/"b"} Unclosed structures . Tests cover all situations where there are open and not closed (or vice versa) structures, for example
[ or [1,{,3] . Obviously, this is a mistake and the tests should not be passed. n_structure_object_unclosed_no_value.json {"": n_structure_object_followed_by_closing_object.json {}} Nested structures. Structures sometimes contain other structures, arrays - other arrays. The first element can be an array, whose first element is also an array, and so on, like a doll
[[[[[]]]]] . RFC 7159 allows parsers to set limits on the maximum nesting depth ( section 9 ).Several parsers do not limit the depth and at some point just fall. For example, Xcode will crash if you open a .json file containing a thousand characters
[ . This is probably because the selector of syntax elements JSON does not implement the depth limit. $ python -c "print('['*100000)" > ~/x.json $ ./Xcode ~/x.json Segmentation fault: 11 Spaces Grammar RFC 7159 allows using
0x20 (space), 0x09 (tabulation), 0x0A (line feed) and 0x0D (carriage return) as their quality. Spaces are allowed before and after structural characters []{}:, . So 20[090A]0D will pass the tests. Conversely, the file will not pass the tests if we include all kinds of spaces that are not explicitly allowed, for example, input form 0x0C or [E281A0] - UTF-8 designation for the word connector U+2060 WORD JOINER . n_structure_whitespace_formfeed.json [0C] n_structure_whitespace_U+2060_word_joiner.json [E281A0] n_structure_no_data.json 2.2. Numbers
NaN and Infinity. Strings describing special numbers like
NaN or Infinity are not part of the JSON grammar. But some parsers accept them, regarding them as “extensions” ( section 9 ). In the test files, the negative forms -NaN and -Infinity are also checked. n_number_NaN.json [NaN] n_number_minus_infinity.json [-Infinity] Hexadecimal numbers - RFC 7159 does not allow their use. Tests contain numbers like
0xFF , and such files should not be parsed. n_number_hex_2_digits.json [0x42] Range and accuracy - and what about numbers from a huge number of numbers? According to RFC 7159, “the JSON parser MUST accept all sorts of text that conforms to the JSON grammar” ( Chapter 9 ). But the same paragraph says: "The implementation may limit the range and accuracy of numbers." So it is not clear to me whether the parsers can generate an error when they encounter values like
1e9999 or 0.0000000000000000000000000000001 . y_number_very_big_negative_int.json [-237462374673276894279832(...) Exponential representations — parsing them can be a surprisingly difficult task (see the results chapter). There are also valid (
[0E0] , [0e+1] ), and [0E0] valid variants ( [1.0e+] , [0E] and [1eE2] ). n_number_0_capital_E+.json [0E+] n_number_.2e-3.json [.2e-3] y_number_double_huge_neg_exp.json [123.456e-789] 2.3. Arrays
Most of the extreme situations associated with arrays are problems with opening / closing and restricting nesting. They are discussed in section 2.1 (Structures) . Tests will pass
[[] and [[[]]] , but will not pass ] or [[]]] . n_array_comma_and_number.json [,1] n_array_colon_instead_of_comma.json ["": 1] n_array_unclosed_with_new_lines.json [1,0A10A,1 2.4. Objects
Duplicate keys . Section 4 of RFC 7159 states: “There must be unique names within the object”. This does not prevent parsing of objects in which one key appears several times
{"a":1,"a":2} , but allows parsers to decide for themselves what to do in such cases. Section 4 even mentions that “[some] implementations report an error or failure while parsing an object”, without specifying whether the parsing failure corresponds to the RFC provisions, especially this : “The JSON parser MUST accept all kinds of texts corresponding to the JSON grammar ".Variants of such special cases include the same key: the same value
{"a":1,"a":1} , as well as keys or values whose sameness depends on how the strings are compared. For example, the keys may be different in binary expression, but equivalent in accordance with the normalization of Inicode NFC: {"C3A9:"NFC","65CC81":"NFD"} , here both keys denote" é ". Also included in the tests is {"a":0,"a":-0} . y_object_empty_key.json {"":0} y_object_duplicated_key_and_value.json {"a":"b","a":"b"} n_object_double_colon.json {"x"::"b"} n_object_key_with_single_quotes.json {key: 'value'} n_object_missing_key.json {:"b"} n_object_non_string_key.json {1:1} 2.5. Strings
File encoding “JSON text MUST be UTF-8, UTF-16 or UTF-32 encoded. The default is UTF-8 ”( section 8.1 ).
