How git works
This essay describes the Git workflow. It is assumed that you are familiar with Git enough to use it to control the versions of your projects.
The essay focuses on the structure of the graph on which Git is based, and how the properties of this graph determine the behavior of Git. Studying the basics, you build your presentation on reliable information, and not on hypotheses derived from experiments with API. The correct model will allow you to better understand what Git did, what it does and what it is going to do.
The text is divided into a series of teams working with a single project. Sometimes there are observations about the data structure of the graph underlying Git. The observations illustrate the property of the graph and the behavior based on it.
')
After reading for an even deeper immersion, you can refer to the abundantly commented source code of my Git implementation in JavaScript.
User creates an alpha directory
It moves to this directory and creates a data directory. Inside, he creates a letter.txt file with the contents of "a." The alpha directory looks like this:
git init adds the current directory to the git repository. To do this, it creates a .git directory and creates several files in it. They define the entire Git configuration and project history. These are ordinary files - no magic. The user can read and edit them. That is - the user can read and edit the history of the project as easy as the files of the project itself.
Now the alpha directory looks like this:
The .git directory with its contents belongs with Git. All other files are called working copy and belong to the user.
The user runs git add on data / letter.txt. Two things happen.
First, a new blob file is created in the .git / objects / directory. It contains the compressed content of data / letter.txt. Its name is the generated hash based on the content. For example, Git makes a hash from a and gets 2e65efe2a145dda7ee51d1741299f848e5bf752e. The first two characters of the hash are used for the directory name in the object database: .git / objects / 2e /. The remainder of the hash is the name of the blob file containing the internals of the added file: .git / objects / 2e / 65efe2a145dda7ee51d1741299f848e5bf752e.
Notice that simply adding a file to Git saves its contents in the objects directory. It will be stored there if the user deletes data / letter.txt from the working copy.
Second, git add adds the file to the index. The index is a list containing all the files that Git was told to follow. It is stored in .git / index. Each line gives a hash of its contents and the time of addition to the monitored file. This is what the index contents after the git add command is:
The user creates the data / number.txt file containing 1234.
The working copy looks like this:
The user adds the file to Git.
The git add command creates a blob file that stores the contents of data / number.txt. It adds an entry to the index for data / number.txt pointing to a blob. Here is the index content after re-running git add:
Notice that the index lists only files from the data directory, although the user gave the git add data command. The data directory itself is not specified separately.
When the user created data / number.txt, he wanted to write 1, not 1234. He makes a change and adds the file to the index again. This command creates a new blob with new content. It updates the index entry for data / number.txt indicating the new blob.
User makes commit a1. Git displays information about it. We will explain them soon.
The commit command has three steps. It creates a graph representing the contents of the version of the project that is committed. It creates a commit object. It sends the current branch to a new commit object.
Git remembers the current state of the project by creating a tree graph from the index. This graph records the location and contents of each file in the project.
The graph consists of two types of objects: blobs and trees. Blobs are saved via git add. They represent the contents of the files. Trees are saved at commit. The tree represents the directory in the working copy. Below is the tree object that recorded the contents of the data directory with a new commit.
The first line records everything needed to reproduce data / letter.txt. The first part stores file permissions. The second is that the contents of the file are stored in a blob, and not in a tree. The third is a blob hash. The fourth is the file name.
The second line in the same way applies to data / number.txt.
Below is the tree object for alpha, the root directory of the project:
A single line points to the data tree.

In the above graph, the root tree points to the data tree. The data tree indicates blobs for data / letter.txt and data / number.txt.
git commit creates a commit object after creating a graph. A commit object is another text file in .git / objects /:
The first line indicates the tree of the graph. The hash is for the tree object representing the root of the working copy. That is, alpha directories. The last line is a commit comment.

Finally, the commit command directs the current branch to a new commit object.
What is our current branch? Git goes to the HEAD file in .git / HEAD and sees:
This means HEAD points to master. master is the current branch.
HEAD and master are links. A link is a label used by Git, or by the user, to identify a specific commit.
The file representing the master link does not exist, as this is the first commit in the repository. Git creates a file in .git / refs / heads / master and sets its contents — the hash of the commit object:
(If you are typing into Git commands in parallel with reading, your a1 hash will be different from mine. The hash of content objects — blobs and trees — is always the same. But no commits, because they take into account the dates and names of the creators).
Add Git HEAD and master to the graph:

HEAD points to master, just as before the commit. But now master exists and points to a new commit object.
Below is the graph after commit a1. Working copy and index included.

Notice that the working copy, index, and commit have the same content data / letter.txt and data / number.txt. Index and HEAD use hashes to indicate blobs, but the contents of the working copy are stored as text elsewhere.
The user changes the data / number.txt contents to 2. This updates the working copy, but leaves the index and HEAD unchanged.
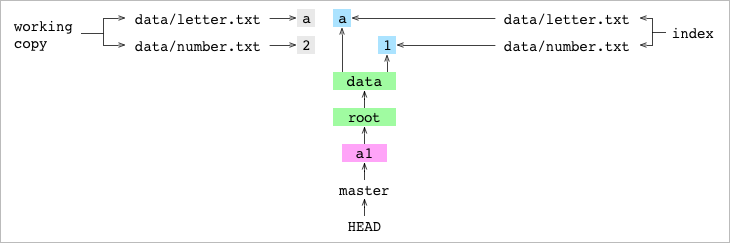
The user adds the file to Git. This adds a blob containing 2 to the objects directory. Index entry pointer for data / number.txt points to a new blob.
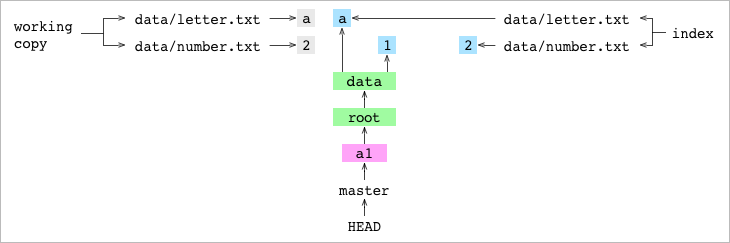
The user makes a commit. His steps are the same as before.
First, a new tree graph is created to represent the contents of the index.
The entry in the index for data / number.txt has changed. The old data tree no longer reflects the indexed state of the data directory. You need to create a new data tree object.
The hash of the new object is different from the old data tree. You need to create a new root tree to write this hash.
Secondly, a new commit object is created.
The first line of the commit object points to the new root object. The second line indicates a1: parent commit. To find the parent commit, Git goes to HEAD, goes to master and finds the hash of a1.
Third, the contents of the master branch file are changed to the hash of the new commit.
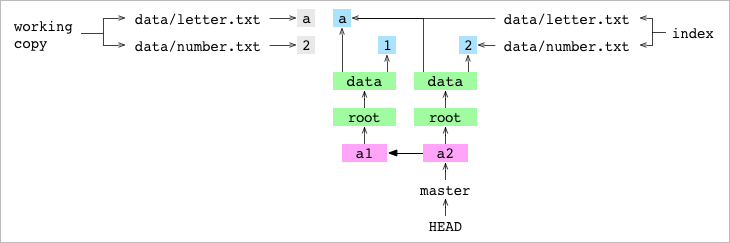
Commit a2

