Familiarity with the Ceph repository in pictures
Cloud file storage continues to gain popularity, and their demands continue to grow. Modern systems are no longer able to fully meet all these requirements without a significant expenditure of resources to support and scale these systems. By system, I mean a cluster with some level of data access. Reliability of storage and high availability is important for the user, so that files can always be easily and quickly received, and the risk of data loss tends to zero. In turn, for suppliers and administrators of such storage, simplicity of support, scalability and low cost of hardware and software components are important.
Ceph is an open source software-defined distributed file system, devoid of bottlenecks and single points of failure, which is a cluster of nodes that perform various functions, provides storage and replication of data, as well as load distribution, which guarantees high availability and reliability. The system is free, although developers can provide paid support. No special equipment is required.
')
When any disk, node or group of nodes fails, Ceph will not only ensure data integrity, but will also restore lost copies on other nodes until the failed nodes or disks are replaced with working ones. At the same time, a rebuild occurs without a second downtime and is transparent to customers.
Since the system is software defined and works on top of standard file systems and network layers, you can take a bunch of different servers, stuff them with different disks of different sizes, connect all this happiness with some kind of network (better fast) and raise the cluster. You can plug into these servers on the second network card, and connect them with a second network to speed up the inter-server data exchange. And experiments with settings and schemes can be easily carried out even in a virtual environment. My experience of experiments shows that the longest in this process is the installation of the OS. If we have three servers with disks and a configured network, it will take 5-10 minutes to raise a working cluster with default settings (if everything is done correctly).
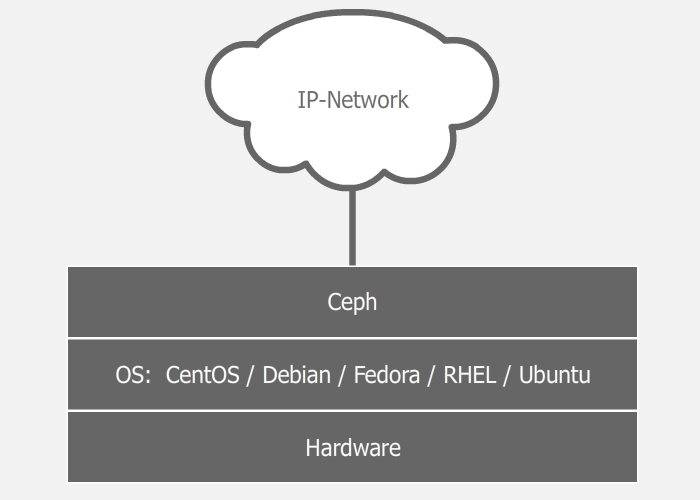
On top of the operating system, there are Ceph daemons that perform various cluster roles. Thus, a single server can act, for example, both as a monitor (MON), and as a data warehouse (OSD). In the meantime, another server can act as a data warehouse and as a metadata server (MDS). In large clusters, daemons run on separate machines, but in small clusters, where the number of servers is very limited, some servers can perform two or three roles at once. Depends on server power and the roles themselves. Of course, everything will work faster on separate servers, but it is not always possible to implement it. A cluster can even be assembled from one machine and just one disk, and it will work. Another conversation that it would not make sense. It should be noted that due to software determinability, the storage can be raised even on top of a RAID or iSCSI device, but in most cases this will also not make sense.
The documentation lists 3 types of daemons:
The initial cluster can be created from several machines, combining cluster roles on them. Then, with the growth of the cluster and the addition of new servers, some roles can be duplicated on other machines or completely transferred to separate servers.