So for passing the tests one of the three encodings is needed. Texts in UTF-16 and UTF-32 must also contain older and minor versions.
Failure tests include ISO-Latin-1 encoded strings.
y_string_utf16.json FFFE[00"00E900"00]00 n_string_iso_latin_1.json ["E9"] Byte Order Marker. Although section 8.1 states: "Implementations MUST NOT add a byte sequence marker to the beginning of JSON text," then we see: "Implementations ... MAY ignore the presence of a marker, and not treat it as an error."
Failure tests include only marks in UTF-8 encoding, without other content. Tests whose implementation-dependent results include a UTF-8 BOM with a UTF-8 string, as well as a UTF-8 BOM with a UTF-16 string and a UTF-16 BOM with a UTF-8 string.
n_structure_UTF8_BOM_no_data.json EFBBBF n_structure_incomplete_UTF8_BOM.json EFBB{} i_structure_UTF-8_BOM_empty_object.json EFBBBF{} Control characters should be isolated and defined as
U+0000 as U+001F ( section 7 ). This does not include the 0x7F DEL character, which may be part of other control character definitions (see section 4.6, Bash JSON.sh). Therefore, the tests must pass ["7F"] . n_string_unescaped_ctrl_char.json ["a\09a"] y_string_unescaped_char_delete.json ["7F"] n_string_escape_x.json ["\x00"] Screening. “All characters can be escaped” ( Section 7 ), for example, \ uXXXX. But some — quotes, backslashes, and escape characters — MUST be escaped. The failures tests include shielded characters with no shielded values or with values with incomplete shielding. Examples:
["\"] , ["\ , [\ . y_string_allowed_escapes.json ["\"\\/\b\f\n\r\t"] n_structure_bad_escape.json ["\ The shielding symbol can be used to represent code points (codepoints) at a basic multilingual level (Basic Multilingual Plane, BMP) (
\u005C ). Successful tests include a zero character ( \u0000 zero), which can lead to problems in the C parsers. Failure tests include the capital U \U005C , non-hexadecimal shielded values \u123Z and values with incomplete shielding \u123 . y_string_backslash_and_u_escaped_zero.json ["\u0000"] n_string_invalid_unicode_escape.json ["\uqqqq"] n_string_incomplete_escaped_character.json ["\u00A"] Non-Unicode escapes
Code points outside BMP are represented by shielded UTF-16 encodings:
+1D11E becomes \uD834\uDD1E . Successful tests include single substitutes, since they are valid from the point of view of JSON grammar. A typo 3984 in RFC 7159 gave rise to the problem of grammatically correct shielded code points that are not Unicode characters ( \uDEAD ), or non-characters from U+FDD0 to U+10FFFE .At the same time, the augmented Backus - Naur form (ABNF, Augmented Backus - Naur form ) does not allow the use of non-Unicode code points (section 7) and requires Unicode compliance (section 1).