Git graph without working copy and index
Properties of the graph:
• Content is stored as a tree of objects. This means that only changes are stored in the database. Take a look at the graph above. Commit a2 reuses a blob made before commit a1. In the same way, if the entire directory from commit to commit does not change, its tree and all blobs and underlying trees can be reused. Usually the changes between commits are small. This means that Git can store large commit stories, taking up little space.
• Each commit has an ancestor. This means that the history of the project can be stored in the repository.
• Links - input points for a particular commit history. This means that commits can be given meaningful names. The user organizes the work in the form of a pedigree, meaningful for his project, with links like fix-for-bug-376. Git uses symbolic links like HEAD, MERGE_HEAD and FETCH_HEAD to support the commit history editing command.
• The nodes in the objects / directory are immutable. This means that the content is edited but not deleted. Every piece of content added ever, every commit made is stored somewhere in the objects directory.
• Links are changeable. Hence, the meaning of the link may change. The commit pointed to by master may be the best version of the project at the moment, but it may soon be replaced by a new commit.
• Working copy and referenced commits are immediately available. Other commits are not. This means that recent history is easier to call, but it also changes more often. We can say that the memory of Git is constantly disappearing, and it must be stimulated by more and more hard butting.
A working copy is easiest to retrieve from history because it is at the root of the repository. Her call doesn't even require a git command. But it is also the most inconstant point in history. A user can make a dozen versions of a file, but Git will not write any of them until they are added.
The commit that HEAD points to is very easy to call. It is at the end of the confirmed branch. To view its contents, the user can simply save and then examine the working copy. And at the same time, HEAD is the most frequently changing link.
The commit to which a particular link points is easy to call. The user simply confirms this thread. The end of a branch changes less often than HEAD, but it is enough to change the meaning of the name of the branch.
It is difficult to cause a commit that is not referenced. The further the user moves away from the link, the harder it is for him to recreate the meaning of the commit. But the farther he goes into the past, the less likely it is that someone has changed the story since their last viewing.
The user confirms commit a2 using his hash. (If you run these commands, then this command will not work for you. Use git log to find out the hash of your commit a2).
The confirmation consists of four steps.
First, Git gets commit a2 and the graph it points to.
Secondly, he takes notes on the files in the graph in the working copy. As a result, no changes occur. The working copy already contains the contents of the graph, since HEAD already pointed to a2 commit via master.
Thirdly, Git makes entries about the files in the graph in the index. Here, too, changes do not occur. The index already contains commit a2.
Fourth, the HEAD content is assigned to the a2 commit hash:
Writing a hash in HEAD results in a repository in a state with a separate HEAD. Notice in the box below that HEAD points directly to commit a2, and not to master.

The user writes the value 3 to the contents of data / number.txt and commits the change. Git goes to HEAD to get the parent of commit a3. Instead of finding and following a link to a branch, it finds and returns the a2 commit hash.
Git is updating HEAD so that it points to the hash of new commit a3. The repository is still in a state with a separate HEAD. It is not on a branch, since no commit indicates either a3 or any of its descendants. It's easy to lose.
Next we will omit the trees and blobs from the graph charts.

Create a branch
The user creates a new branch called deputy. As a result, a new file in .git / refs / heads / deputy appears, containing the hash pointed to by HEAD: commit a3 hash.
Branches are only links, and links are only files. This means that Git branches weigh very little.
Creating a deputy branch places a new commit a3 on the branch. HEAD is still separated because it still points directly to the commit.

The user confirms the master branch.
First, Git gets the commit a2, pointed to by master, and gets the graph pointed to by commit.
Secondly, Git makes file entries in the graph in the working copy files. This changes the data / number.txt content to 2.
Third, Git makes file entries in the index graph. This updates the entry for data / number.txt on the hash of the blob 2.
Fourth, Git sends HEAD to master, changing its contents from hash to

Confirm branch incompatible with working copy
The user accidentally assigns the content to data / number.txt a value of 789. He is trying to confirm the deputy. Git prevents confirmation.
HEAD points to the master pointing to a2, where it is recorded in data / number.txt 2. deputy points to a3, where it is recorded in data / number.txt 3. In the working copy version for data / number.txt, 789 is written. All these versions different, and the difference needs to be somehow eliminated.
Git can replace the version of the working copy with the version from the confirmed commit. But he avoids data loss with all his might.
Git can merge the version of the working copy with the confirmed version. But it is difficult.
Therefore, Git rejects confirmation.
The user notices that he accidentally edited data / number.txt and assigns him back 2. Then he successfully confirms the deputy.

User includes master in deputy. Merging two branches means merging two commits. The first commit is the one pointed to by the deputy: the receiver. The second commit is the one pointed to by master: the giver. Git does nothing to merge. He reports that he is already "Already up-to-date".
A series of associations in the graph is interpreted as a series of changes to the repository contents. This means that when merged, if the commit of the giver is obtained as the ancestor of the host commit, Git does nothing. These changes have already been made.
The user confirms the master.
It includes a deputy in the master. Git discovers that the commit commit, a2, is the ancestor of the giver’s commit, a3. It can do the fast forward forwarding.
He takes the commit of the giver and the graph to which he points. It makes file entries in the working copy and index columns. Then he “rewinds” the master to point to a3.

