Go for the record: Chromium fifth check
 It would seem that Chromium was considered by us repeatedly. The attentive reader will ask a logical question: “Why do we need another check? Wasn’t it enough? ” Undoubtedly, the Chromium code is distinguished by its purity, which we were convinced of every time we checked, but errors inevitably continue to be detected. Repeated checks well demonstrate that the more often static analysis is applied, the better. Well, if the project is checked every day. It is even better if the analyzer is used by programmers directly at work (automatic analysis of the modified code).
It would seem that Chromium was considered by us repeatedly. The attentive reader will ask a logical question: “Why do we need another check? Wasn’t it enough? ” Undoubtedly, the Chromium code is distinguished by its purity, which we were convinced of every time we checked, but errors inevitably continue to be detected. Repeated checks well demonstrate that the more often static analysis is applied, the better. Well, if the project is checked every day. It is even better if the analyzer is used by programmers directly at work (automatic analysis of the modified code).A bit of background
Chromium has already been tested with PVS-Studio four times:
- first check (05/23/2011)
- the second check (10/13/2011)
- the third check (08/12/2013)
- the fourth check (02.12.2013)
Previously, all checks were performed by the Windows version of the PVS-Studio analyzer. Recently, PVS-Studio works under Linux, so this version was used for analysis.
During this time, the project grew in size: in the third test, the number of projects reached 1169. At the time of writing, their number was 4420. The size of the source code grew noticeably to 370 MB (in 2013, the size was 260 MB).
')
For four checks, the highest quality code for such a large project was noted. Has the situation changed after two and a half years? Not. The quality is still on top. However, due to the large amount of code and its continuous development, we again find many errors.
How to check?
Let us dwell on how to make a test Chromium. This time we will do it in Linux. After downloading the sources using depot_tools and preparing (more details here , before the Building section) we build the project:
pvs-studio-analyzer trace -- ninja -C out/Default chrome Next, execute the command (this is one line):
pvs-studio-analyzer analyze -l /path/to/PVS-Studio.lic -o /path/to/save/chromium.log -j<N> where the "-j" flag starts the analysis in multi-threaded mode. The recommended number of threads is the number of physical CPU cores plus one (for example, on a quad-core processor, the flag will look like "-j5").
As a result, a report of the PVS-Studio analyzer will be received. Using the PlogConverter utility, which comes as part of the PVS-Studio distribution, it can be converted to one of three readable formats: xml, errorfile, tasklist. We will use tasklist for viewing messages. In the current check, only general purpose warnings (General Analysis) of all levels (High, Medium, Low) will be viewed. The conversion command will look like this (in one line):
plog-converter -t tasklist -o /path/to/save/chromium.tasks -a GA:1,2,3 /path/to/saved/chromium.log More information about all the parameters of PlogConverter can be found here . The tasklist load “chromium.tasks” in QtCreator (must be pre-installed) is performed using the command:
qtcreator path/to/saved/chromium.tasks It is highly recommended to start viewing the report with High and Medium level alerts - the probability that there will be erroneous instructions in the code will be very high. Low level warnings can also indicate potential errors, but they have a higher probability of false positives, so they are usually not studied when writing articles.
The report view in QtCreator itself will look like this:
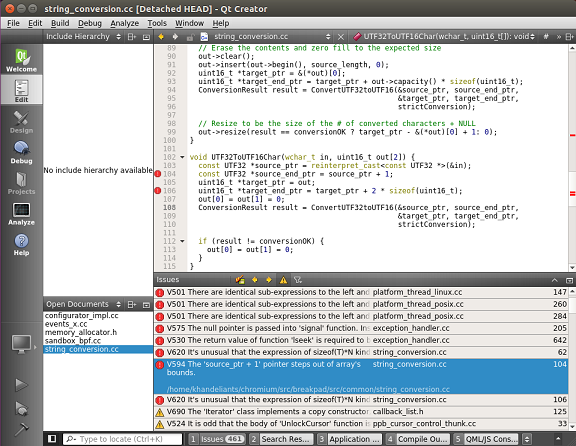
Figure 1 - Working with the results of the analyzer from under QtCreator (click on image to enlarge)
What did the analyzer tell?
