Secrets of Progressive Web Apps: Part 2
For those who missed the first part of the article: you here . Well, for everyone else, as usual, hello, Habrahabr. We continue the topic of PWA and the study of the basic synchronization algorithm (do not quit what has begun?). In the last part, we ended up with the fact that our conditional application is able to request articles from the server, receive only relevant materials, monitor changes and deletions of articles and correctly handle all this. It all worked through the calculation of the delta: the difference between what the application has and what is stored on the server.
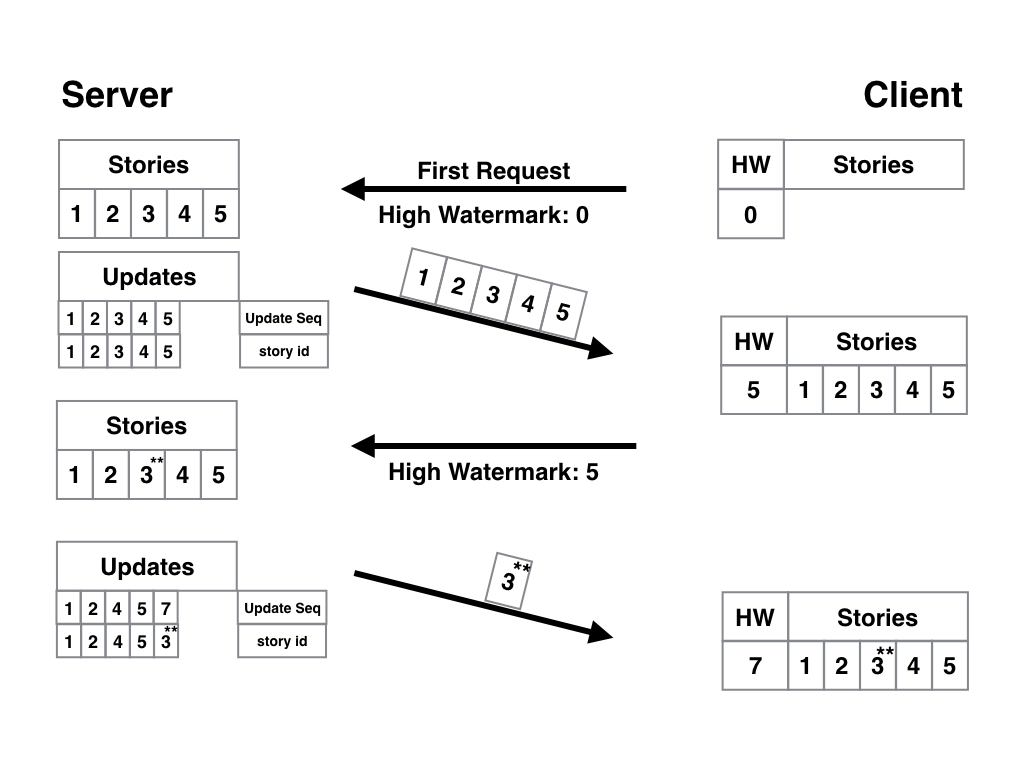
In this part we will study various specific schemes for the implementation of the theories described above, discuss their strengths and weaknesses. Well, before we start, let's describe the requirements for the desired algorithms.
We have two objects with the same ID, and we need to be able to distinguish between them: say which one is newer. That is, determine which of the objects is relevant. If we have not two, but three, five or ten - in essence, nothing changes, you just need to sort them according to their degree of relevance and be able to select the most recent, fresh, relevant of the objects. Actually, we need a version control system.
')
The first and most obvious idea is to make a trivial integer counter. "Version 1", "Version 2", ... "Version 100500" - well, you understand.

The main advantage of this thing is that everything here is clear not only to a computer, but also to a person. That is, if you climb into the database with your hands, you will immediately understand which article is relevant and which is not. So what's the problem?