A series of commits on a graph is interpreted as a series of changes to the repository contents. This means that when combined, if the giver is a descendant of the receiver, the story does not change. There is already a sequence of commits describing the necessary changes: a sequence of commits between the receiver and the giver. But, although the history of Git does not change, the Git graph is changing. The specific link that HEAD points to is updated to indicate the commit's commit.
The user writes 4 to the contents of number.txt and commits the change to master.
The user confirms the deputy. He writes “b” to the contents of data / letter.txt and commits the change to deputy.

Commits can have common parents. This means that in the history of commits you can create new genealogies.
A commit can have multiple parents. This means that different pedigrees can be combined by a commit with two parents: a unifying commit.
User merges master with deputy.
Git discovers that the receiver, b3, and the giver, a4, are in different pedigrees. He performs a commit commit. This process has eight steps.
1. Git writes the hash of the commit commit to the alpha / .git / MERGE_HEAD file. The presence of this file tells Git that it is in the process of being merged.
2. Secondly, Git finds the base commit: the newest ancestor, common to the giving and receiving commits.
Commits have parents. This means that you can find the point at which the two pedigrees are divided. Git tracks the chain back from b3 to find all its ancestors, and back from a4 for the same purpose. He finds the newest of their common ancestors, a3. This is a basic commit.
3. Git creates indices for base, giver and host commits from their tree graphs.
4. Git creates a diff that merges the changes that the commit and giver commits to the baseline. This diff is a list of file paths that indicate changes: add, delete, modify, or conflict.
Git gets a list of all the files in the indices of the base commit that receives and gives. For each, he compares the entries in the indexes and decides how to change the file. He writes the corresponding entry in diff. In our case, there are two entries in diff.
The first entry for data / letter.txt. The contents of this file are “a” in the base file, “b” in the receiver and “a” in the giver. The content of the base and the receiver is different. But at the base and the giver - the same. Git sees that the content has been changed by the recipient, not the giver. The diff entry for data / letter.txt is a change, not a conflict.
The second entry in diff is for data / number.txt. In this case, the content is the same for the base and the receiver, and for the one who gives it is different. The diff entry for data / number.txt is also a change.
It is possible to find a base commit association. This means that if a file differs from the base only in the recipient or the giver, Git can automatically merge the file. This reduces the work that the user must do.
5. The changes described by the diff entries apply to the working copy. The contents of data / letter.txt are set to b, and the contents of data / number.txt are set to 4.
6. The changes described by the diff entries apply to the index. The entry for data / letter.txt points to blob b, and the entry for data / number.txt points to blob 4.
7. Confirmed updated index:
Please note that a commit has two parents.
8. Git sends the current branch, the deputy, to a new commit.

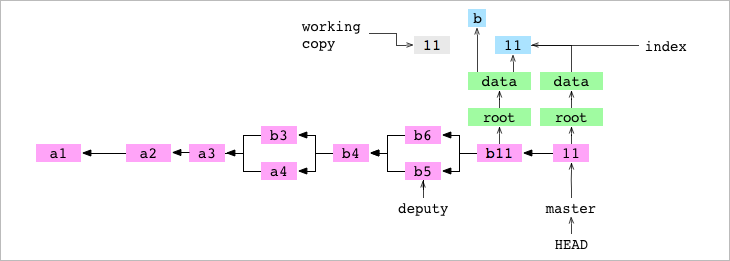
The user confirms the master. He combines the deputy and master. This causes the master to rewind to commit b4. Now master and deputy point to the same commit.

The user confirms the deputy. It sets the contents of data / number.txt to 5 and confirms the change in the deputy.
The user confirms the master. It sets the contents of data / number.txt to 6 and confirms the change to master.

deputy master. . , : .git/MERGE_HEAD, , , , diff, . - . , .
1. Git .git/MERGE_HEAD.

2. Git finds a base commit, b4.
3. Git generates indices for basic, committing and giving commits.
4. Git generates a diff that combines changes to the base commit made by the receive and give commits. This diff is a list of paths to files indicating changes: add, delete, modify, or conflict.
In this case, diff contains only one entry: data / number.txt. It is marked as a conflict, since the content of data / number.txt is different in the giving, receiving and basic commits.
5. Changes made by diff entries apply to the working copy. In the conflict area, Git prints both versions to a working copy file. The contents of the ata / number.txt file becomes the following:
6. The changes defined by the diff entries apply to the index. Entries in the index have a unique identifier in the form of a combination of file path and stage. For a file entry without conflict, the stage is 0. Before the union, the index looked like this, where the zeros are the numbers of the stages:
After writing diff to the index, it looks like this:
The data / letter.txt entry in step 0 is the same as it was before the merge. The entry for data / number.txt with step 0 disappeared. Instead, there are three new ones. The entry with stage 1 hash from the base content of data / number.txt. The entry with stage 3 hash from the content of the data / number.txt giver. The presence of three entries tells Git that a conflict has arisen for data / number.txt.
Merging is suspended.
The user integrates the contents of the two conflicting versions, setting the contents of data / number.txt to 11. It adds the file to the index. Git adds a blob containing 11. Adding a conflict file tells Git that the conflict has been resolved. Git removes the data / number.txt occurrences for steps 1, 2 and 3 from the index. It adds an entry for data / number.txt in step 0 with a hash from the new blob. Now the index contains entries:
7. User commits. Git sees it in the .git / MERGE_HEAD repository, which tells it that merging is in progress. It checks the index and does not detect conflicts. He creates a new commit, b11, to record the contents of the allowed join. It deletes the .git / MERGE_HEAD file. This completes the merger.
8. Git sends the current branch, master, to the new commit.

The chart for the Git graph includes the commit history, trees and blobs of the last commit, working copy and index:

User instructs Git to remove data / letter.txt. The file is deleted from the working copy. An entry is removed from the index.

The user makes a commit. As usual with commits, Git builds a graph representing the contents of the index. data / letter.txt is not included in the graph since it is not in the index.
The user copies the contents of the alpha / repository to the bravo / directory. This leads to the following structure:
Now in the bravo directory there is a new Git graph:

The user is returned to the alpha repository. He assigns bravo to the remote repository for alpha. This adds several lines to the alpha / .git / config file:
The lines say that there is a bravo remote repository in the ../bravo directory.
The user goes to the bravo repository. It sets the content of data / number.txt to 12 and commits the change to master to bravo.

