High availability cluster on postgresql 9.6 + repmgr + pgbouncer + haproxy + keepalived + control via telegram
To date, the implementation procedure for “failover” in Postgresql is one of the most simple and intuitive. To implement it, you need to decide on file server scripts - this is the key to successful cluster operation, to test its operation. In a nutshell - replication is configured, usually asynchronous, and in case of failure of the current master, the other node (standby) becomes the current “master”, the other standby nodes begin to follow the new master.
Today, repmgr supports the automatic Failover - autofailover script, which allows you to maintain the cluster in working condition after a master node fails without an immediate employee intervention, which is important, since there is no big UPTIME crash. For notifications we use telegram.
There is a need in connection with the development of internal services to implement the database storage system on Postgresql + replication + balancing + failover. As always, the Internet seems to be something, but everything is outdated or not practical in practice in the form in which it is presented. It was decided to present this solution so that in the future specialists who decided to implement such a scheme had an idea of how this is done, and that it was easy for newcomers to follow this instruction. We tried to describe everything as detailed as possible, to grasp all the nuances and peculiarities.
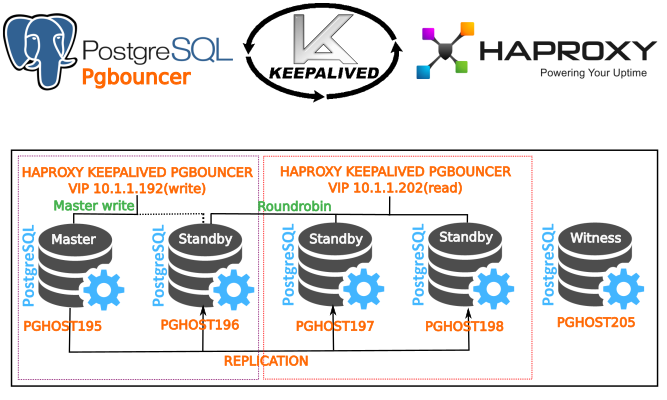
So, what we have: 5 VM with debian 8, Postgresql 9.6 + repmgr (for cluster management), balancing and HA based on HAPROXY (software for balancing and high availability of web applications and databases) and lightweight connection manager Pgbouncer, keepalived for ip address migration (VIP) between nodes, the 5th witness node to control the cluster and prevent the “split brain” situations when the next master node could not be determined after the failure of the current master. Notifications via telegram (without it as without hands).
')
Let's write the nodes / etc / hosts - for convenience, since everything will operate with domain names in the future.
file / etc / hosts
10.1.1.195 - pghost195 10.1.1.196 - pghost196 10.1.1.197 - pghost197 10.1.1.198 - pghost198 10.1.1.205 - pghost205 VIP 10.1.1.192 - write, 10.1.1.202 - roundrobin (balancing / read only).
Installing Postgresql 9.6 pgbouncer haproxy repmgr
We put on all nodes
Installing Postgresql-9.6 and repmgr debian 8
touch /etc/apt/sources.list.d/pgdg.list echo “deb http://apt.postgresql.org/pub/repos/apt/ jessie-pgdg main” > /etc/apt/sources.list.d/pgdg.list wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | apt-key add - apt-get update wget http://ftp.ru.debian.org/debian/pool/main/p/pkg-config/pkg-config_0.28-1_amd64.deb dpkg -i pkg-config_0.28-1_amd64.deb apt-get install postgresql-9.6-repmgr libevent-dev -y Turning off Postgresql autorun at system startup - all processes will be controlled by the postgres user. It is also necessary in order to avoid situations where we can have two master nodes, after restoring one after a power failure, for example.
How to disable autorun
nano /etc/postgresql/9.6/main/start.conf auto manual We will also use chkconfig to control and manage autorun.
Install chkconfig
apt-get install chkconfig -y Watch autorun
Hidden text
/sbin/chkconfig --list Disable
Hidden text
update-rc.d postgresql disable We look postgresql now
Hidden text
/sbin/chkconfig --list postgresql Is done. We go further.
Configuring ssh connection without password - between all nodes (we do on all servers)
Set up connections between all servers and to yourself through the postgres user (repmgr is also connected via the postgres user).
Install the packages that we need to work (immediately set)
We put ssh and rsync
apt-get install openssh-server rsync -y To begin with we will install to it the local password for postgres (we will immediately do it on all nodes).
Hidden text
passwd postgres We introduce a new password.
OK.
Next, configure the ssh connection
Hidden text
su postgres cd ~ ssh-keygen We generate a key - without a password.
Put the key to other nodes
Hidden text
ssh-copy-id -i ~/.ssh/id_rsa.pub postgres@pghost195 ssh-copy-id -i ~/.ssh/id_rsa.pub postgres@pghost196 ssh-copy-id -i ~/.ssh/id_rsa.pub postgres@pghost197 ssh-copy-id -i ~/.ssh/id_rsa.pub postgres@pghost198 ssh-copy-id -i ~/.ssh/id_rsa.pub postgres@pghost205 In order for ssh not to ask whether you trust the host and do not issue other warnings and restrictions regarding security policy, we can add to the file
Hidden text
nano /etc/ssh/ssh_config StrictHostKeyChecking no UserKnownHostsFile=/dev/null Restart ssh. This option is convenient when you do not care too much about security, for example, to test the cluster.
Let's go to node 2,3,4 and repeat everything. Now we can walk without passwords between the nodes to switch their status (assignment of a new master and standby).
We put pgbouncer from git
Install the necessary packages for assembly
Hidden text
apt-get install libpq-dev checkinstall build-essential libpam0g-dev libssl-dev libpcre++-dev libtool automake checkinstall gcc+ git -y cd /tmp git clone https://github.com/pgbouncer/pgbouncer.git cd pgbouncer git submodule init git submodule update ./autogen.sh wget https://github.com/libevent/libevent/releases/download/release-2.0.22-stable/libevent-2.0.22-stable.tar.gz tar -xvf libevent-2.0.22-stable.tar.gz cd libevent* ./configure checkinstall cd .. If you want postgresql with PAM authorization, then we put the module still at home and with configure we set --with-pam
Hidden text
./configure --prefix=/usr/local --with-libevent=libevent-prefix --with-pam make -j4 mkdir -p /usr/local/share/doc; mkdir -p /usr/local/share/man; checkinstall We put the version - 1.7.2 (as of November 2016).
Is done. We see
Hidden text
Done. The new package has been installed and saved to /tmp/pgbouncer/pgbouncer_1.7.2-1_amd64.deb You can remove it from your system anytime using: dpkg -r pgbouncer_1.7.2-1_amd64.deb Be sure to configure the environment - add the variable PATH = / usr / lib / postgresql / 9.6 / bin: $ PATH (on each node).