After checking the Chromium project, 2312 warnings were received. The following diagram shows the distribution of warnings by severity level:
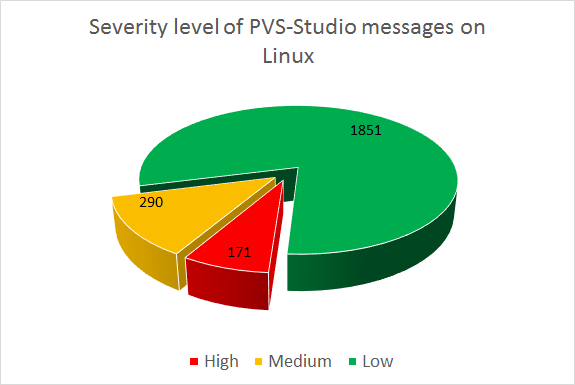
Figure 2 - Distribution of alerts by severity level
We briefly comment on the diagram: 171 warnings of the High level were received, 290 warnings of the Medium level, 1851 warnings of the Low level.
Despite the rather large number of warnings, for such a giant project it is not much. The total number of lines of the source code (SLOC) without libraries is 6468751. If we take into account only the warnings of the High and Medium levels, then among them I can probably point out 220 true errors. Figures are numbers, but in fact we get an error density of 0.034 errors per 1000 lines of code. This, of course, is not the density of all errors, but only those that PVS-Studio finds. Or rather, the mistakes that I noticed while viewing the report.
As a rule, on other projects we get the greater density of errors found. The developers of Chromium are great! However, you should not relax: there are mistakes, and they are far from harmless.
Let us consider in more detail the most interesting errors.
New bugs found
Copy paste

Analyzer Warning : V501 There are identical sub-expressions 'request_body_send_buf_ == nullptr' the operator. http_stream_parser.cc 1222
bool HttpStreamParser::SendRequestBuffersEmpty() { return request_headers_ == nullptr && request_body_send_buf_ == nullptr && request_body_send_buf_ == nullptr; // <= } Classics of the genre. The programmer compared the request_body_send_buf_ pointer to nullptr twice . This is probably a typo, and some member of the class should have been compared with nullptr .
Analyzer Warning : V766 An item with the same key '"colorSectionBorder"' has already been added. ntp_resource_cache.cc 581
void NTPResourceCache::CreateNewTabCSS() { .... substitutions["colorSectionBorder"] = // <= SkColorToRGBAString(color_section_border); .... substitutions["colorSectionBorder"] = // <= SkColorToRGBComponents(color_section_border); .... } The analyzer reports a suspicious double initialization of the object using the “colorSectionBorder” key. The variable substitutions in this context is an associative array. In the first initialization, the color_section_border variable of the SkColor type (defined as uint32_t ) is translated into the string representation of RGBA (judging from the name of the SkColorToRGBAString method) and stored by the “colorSectionBorder” key. When reassigning, color_section_border is converted to another string format ( SkColorToRGBComponents method) and is written using the same key. This means that the previous value for the key "colorSectionBorder" will be destroyed. Perhaps it was conceived, but then one of the initializations should be removed. Otherwise, you should save the color components by a different key.
Note. By the way, this is the first error found using the V766 diagnostics in a real project. The type of error is quite specific, but the Chromium project is so large that you can meet exotic defects in it.
Incorrect work with pointers

I suggest that readers warm up a little and try to find a mistake on their own.
// Returns the item associated with the component |id| or nullptr // in case of errors. CrxUpdateItem* FindUpdateItemById(const std::string& id) const; void ActionWait::Run(UpdateContext* update_context, Callback callback) { .... while (!update_context->queue.empty()) { auto* item = FindUpdateItemById(update_context->queue.front()); if (!item) { item->error_category = static_cast<int>(ErrorCategory::kServiceError); item->error_code = static_cast<int>(ServiceError::ERROR_WAIT); ChangeItemState(item, CrxUpdateItem::State::kNoUpdate); } else { NOTREACHED(); } update_context->queue.pop(); } .... } Analyzer Warning : V522 Dereferencing of the null pointer 'item' might take place. action_wait.cc 41
Here the programmer decided to shoot his leg in an obvious way. In the code, the queue is sequentially bypassed, which contains identifiers in string representations. The identifier is retrieved from the queue, then the FindUpdateItemById method must return a pointer to an object of type CrxUpdateItem by identifier. If an error occurs in the FindUpdateItemById method, a nullptr will be returned, which will then be de-signed in the then branch of the if statement .