The user goes to the alpha repository. It copies the master from bravo to alpha. This process has four steps.
1. Git gets the commit hash that master points to in bravo. This is a hash of commit 12.
2. Git makes a list of all objects on which commit 12 depends: the commit object itself, the objects in its graph, commits of the ancestor of commit 12, and objects from their graphs. It removes from this list all the objects that already exist in the alpha database. He copies the rest to alpha / .git / objects /.
3. The content of the specific reference file in alpha / .git / refs / remotes / bravo / master is assigned the hash of commit 12.
4. The content of alpha / .git / FETCH_HEAD becomes the following:
This means that the most recent fetch command got commit 12 from master with bravo.

Objects can be copied. This means that different repositories can have a common story.
Repositories can store links to remote branches of the type alpha / .git / refs / remotes / bravo / master. This means that the repository can locally record the state of the branch of the remote repository. It is correct when it is copied, but will become obsolete if the remote branch changes.
User merges FETCH_HEAD. FETCH_HEAD is just another link. She points to commit 12, giving. HEAD points to commit 11, the host. Git does a rewind join and sends the master to commit 12.

User transfers master from bravo to alpha. Pull is short for “copy and merge FETCH_HEAD”. Git executes both commands and reports that the master is “Already up-to-date”.
The user moves to the top directory. He clones alpha into charlie. Cloning produces results similar to the cp command that the user performed to create the bravo repository. Git creates a new charlie directory. It initializes charlie as a repository, adds alpha as remote as origin, gets origin, and combines FETCH_HEAD.
The user is returned to the alpha repository. Sets the content of data / number.txt to 13 and commits the change to master to alpha.
It assigns charlie the remote alpha repository
He places the master on charlie. All objects needed for commit 13 are copied to charlie.
At this point, the placement process stops. Git, as always, tells the user what went wrong. He refuses to post on a branch that is confirmed remotely. It makes sense. Placement would update the remote index and HEAD. This would cause confusion if someone else edited a working copy on a remote repository.
At this point, the user can create a new branch, merge commit 13 with it, and place this branch on charlie. But users need a repository on which you can post anything. They need a central repository, on which they can be placed, and from which they can be received (pull), but to which no one directly commits. They need something like a remote github. They need a clean (bare) repository.
The user goes to the top directory. It creates a delta clone as a clean repository. This is a common clone with two features. The config file says that the repository is clean. And the files usually stored in the .git directory are stored in the root of the repository:
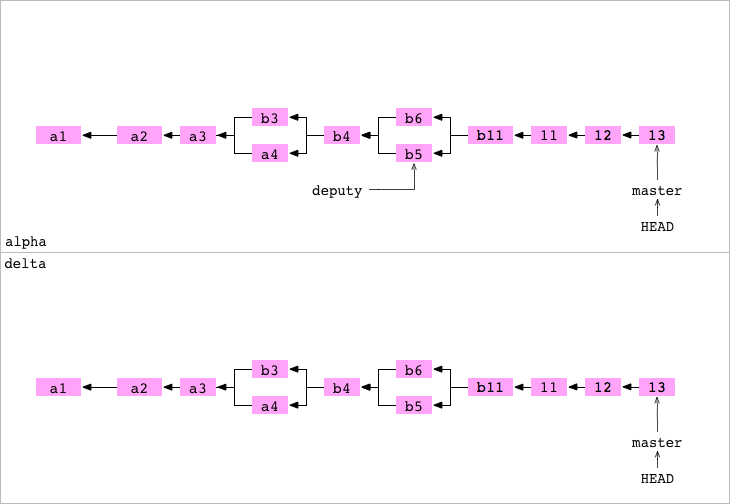
The user is returned to the alpha repository. It assigns the delta as the remote repository for alpha.
It sets the content to 14 and commits the change to master to alpha.

It places the master in delta. Placement takes place in three stages.
1. All objects required for commit 14 on the master branch are copied from alpha / .git / objects / to delta / objects /.
2. delta / refs / heads / master is updated to commit 14.
3. alpha / .git / refs / remotes / delta / master is sent to commit 14. The current status record delta is in alpha.