Add to ~ / .bashrc
Hidden text
su postgres cd ~ nano .bashrc Paste the code
Hidden text
PATH=$PATH:/usr/lib/postgresql/9.6/bin export PATH export PGDATA="$HOME/9.6/main" Keep it up
Copy the file to .bashrc other nodes
Hidden text
su postgres cd ~ scp .bashrc postgres@pghost195:/var/lib/postgresql scp .bashrc postgres@pghost196:/var/lib/postgresql scp .bashrc postgres@pghost197:/var/lib/postgresql scp .bashrc postgres@pghost198:/var/lib/postgresql scp .bashrc postgres@pghost205:/var/lib/postgresql Setting up a server as a wizard (pghost195)
Let's edit the config /etc/postgresql/9.6/main/postgresql.conf - Make the necessary options appear (just add to the end of the file).
Hidden text
listen_addresses='*' wal_level = 'hot_standby' archive_mode = on wal_log_hints = on wal_keep_segments = 0 archive_command = 'cd .' max_replication_slots = 5 # standby , . hot_standby = on shared_preload_libraries = 'repmgr_funcs, pg_stat_statements' #### repmgr postgres max_connections = 800 max_wal_senders = 10# port = 5433 pg_stat_statements.max = 10000 pg_stat_statements.track = all As we can see, we will run postgresql on port 5433, because we will use the default port for applications for other purposes - namely, for balancing, proxying, and failover. You can use any port as you wish.
Configure the connection file
nano /etc/postgresql/9.6/main/pg_hba.conf
Let's bring to mind
Hidden text
# IPv6 local connections: host all all ::1/128 md5 local all postgres peer local all all peer host all all 127.0.0.1/32 md5 ####################################### (MASTER, STAND BY). local replication repmgr trust host replication repmgr 127.0.0.1/32 trust host replication repmgr 10.1.1.0/24 trust local repmgr repmgr trust host repmgr repmgr 127.0.0.1/32 trust host repmgr repmgr 10.1.1.0/24 trust ###################################### host all all 0.0.0.0/32 md5 ####### ##################################### Let's apply the rights to the configs, otherwise it will swear at pg_hba.conf
Hidden text
chown -R -v postgres /etc/postgresql We start postgres (from postgres user).
Hidden text
pg_ctl -D /etc/postgresql/9.6/main --log=/var/log/postgresql/postgres_screen.log start Setting up users and databases on the master server (pghost195).
Hidden text
su postgres cd ~ Create a user repmgr.
Hidden text
psql # create role repmgr with superuser noinherit; # ALTER ROLE repmgr WITH LOGIN; # create database repmgr; # GRANT ALL PRIVILEGES on DATABASE repmgr to repmgr; # ALTER USER repmgr SET search_path TO repmgr_test, "$user", public; Create user test_user with password 1234
Hidden text
create user test_user; ALTER USER test_user WITH PASSWORD '1234'; Configuring repmgr on master
Hidden text
nano /etc/repmgr.conf Content
Hidden text
cluster=etagi_test node=1 node_name=node1 use_replication_slots=1 conninfo='host=pghost195 port=5433 user=repmgr dbname=repmgr' pg_bindir=/usr/lib/postgresql/9.6/bin Persist.
Register the server as a master.
Hidden text
su postgres repmgr -f /etc/repmgr.conf master register See our status
Hidden text
repmgr -f /etc/repmgr.conf cluster show We see
Hidden text
Role | Name | Upstream | Connection String ----------+-------|----------|-------------------------------------------------- * master | node1 | | host=pghost195 port=5433 user=repmgr dbname=repmgr Go ahead.
Setting up slaves (standby) - pghost196, pghost197, pghost198
Configuring repmgr on slave1 (pghost197)
nano /etc/repmgr.conf - create a config
Content
Hidden text
cluster=etagi_test node=2 node_name=node2 use_replication_slots=1 conninfo='host=pghost196 port=5433 user=repmgr dbname=repmgr' pg_bindir=/usr/lib/postgresql/9.6/bin Persist.
Register server as standby
Hidden text
su postgres cd ~/9.6/ rm -rf main/* repmgr -h pghost1 -p 5433 -U repmgr -d repmgr -D main -f /etc/repmgr.conf --copy-external-config-files=pgdata --verbose standby clone pg_ctl -D /var/lib/postgresql/9.6/main --log=/var/log/postgresql/postgres_screen.log start Configs will be copied based on which there will be a switching of the master and standby state of the servers.
Let's browse the files that are in the root of the /var/lib/postgresql/9.6/main folder - these files must be included.
Hidden text
PG_VERSION backup_label pg_hba.conf pg_ident.conf postgresql.auto.conf postgresql.conf recovery.conf Register server in cluster
Hidden text
su postgres repmgr -f /etc/repmgr.conf standby register; repmgr -f /etc/repmgr.conf cluster show repmgr -f /etc/repmgr.conf cluster show <spoiler title=""> <source lang="bash"> Role | Name | Upstream | Connection String ----------+-------|----------|-------------------------------------------------- * master | node195 | | host=pghost195 port=5433 user=repmgr dbname=repmgr standby | node196 | node1 | host=pghost196 port=5433 user=repmgr dbname=repmgr Setting up a second stand-by - pghost197 Configuring repmgr on pghost197
nano /etc/repmgr.conf - create a config
Content
Hidden text
cluster=etagi_test node=3 node_name=node3 use_replication_slots=1 conninfo='host=pghost197 port=5433 user=repmgr dbname=repmgr' pg_bindir=/usr/lib/postgresql/9.6/bin Persist.
Register server as standby
Hidden text
su postgres cd ~/9.6/ rm -rf main/* repmgr -h pghost195 -p 5433 -U repmgr -d repmgr -D main -f /etc/repmgr.conf --copy-external-config-files=pgdata --verbose standby clone or
Hidden text
repmgr -D /var/lib/postgresql/9.6/main -f /etc/repmgr.conf -d repmgr -p 5433 -U repmgr -R postgres --verbose --force --rsync-only --copy-external-config-files=pgdata standby clone -h pghost195 This command with the -r / - rsync-only option is used in some cases, for example, when the data directory being copied is the data directory of the failed server with the active replication node.
Configs will also be copied based on which the switching of the master and standby state of the servers will occur.