The correct code might look like this:
.... while (!update_context->queue.empty()) { auto* item = FindUpdateItemById(update_context->queue.front()); if (item != nullptr) { .... } .... } .... Analyzer Warning : V620 string_conversion.cc 62
int UTF8ToUTF16Char(const char *in, int in_length, uint16_t out[2]) { const UTF8 *source_ptr = reinterpret_cast<const UTF8 *>(in); const UTF8 *source_end_ptr = source_ptr + sizeof(char); uint16_t *target_ptr = out; uint16_t *target_end_ptr = target_ptr + 2 * sizeof(uint16_t); // <= out[0] = out[1] = 0; .... } The analyzer detected a code with a suspicious address arithmetic. As the name implies, the function converts a character from UTF-8 to UTF-16. The current Unicode 6.x standard implies a UTF-8 character extension to four bytes. In this regard, a UTF-8 character is decoded as 2 UTF-16 characters (a UTF-16 character is hard-coded by two bytes). For decoding, 4 pointers are used - pointers to the beginning and end of the arrays in and out . Pointers to the end of arrays in the code act like STL iterators: they refer to the memory area behind the last element in the array. If in the case of source_end_ptr the pointer was received correctly, then with target_end_ptr everything is not so rosy. The implication was that he had to refer to the memory area behind the second element of the out array (that is, move relative to the out pointer by 4 bytes), but instead the pointer would refer to the memory area behind the fourth element (8 out byte).
We illustrate the words spoken, as it should have been:
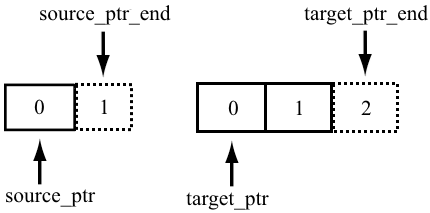
How did it actually happen:

The correct code should look like this:
int UTF8ToUTF16Char(const char *in, int in_length, uint16_t out[2]) { const UTF8 *source_ptr = reinterpret_cast<const UTF8 *>(in); const UTF8 *source_end_ptr = source_ptr + 1; uint16_t *target_ptr = out; uint16_t *target_end_ptr = target_ptr + 2; out[0] = out[1] = 0; .... } The analyzer also found another suspicious location:
- V620 It is unusual that it can be summed with the pointer to the T type. string_conversion.cc 106
Various errors

I propose to warm up again and try to find an error in the code yourself.
CheckReturnValue& operator=(const CheckReturnValue& other) { if (this != &other) { DCHECK(checked_); value_ = other.value_; checked_ = other.checked_; other.checked_ = true; } } Analyzer warning : V591 Non-void function should return a value. memory_allocator.h 39
Undefined behavior occurs in the code above: the C ++ standard says that any non-void method should return a value. What is the code above? The assignment operator checks for assignment to itself (comparison of objects by their pointers) and copying fields (if the pointers are different). However, the method did not return a reference to itself ( return * this ).
There are a couple more places in the project where the non-void method does not return values:
- V591 Non-void function should return a value. sandbox_bpf.cc 115
- V591 Non-void function should return a value. events_x.cc 73
Analyzer warning : V583 The '?:' Operator, regardless of its conditional expression, always returns one and the same value: 1. configurator_impl.cc 133
int ConfiguratorImpl::StepDelay() const { return fast_update_ ? 1 : 1; } The code always returns a delay equal to one. Perhaps this is a reserve for the future, but so far there is no use for such a ternary operator.