Imagine that we have an article can edit a few people. One is on the server side, the other is on the client side. The first edition of the article was published with the “Version 1” index. Next, the server creates an edited document with the “Version 2” index, and the client ... and the “Version 2” is also created on the client, because “1” is followed by “2”, and the client did not know what was on the server : let's say there was no available connection at the moment.
Now we have two documents with the “Version 2” index, but we don’t know if they are the same or not. And for the client (and for the server too) both versions seem legitimate - the version counter is the same, nothing needs to be synchronized. So our versions should be described in more detailed language?
To distinguish between versions of documents with the same ID, we can record not only the counter, but also the time in which the article was saved. Whether it is October 11, 2016, 12:30:57, or just 111016123057 - it is important for us that the number be unique and express the specific state of the article.
We will not go into the details of the CORRECT description of timestamps, some types are more convenient to process on a PC, some are more convenient for the user. If you want to do it your way - do it, we just recommend using the ISO 8601 standard .

What do we have in the end? We have the same article with different timestamps, it’s easy to see which version is newer. Since the clock goes forward only, each next version of the timestamp will be exactly larger than the previous one. Or not?
Before you continue reading the article, look at this wonderful collection of rakes that programmers are attacking when they think they know how time works. He also has a second part .
Banal example. You met a charming girl in a bar, write her number on the phone. You drank enough to mix up the two numbers in some places, and it’s good that you decided to double-check. You edit the number, save the correct version, say goodbye. Our contacts have timestamps, the synchronization with the cloud was successful, so even if you lose the phone on your way home, the phone number will remain. Or not?
If you have already opened the "rake" of the links above, you will understand how much everything could happen to your address book while maintaining the second number. Even such giants as Google, with almost infinite resources, sometimes ... face problems relating to time.
In the process of updating the notebook, anything can happen. You synchronized the first version with a typo, and then bam! - the phone was synchronized with the server and switched the clock a minute ago. Or you hit exactly at midnight, daylight saving time turned on. The iPhones still have problems with alarms set on January 1st. In general, we cannot trust simple timestamps as we would like to - in our case, you would lose the girl’s phone, because in the morning you would not remember what the typo was and where ... In general, we do not need. But the time can also be unsynchronized on the client and the server ...
Let us summarize our thoughts: whatever the specific scenario may be, the problem may arise in a small project and in a large system. You cannot trust simple timestamps and guarantee the sequence of revisions of two objects, even if both timestamps were generated on one device: this behavior can lead to data loss. And this means that we need to improve the timestamps. But before that we need to consider another source of problems: conflicts.
To illustrate conflicts, we need to expand our example a little. Imagine that we have not just a club of interesting articles, but a club of readers and writers. How Habrahabr.
We already have something and it works: there is some kind of code. The server is able to poll the authors, and their applications can deliver new and / or modified articles, and users can also request new materials from the user and save traffic, since the server will send them only what they need. And we also have conditional editors, moderators and administrators who can fix anything in any article.
Now here is a case: the editor read the article, found a typo, corrected it and sent the change to the server. Approximately at the same time, the author added an update to the article, where he said that he updated the repository with code examples, thanked attentive readers for the comments and the indicated errors and also sent it to the server.
What happens if both of these events occur with a difference of seconds? Even if we know 100% which of the edits came later, and which was earlier (synchronized the clock with the server before sending, checked all conceivable and inconceivable problems), we will have either a typed article or an article with errors in the code.

Actually, this is a conflict. In this case - the conflict of versions of the article.
I do not know about you, but I do not like conflicts. And in real life I try to avoid them. However, if in life it is often possible to do this, then in IT it is necessary to face conflicts constantly. And conflicts are very, very bad. And we also have such a thing as distributed systems. This phrase has a lot of different interpretations, but in our case it all comes down to this: you have two or more computers connected by a network, and you try to make a data set look the same on all computers. And now the most delicious - any element of the network can refuse at any time. There are many failure scenarios and EVERYTHING is difficult. And even with the basic scenario, where there are two devices and one server, we already have a distributed system that needs to be made to work. And this will do. Let's start small, and a well-constructed solution can be scaled without any problems.