Git is built on a graph. Almost all Git commands manipulate this graph. To understand Git, focus on the properties of the graph, not the procedures or commands.
To learn more about Git, explore the .git directory. It's not scary.Look inside. Change the contents of the files and see what happens. Create a commit manually. Try to see how hard you can break the repository. Then fix it.
The essay focuses on the structure of the graph on which Git is based, and how the properties of this graph determine the behavior of Git. Studying the basics, you build your presentation on reliable information, and not on hypotheses derived from experiments with API. The correct model will allow you to better understand what Git did, what it does and what it is going to do.
The text is divided into a series of teams working with a single project. Sometimes there are observations about the data structure of the graph underlying Git. The observations illustrate the property of the graph and the behavior based on it.
')
After reading for an even deeper immersion, you can refer to the abundantly commented source code of my Git implementation in JavaScript.
Project creation
~ $ mkdir alpha ~ $ cd alpha User creates an alpha directory
~/alpha $ mkdir data ~/alpha $ printf 'a' > data/letter.txt It moves to this directory and creates a data directory. Inside, he creates a letter.txt file with the contents of "a." The alpha directory looks like this:
alpha └── data └── letter.txt Initialize the repository
~/alpha $ git init Initialized empty Git repository git init adds the current directory to the git repository. To do this, it creates a .git directory and creates several files in it. They define the entire Git configuration and project history. These are ordinary files - no magic. The user can read and edit them. That is - the user can read and edit the history of the project as easy as the files of the project itself.
Now the alpha directory looks like this:
alpha ├── data | └── letter.txt └── .git ├── objects etc... The .git directory with its contents belongs with Git. All other files are called working copy and belong to the user.
Add files
~/alpha $ git add data/letter.txt The user runs git add on data / letter.txt. Two things happen.
First, a new blob file is created in the .git / objects / directory. It contains the compressed content of data / letter.txt. Its name is the generated hash based on the content. For example, Git makes a hash from a and gets 2e65efe2a145dda7ee51d1741299f848e5bf752e. The first two characters of the hash are used for the directory name in the object database: .git / objects / 2e /. The remainder of the hash is the name of the blob file containing the internals of the added file: .git / objects / 2e / 65efe2a145dda7ee51d1741299f848e5bf752e.
Notice that simply adding a file to Git saves its contents in the objects directory. It will be stored there if the user deletes data / letter.txt from the working copy.
Second, git add adds the file to the index. The index is a list containing all the files that Git was told to follow. It is stored in .git / index. Each line gives a hash of its contents and the time of addition to the monitored file. This is what the index contents after the git add command is:
data/letter.txt 2e65efe2a145dda7ee51d1741299f848e5bf752e The user creates the data / number.txt file containing 1234.
~/alpha $ printf '1234' > data/number.txt The working copy looks like this:
alpha └── data └── letter.txt └── number.txt The user adds the file to Git.
~/alpha $ git add data The git add command creates a blob file that stores the contents of data / number.txt. It adds an entry to the index for data / number.txt pointing to a blob. Here is the index content after re-running git add:
data/letter.txt 2e65efe2a145dda7ee51d1741299f848e5bf752e data/number.txt 274c0052dd5408f8ae2bc8440029ff67d79bc5c3 Notice that the index lists only files from the data directory, although the user gave the git add data command. The data directory itself is not specified separately.
~/alpha $ printf '1' > data/number.txt ~/alpha $ git add data When the user created data / number.txt, he wanted to write 1, not 1234. He makes a change and adds the file to the index again. This command creates a new blob with new content. It updates the index entry for data / number.txt indicating the new blob.
Making a commit
~/alpha $ git commit -m 'a1' [master (root-commit) 774b54a] a1 User makes commit a1. Git displays information about it. We will explain them soon.
The commit command has three steps. It creates a graph representing the contents of the version of the project that is committed. It creates a commit object. It sends the current branch to a new commit object.
Creating a graph
Git remembers the current state of the project by creating a tree graph from the index. This graph records the location and contents of each file in the project.
The graph consists of two types of objects: blobs and trees. Blobs are saved via git add. They represent the contents of the files. Trees are saved at commit. The tree represents the directory in the working copy. Below is the tree object that recorded the contents of the data directory with a new commit.
100664 blob 2e65efe2a145dda7ee51d1741299f848e5bf752e letter.txt 100664 blob 56a6051ca2b02b04ef92d5150c9ef600403cb1de number.txt The first line records everything needed to reproduce data / letter.txt. The first part stores file permissions. The second is that the contents of the file are stored in a blob, and not in a tree. The third is a blob hash. The fourth is the file name.
The second line in the same way applies to data / number.txt.
Below is the tree object for alpha, the root directory of the project:
040000 tree 0eed1217a2947f4930583229987d90fe5e8e0b74 data A single line points to the data tree.
In the above graph, the root tree points to the data tree. The data tree indicates blobs for data / letter.txt and data / number.txt.
Creating a commit object
git commit creates a commit object after creating a graph. A commit object is another text file in .git / objects /:
tree ffe298c3ce8bb07326f888907996eaa48d266db4 author Mary Rose Cook <mary@maryrosecook.com> 1424798436 -0500 committer Mary Rose Cook <mary@maryrosecook.com> 1424798436 -0500 a1 The first line indicates the tree of the graph. The hash is for the tree object representing the root of the working copy. That is, alpha directories. The last line is a commit comment.
Send current branch to new commit
Finally, the commit command directs the current branch to a new commit object.
What is our current branch? Git goes to the HEAD file in .git / HEAD and sees:
ref: refs/heads/master This means HEAD points to master. master is the current branch.
HEAD and master are links. A link is a label used by Git, or by the user, to identify a specific commit.
The file representing the master link does not exist, as this is the first commit in the repository. Git creates a file in .git / refs / heads / master and sets its contents — the hash of the commit object:
74ac3ad9cde0b265d2b4f1c778b283a6e2ffbafd (If you are typing into Git commands in parallel with reading, your a1 hash will be different from mine. The hash of content objects — blobs and trees — is always the same. But no commits, because they take into account the dates and names of the creators).
Add Git HEAD and master to the graph:
HEAD points to master, just as before the commit. But now master exists and points to a new commit object.
We make not the first commit
Below is the graph after commit a1. Working copy and index included.
Notice that the working copy, index, and commit have the same content data / letter.txt and data / number.txt. Index and HEAD use hashes to indicate blobs, but the contents of the working copy are stored as text elsewhere.
~/alpha $ printf '2' > data/number.txt The user changes the data / number.txt contents to 2. This updates the working copy, but leaves the index and HEAD unchanged.