The editors decided that the grammar should not be limited and that it was enough to warn users about the "unpredictability" ( RFC 7159, section 8.2 ) of the behavior of the parsers. In other words, parsers MUST parse u-screened non-characters, but the result is unpredictable. In such cases, the file names begin with the prefix
i_ (depends on the implementation). According to the Unicode standard, invalid code points must be replaced with the U+FFFD REPLACEMENT CHARACTER replacement character. If you have already experienced the complexity of Unicode , then you will not be surprised that the replacement is optional and can be done in different ways (see Unicode PR # 121: Recommended Techniques for Replacement Characters ). Therefore, some parsers use replacement characters, while others leave a shielded form or generate a non-Unicode character (see Section 5 - Parsing Content ). y_string_accepted_surrogate_pair.json ["\uD801\udc37"] n_string_incomplete_escaped_character.json ["\u00A"] i_string_incomplete_surrogates_escape_valid.json ["\uD800\uD800\n"] i_string_lone_second_surrogate.json ["\uDFAA"] i_string_1st_valid_surrogate_2nd_invalid.json ["\uD888\u1234"] i_string_inverted_surrogates_U+1D11E.json ["\uDd1e\uD834"] Non Raw Unicode Characters
In the previous section, we discussed non-Unicode code points appearing in strings (
\uDEAD ). These points are valid Unicode in u-shielded form, but are not decoded into Unicode characters.Parsers must also handle regular bytes that do not encode Unicode characters. For example, in UTF-8 bytes, the FF is not a Unicode character. Therefore, the string value containing FF is not a UTF-8 encoded string. In this case, the parser should simply refuse to parse it, because “String value is a sequence of Unicode characters in the amount of zero or more” ( RFC 7159, section 1 ) and “JSON text MUST be represented in Unicode” ( RFC 7159 section 8.1 ).
y_string_utf8.json ["€?"] n_string_invalid_utf-8.json ["FF"] n_array_invalid_utf8.json [FF] Ambiguities RFC 7159
In addition to the specific cases that we considered, it is almost impossible to determine whether the parser meets the requirements of RFC 7159, because of what was said in section 9 :
The JSON parser MUST accept all texts corresponding to the JSON grammar. The JSON parser MAY accept non-JSON forms or extensions.
While everything is clear. All grammatically correct input data MUST be parsed, and the parsers can decide whether to accept other content.
Implementations may limit:
- the size of the received text;
- maximum depth of nesting;
- range and accuracy of numbers;
- the length of the string values and their character set.
All these restrictions sound reasonable (with the possible exception of symbols), but contradict the word "MUST" from the previous quotation. RFC 2119 explains its meaning very clearly:
SHOULD. This word, like “REQUIRED” or “FOLLOWS”, means a mandatory specification requirement.
RFC 7159 is restrictive, but does not specify minimum requirements. Therefore, technically, a parser that cannot parse a string longer than three characters still meets the requirements of RFC 7159.
In addition, section 9 of RFC 7159 requires parsers to clearly document restrictions and / or allow the use of custom configurations. But these configurations can lead to compatibility issues, so it’s best to stay with minimum requirements.
Such a lack of specifics against the allowable restrictions practically does not allow one to say for sure whether the RFC 7159 parser matches. After all, you can parse content that does not correspond to grammar (these are “extensions”) and reject content that corresponds to grammar (these are “limitations” of the parser).
3. Testing architecture
I wanted to see how the parsers actually behave, regardless of how they should behave. Therefore, I chose several JSON parsers and set everything up so that I could feed my test files to it.
As a Cocoa developer, most parsers are written in Swift and Objective-C. But there are quite arbitrarily chosen parsers in C, Python, Ruby, R, Lua, Perl, Bash and Rust. Basically, I tried to cover a variety of age and popularity languages.
Some parsers allow you to strengthen or weaken the severity of restrictions, customize Unicode support, or use specific extensions. I wanted to always configure parsers to work as close as possible to the most rigorous interpretation of RFC 7159.