So, if for editing a document on one computer, as we have already found out, conflicts are very bad, then for distributed calculations conflicts are a natural state of affairs. This does not mean that we can ignore them or pretend that this is not happening, it means that we must accept conflicts and make them part of the mechanics.
We have already discussed how conflicts arise (and even created one in the example), let's see how to resolve them. For example, in our previous example, a typo was in the second paragraph, and the addition to the material was added at the end of the article:

If the article is stored as paragraphs, for example, then we could just update two edits in different paragraphs, treating these changes as two separate entities. For programmers, this is called merge (or merge, if in Russian). In all sorts of git type items, this is a popular and very convenient mechanism. In this case, the computer collects the final version of the article without conflict, independently.
Let's complicate the task. Suppose the author and the editor simultaneously noticed a typo and corrected it in different ways. The author decided to choose a synonym and replaced the word, and the editor only corrected one or two characters in the existing one. And both almost simultaneously sent the changes to the server. Now the computer can not determine which version is correct. What to do?
As you have already noticed, we are hitting one global task into smaller and smaller parts and continue to understand the problems of synchronization more and more. There was an article - now paragraphs. Paragraphs can be broken into lines. Lines - in words. Sooner or later we will reach a reasonable limit of division into entities, and still we will have conflicts. Moreover, we will have exactly those conflicts that the computer cannot solve on its own: the previous example is a clear confirmation of this.
We will simply have to connect a person to such problems: the AI has not yet been invented, so there is no other way at the moment. In the end, evolution did nothing but teach a person to survive and resolve conflicts, so I think now you will not be so much afraid of conflicts in a ... computer sense. Oh yes, it's time to go back to the timestamps and improve them.
As soon as you start looking for a solution for problems with timestamps, you will stumble upon the mention of vector clocks , for example, in the form of Lamport's timestamps . Applying the vector clock to the timestamps, we get what is called a logical clock . If we use not only timestamps, but also a logical clock with our objects, then we can definitely calculate which of the edits came earlier, and which of them later. Gorgeous! It remains to deal with something else.

Remember when we talked about the case of a simultaneous correction of a typo by the editor and the addition of material by the author? We have fixed this conflict with the system above: logical clocks + timestamps. But what if their edits relate to the same piece of text or, even more fun, the result of their edits is the same piece of text? No tricks will help here, the conflict will remain. That is, at first glance, there is no conflict, compare the results, throw out the extra ones and that's it, business. But what if you go further and not create conflicts instead of solving their consequences?
Now this problem looks somewhat contrived, but, hey ... This is an example so that later, when you really encounter such a problem, you will work not with a single synchronization server, but with a whole server cluster, but with thousands and thousands of clients, you had no problems with the creation of a working solution, nor with scaling it in the future.
Allow me to skip the tediousness and go to the point, otherwise our tutorial has already dragged on. In general, there is such a thing as Content Adressable Versions.
In order to resolve conflicts with the same edits, we will use this hack. We take the content of the edit / object, run through the hash function (via the same MD5 or SHA-1) and use the hash as the version. Since identical source data gives identical hashes, edits, the result of which is the same, do not create a conflict.
True, this does not solve the problem with the order of edits, but we will fix this now. To begin with, instead of rewriting the document with each update, we will keep an ordered list of versions along with the document. When we update part of a document, the Content Adressable Version is recorded along with edits to the top of the sheet. Now we know exactly when and what version of the edits arrived. In general, the piece is useful, but it is worth deciding in advance how many edits and variants of the document we will store or transfer to the server. You remember, for the sake of what it all started? To optimize the application, reduce the amount of traffic, memory, and so on. So in actual development, think about how many edits you need to “carry with you”: in general, the number from 10 to 1000 will do, and only personal experience and knowledge of the tasks, target audience and how your application is used will help you find the right parameter.