~/alpha $ git add data/number.txt The user adds the file to Git. This adds a blob containing 2 to the objects directory. Index entry pointer for data / number.txt points to a new blob.
~/alpha $ git commit -m 'a2' [master f0af7e6] a2 The user makes a commit. His steps are the same as before.
First, a new tree graph is created to represent the contents of the index.
The entry in the index for data / number.txt has changed. The old data tree no longer reflects the indexed state of the data directory. You need to create a new data tree object.
100664 blob 2e65efe2a145dda7ee51d1741299f848e5bf752e letter.txt 100664 blob d8263ee9860594d2806b0dfd1bfd17528b0ba2a4 number.txt The hash of the new object is different from the old data tree. You need to create a new root tree to write this hash.
040000 tree 40b0318811470aaacc577485777d7a6780e51f0b data Secondly, a new commit object is created.
tree ce72afb5ff229a39f6cce47b00d1b0ed60fe3556 parent 774b54a193d6cfdd081e581a007d2e11f784b9fe author Mary Rose Cook <mary@maryrosecook.com> 1424813101 -0500 committer Mary Rose Cook <mary@maryrosecook.com> 1424813101 -0500 a2 The first line of the commit object points to the new root object. The second line indicates a1: parent commit. To find the parent commit, Git goes to HEAD, goes to master and finds the hash of a1.
Third, the contents of the master branch file are changed to the hash of the new commit.
Commit a2
Git graph without working copy and index
Properties of the graph:
• Content is stored as a tree of objects. This means that only changes are stored in the database. Take a look at the graph above. Commit a2 reuses a blob made before commit a1. In the same way, if the entire directory from commit to commit does not change, its tree and all blobs and underlying trees can be reused. Usually the changes between commits are small. This means that Git can store large commit stories, taking up little space.
• Each commit has an ancestor. This means that the history of the project can be stored in the repository.
• Links - input points for a particular commit history. This means that commits can be given meaningful names. The user organizes the work in the form of a pedigree, meaningful for his project, with links like fix-for-bug-376. Git uses symbolic links like HEAD, MERGE_HEAD and FETCH_HEAD to support the commit history editing command.
• The nodes in the objects / directory are immutable. This means that the content is edited but not deleted. Every piece of content added ever, every commit made is stored somewhere in the objects directory.
• Links are changeable. Hence, the meaning of the link may change. The commit pointed to by master may be the best version of the project at the moment, but it may soon be replaced by a new commit.
• Working copy and referenced commits are immediately available. Other commits are not. This means that recent history is easier to call, but it also changes more often. We can say that the memory of Git is constantly disappearing, and it must be stimulated by more and more hard butting.
A working copy is easiest to retrieve from history because it is at the root of the repository. Her call doesn't even require a git command. But it is also the most inconstant point in history. A user can make a dozen versions of a file, but Git will not write any of them until they are added.
The commit that HEAD points to is very easy to call. It is at the end of the confirmed branch. To view its contents, the user can simply save and then examine the working copy. And at the same time, HEAD is the most frequently changing link.
The commit to which a particular link points is easy to call. The user simply confirms this thread. The end of a branch changes less often than HEAD, but it is enough to change the meaning of the name of the branch.
It is difficult to cause a commit that is not referenced. The further the user moves away from the link, the harder it is for him to recreate the meaning of the commit. But the farther he goes into the past, the less likely it is that someone has changed the story since their last viewing.
Confirm (check out) commit
~/alpha $ git checkout 37888c2 You are in 'detached HEAD' state... The user confirms commit a2 using his hash. (If you run these commands, then this command will not work for you. Use git log to find out the hash of your commit a2).
The confirmation consists of four steps.
First, Git gets commit a2 and the graph it points to.
Secondly, he takes notes on the files in the graph in the working copy. As a result, no changes occur. The working copy already contains the contents of the graph, since HEAD already pointed to a2 commit via master.
Thirdly, Git makes entries about the files in the graph in the index. Here, too, changes do not occur. The index already contains commit a2.
Fourth, the HEAD content is assigned to the a2 commit hash:
f0af7e62679e144bb28c627ee3e8f7bdb235eee9 Writing a hash in HEAD results in a repository in a state with a separate HEAD. Notice in the box below that HEAD points directly to commit a2, and not to master.
~/alpha $ printf '3' > data/number.txt ~/alpha $ git add data/number.txt ~/alpha $ git commit -m 'a3' [detached HEAD 3645a0e] a3 The user writes the value 3 to the contents of data / number.txt and commits the change. Git goes to HEAD to get the parent of commit a3. Instead of finding and following a link to a branch, it finds and returns the a2 commit hash.
Git is updating HEAD so that it points to the hash of new commit a3. The repository is still in a state with a separate HEAD. It is not on a branch, since no commit indicates either a3 or any of its descendants. It's easy to lose.
Next we will omit the trees and blobs from the graph charts.
Create a branch
~/alpha $ git branch deputy The user creates a new branch called deputy. As a result, a new file in .git / refs / heads / deputy appears, containing the hash pointed to by HEAD: commit a3 hash.
Branches are only links, and links are only files. This means that Git branches weigh very little.
Creating a deputy branch places a new commit a3 on the branch. HEAD is still separated because it still points directly to the commit.
Confirm branch
~/alpha $ git checkout master Switched to branch 'master' The user confirms the master branch.
First, Git gets the commit a2, pointed to by master, and gets the graph pointed to by commit.
Secondly, Git makes file entries in the graph in the working copy files. This changes the data / number.txt content to 2.
Third, Git makes file entries in the index graph. This updates the entry for data / number.txt on the hash of the blob 2.
Fourth, Git sends HEAD to master, changing its contents from hash to
ref: refs/heads/master Confirm branch incompatible with working copy
~/alpha $ printf '789' > data/number.txt ~/alpha $ git checkout deputy Your changes to these files would be overwritten by checkout: data/number.txt Commit your changes or stash them before you switch branches. The user accidentally assigns the content to data / number.txt a value of 789. He is trying to confirm the deputy. Git prevents confirmation.
HEAD points to the master pointing to a2, where it is recorded in data / number.txt 2. deputy points to a3, where it is recorded in data / number.txt 3. In the working copy version for data / number.txt, 789 is written. All these versions different, and the difference needs to be somehow eliminated.
Git can replace the version of the working copy with the version from the confirmed commit. But he avoids data loss with all his might.
Git can merge the version of the working copy with the confirmed version. But it is difficult.
Therefore, Git rejects confirmation.
~/alpha $ printf '2' > data/number.txt ~/alpha $ git checkout deputy Switched to branch 'deputy' The user notices that he accidentally edited data / number.txt and assigns him back 2. Then he successfully confirms the deputy.
Ancestor Union