The
run_tests.py Python script run_tests.py each test file through each parser (or a single test if the file is passed as an argument). Usually the parsers were wrappers and returned 0 if successful and 1 if parsing failed. A separate status was provided for the fall of the parser, as well as a timeout of 5 seconds. In fact, I turned JSON parsers into JSON validators.run_tests.py compared the return value for each test with the expected result, reflected in the prefix of the file name. If they did not match or when the prefix was i (depends on the implementation), run_tests.py recorded in a log ( results/logs.txt ) a string of a certain format: Python 2.7.10 SHOULD_HAVE_FAILED n_number_infinity.json 
Then
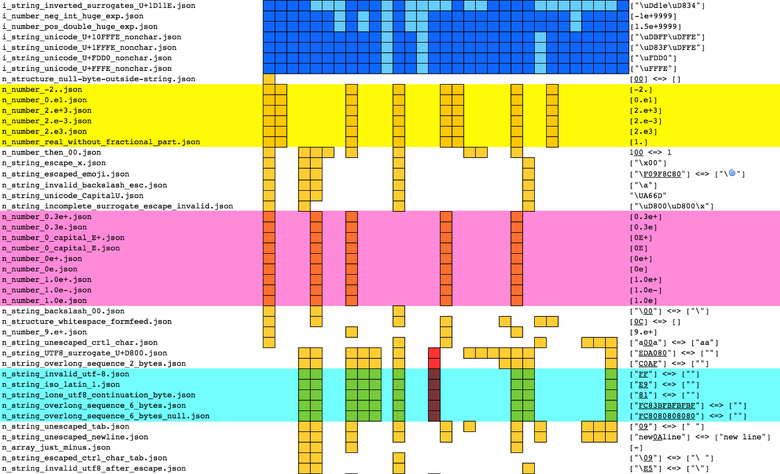
run_tests.py read the log and generated HTML tables with the results ( results/parsing.html ).Each line contains the results for one of the files. Parsers are presented in columns. For different results, different cell fill colors are provided:

Tests are sorted by results. This makes it easier to find similar results and remove redundant ones.
4. Results and comments
4.1. Full results
Full test results can be found here: seriot.ch/json/parsing.html . Tests are sorted by similarity of results. In
run_tests.py there is an option that allows you to display “abbreviated results” (pruned results): when a test suite gives the same results, only the first test is saved. The abbreviated file is available here: www.seriot.ch/json/parsing_pruned.html .Falling (red color) is the most serious problem, since parsing uncontrolled input data puts the entire process at risk. The tests “expected successful execution” (brown color) are also very dangerous: uncontrolled input data can prevent you from sending the entire document. The tests “expected to fail” (yellow color) are less dangerous. They talk about "extensions" that cannot be parsed. So everything will work until the parser is replaced by another one who cannot parse these “extensions”.

Then I will review and comment on the most remarkable results.
4.2. C-parsers
I chose five C-parsers:
- github.com/zserge/jsmn
- github.com/akheron/jansson
- github.com/rustyrussell/ccan
- github.com/DaveGamble/cJSON
- github.com/udp/json-parser
Short comparative table:

More details can be found in the full results table.
4.3. Objective-C parsers
I chose three Objective-C parsers that were very popular in the early days of iOS development, especially because Apple did not release NSJSONSerialization before iOS 5. All three parsers were interesting to test, since they were used in the development of many applications.
Short comparative table:
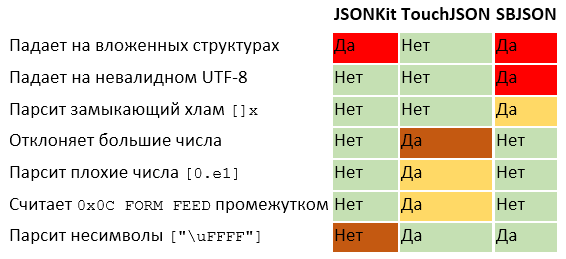
SBJSON survived after the appearance of the NSJSONSerialization, it is still supported, you can download it through CocoaPods. Therefore, in application # 219, I recorded a crash when the parsley is not a UTF-8 line like [“FF”].