Let's browse the files that are in the root of the /var/lib/postgresql/9.6/main folder - the following files must be present:
Hidden text
PG_VERSION backup_label pg_hba.conf pg_ident.conf postgresql.auto.conf postgresql.conf recovery.conf Starting postgres (from postgres)
Hidden text
pg_ctl -D /var/lib/postgresql/9.6/main --log=/var/log/postgresql/postgres_screen.log start Register server in cluster
Hidden text
su postgres repmgr -f /etc/repmgr.conf standby register View Cluster Status
Hidden text
repmgr -f /etc/repmgr.conf cluster show We see
Hidden text
Role | Name | Upstream | Connection String ----------+-------|----------|-------------------------------------------------- * master | node1 | | host=pghost1 port=5433 user=repmgr dbname=repmgr standby | node2 | node1 | host=pghost2 port=5433 user=repmgr dbname=repmgr standby | node3 | node1 | host=pghost2 port=5433 user=repmgr dbname=re Configure cascade replication.
You can also customize cascading replication. Consider an example. Configuring repmgr on pghost198 from pghost197
nano /etc/repmgr.conf - create a config. Content
Hidden text
cluster=etagi_test node=4 node_name=node4 use_replication_slots=1 conninfo='host=pghost198 port=5433 user=repmgr dbname=repmgr' pg_bindir=/usr/lib/postgresql/9.6/bin upstream_node=3 Persist. As we can see, in upstream_node we specified node3, which is pghost197.
We register the server as standby from standby
Hidden text
su postgres cd ~/9.6/ rm -rf main/* repmgr -h pghost197 -p 5433 -U repmgr -d repmgr -D main -f /etc/repmgr.conf --copy-external-config-files=pgdata --verbose standby clone Starting postgres (from postgres)
Hidden text
pg_ctl -D /var/lib/postgresql/9.6/main --log=/var/log/postgresql/postgres_screen.log start Register server in cluster
Hidden text
su postgres repmgr -f /etc/repmgr.conf standby register View Cluster Status
Hidden text
repmgr -f /etc/repmgr.conf cluster show We see
Hidden text
Role | Name | Upstream | Connection String ----------+-------|----------|-------------------------------------------------- * master | node1 | | host=pghost195 port=5433 user=repmgr dbname=repmgr standby | node2 | node1 | host=pghost196 port=5433 user=repmgr dbname=repmgr standby | node3 | node1 | host=pghost197 port=5433 user=repmgr dbname=repmgr standby | node4 | node3 | host=pghost198 port=5433 user=repmgr dbname=repmgr Configure Automatic Failover.
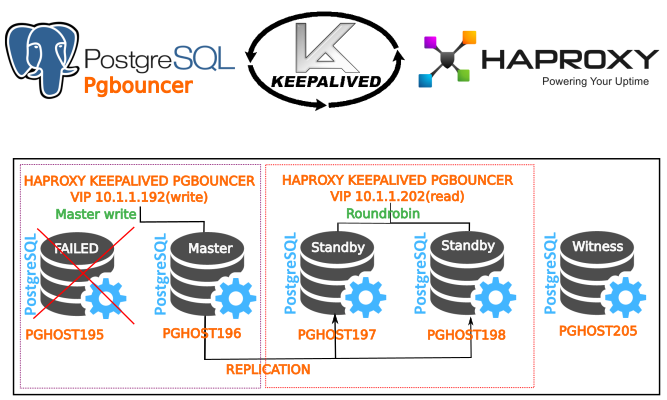
So, we’ve finished streaming replication setup. Now let's proceed to setting up auto-switching - activating a new wizard from the stand-by server. To do this, you need to add new sections to the /etc/repmgr.conf file on stand-by servers. On the master of this should not be!
! Configs on standby (slave's) should be different - as in the example below. Let's set a different time (master_responce_timeout)!
Add lines to pghost196 in /etc/repmgr.conf
Hidden text
####### FAILOVER####### STAND BY################## master_response_timeout=20 reconnect_attempts=5 reconnect_interval=5 failover=automatic promote_command='sh /etc/postgresql/failover_promote.sh' follow_command='sh /etc/postgresql/failover_follow.sh' #loglevel=NOTICE #logfacility=STDERR #logfile='/var/log/postgresql/repmgr-9.6.log' priority=90 # a value of zero or less prevents the node being promoted to master Add lines to pghost197 in /etc/repmgr.conf
Hidden text
####### FAILOVER####### STAND BY################## master_response_timeout=20 reconnect_attempts=5 reconnect_interval=5 failover=automatic promote_command='sh /etc/postgresql/failover_promote.sh' follow_command='sh /etc/postgresql/failover_follow.sh' #loglevel=NOTICE #logfacility=STDERR #logfile='/var/log/postgresql/repmgr-9.6.log' priority=70 # a value of zero or less prevents the node being promoted to master Add lines to pghost198 in /etc/repmgr.conf
Hidden text
####### FAILOVER####### STAND BY################## master_response_timeout=20 reconnect_attempts=5 reconnect_interval=5 failover=automatic promote_command='sh /etc/postgresql/failover_promote.sh' follow_command='sh /etc/postgresql/failover_follow.sh' #loglevel=NOTICE #logfacility=STDERR #logfile='/var/log/postgresql/repmgr-9.6.log' priority=50 # a value of zero or less prevents the node being promoted to master As we can see, all auto-fixer settings are identical, the only difference is in priority. If 0, then this Standby will never become a Master. This parameter will determine the order of failover operation, i.e. a smaller number indicates a higher priority, then after the master server fails, pghost197 will take over its function.
It is also necessary to add the following lines to the /etc/postgresql/9.6/main/postgresql.conf file (only on the stand-by server !!!!!!)
Hidden text
shared_preload_libraries = 'repmgr_funcs' To start the auto-switching daemon, you must:
Hidden text
su postgres repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v >> /var/log/postgresql/repmgr.log 2>&1 The repmgrd process will run as a daemon. We look
Hidden text
ps aux | grep repmgrd We see
Hidden text
postgres 2921 0.0 0.0 59760 5000 ? S 16:54 0:00 /usr/lib/postgresql/9.6/bin/repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v postgres 3059 0.0 0.0 12752 2044 pts/1 S+ 16:54 0:00 grep repmgrd All OK. Go ahead.