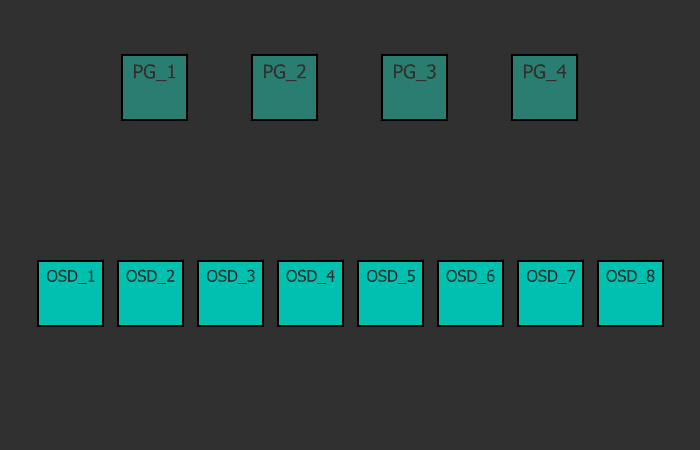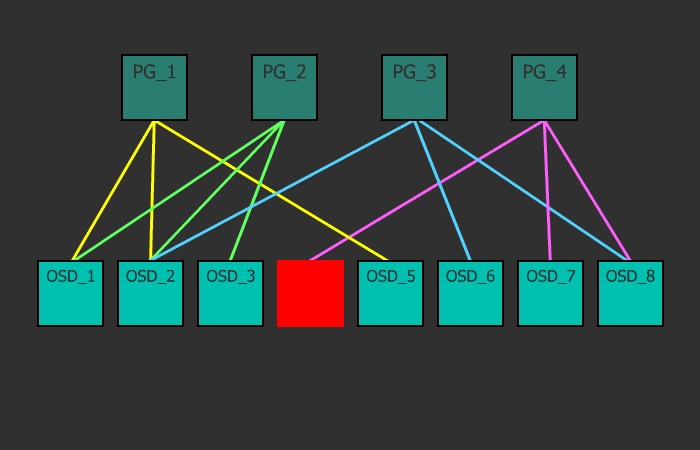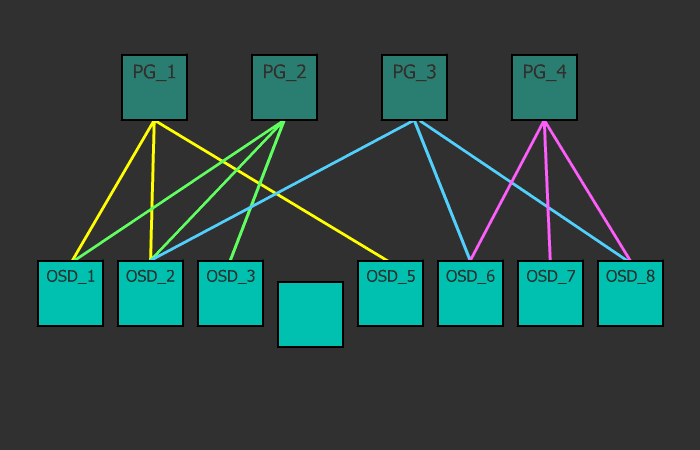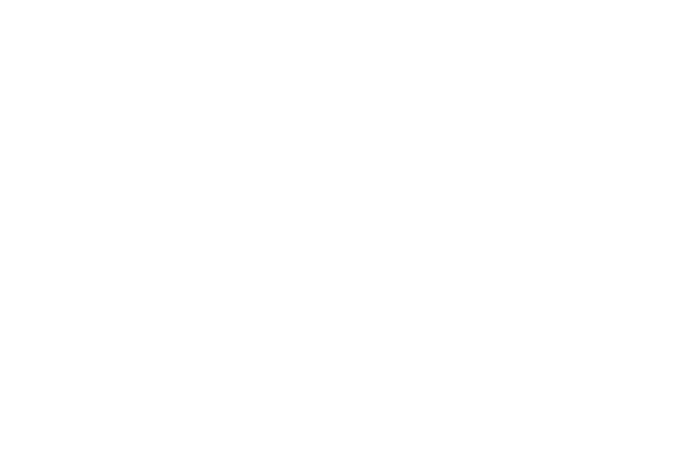
For a start, short and incomprehensible. A cluster can have one or many data pools of different purposes and with different settings. Pools are divided into placement groups. In the placement groups are stored objects that are accessed by customers. At this the logical level ends and the physical begins, because each placement group has one main disk and several replica disks (how much depends on the pool replication factor). In other words, at the logical level, an object is stored in a particular placement group, and at the physical level - on disks that are assigned to it. In this case, the disks can physically be located on different nodes or even in different data centers.

Further detail & understandable.
Replication factor is the level of data redundancy. The number of copies of data that will be stored on different disks. The variable size is responsible for this parameter. The replication factor can be different for each pool, and can be changed on the fly. In general, in Ceph almost all parameters can be changed on the fly, instantly receiving a cluster response. At first, we can have size = 2, and in this case, the pool will store two copies of one piece of data on different disks. This parameter of the pool can be changed to size = 3, and at the same time the cluster will begin to redistribute the data, decomposing another copy of the existing data on the disks, without stopping the work of clients.
A pool is a logical abstract container for storing user data. Any data is stored in the pool as objects. Multiple pools can be spread on the same disks (and maybe in different ways how to configure) using different sets of placement groups. Each pool has a number of customizable parameters: replication factor, number of placement groups, the minimum number of live replicas of the object required for operation, etc. Each pool can have its own replication policy (by city, data center, rack or even disk). For example, a pool for hosting may have a replication factor of size = 3, and a failure zone will be data centers. And then Ceph will ensure that each piece of data has one copy in three data centers. In the meantime, the pool for virtual machines may have a replication factor of size = 2, and the level of failure will already be the server rack. And in this case, the cluster will store only two copies. At the same time, if we have two racks with a storage of virtual images in one data center, and two racks in another, the system will not pay attention to data centers, and both copies of data can fly into one data center, but guaranteed to be in different racks, as we wanted .
Placement groups are such a link between the physical storage layer (disks) and the logical organization of data (pools).