~/alpha $ git merge master Already up-to-date. User includes master in deputy. Merging two branches means merging two commits. The first commit is the one pointed to by the deputy: the receiver. The second commit is the one pointed to by master: the giver. Git does nothing to merge. He reports that he is already "Already up-to-date".
A series of associations in the graph is interpreted as a series of changes to the repository contents. This means that when merged, if the commit of the giver is obtained as the ancestor of the host commit, Git does nothing. These changes have already been made.
Association with the descendant
~/alpha $ git checkout master Switched to branch 'master' The user confirms the master.
~/alpha $ git merge deputy Fast-forward It includes a deputy in the master. Git discovers that the commit commit, a2, is the ancestor of the giver’s commit, a3. It can do the fast forward forwarding.
He takes the commit of the giver and the graph to which he points. It makes file entries in the working copy and index columns. Then he “rewinds” the master to point to a3.
A series of commits on a graph is interpreted as a series of changes to the repository contents. This means that when combined, if the giver is a descendant of the receiver, the story does not change. There is already a sequence of commits describing the necessary changes: a sequence of commits between the receiver and the giver. But, although the history of Git does not change, the Git graph is changing. The specific link that HEAD points to is updated to indicate the commit's commit.
Merge two commits from different pedigrees
~/alpha $ printf '4' > data/number.txt ~/alpha $ git add data/number.txt ~/alpha $ git commit -m 'a4' [master 7b7bd9a] a4 The user writes 4 to the contents of number.txt and commits the change to master.
~/alpha $ git checkout deputy Switched to branch 'deputy' ~/alpha $ printf 'b' > data/letter.txt ~/alpha $ git add data/letter.txt ~/alpha $ git commit -m 'b3' [deputy 982dffb] b3 The user confirms the deputy. He writes “b” to the contents of data / letter.txt and commits the change to deputy.
Commits can have common parents. This means that in the history of commits you can create new genealogies.
A commit can have multiple parents. This means that different pedigrees can be combined by a commit with two parents: a unifying commit.
~/alpha $ git merge master -m 'b4' Merge made by the 'recursive' strategy. User merges master with deputy.
Git discovers that the receiver, b3, and the giver, a4, are in different pedigrees. He performs a commit commit. This process has eight steps.
1. Git writes the hash of the commit commit to the alpha / .git / MERGE_HEAD file. The presence of this file tells Git that it is in the process of being merged.
2. Secondly, Git finds the base commit: the newest ancestor, common to the giving and receiving commits.
Commits have parents. This means that you can find the point at which the two pedigrees are divided. Git tracks the chain back from b3 to find all its ancestors, and back from a4 for the same purpose. He finds the newest of their common ancestors, a3. This is a basic commit.
3. Git creates indices for base, giver and host commits from their tree graphs.
4. Git creates a diff that merges the changes that the commit and giver commits to the baseline. This diff is a list of file paths that indicate changes: add, delete, modify, or conflict.
Git gets a list of all the files in the indices of the base commit that receives and gives. For each, he compares the entries in the indexes and decides how to change the file. He writes the corresponding entry in diff. In our case, there are two entries in diff.
The first entry for data / letter.txt. The contents of this file are “a” in the base file, “b” in the receiver and “a” in the giver. The content of the base and the receiver is different. But at the base and the giver - the same. Git sees that the content has been changed by the recipient, not the giver. The diff entry for data / letter.txt is a change, not a conflict.
The second entry in diff is for data / number.txt. In this case, the content is the same for the base and the receiver, and for the one who gives it is different. The diff entry for data / number.txt is also a change.
It is possible to find a base commit association. This means that if a file differs from the base only in the recipient or the giver, Git can automatically merge the file. This reduces the work that the user must do.
5. The changes described by the diff entries apply to the working copy. The contents of data / letter.txt are set to b, and the contents of data / number.txt are set to 4.
6. The changes described by the diff entries apply to the index. The entry for data / letter.txt points to blob b, and the entry for data / number.txt points to blob 4.
7. Confirmed updated index:
tree 20294508aea3fb6f05fcc49adaecc2e6d60f7e7d parent 982dffb20f8d6a25a8554cc8d765fb9f3ff1333b parent 7b7bd9a5253f47360d5787095afc5ba56591bfe7 author Mary Rose Cook <mary@maryrosecook.com> 1425596551 -0500 committer Mary Rose Cook <mary@maryrosecook.com> 1425596551 -0500 b4 Please note that a commit has two parents.
8. Git sends the current branch, the deputy, to a new commit.
Combining two commits from different pedigrees, changing the same file
~/alpha $ git checkout master Switched to branch 'master' ~/alpha $ git merge deputy Fast-forward The user confirms the master. He combines the deputy and master. This causes the master to rewind to commit b4. Now master and deputy point to the same commit.
~/alpha $ git checkout deputy Switched to branch 'deputy' ~/alpha $ printf '5' > data/number.txt ~/alpha $ git add data/number.txt ~/alpha $ git commit -m 'b5' [deputy bd797c2] b5 The user confirms the deputy. It sets the contents of data / number.txt to 5 and confirms the change in the deputy.
~/alpha $ git checkout master Switched to branch 'master' ~/alpha $ printf '6' > data/number.txt ~/alpha $ git add data/number.txt ~/alpha $ git commit -m 'b6' [master 4c3ce18] b6 The user confirms the master. It sets the contents of data / number.txt to 6 and confirms the change to master.
~/alpha $ git merge deputy CONFLICT in data/number.txt Automatic merge failed; fix conflicts and commit the result. deputy master. . , : .git/MERGE_HEAD, , , , diff, . - . , .
1. Git .git/MERGE_HEAD.
2. Git finds a base commit, b4.
3. Git generates indices for basic, committing and giving commits.
4. Git generates a diff that combines changes to the base commit made by the receive and give commits. This diff is a list of paths to files indicating changes: add, delete, modify, or conflict.
In this case, diff contains only one entry: data / number.txt. It is marked as a conflict, since the content of data / number.txt is different in the giving, receiving and basic commits.
5. Changes made by diff entries apply to the working copy. In the conflict area, Git prints both versions to a working copy file. The contents of the ata / number.txt file becomes the following:
<<<<<<< HEAD 6 ======= 5 >>>>>>> deputy 6. The changes defined by the diff entries apply to the index. Entries in the index have a unique identifier in the form of a combination of file path and stage. For a file entry without conflict, the stage is 0. Before the union, the index looked like this, where the zeros are the numbers of the stages:
0 data/letter.txt 63d8dbd40c23542e740659a7168a0ce3138ea748 0 data/number.txt 62f9457511f879886bb7728c986fe10b0ece6bcb After writing diff to the index, it looks like this:
0 data/letter.txt 63d8dbd40c23542e740659a7168a0ce3138ea748 1 data/number.txt bf0d87ab1b2b0ec1a11a3973d2845b42413d9767 2 data/number.txt 62f9457511f879886bb7728c986fe10b0ece6bcb 3 data/number.txt 7813681f5b41c028345ca62a2be376bae70b7f61 The data / letter.txt entry in step 0 is the same as it was before the merge. The entry for data / number.txt with step 0 disappeared. Instead, there are three new ones. The entry with stage 1 hash from the base content of data / number.txt. The entry with stage 3 hash from the content of the data / number.txt giver. The presence of three entries tells Git that a conflict has arisen for data / number.txt.