Check the work auto-file
Hidden text
su postgres psql repmgr repmgr # SELECT * FROM repmgr_etagi_test.repl_nodes ORDER BY id; id | type | upstream_node_id | cluster | name | conninfo | slot_name | priority | active ----+---------+------------------+------------+-------+---------------------------------------------------+---------------+----------+-------- 1 | master | | etagi_test | node1 | host=pghost195 port=5433 user=repmgr dbname=repmgr | repmgr_slot_1 | 100 | t 2 | standby | 1 | etagi_test | node2 | host=pghost196 port=5433 user=repmgr dbname=repmgr | repmgr_slot_2 | 100 | t 3 | standby | 1 | etagi_test | node3 | host=pghost197 port=5433 user=repmgr dbname=repmgr | repmgr_slot_3 | 100 | t So far so good - now we will test. Stop Master - pghost195
Hidden text
su postgres pg_ctl -D /etc/postgresql/9.6/main -m immediate stop In the logs on pghost196
Hidden text
tail -f /var/log/postgresql/* We see
Hidden text
[2016-10-21 16:58:34] [NOTICE] promoting standby [2016-10-21 16:58:34] [NOTICE] promoting server using '/usr/lib/postgresql/9.6/bin/pg_ctl -D /var/lib/postgresql/9.6/main promote' [2016-10-21 16:58:36] [NOTICE] STANDBY PROMOTE successful In the logs on pghost197
Hidden text
tail -f /var/log/postgresql/* We see
Hidden text
2016-10-21 16:58:39] [NOTICE] node 2 is the best candidate for new master, attempting to follow... [2016-10-21 16:58:40] [ERROR] connection to database failed: could not connect to server: Connection refused Is the server running on host "pghost195" (10.1.1.195) and accepting TCP/IP connections on port 5433? [2016-10-21 16:58:40] [NOTICE] restarting server using '/usr/lib/postgresql/9.6/bin/pg_ctl -w -D /var/lib/postgresql/9.6/main -m fast restart' [2016-10-21 16:58:42] [NOTICE] node 3 now following new upstream node 2 Everything is working. We have a new master - pghost196, pghost197, pghost198 - now listens to stream from pghost2.
Return fallen master in build!

You can not just take and return the fallen master in the system. But he will return as a slave.
Postgres must be stopped before returning. On the node that failed create a script. In this script, telegram notification has already been set up, and trigger check is set up - if the / etc / postgresql / disabled file is created, then recovery will not occur. We will also create the file /etc/postgresql/current_master.list with the contents - the name of the current master.
/etc/postgresql/current_master.list
pghost196 Let's call the script "register.sh" and place it in the / etc / postgresql directory
Script recovery nodes in the cluster as a standby
/etc/postgresql/register.sh.
trigger="/etc/postgresql/disabled" TEXT="'`hostname -f`_postgresql_disabled_and_don't_be_started.You_must_delete_file_/etc/postgresql/disabled'" TEXT if [ -f "$trigger" ] then echo "Current server is disabled" sh /etc/postgresql/telegram.sh $TEXT else pkill repmgrd pg_ctl stop rm -rf /var/lib/postgresql/9.6/main/*; mkdir /var/run/postgresql/9.6-main.pg_stat_tmp; #repmgr -D /var/lib/postgresql/9.6/main -f /etc/repmgr.conf -d repmgr -p 5433 -U repmgr -R postgres --verbose --force --rsync-only --copy-external-config-files=pgdata standby clone -h $(cat /etc/postgresql/current_master.list); repmgr -h $(cat /etc/postgresql/current_master.list) -p 5433 -U repmgr -d repmgr -D /var/lib/postgresql/9.6/main -f /etc/repmgr.conf --copy-external-config-files=pgdata --verbose standby clone /usr/lib/postgresql/9.6/bin/pg_ctl -D /var/lib/postgresql/9.6/main --log=/var/log/postgresql/postgres_screen.log start; /bin/sleep 5; repmgr -f /etc/repmgr.conf --force standby register; echo " "; repmgr -f /etc/repmgr.conf cluster show; sh /etc/postgresql/telegram.sh $TEXT sh /etc/postgresql/repmgrd.sh; ps aux | grep repmgrd; fi As you can see, we also have in the script a file repmgrd.sh and telegram.sh. They should also be located in the / etc / postgresql directory.
/etc/postgresql/repmgrd.sh
#!/bin/bash pkill repmgrd rm /var/run/postgresql/repmgrd.pid; repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v >> /var/log/postgresql/repmgr.log 2>&1; ps aux | grep repmgrd; Script to send to telegrams.
telegram.sh.
USERID="_____" CLUSTERNAME="PGCLUSTER_RIES" KEY="__" TIMEOUT="10" EXEPT_USER="root" URL="https://api.telegram.org/bot$KEY/sendMessage" DATE_EXEC="$(date "+%d %b %Y %H:%M")" TMPFILE='/etc/postgresql/ipinfo-$DATE_EXEC.txt' IP=$(echo $SSH_CLIENT | awk '{print $1}') PORT=$(echo $SSH_CLIENT | awk '{print $3}') HOSTNAME=$(hostname -f) IPADDR=$(hostname -I | awk '{print $1}') curl http://ipinfo.io/$IP -s -o $TMPFILE #ORG=$(cat $TMPFILE | jq '.org' | sed 's/"//g') TEXT=$1 for IDTELEGRAM in $USERID do curl -s --max-time $TIMEOUT -d "chat_id=$IDTELEGRAM&disable_web_page_preview=1&text=$TEXT" $URL > /dev/null done rm $TMPFILE Edit the repmgr config on the fallen master
/etc/repmgr.conf
cluster=etagi_cluster1 node=1 node_name=node195 use_replication_slots=1 conninfo='host=pghost195 port=5433 user=repmgr dbname=repmgr' pg_bindir=/usr/lib/postgresql/9.6/bin ####### FAILOVER####### STAND BY################## master_response_timeout=20 reconnect_attempts=5 reconnect_interval=5 failover=automatic promote_command='sh /etc/postgresql/failover_promote.sh' follow_command='sh /etc/postgresql/failover_follow.sh' #loglevel=NOTICE #logfacility=STDERR #logfile='/var/log/postgresql/repmgr-9.6.log' priority=95 # a value of zero or less prevents the node being promoted to master Keep it up Now run our script on the failed node. Do not forget about the rights (postgres) for files.