As a result, we spend a little more space on storing the history of edits, but we have a flexible system that avoids some conflicts.
It may seem to you that it is easier to use the same Vector Clock and resolve conflicts as they arrive, than to fence such a complex thing and waste space on storing “unnecessary” data, but believe me, everything will change as soon as you have a cluster instead of one server independent servers processing requests and the need to provide consistent data for all users.
Finally, we have to solve the last problem. When one user consistently made changes to the same material, the version history looks like this (for simplicity, we use simple numbers instead of hashes):
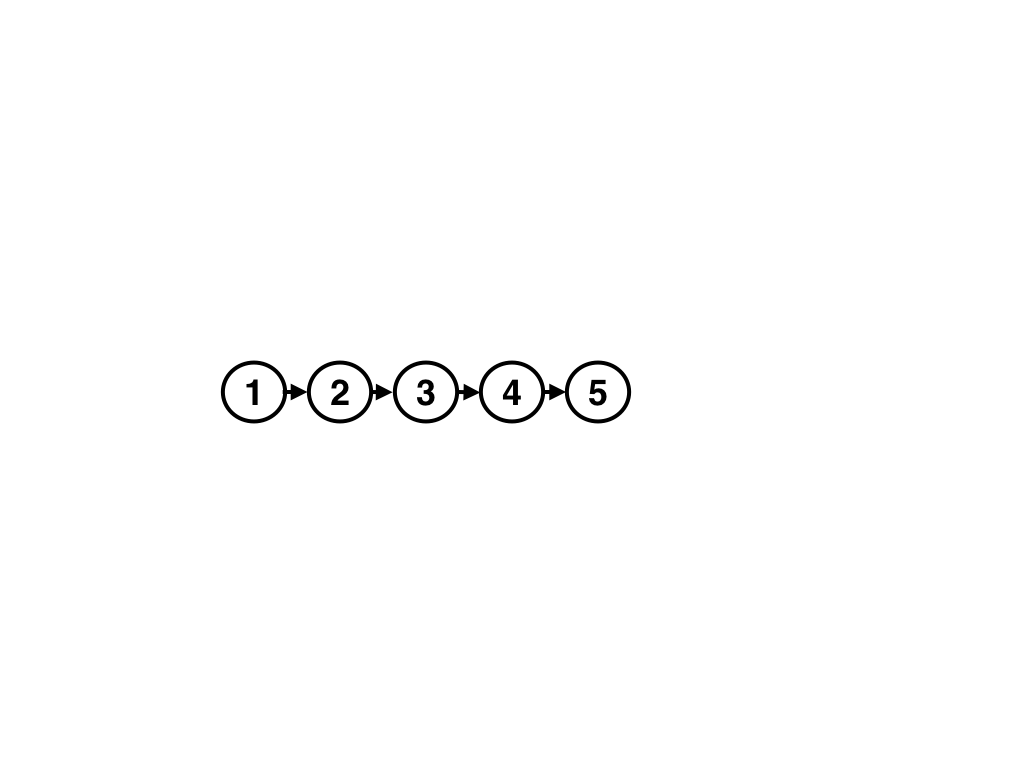
We have five versions. Now we will artificially create a conflict: in the list of versions after 4, we will have a conflict of the 5th and 6th versions:

We know that these versions are in conflict. And what if instead of solving this conflict, we created another? Just write a couple of values on the sheet above:
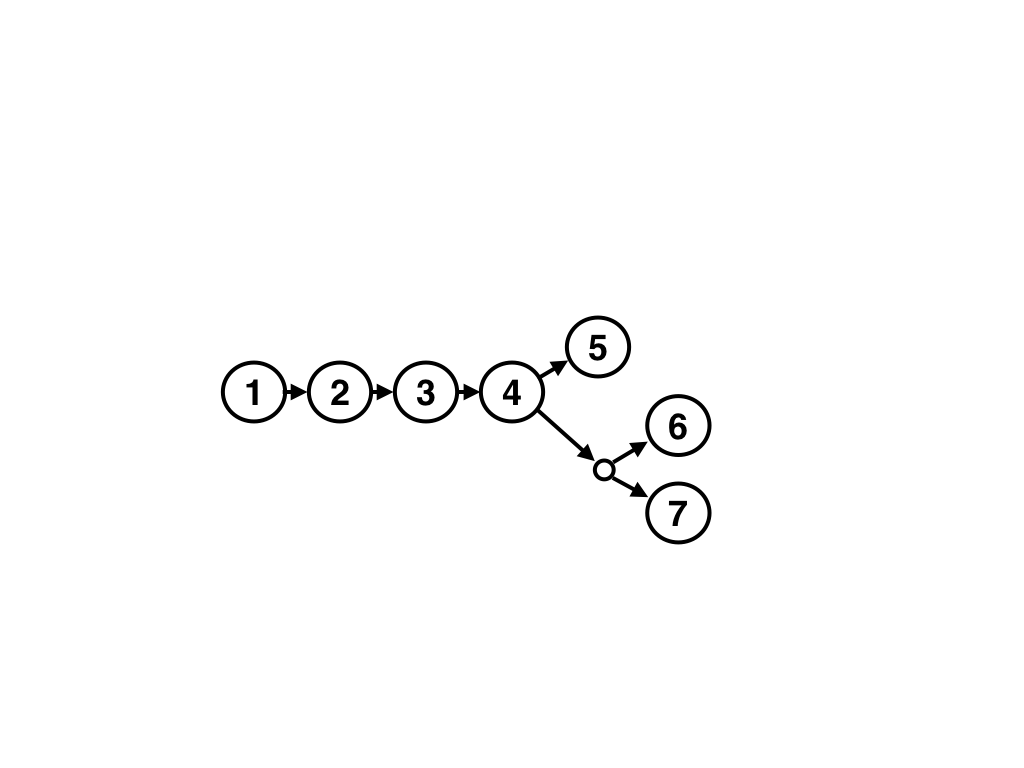
Now we have a conflict of versions "6" and "7", and this conflict itself conflicts with version 5. Someone uplls? Not. In fact, our revision history turns into a version tree. He has several advantages:
So let's summarize. Together we have analyzed and clarified many (sometimes seemingly obvious) aspects of synchronization. Now let's see what we did if we took all the developments and put them together. Below are the key points of the algorithm described above, with no explanation as to why this is all done, since we have already dealt with these questions:
1. There are two devices - A and B; it is necessary to synchronize information on them (from A to B).
2. Read synchronization checkpoint, if it exists.