*** Assertion failure in -[SBJson4Parser parserFound:isValue:], SBJson4Parser.m:150 *** Terminating app due to uncaught exception 'NSInternalInconsistencyException', reason: 'Invalid parameter not satisfying: obj' *** First throw call stack: ( 0 CoreFoundation 0x00007fff95f4b4f2 __exceptionPreprocess + 178 1 libobjc.A.dylib 0x00007fff9783bf7e objc_exception_throw + 48 2 CoreFoundation 0x00007fff95f501ca +[NSException raise:format:arguments:] + 106 3 Foundation 0x00007fff9ce86856 -[NSAssertionHandler handleFailureInMethod:object:file:lineNumber:description:] + 198 4 test_SBJSON 0x00000001000067e5 -[SBJson4Parser parserFound:isValue:] + 309 5 test_SBJSON 0x00000001000073f3 -[SBJson4Parser parserFoundString:] + 67 6 test_SBJSON 0x0000000100004289 -[SBJson4StreamParser parse:] + 2377 7 test_SBJSON 0x0000000100007989 -[SBJson4Parser parse:] + 73 8 test_SBJSON 0x0000000100005d0d main + 221 9 libdyld.dylib 0x00007fff929ea5ad start + 1 ) libc++abi.dylib: terminating with uncaught exception of type NSException 4.4. Apple (NS)JSONSerialization
developer.apple.com/reference/foundation/nsjsonserialization
NSJSONSerialization iOS 5, JSON- OS X iOS. Objective-C Swift: NSJSONSerialization.swift . Swift 3 NS .
JSONSerialization :
- :
[123123e100000] - u- :
["\ud800"]
JSONSerialization :
- :
[1,]{"a":0,}
, , . .
JSON-, JSON-. , , JSONSerialization
Double.nan . , NaN JSON, JSONSerialization , . do { let a = [Double.nan] let data = try JSONSerialization.data(withJSONObject: a, options: []) } catch let e { } SIGABRT *** Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: 'Invalid number value (NaN) in JSON write' 4.5. Freddy (Swift)
Freddy (https://github.com/bignerdranch/Freddy) — JSON-, Swift 3. «», GitHub- Swift JSON-, Apple JSONSerialization JSON- -.
Freddy , Cocoa- Swift Swift- JSON- (Array, Dictionary, Double, Int, String, Bool Null).
Freddy 2016- , . ,
[1 , {"a": , " ". #199 , !,
"0e1" , #198 , .18 Freddy
[" \ . #206 .Freddy:

4.6. Bash JSON.sh
github.com/dominictarr/JSON.sh , 12 2016 .
Bash- , , RFC 7159, . Bash JSON , .
:cntlr: . [\x00-\x1F\x7F] . JSON 0x7F DEL . 00 nul 01 soh 02 stx 03 etx 04 eot 05 enq 06 ack 07 bel 08 bs 09 ht 0a nl 0b vt 0c np 0d cr 0e so 0f si 10 dle 11 dc1 12 dc2 13 dc3 14 dc4 15 nak 16 syn 17 etb 18 can 19 em 1a sub 1b esc 1c fs 1d gs 1e rs 1f us 20 sp 21 ! 22 " 23 # 24 $ 25 % 26 & 27 ' 28 ( 29 ) 2a * 2b + 2c , 2d — 2e . 2f / 30 0 31 1 32 2 33 3 34 4 35 5 36 6 37 7 38 8 39 9 3a : 3b ; 3c < 3d = 3e > 3f ? 40 @ 41 A 42 B 43 C 44 D 45 E 46 F 47 G 48 H 49 I 4a J 4b K 4c L 4d M 4e N 4f O 50 P 51 Q 52 R 53 S 54 T 55 U 56 V 57 W 58 X 59 Y 5a Z 5b [ 5c \ 5d ] 5e ^ 5f _ 60 ` 61 a 62 b 63 c 64 d 65 e 66 f 67 g 68 h 69 i 6a j 6b k 6c l 6d m 6e n 6f o 70 p 71 q 72 r 73 s 74 t 75 u 76 v 77 w 78 x 79 y 7a z 7b { 7c | 7d } 7e ~ 7f del JSON.sh
["7F"] . . JSON.sh 10 000 [. . $ python -c "print('['*100000)" | ./JSON.sh ./JSON.sh: line 206: 40694 Done tokenize 40695 Segmentation fault: 11 | parse 4.7.
C / Objective-C Swift, . . , , , .