sh /etc/postgresq/register.sh
Will see
Hidden text
[2016-10-31 15:19:53] [NOTICE] notifying master about backup completion... : pg_stop_backup , WAL [2016-10-31 15:19:54] [NOTICE] standby clone (using rsync) complete [2016-10-31 15:19:54] [NOTICE] you can now start your PostgreSQL server [2016-10-31 15:19:54] [HINT] for example : pg_ctl -D /var/lib/postgresql/9.6/main start [2016-10-31 15:19:54] [HINT] After starting the server, you need to register this standby with "repmgr standby register" [2016-10-31 15:19:59] [NOTICE] standby node correctly registered for cluster etagi_cluster1 with id 2 (conninfo: host=pghost196 port=5433 user=repmgr dbname=repmgr) Role | Name | Upstream | Connection String ----------+---------|----------|---------------------------------------------------- * standby | node195 | | host=pghost195 port=5433 user=repmgr dbname=repmgr master | node196 | node195 | host=pghost197 port=5433 user=repmgr dbname=repmgr standby | node197 | node195 | host=pghost198 port=5433 user=repmgr dbname=repmgr standby | node198 | node195 | host=pghost196 port=5433 user=repmgr dbname=repmgr postgres 11317 0.0 0.0 4336 716 pts/0 S+ 15:19 0:00 sh /etc/postgresql/repmgrd.sh postgres 11322 0.0 0.0 59548 3632 ? R 15:19 0:00 /usr/lib/postgresql/9.6/bin/repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v postgres 11324 0.0 0.0 12752 2140 pts/0 S+ 15:19 0:00 grep repmgrd postgres 11322 0.0 0.0 59548 4860 ? S 15:19 0:00 /usr/lib/postgresql/9.6/bin/repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v postgres 11327 0.0 0.0 12752 2084 pts/0 S+ 15:19 0:00 grep repmgrd As we can see the script worked, we received notifications and saw the status of the cluster.
Implementing the Switchover procedure (manual wizard shifts).
Suppose there is such a situation when you need to swap the master and a certain standby. Suppose we want to make the master pghost195 instead of the pghost196 that has become on the filer, after it has been restored as a slave. Our steps.
On pghost195
Hidden text
su postgres repmgr -f /etc/repmgr.conf standby switchover [2016-10-26 15:29:42] [NOTICE] replication slot "repmgr_slot_1" deleted on former master [2016-10-26 15:29:42] [NOTICE] switchover was successful Now we need to give the command to the replicas, except the old master, to give the command to transfer to the new master.
On pghost197
Hidden text
su postgres repmgr -f /etc/repmgr.conf standby follow repmgr -f /etc/repmgr.conf cluster show; We see that we are following the new master.
Pghost198 is the same
Hidden text
su postgres repmgr -f /etc/repmgr.conf standby follow repmgr -f /etc/repmgr.conf cluster show; We see that we are following the new master.
On pghost196 - he was a previous master, from whom we took away the rights
Hidden text
su postgres repmgr -f /etc/repmgr.conf standby follow We see an error
Hidden text
[2016-10-26 15:35:51] [ERROR] Slot 'repmgr_slot_2' already exists as an active slot We pghost196
Hidden text
pg_ctl stop To fix it, go to the phgost195 (new master)
Hidden text
su postgres psql repmgr #select pg_drop_replication_slot('repmgr_slot_2'); We see
Hidden text
pg_drop_replication_slot -------------------------- (1 row) Go to pghost196, and do everything by analogy with the paragraph.
Creating and using witness nodes

Witness node is used to manage the cluster, in the event of a filer and acts as a kind of arbiter, makes sure that no conflict occurs when choosing a new master. It is not an active node in terms of using it as a standby server; it can be installed on the same node as postgres or on a separate node.
Add another pghost205 node to manage the cluster (the setting is absolutely the same as the slave setting), the copying method will be different:
Hidden text
repmgr -h pghost195 -p 5433 -U repmgr -d repmgr -D main -f /etc/repmgr.conf --force --copy-external-config-files=pgdata --verbose witness create; repmgr -D /var/lib/postgresql/9.6/main -f /etc/repmgr.conf -d repmgr -p 5433 -U repmgr -R postgres --verbose --force --rsync-only --copy-external-config-files=pgdata witness create -h pghost195; See the output
Hidden text
2016-10-26 17:27:06] [WARNING] --copy-external-config-files can only be used when executing STANDBY CLONE [2016-10-26 17:27:06] [NOTICE] using configuration file "/etc/repmgr.conf" , , "postgres". . "ru_RU.UTF-8". , : "UTF8". "russian". . main... ... max_connections... 100 shared_buffers... 128MB ... posix ... ... ... ... : "trust" . , pg_hba.conf -A, --auth-local --auth-host initdb. . : /usr/lib/postgresql/9.6/bin/pg_ctl -D main -l logfile start ....: : 2016-10-26 17:27:07 YEKT : : : Warning: Permanently added 'pghost1,10.1.9.1' (ECDSA) to the list of known hosts. receiving incremental file list pg_hba.conf 1,174 100% 1.12MB/s 0:00:00 (xfr#1, to-chk=0/1) : SIGHUP, [2016-10-26 17:27:10] [NOTICE] configuration has been successfully copied to the witness /usr/lib/postgresql/9.6/bin/pg_ctl -D /var/lib/postgresql/9.6/main -l logfile start Is done. We go further. Manage repmgr.conf file for witness nodes
Disable the automatic filer on the witness node.
nano /etc/repmgr.conf
cluster=etagi_test node=5 node_name=node5 use_replication_slots=1 conninfo='host=pghost205 port=5499 user=repmgr dbname=repmgr' pg_bindir=/usr/lib/postgresql/9.6/bin #######FAILOVER####### WITNESS NODE####### master_response_timeout=50 reconnect_attempts=3 reconnect_interval=5 failover=manual promote_command='repmgr standby promote -f /etc/repmgr.conf' follow_command='repmgr standby follow -f /etc/repmgr.conf' On the witness node, be sure to change the port to 5499 in conninfo.
Be sure to (re) run the repmgrd on all nodes except the master
Hidden text
su postgres pkill repmgr repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v >> /var/log/postgresql/repmgr.log 2>&1 ps aux | grep repmgr Configure the Pgbouncer connection manager and balancing via Haproxy. Fault tolerance through keepalived.
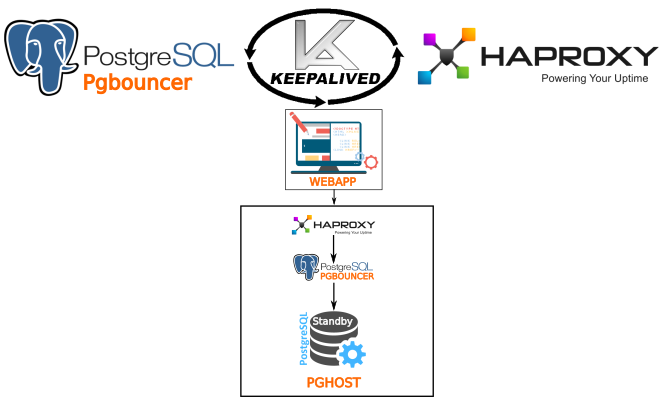
Pgbouncer setup
Pgbouncer we have already installed in advance. What is it for ...
Why pgbouncer
. Postgres, . PgBouncer . Let's move on to setting it up.