3. We begin to read the update information from device A; read from the checkpoint, if it exists, or from the very beginning, if it did not exist.
4. Check in the list of versions whether the current version is a direct continuation of the latest version on B.
Thank you for reaching the end. I hope you understand how difficult it is to competently and from the first time develop a working and effective synchronization that will be reliable and will not turn into one big pain for you when scaling an application. Well, we discussed synchronization not for the sake of synchronization itself, but in the context of its use in PWA, so apply this knowledge in practice.
By the way, I didn’t initially tell you, but we “sorted out” at a visual level CouchDB Replication Protocol , in which all this is taken into account: it allows you to create transparent synchronization based on p2p with any number of users and takes into account all the scenarios described above. In turn, this protocol is part of the CouchDB database, so it works great with servers. In the browser and on local machines, you can use PouchDB: a similar product that implements the same protocol, but in JavaScript and node.js. This way you can use the CouchDB + PouchDB bundle and cover all the necessary user cases. Of course, on mobile phones, these technologies are also presented in the form of Couchbase Mobile and Cloudant Sync for iOS and Android, respectively. So, as I said at the very beginning of the first post:
Use the finished product. But do not forget to understand the technology thoroughly, sooner or later to create your own. That's all.
In this part we will study various specific schemes for the implementation of the theories described above, discuss their strengths and weaknesses. Well, before we start, let's describe the requirements for the desired algorithms.