Merging is suspended.
~/alpha $ printf '11' > data/number.txt ~/alpha $ git add data/number.txt The user integrates the contents of the two conflicting versions, setting the contents of data / number.txt to 11. It adds the file to the index. Git adds a blob containing 11. Adding a conflict file tells Git that the conflict has been resolved. Git removes the data / number.txt occurrences for steps 1, 2 and 3 from the index. It adds an entry for data / number.txt in step 0 with a hash from the new blob. Now the index contains entries:
0 data/letter.txt 63d8dbd40c23542e740659a7168a0ce3138ea748 0 data/number.txt 9d607966b721abde8931ddd052181fae905db503 ~/alpha $ git commit -m 'b11' [master 251a513] b11 7. User commits. Git sees it in the .git / MERGE_HEAD repository, which tells it that merging is in progress. It checks the index and does not detect conflicts. He creates a new commit, b11, to record the contents of the allowed join. It deletes the .git / MERGE_HEAD file. This completes the merger.
8. Git sends the current branch, master, to the new commit.
Delete file
The chart for the Git graph includes the commit history, trees and blobs of the last commit, working copy and index:
~/alpha $ git rm data/letter.txt rm 'data/letter.txt' User instructs Git to remove data / letter.txt. The file is deleted from the working copy. An entry is removed from the index.
~/alpha $ git commit -m '11' [master d14c7d2] 11 The user makes a commit. As usual with commits, Git builds a graph representing the contents of the index. data / letter.txt is not included in the graph since it is not in the index.
Copy repository
~/alpha $ cd .. ~ $ cp -R alpha bravo The user copies the contents of the alpha / repository to the bravo / directory. This leads to the following structure:
~ ├── alpha | └── data | └── number.txt └── bravo └── data └── number.txt Now in the bravo directory there is a new Git graph:
Associate a repository with another repository.
~ $ cd alpha ~/alpha $ git remote add bravo ../bravo The user is returned to the alpha repository. He assigns bravo to the remote repository for alpha. This adds several lines to the alpha / .git / config file:
[remote "bravo"] url = ../bravo/ The lines say that there is a bravo remote repository in the ../bravo directory.
Get a branch from a remote repository
~/alpha $ cd ../bravo ~/bravo $ printf '12' > data/number.txt ~/bravo $ git add data/number.txt ~/bravo $ git commit -m '12' [master 94cd04d] 12 The user goes to the bravo repository. It sets the content of data / number.txt to 12 and commits the change to master to bravo.
~/bravo $ cd ../alpha ~/alpha $ git fetch bravo master Unpacking objects: 100% From ../bravo * branch master -> FETCH_HEAD The user goes to the alpha repository. It copies the master from bravo to alpha. This process has four steps.
1. Git gets the commit hash that master points to in bravo. This is a hash of commit 12.
2. Git makes a list of all objects on which commit 12 depends: the commit object itself, the objects in its graph, commits of the ancestor of commit 12, and objects from their graphs. It removes from this list all the objects that already exist in the alpha database. He copies the rest to alpha / .git / objects /.
3. The content of the specific reference file in alpha / .git / refs / remotes / bravo / master is assigned the hash of commit 12.
4. The content of alpha / .git / FETCH_HEAD becomes the following:
94cd04d93ae88a1f53a4646532b1e8cdfbc0977f branch 'master' of ../bravo This means that the most recent fetch command got commit 12 from master with bravo.
Objects can be copied. This means that different repositories can have a common story.
Repositories can store links to remote branches of the type alpha / .git / refs / remotes / bravo / master. This means that the repository can locally record the state of the branch of the remote repository. It is correct when it is copied, but will become obsolete if the remote branch changes.
FETCH_HEAD union
~/alpha $ git merge FETCH_HEAD Updating d14c7d2..94cd04d Fast-forward User merges FETCH_HEAD. FETCH_HEAD is just another link. She points to commit 12, giving. HEAD points to commit 11, the host. Git does a rewind join and sends the master to commit 12.
Get remote repository branch
~/alpha $ git pull bravo master Already up-to-date. User transfers master from bravo to alpha. Pull is short for “copy and merge FETCH_HEAD”. Git executes both commands and reports that the master is “Already up-to-date”.
Clone repository
~/alpha $ cd .. ~ $ git clone alpha charlie Cloning into 'charlie' The user moves to the top directory. He clones alpha into charlie. Cloning produces results similar to the cp command that the user performed to create the bravo repository. Git creates a new charlie directory. It initializes charlie as a repository, adds alpha as remote as origin, gets origin, and combines FETCH_HEAD.
Place (push) the branch on the confirmed branch on the remote repository
~ $ cd alpha ~/alpha $ printf '13' > data/number.txt ~/alpha $ git add data/number.txt ~/alpha $ git commit -m '13' [master 3238468] 13 The user is returned to the alpha repository. Sets the content of data / number.txt to 13 and commits the change to master to alpha.
~/alpha $ git remote add charlie ../charlie It assigns charlie the remote alpha repository
~/alpha $ git push charlie master Writing objects: 100% remote error: refusing to update checked out branch: refs/heads/master because it will make the index and work tree inconsistent He places the master on charlie. All objects needed for commit 13 are copied to charlie.
At this point, the placement process stops. Git, as always, tells the user what went wrong. He refuses to post on a branch that is confirmed remotely. It makes sense. Placement would update the remote index and HEAD. This would cause confusion if someone else edited a working copy on a remote repository.
At this point, the user can create a new branch, merge commit 13 with it, and place this branch on charlie. But users need a repository on which you can post anything. They need a central repository, on which they can be placed, and from which they can be received (pull), but to which no one directly commits. They need something like a remote github. They need a clean (bare) repository.
We clone clean (bare) repository
~/alpha $ cd .. ~ $ git clone alpha delta --bare Cloning into bare repository 'delta' The user goes to the top directory. It creates a delta clone as a clean repository. This is a common clone with two features. The config file says that the repository is clean. And the files usually stored in the .git directory are stored in the root of the repository:
delta ├── HEAD ├── config ├── objects └── refs Put a branch in a clean repository
~ $ cd alpha ~/alpha $ git remote add delta ../delta The user is returned to the alpha repository. It assigns the delta as the remote repository for alpha.
~/alpha $ printf '14' > data/number.txt ~/alpha $ git add data/number.txt ~/alpha $ git commit -m '14' [master cb51da8] 14 It sets the content to 14 and commits the change to master to alpha.
~/alpha $ git push delta master Writing objects: 100% To ../delta 3238468..cb51da8 master -> master It places the master in delta. Placement takes place in three stages.
1. All objects required for commit 14 on the master branch are copied from alpha / .git / objects / to delta / objects /.
2. delta / refs / heads / master is updated to commit 14.
3. alpha / .git / refs / remotes / delta / master is sent to commit 14. The current status record delta is in alpha.
Total
Git is built on a graph. Almost all Git commands manipulate this graph. To understand Git, focus on the properties of the graph, not the procedures or commands.
To learn more about Git, explore the .git directory. It's not scary.Look inside. Change the contents of the files and see what happens. Create a commit manually. Try to see how hard you can break the repository. Then fix it.
Source: https://habr.com/ru/post/313890/
All Articles