Copy the installed pgbouncer to the / etc / folder (for convenience)
Hidden text
cp -r /usr/local/share/doc/pgbouncer /etc cd /etc/pgbouncer We bring to mind the file in
nano /etc/pgbouncer/pgbouncer.ini
[databases] ################################ ########### web1 = host = localhost port=5433 dbname=web1 web2 = host = localhost port=5433 dbname=web2 ####################################################### [pgbouncer] logfile = /var/log/postgresql/pgbouncer.log pidfile = /var/run/postgresql/pgbouncer.pid listen_addr = * listen_port = 6432 auth_type = trust auth_file = /etc/pgbouncer/userlist.txt ;;; Pooler personality questions ; When server connection is released back to pool: ; session - after client disconnects ; transaction - after transaction finishes ; statement - after statement finishes pool_mode = session server_reset_query = DISCARD ALL max_client_conn = 500 default_pool_size = 30 /etc/pgbouncer/userlist.txt
"test_user" "passworduser" "postgres" "passwordpostgres" "pgbouncer" "fake" Hidden text
chown -R postgres /etc/pgbouncer (-d)
pgbouncer
su postgres pkill pgbouncer pgbouncer -d --verbose /etc/pgbouncer/pgbouncer.ini Hidden text
netstat -4ln | grep 6432 Hidden text
tail -f /var/log/postgresql/pgbouncer.log . .
Haproxy.
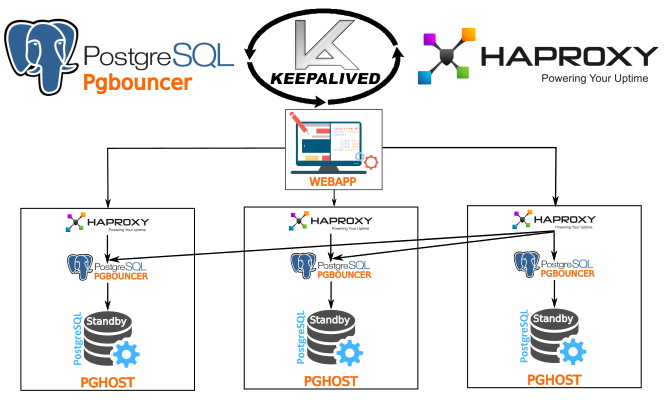
Xinetd Haproxy
Hidden text
apt-get install xinetd haproxy -y Hidden text
nano /etc/services pgsqlchk 23267/tcp # pgsqlchk postgres — pgsqlcheck
nano /opt/pgsqlchk
#!/bin/bash # /opt/pgsqlchk # This script checks if a postgres server is healthy running on localhost. It will # return: # # "HTTP/1.x 200 OK\r" (if postgres is running smoothly) # # - OR - # # "HTTP/1.x 500 Internal Server Error\r" (else) # # The purpose of this script is make haproxy capable of monitoring postgres properly # # # It is recommended that a low-privileged postgres user is created to be used by # this script. # For eg. create user pgsqlchkusr login password 'pg321'; # PGSQL_HOST="localhost" PGSQL_PORT="5433" PGSQL_DATABASE="template1" PGSQL_USERNAME="pgsqlchkusr" export PGPASSWORD="pg321" TMP_FILE="/tmp/pgsqlchk.out" ERR_FILE="/tmp/pgsqlchk.err" # # We perform a simple query that should return a few results :-p # psql -h $PGSQL_HOST -p $PGSQL_PORT -U $PGSQL_USERNAME \ $PGSQL_DATABASE -c "show port;" > $TMP_FILE 2> $ERR_FILE # # Check the output. If it is not empty then everything is fine and we return # something. Else, we just do not return anything. # if [ "$(/bin/cat $TMP_FILE)" != "" ] then # Postgres is fine, return http 200 /bin/echo -e "HTTP/1.1 200 OK\r\n" /bin/echo -e "Content-Type: Content-Type: text/plain\r\n" /bin/echo -e "\r\n" /bin/echo -e "Postgres is running.\r\n" /bin/echo -e "\r\n" else # Postgres is down, return http 503 /bin/echo -e "HTTP/1.1 503 Service Unavailable\r\n" /bin/echo -e "Content-Type: Content-Type: text/plain\r\n" /bin/echo -e "\r\n" /bin/echo -e "Postgres is *down*.\r\n" /bin/echo -e "\r\n" fi pgsqlchkusr postgres
Hidden text
plsq #create user pgsqlchkusr; #ALTER ROLE pgsqlchkusr WITH LOGIN; #ALTER USER pgsqlchkusr WITH PASSWORD 'pg321'; #\q — check .
Hidden text
chmod +x /opt/pgsqlchk;touch /tmp/pgsqlchk.out; touch /tmp/pgsqlchk.err; chmod 777 /tmp/pgsqlchk.out; chmod 777 /tmp/pgsqlchk.err; xinetd pgsqlchk
nano /etc/xinetd.d/pgsqlchk
# /etc/xinetd.d/pgsqlchk # # default: on # # description: pqsqlchk service pgsqlchk { flags = REUSE socket_type = stream port = 23267 wait = no user = nobody server = /opt/pgsqlchk log_on_failure += USERID disable = no only_from = 0.0.0.0/0 per_source = UNLIMITED } .
haproxy.
— . , , , pghost195. - , 6432( pgbouncer).
nano /etc/haproxy/haproxy.cfg
global log 127.0.0.1 local0 log 127.0.0.1 local1 notice #chroot /usr/share/haproxy chroot /var/lib/haproxy pidfile /var/run/haproxy.pid user postgres group postgres daemon maxconn 20000 defaults log global mode http option tcplog option dontlognull retries 3 option redispatch timeout connect 30000ms timeout client 30000ms timeout server 30000ms frontend stats-front bind *:8080 mode http default_backend stats-back frontend pxc-onenode-front bind *:5432 mode tcp default_backend pxc-onenode-back backend stats-back mode http stats uri / stats auth admin:adminpassword backend pxc-onenode-back mode tcp balance leastconn option httpchk default-server port 6432 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxqueue 128 weight 100 server pghost195 10.1.1.195:6432 check port 23267 haproxy 5432. 8080. admin adminpassword.
Hidden text
/etc/init.d/xinetd restart; /etc/init.d/haproxy restart; . , , pghost198( ) haproxy .
nano /etc/haproxy/haproxy.cfg
global log 127.0.0.1 local0 log 127.0.0.1 local1 notice #chroot /usr/share/haproxy chroot /var/lib/haproxy pidfile /var/run/haproxy.pid user postgres group postgres daemon maxconn 20000 defaults log global mode http option tcplog option dontlognull retries 3 option redispatch timeout connect 30000ms timeout client 30000ms timeout server 30000ms frontend stats-front bind *:8080 mode http default_backend stats-back frontend pxc-onenode-front bind *:5432 mode tcp default_backend pxc-onenode-back backend stats-back mode http stats uri / stats auth admin:adminpassword backend pxc-onenode-back mode tcp balance roundrobin option httpchk default-server port 6432 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxqueue 128 weight 100 server pghost196 10.1.1.196:6432 check port 23267 server pghost197 10.1.1.196:6432 check port 23267 server pghost198 10.1.1.196:6432 check port 23267 hostip :8080
keepalived.