We have two objects with the same ID, and we need to be able to distinguish between them: say which one is newer. That is, determine which of the objects is relevant. If we have not two, but three, five or ten - in essence, nothing changes, you just need to sort them according to their degree of relevance and be able to select the most recent, fresh, relevant of the objects. Actually, we need a version control system.
')
Increase the counter
The first and most obvious idea is to make a trivial integer counter. "Version 1", "Version 2", ... "Version 100500" - well, you understand.
The main advantage of this thing is that everything here is clear not only to a computer, but also to a person. That is, if you climb into the database with your hands, you will immediately understand which article is relevant and which is not. So what's the problem?
Imagine that we have an article can edit a few people. One is on the server side, the other is on the client side. The first edition of the article was published with the “Version 1” index. Next, the server creates an edited document with the “Version 2” index, and the client ... and the “Version 2” is also created on the client, because “1” is followed by “2”, and the client did not know what was on the server : let's say there was no available connection at the moment.
Now we have two documents with the “Version 2” index, but we don’t know if they are the same or not. And for the client (and for the server too) both versions seem legitimate - the version counter is the same, nothing needs to be synchronized. So our versions should be described in more detailed language?
Timestamps
To distinguish between versions of documents with the same ID, we can record not only the counter, but also the time in which the article was saved. Whether it is October 11, 2016, 12:30:57, or just 111016123057 - it is important for us that the number be unique and express the specific state of the article.
We will not go into the details of the CORRECT description of timestamps, some types are more convenient to process on a PC, some are more convenient for the user. If you want to do it your way - do it, we just recommend using the ISO 8601 standard .
What do we have in the end? We have the same article with different timestamps, it’s easy to see which version is newer. Since the clock goes forward only, each next version of the timestamp will be exactly larger than the previous one. Or not?
Before you continue reading the article, look at this wonderful collection of rakes that programmers are attacking when they think they know how time works. He also has a second part .
Banal example. You met a charming girl in a bar, write her number on the phone. You drank enough to mix up the two numbers in some places, and it’s good that you decided to double-check. You edit the number, save the correct version, say goodbye. Our contacts have timestamps, the synchronization with the cloud was successful, so even if you lose the phone on your way home, the phone number will remain. Or not?
If you have already opened the "rake" of the links above, you will understand how much everything could happen to your address book while maintaining the second number. Even such giants as Google, with almost infinite resources, sometimes ... face problems relating to time.
In the process of updating the notebook, anything can happen. You synchronized the first version with a typo, and then bam! - the phone was synchronized with the server and switched the clock a minute ago. Or you hit exactly at midnight, daylight saving time turned on. The iPhones still have problems with alarms set on January 1st. In general, we cannot trust simple timestamps as we would like to - in our case, you would lose the girl’s phone, because in the morning you would not remember what the typo was and where ... In general, we do not need. But the time can also be unsynchronized on the client and the server ...
Let us summarize our thoughts: whatever the specific scenario may be, the problem may arise in a small project and in a large system. You cannot trust simple timestamps and guarantee the sequence of revisions of two objects, even if both timestamps were generated on one device: this behavior can lead to data loss. And this means that we need to improve the timestamps. But before that we need to consider another source of problems: conflicts.
We destroy conflicts
To illustrate conflicts, we need to expand our example a little. Imagine that we have not just a club of interesting articles, but a club of readers and writers. How Habrahabr.
We already have something and it works: there is some kind of code. The server is able to poll the authors, and their applications can deliver new and / or modified articles, and users can also request new materials from the user and save traffic, since the server will send them only what they need. And we also have conditional editors, moderators and administrators who can fix anything in any article.
Now here is a case: the editor read the article, found a typo, corrected it and sent the change to the server. Approximately at the same time, the author added an update to the article, where he said that he updated the repository with code examples, thanked attentive readers for the comments and the indicated errors and also sent it to the server.