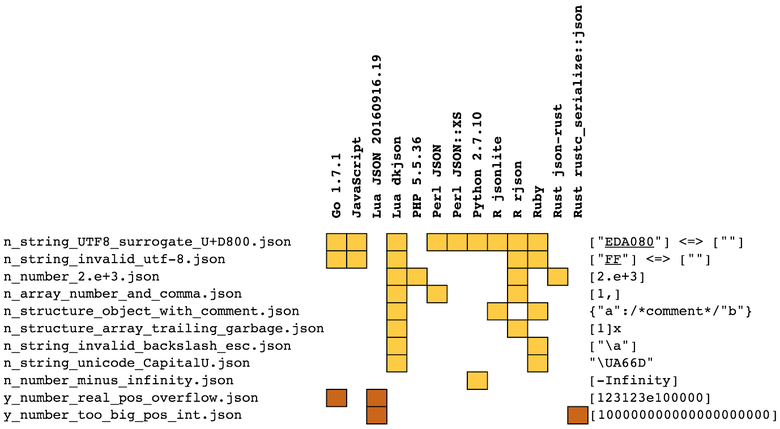
:
- Lua JSON 20160728.17 regex.info/blog/lua/json ( )
- Lua dkjson 2.5.1 github.com/LuaDist/dkjson
- Go 1.7.1, json mobule golang.org/pkg/encoding/json
- Python 2.7.10, json module docs.python.org/2.7/library/json.html
- JavaScript, macOS 10.12
- Perl JSON metacpan.org/pod/JSON
- Perl JSON::XS metacpan.org/pod/JSON ::XS
- PHP 5.6.24, macOS 10.12
- R rjson cran.r-project.org/web/packages/rjson/index.html
- R jsonlite github.com/jeroenooms/jsonlite
- Rust json-rust github.com/maciejhirsz/json-rust
- Rust rustc_serialize::json doc.rust-lang.org/rustc-serialize/rustc_serialize/json
Java-, , :
- Java Gson 2.7 github.com/google/gson
- Java Jackson 2.8.4 github.com/FasterXML/jackson
- Java Simple JSON 1.1.1 code.google.com/archive/p/json-simple
JSON- Python
NaN -Infinity . , parse_constant , , . , . def f_parse_constant(o): raise ValueError o = json.loads(data, parse_constant=f_parse_constant) 4.8. JSON Checker
JSON- JSON- . JSON, .
, JSON. — JSON-.
JSON_Checker. www.json.org/JSON_checker , ():
JSON_Checker — pushdown automaton , JSON-. . JSON_Checker JSON-.
JSON_Checker , , JSON- .
, JSON_Checker , . ,
[1.] , [0.e1] , JSON., JSON_Checker
[0e1] , JSON-. , - 0e1 .JSON_Checker pushdown automaton , , , .

1: 0e1 .
ZE , 0 , E1 e E . , .2: [1.] . ,
0. , . , 1. , .JSON_Checker
FR , . , FR F0 frac0 . 1. .
(Obj-C TouchJSON, PHP, R rjson, Rust json-rust, Bash JSON.sh, C jsmn Lua dkjson)
[1.] . JSON_Checker? , json.org.4.9.
JSON? , , . , , .
StackOverflow Ruby JSON :
JSON_VALIDATOR_RE = /( # define subtypes and build up the json syntax, BNF-grammar-style # The {0} is a hack to simply define them as named groups here but not match on them yet # I added some atomic grouping to prevent catastrophic backtracking on invalid inputs (?<number> -?(?=[1-9]|0(?!\d))\d+(\.\d+)?([eE][+-]?\d+)?){0} (?<boolean> true | false | null ){0} (?<string> " (?>[^"\\\\]* | \\\\ ["\\\\bfnrt\/] | \\\\ u [0-9a-f]{4} )* " ){0} (?<array> \[ (?> \g<json> (?: , \g<json> )* )? \s* \] ){0} (?<pair> \s* \g<string> \s* : \g<json> ){0} (?<object> \{ (?> \g<pair> (?: , \g<pair> )* )? \s* \} ){0} (?<json> \s* (?> \g<number> | \g<boolean> | \g<string> | \g<array> | \g<object> ) \s* ){0} ) \A \g<json> \Z /uix JSON, :
- u- , :
["\u002c"] - , :
["\\a"]
( JSON-):
- True :
[True] - :
["09"]
5.