Keepalived ip (VIP) ( ) ip . VIP 10.1.1.192 pghost195,pghost196,pghost197. pghost195 pghost196 ip addr 10.1.1.192 haproxy pgbouncer — . — Haproxy.
keepalived
Hidden text
apt-get install keepalived -y keepalived. /etc/sysctl.conf
Hidden text
net.ipv4.ip_forward=1 Then
Hidden text
sysctl -p 1- (pghost195)
nano /etc/keepalived/keepalived.conf
! this is who emails will go to on alerts notification_email { admin@domain.com ! add a few more email addresses here if you would like } notification_email_from servers@domain.com ! I use the local machine to relay mail smtp_server smt.local.domain smtp_connect_timeout 30 ! each load balancer should have a different ID ! this will be used in SMTP alerts, so you should make ! each router easily identifiable lvs_id LVS_HAPROXY-pghost195 } } vrrp_instance haproxy-pghost195 { interface eth0 state MASTER virtual_router_id 192 priority 150 ! send an alert when this instance changes state from MASTER to BACKUP smtp_alert authentication { auth_type PASS auth_pass passwordforcluster } track_script { chk_http_port } virtual_ipaddress { 10.1.1.192/32 dev eth0 } notify_master "sh /etc/postgresql/telegram.sh 'MASTER pghost195.etagi.com VIP'" notify_backup "sh /etc/postgresql/telegram.sh 'BACKUP pghost195.etagi.com VIP'" notify_fault "sh /etc/postgresql/telegram.sh 'FAULT pghost195.etagi.com VIP'" } /etc/init.d/keepalived restart
keepalived 2- (pghost196)
nano /etc/keepalived/keepalived.conf
! this is who emails will go to on alerts notification_email { admin@domain.com ! add a few more email addresses here if you would like } notification_email_from servers@domain.com ! I use the local machine to relay mail smtp_server smt.local.domain smtp_connect_timeout 30 ! each load balancer should have a different ID ! this will be used in SMTP alerts, so you should make ! each router easily identifiable lvs_id LVS_HAPROXY-pghost196 } } vrrp_instance haproxy-pghost196 { interface eth0 state MASTER virtual_router_id 192 priority 80 ! send an alert when this instance changes state from MASTER to BACKUP smtp_alert authentication { auth_type PASS auth_pass passwordforcluster } track_script { chk_http_port } virtual_ipaddress { 10.1.1.192/32 dev eth0 } notify_master "sh /etc/postgresql/telegram.sh 'MASTER pghost196.etagi.com VIP'" notify_backup "sh /etc/postgresql/telegram.sh 'BACKUP pghost196.etagi.com VIP'" notify_fault "sh /etc/postgresql/telegram.sh 'FAULT pghost196.etagi.com VIP'" } keepalived 3- (pghost197)
nano /etc/keepalived/keepalived.conf
! this is who emails will go to on alerts notification_email { admin@domain.com ! add a few more email addresses here if you would like } notification_email_from servers@domain.com ! I use the local machine to relay mail smtp_server smt.local.domain smtp_connect_timeout 30 ! each load balancer should have a different ID ! this will be used in SMTP alerts, so you should make ! each router easily identifiable lvs_id LVS_HAPROXY-pghost197 } } vrrp_instance haproxy-pghost197 { interface eth0 state MASTER virtual_router_id 192 priority 50 ! send an alert when this instance changes state from MASTER to BACKUP smtp_alert authentication { auth_type PASS auth_pass passwordforcluster } track_script { chk_http_port } virtual_ipaddress { 10.1.1.192/32 dev eth0 } notify_master "sh /etc/postgresql/telegram.sh 'MASTER pghost197.etagi.com VIP'" notify_backup "sh /etc/postgresql/telegram.sh 'BACKUP pghost197.etagi.com VIP'" notify_fault "sh /etc/postgresql/telegram.sh 'FAULT pghost197.etagi.com VIP'" } Hidden text
/etc/init.d/keepalived restart , , .
Hidden text
notify_master "sh /etc/postgresql/telegram.sh 'MASTER pghost195.etagi.com VIP'" notify_backup "sh /etc/postgresql/telegram.sh 'BACKUP pghost195.etagi.com VIP'" notify_fault "sh /etc/postgresql/telegram.sh 'FAULT pghost195.etagi.com VIP'" VIP 10.1.8.111 eth0. pghost195 pghost196, .. IP 10.1.1.192. pghost197, vrrp_instance lvs_id LVS_.
pghost196,pghost197 keepalived. failover promote, .
Hidden text
promote_command='sh /etc/postgresql/failover_promote.sh' follow_command='sh /etc/postgresql/failover_follow.sh' /etc/repmgr.conf (. ).
failover - .
promote_command='sh /etc/postgresql/failover_promote.sh — master host,
follow_command='sh /etc/postgresql/failover_follow.sh' — , .
promote_command='sh /etc/postgresql/failover_promote.sh'
#!/bin/bash CLHOSTS="pghost195 pghost196 pghost197 pghost198 pghost205 " repmgr standby promote -f /etc/repmgr.conf; echo " "; sh /etc/postgresql/failover_notify_master.sh; echo " " repmgr -f /etc/repmgr.conf cluster show | grep node | awk ' {print $7} ' | sed "s/host=//g" | sed '/port/d' > /etc/postgresql/cluster_hosts.list repmgr -f /etc/repmgr.conf cluster show | grep FAILED | awk ' {print $6} ' | sed "s/host=//g" | sed "s/>//g" > /etc/postgresql/failed_host.list repmgr -f /etc/repmgr.conf cluster show | grep master | awk ' {print $7} ' | sed "s/host=//g" | sed "s/>//g" > /etc/postgresql/current_master.list repmgr -f /etc/repmgr.conf cluster show | grep standby | awk ' {print $7} ' | sed "s/host=//g" | sed '/port/d' > /etc/postgresql/standby_host.list #### - ##################### for CLHOST in $CLHOSTS do rsync -arvzSH --include "*.list" --exclude "*" /etc/\postgresql/ postgres@$CLHOST:/etc/postgresql/ done echo " , /etc/postgresql/disabled" for FH in $(cat /etc/postgresql/failed_host.list) do ssh postgres@$FH <<OFF sh /etc/postgresql/register.sh; echo " repmgrd " sh /etc/postgresql/repmgrd.sh; sh /etc/postgresql/failover_notify_restoring_ended.sh; OFF done echo " repmgrd , " pkill repmgrd echo " Keepalived" follow_command='sh /etc/postgresql/failover_follow.sh'
repmgr standby follow -f /etc/repmgr.conf; echo " "; sh /etc/postgresql/failover_notify_standby.sh; pkill repmgrd; repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v >> /var/log/postgresql/repmgr.log 2>&1; — failover, «» .