Analyzer Warning : Consider Inspecting the 'rv == OK || rv! = ERR_ADDRESS_IN_USE 'expression. The expression is misprint. udp_socket_posix.cc 735
int UDPSocketPosix::RandomBind(const IPAddress& address) { DCHECK(bind_type_ == DatagramSocket::RANDOM_BIND && !rand_int_cb_.is_null()); for (int i = 0; i < kBindRetries; ++i) { int rv = DoBind(IPEndPoint(address, rand_int_cb_ .Run(kPortStart, kPortEnd))); if (rv == OK || rv != ERR_ADDRESS_IN_USE) // <= return rv; } return DoBind(IPEndPoint(address, 0)); } The analyzer warns of possible excessive comparison. In the code, a random port is bound to an IP address. If the binding is successful, the loop stops (which means the number of attempts to bind the port to the address). Based on the logic, you can leave one of the comparisons (now the cycle stops, if the binding is successful, or if the port is not returned using a different address).
Analyzer Warning : V523 The 'then' statement is equivalent to the 'else' statement.
bool ResourcePrefetcher::ShouldContinueReadingRequest( net::URLRequest* request, int bytes_read ) { if (bytes_read == 0) { // When bytes_read == 0, no more data. if (request->was_cached()) FinishRequest(request); // <= else FinishRequest(request); // <= return false; } return true; } The analyzer reported similar statements in the then and else branches of an if statement . What can this lead to? Based on the code, the non-cached URL request ( net :: URLRequest * request ) will be completed in the same way as the cached one. If it should be like this, then you can remove the branch statement:
.... if (bytes_read == 0) { // When bytes_read == 0, no more data. FinishRequest(request); // <= return false; } .... If another logic was implied, then the wrong method would be called that could lead to "sleepless nights" and "coffee sea".
Analyzer Warning : V609 Divide by zero. Denominator range [0..4096]. addr.h 159
static int BlockSizeForFileType(FileType file_type) { switch (file_type) { .... default: return 0; // <= } } static int RequiredBlocks(int size, FileType file_type) { int block_size = BlockSizeForFileType(file_type); return (size + block_size - 1) / block_size; // <= } What do we see here? This code can lead to a subtle error: the RequiredBlocks method is divided by the value of the block_size variable (calculated using the BlockSizeForFileType method). In the BlockSizeForFileType method, the transferred value of the FileType enumeration in the switch operator returns some value, however, the default value of 0 was also provided. Suppose that the FileType enumeration decided to expand and added a new value but did not add a new case branch in the switch operator . This will lead to undefined behavior: according to the C ++ standard, division by zero does not cause a program exception. Instead, a hardware exception will be triggered, which is not caught by the standard try / catch block (signal handlers are used instead, you can read more here and here ).
Analyzer warning : V519 The '* list' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 136, 138. util.cc 138
bool GetListName(ListType list_id, std::string* list) { switch (list_id) { .... case IPBLACKLIST: *list = kIPBlacklist; break; case UNWANTEDURL: *list = kUnwantedUrlList; break; case MODULEWHITELIST: *list = kModuleWhitelist; // <= case RESOURCEBLACKLIST: *list = kResourceBlacklist; break; default: return false; } .... } A typical mistake when writing a switch- operator. It is expected that if the list_id variable takes the value MODULEWHITELIST from the ListType enumeration, the string at the list pointer is initialized with the value of kModuleWhitelist and the switch- operator is interrupted. However, due to the missing break statement, the transition to the next RESOURCEBLACKLIST branch will occur, and the string kResourceBlacklist will actually be saved in * list .
findings
Chromium remains a tough nut to crack. Still, the PVS-Studio analyzer may again and again find errors in it. When using static analysis methods, errors can be found at the stage of writing code, before the testing stage.
What tools can I use for static code analysis? In fact, a lot of tools . I naturally suggest trying PVS-Studio: the product is very conveniently integrated into the Visual Studio environment, or perhaps it can be used with any build system. And more recently, the version for Linux has become available. More information about the Windows and Linux versions can be found here and here .

If you want to share this article with an English-speaking audience, then please use the link to the translation: Phillip Khandeliants. Heading for a Record: Chromium, the 5th Check .
Read the article and have a question?
Often our articles are asked the same questions. We collected answers to them here: Answers to questions from readers of articles about PVS-Studio, version 2015 . Please review the list.
Source: https://habr.com/ru/post/313670/
All Articles