RFC 7159 ( 9) :
JSON- JSON- .
, JSON-, .
, u- Unicode- (
"\uDEAD" ), ? - ? RFC 7159 .0.00000000000000000000001 -0 ? , ? RFC 7159 0 –0. , ., (
{"a":1,"a":2} )? ( {"a":1,"a":1} )? ? Unicode-, NFC? RFC .. — (, , JSON- ).
, . , . , . (log statements) / .
. « ».
1.0000000000000000051.0, Rust 1.12.0 / json 0.10.21.0000000000000000051E-999(double)0.0, Freddy"1E-999". Swift Apple JSONSerializattion Obj-C JSONKit .10000000000000000999(Swift Apple JSONSerialization), unsigned long long (Objective-C JSONKit) (Swift Freddy). , cJSON ,10000000000000002048( ).
- {
"C3A9:"NFC","65CC81":"NFD"} NFC- NFD- "é". , Apple JSONSerialization Freddy, . {"a":1,"a":2}{"a":2}(Freddy, SBJSON, Go, Python, JavaScript, Ruby, Rust, Lua dksjon),{"a":1}(Obj-C Apple NSJSONSerialization, Swift Apple JSONSerialization, Swift Freddy){"a":1,"a":2}(cJSON, R, Lua JSON).{"a":1,"a":1}{"a":1}, cJSON, R Lua JSON{"a":1,"a":1}.{"a":0,"a":-0}{"a":0},{"a":-0}(Obj-C JSONKit, Go, JavaScript, Lua){"a":0, "a":0}(cJSON, R).
["A\u0000B"]u-0x00 NUL, C-. (gracefully), JSONKit cJSON . , Freddy["A"]( 0x00).["\uD800"]u-U+D800, UTF-16. , JSON. Python["\uD800"]. Go JavaScript " "U+FFFD REPLACEMENT CHARACTER ["EFBFBD"], R rjson Lua dkjson UTF-8["EDA080"]. R jsonlite Lua JSON 20160728.17["?"].["EDA080"]U+D800, UTF-16, . UTF-8 (. 2.5. — Unicode- ). , cJSON, R rjson jsonlite, Lua JSON, Lua dkjson Ruby,["EDA080"]. Go JavaScript["EFBFBDEFBFBDEFBFBD"], ( ). Python 2 Unicode-["\ud800"], Python 3UnicodeDecodeError.["\uD800\uD800"]. R jsonlite["\U00010000"], Ruby- —["F0908080"].
6. STJSON
STJSON — JSON-, Swift 3 600+ . , , .
github.com/nst/STJSON
STJSON API :
var p = STJSONParser(data: data) do { let o = try p.parse() print(o) } catch let e { print(e) } STJSON :
var p = STJSON(data:data, maxParserDepth:1024, options:[.useUnicodeReplacementCharacter]) :
y_string_utf16.json . , , , STJSON UTF-8 , , , , . STJSON , UTF-16 UTF-32.7.
JSON — , . , :
, , json_checker.c json.org JSON
[0e1] ( 4.24 ), , , . ( ) , , , .JSON- ( 6 ), JSON- RFC 7159. , pull request'.
:
- , , Apple-, Json.Net .
- JSON . , , ( 4 ). , ( 5 ). , - JSON (. 4.2.1 ).
- , JSON- JSON- -.
- (. Unicode Hacks ).
- , YAML, BSON ProtoBuf , JSON. Apple Swift- github.com/apple/swift-protobuf-plugin .
, «» HTML, CSS JSON «» PHP JavaScript . , , , , - , . .
8.
- seriot.ch/json/parsing.html , 4 .
- seriot.ch/json/transform.html , 6 .
- JSON github.com/nst/JSONTestSuite , .
- STJSON github.com/nst/STJSON , , Swift 3.
Source: https://habr.com/ru/post/314014/
All Articles