What happens if both of these events occur with a difference of seconds? Even if we know 100% which of the edits came later, and which was earlier (synchronized the clock with the server before sending, checked all conceivable and inconceivable problems), we will have either a typed article or an article with errors in the code.
Actually, this is a conflict. In this case - the conflict of versions of the article.
What to do?
I do not know about you, but I do not like conflicts. And in real life I try to avoid them. However, if in life it is often possible to do this, then in IT it is necessary to face conflicts constantly. And conflicts are very, very bad. And we also have such a thing as distributed systems. This phrase has a lot of different interpretations, but in our case it all comes down to this: you have two or more computers connected by a network, and you try to make a data set look the same on all computers. And now the most delicious - any element of the network can refuse at any time. There are many failure scenarios and EVERYTHING is difficult. And even with the basic scenario, where there are two devices and one server, we already have a distributed system that needs to be made to work. And this will do. Let's start small, and a well-constructed solution can be scaled without any problems.
So, if for editing a document on one computer, as we have already found out, conflicts are very bad, then for distributed calculations conflicts are a natural state of affairs. This does not mean that we can ignore them or pretend that this is not happening, it means that we must accept conflicts and make them part of the mechanics.
We have already discussed how conflicts arise (and even created one in the example), let's see how to resolve them. For example, in our previous example, a typo was in the second paragraph, and the addition to the material was added at the end of the article:
If the article is stored as paragraphs, for example, then we could just update two edits in different paragraphs, treating these changes as two separate entities. For programmers, this is called merge (or merge, if in Russian). In all sorts of git type items, this is a popular and very convenient mechanism. In this case, the computer collects the final version of the article without conflict, independently.
Let's complicate the task. Suppose the author and the editor simultaneously noticed a typo and corrected it in different ways. The author decided to choose a synonym and replaced the word, and the editor only corrected one or two characters in the existing one. And both almost simultaneously sent the changes to the server. Now the computer can not determine which version is correct. What to do?
As you have already noticed, we are hitting one global task into smaller and smaller parts and continue to understand the problems of synchronization more and more. There was an article - now paragraphs. Paragraphs can be broken into lines. Lines - in words. Sooner or later we will reach a reasonable limit of division into entities, and still we will have conflicts. Moreover, we will have exactly those conflicts that the computer cannot solve on its own: the previous example is a clear confirmation of this.
We will simply have to connect a person to such problems: the AI has not yet been invented, so there is no other way at the moment. In the end, evolution did nothing but teach a person to survive and resolve conflicts, so I think now you will not be so much afraid of conflicts in a ... computer sense. Oh yes, it's time to go back to the timestamps and improve them.
Vector clock
As soon as you start looking for a solution for problems with timestamps, you will stumble upon the mention of vector clocks , for example, in the form of Lamport's timestamps . Applying the vector clock to the timestamps, we get what is called a logical clock . If we use not only timestamps, but also a logical clock with our objects, then we can definitely calculate which of the edits came earlier, and which of them later. Gorgeous! It remains to deal with something else.
Remember when we talked about the case of a simultaneous correction of a typo by the editor and the addition of material by the author? We have fixed this conflict with the system above: logical clocks + timestamps. But what if their edits relate to the same piece of text or, even more fun, the result of their edits is the same piece of text? No tricks will help here, the conflict will remain. That is, at first glance, there is no conflict, compare the results, throw out the extra ones and that's it, business. But what if you go further and not create conflicts instead of solving their consequences?
Now this problem looks somewhat contrived, but, hey ... This is an example so that later, when you really encounter such a problem, you will work not with a single synchronization server, but with a whole server cluster, but with thousands and thousands of clients, you had no problems with the creation of a working solution, nor with scaling it in the future.
Allow me to skip the tediousness and go to the point, otherwise our tutorial has already dragged on. In general, there is such a thing as Content Adressable Versions.