follow_command='sh /etc/postgresql/stop_master.sh'
#! / bin / bash
repmgr -f /etc/repmgr.conf cluster show | grep master | awk ' {print $7} ' | sed «s/host=//g» | sed «s/>//g» > /etc/postgresql/current_master.list
for CURMASTER in $(cat /etc/postgresql/current_master.list)
do
ssh postgres@$CURMASTER <<OFF
cd ~/9.6;
/usr/lib/postgresql/9.6/bin/pg_ctl -D /etc/postgresql/9.6/main -m immediate stop;
touch /etc/postgresql/disabled;
OFF
sh /etc/postgresql/telegram.sh « »
done
repmgr -f /etc/repmgr.conf cluster show | grep master | awk ' {print $7} ' | sed «s/host=//g» | sed «s/>//g» > /etc/postgresql/current_master.list
for CURMASTER in $(cat /etc/postgresql/current_master.list)
do
ssh postgres@$CURMASTER <<OFF
cd ~/9.6;
/usr/lib/postgresql/9.6/bin/pg_ctl -D /etc/postgresql/9.6/main -m immediate stop;
touch /etc/postgresql/disabled;
OFF
sh /etc/postgresql/telegram.sh « »
done
. , root postgres. — .
root postgres
su postgres ssh-copy-id -i ~/.ssh/id_rsa.pub root@pghost195 ssh-copy-id -i ~/.ssh/id_rsa.pub root@pghost196 ssh-copy-id -i ~/.ssh/id_rsa.pub root@pghost197 ssh-copy-id -i ~/.ssh/id_rsa.pub root@pghost198 ssh-copy-id -i ~/.ssh/id_rsa.pub root@pghost205 . , 2 . , .
Hidden text
repmgr -f /etc/repmgr.conf cluster show | grep node | awk ' {print $7} ' | sed "s/host=//g" | sed '/port/d' > /etc/postgresql/cluster_hosts.list repmgr -f /etc/repmgr.conf cluster show | grep FAILED | awk ' {print $6} ' | sed "s/host=//g" | sed "s/>//g" > /etc/postgresql/failed_host.list repmgr -f /etc/repmgr.conf cluster show | grep master | awk ' {print $7} ' | sed "s/host=//g" | sed "s/>//g" > /etc/postgresql/current_master.list repmgr -f /etc/repmgr.conf cluster show | grep standby | awk ' {print $7} ' | sed "s/host=//g" | sed '/port/d' > /etc/postgresql/standby_host.list .
pg_stat_statements( )
Hidden text
su postgres cd ~ pg_ctl restart; :
Hidden text
# CREATE EXTENSION pg_stat_statements; :
Hidden text
# SELECT query, calls, total_time, rows, 100.0 * shared_blks_hit / nullif(shared_blks_hit + shared_blks_read, 0) AS hit_percent FROM pg_stat_statements ORDER BY total_time DESC LIMIT 10; pg_stat_statements_reset:
Hidden text
# SELECT pg_stat_statements_reset(); 'FAILED'
Hidden text
DELETE FROM repmgr_etagi_test.repl_nodes WHERE name = 'node1'; — etagi_test — ;
node1 —
Hidden text
plsq #SELECT EXTRACT(EPOCH FROM (now() - pg_last_xact_replay_timestamp()))::INT; 00:00:31.445829 (1 ) Insert' — . hiload .
Slot 'repmgr_slot_ ' already exists as an active slot
postgresql ,
Hidden text
su postgres pg_ctl stop; master'e
Hidden text
su postgres psql repmgr #select pg_drop_replication_slot('repmgr_slot_4'); : «dbname»
, .
Hidden text
plsq # SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE datname = 'dbname'; # DROP DATABASE dbname; INSERT UPDATE «repl_nodes» : INSERT UPDATE «repl_nodes» «repl_nodes_upstream_node_id_fkey». DETAIL: (upstream_node_id)=(-1) «repl_nodes».
switchover (standby)
Hidden text
repmgr -f /etc/repmgr.conf standby switchover Standby . “ ” standby
Hidden text
repmgr -f /etc/repmgr.conf standby follow : "/var/run/postgresql/9.6-main.pg_stat_tmp":
Hidden text
su postgres mkdir -p /var/run/postgresql/9.6-main.pg_stat_tmp no password supplied.
“no password supplied”. , , - .
Backup
pg_dumpall | gzip -c > filename.gz Postgres
backup_pg.sh
#!/bin/bash DBNAMES="db1 db2 db3" DATE_Y=`/bin/date '+%y'` DATE_M=`/bin/date '+%m'` DATE_D=`/bin/date '+%d'` SERVICE="pgdump" #DB_NAME="repmgr"; #`psql -l | awk '{print $1}' ` for DB_NAME in $DBNAMES do echo "CREATING DIR /Backup/20${DATE_Y}/${DATE_M}/${DATE_D}/${DB_NAME} " BACKUP_DIR="/Backup/20${DATE_Y}/${DATE_M}/${DATE_D}/${DB_NAME}" mkdir -p $BACKUP_DIR; pg_dump -Fc --verbose ${DB_NAME} | gzip > $BACKUP_DIR/${DB_NAME}.gz # dump , pg_dump -Fc -s -f $BACKUP_DIR/${DB_NAME}_only_shema ${DB_NAME} /bin/sleep 2; # pg_restore -l $BACKUP_DIR/${DB_NAME}_only_shema | grep FUNCTION > $BACKUP_DIR/function_list done ## ######################### #pg_restore -h localhost -U username -d _ -L function_list db_dump ######################## ### , payment. #pg_restore --dbname db1 --table=table1 #### , ###pg_restore --dbname ldb1 _only_shema Conclusion
, :
— master-standby ;
— failover ( repmgr'a);
— ( ) haproxy pgbouncer( );
— — keepalived ip , “” ;
— ( ) — );
— — repmgr bash ;
— “ ”.
, , HA Postgresql Failover.
Source: https://habr.com/ru/post/314000/
All Articles