Content Adressable Versions
In order to resolve conflicts with the same edits, we will use this hack. We take the content of the edit / object, run through the hash function (via the same MD5 or SHA-1) and use the hash as the version. Since identical source data gives identical hashes, edits, the result of which is the same, do not create a conflict.
True, this does not solve the problem with the order of edits, but we will fix this now. To begin with, instead of rewriting the document with each update, we will keep an ordered list of versions along with the document. When we update part of a document, the Content Adressable Version is recorded along with edits to the top of the sheet. Now we know exactly when and what version of the edits arrived. In general, the piece is useful, but it is worth deciding in advance how many edits and variants of the document we will store or transfer to the server. You remember, for the sake of what it all started? To optimize the application, reduce the amount of traffic, memory, and so on. So in actual development, think about how many edits you need to “carry with you”: in general, the number from 10 to 1000 will do, and only personal experience and knowledge of the tasks, target audience and how your application is used will help you find the right parameter.
As a result, we spend a little more space on storing the history of edits, but we have a flexible system that avoids some conflicts.
It may seem to you that it is easier to use the same Vector Clock and resolve conflicts as they arrive, than to fence such a complex thing and waste space on storing “unnecessary” data, but believe me, everything will change as soon as you have a cluster instead of one server independent servers processing requests and the need to provide consistent data for all users.
Store conflicts efficiently
Finally, we have to solve the last problem. When one user consistently made changes to the same material, the version history looks like this (for simplicity, we use simple numbers instead of hashes):
We have five versions. Now we will artificially create a conflict: in the list of versions after 4, we will have a conflict of the 5th and 6th versions:
We know that these versions are in conflict. And what if instead of solving this conflict, we created another? Just write a couple of values on the sheet above:
Now we have a conflict of versions "6" and "7", and this conflict itself conflicts with version 5. Someone uplls? Not. In fact, our revision history turns into a version tree. He has several advantages:
- It keeps conflicts efficiently;
- We can resolve conflicts recursively: no matter how many conflicting edits and branches we have, we can always return to a state in which there were no conflicts.
Putting it all together
So let's summarize. Together we have analyzed and clarified many (sometimes seemingly obvious) aspects of synchronization. Now let's see what we did if we took all the developments and put them together. Below are the key points of the algorithm described above, with no explanation as to why this is all done, since we have already dealt with these questions:
1. There are two devices - A and B; it is necessary to synchronize information on them (from A to B).
2. Read synchronization checkpoint, if it exists.
3. We begin to read the update information from device A; read from the checkpoint, if it exists, or from the very beginning, if it did not exist.
- We consider each pair of the form Id / version;
- If this deletion, we remember the deletion locally on device B;
- If such a pair was not on B, read it from A and memorize it locally on B;
- Save checkpoint updates on A and B.
4. Check in the list of versions whether the current version is a direct continuation of the latest version on B.
- If yes, save it on device B;
- If not, create a conflict.
That's all
Thank you for reaching the end. I hope you understand how difficult it is to competently and from the first time develop a working and effective synchronization that will be reliable and will not turn into one big pain for you when scaling an application. Well, we discussed synchronization not for the sake of synchronization itself, but in the context of its use in PWA, so apply this knowledge in practice.
By the way, I didn’t initially tell you, but we “sorted out” at a visual level CouchDB Replication Protocol , in which all this is taken into account: it allows you to create transparent synchronization based on p2p with any number of users and takes into account all the scenarios described above. In turn, this protocol is part of the CouchDB database, so it works great with servers. In the browser and on local machines, you can use PouchDB: a similar product that implements the same protocol, but in JavaScript and node.js. This way you can use the CouchDB + PouchDB bundle and cover all the necessary user cases. Of course, on mobile phones, these technologies are also presented in the form of Couchbase Mobile and Cloudant Sync for iOS and Android, respectively. So, as I said at the very beginning of the first post:
Use the finished product. But do not forget to understand the technology thoroughly, sooner or later to create your own. That's all.
Source: https://habr.com/ru/post/313674/
All Articles