Each object at the logical level is stored in a specific place-group. At the physical level, it lies in the right number of copies on different physical disks, which are included in this placement group (in fact, not disks, but OSD, but usually one OSD is one disk, and for simplicity I will call it drive, although I remind you, it may be a RAID array or an iSCSI device). With the replication factor size = 3, each placement group includes three disks. But at the same time, each disc is in a multitude of placement groups, and for some groups it will be primary, for others - a replica. If OSD is included, for example, into three placement groups, then when such an OSD falls, placement groups will exclude it from work, and in its place each placement group will select a working OSD and spread the data on it. Using this mechanism, a fairly uniform distribution of data and load is achieved. This is a very simple and at the same time flexible solution.
A monitor is a daemon that acts as a coordinator from which the cluster begins. As soon as we have at least one working monitor, we have a Ceph cluster. The monitor stores information about the health and condition of the cluster, exchanging various maps with other monitors. Clients access monitors to find out which OSDs to write / read data on. When a new storage is deployed, the monitor (or several) is created first. A cluster can live on one monitor, but it is recommended to make 3 or 5 monitors, in order to avoid the fall of the entire system due to the fall of a single monitor. The main thing is that the number of these should be odd in order to avoid situations of a split consciousness (split-brain). Monitors operate in a quorum, so if more than half of the monitors fall, the cluster will be locked to prevent data mismatch.
OSD is a storage unit that stores the data itself and processes customer requests, exchanging data with other OSDs. This is usually a disk. And usually a separate OSD daemon is responsible for each OSD, which can be run on any machine on which this disk is installed. This is the second thing that needs to be added to the cluster, when deployed. One monitor and one OSD - the minimum set in order to raise the cluster and start using it. If there are 12 disks spinning on the server for storage, then the same OSD daemons will be launched on it. Clients work directly with the OSD themselves, bypassing the bottlenecks, and thus achieving load distribution. The client always writes the object to the primary OSD for some group placement, and further on this OSD synchronizes data with the other (secondary) OSD from the same placement group. Confirmation of a successful record can be sent to the client immediately after writing to the primary OSD, or maybe after reaching the minimum number of records (pool parameter min_size). For example, if the replication factor size = 3, and min_size = 2, then confirmation of successful recording will be sent to the client when the object is written to at least two of the three OSDs (including the primary one).
With different options for setting these parameters, we will observe different behavior.
If size = 3 and min_size = 2: everything will be fine as long as 2 out of 3 OSD placement groups are alive. When only 1 live OSD remains, the cluster will freeze the operations of this placement group until at least one more OSD comes to life.
If size = min_size, then the placement group will be blocked when any OSD that is part of it is dropped. And due to the high level of data blurring, the majority of crashes of at least one OSD will result in freezing of the entire or almost the entire cluster. Therefore, the size parameter should always be at least one item larger than the min_size parameter.
If size = 1, the cluster will work, but the death of any OSD will mean irretrievable data loss. Ceph allows you to set this parameter to one, but even if the administrator does this for a specific purpose for a short time, he takes the risk.
An OSD disk consists of two parts: the log and the data itself. Accordingly, the data is first written to the log, then to the data section. On the one hand, this provides additional reliability and some optimization, and on the other hand, an additional operation that affects performance. The issue of log performance will be discussed below.
The mechanism of decentralization and distribution is based on the so-called CRUSH algorithm (Controlled Replicated Under Scalable Hashing), which plays an important role in the system architecture. This algorithm allows you to uniquely determine the location of an object based on the object name hash and a specific map, which is formed based on the physical and logical structures of the cluster (data centers, halls, rows, racks, nodes, disks). The map does not include location information. Each client determines the path to the data himself, using the CRUSH algorithm and the current map, which he first asks for the monitor. When you add a disk or server crashes, the map is updated.
Thanks to determinism, two different clients will find the same unique path to one object on their own, eliminating the need to keep all these paths on some servers, synchronizing them with each other, giving a huge overload to the storage as a whole.
Example:

A client wants to write some object1 to pool1. To do this, he looks at the card of placement groups, which the monitor has kindly provided him before, and sees that Pool1 is divided into 10 placement groups. Then, using the CRUSH algorithm, which accepts the object name and the total number of placement groups in Pool1 as input, the placement group ID is calculated. Following the map, the client understands that this OS placement group has three OSDs (say, their numbers: 17, 9, and 22), the first of which is primary, which means the client will write to him. By the way, there are three of them, because replication factor size = 3 is set in this pool. After the object is successfully written to OSD_17, the client’s work is finished (this is if the pool parameter is min_size = 1), and OSD_17 replicates this object to OSD_9 and OSD_22 assigned to this placement group. It is important to understand that this is a simplified explanation of the operation of the algorithm.
By default, our CRUSH card is flat, all nodes are in the same space. However, you can easily turn this plane into a tree by distributing servers in racks, racks in rows, rows in halls, halls in data centers, and data centers in different cities and planets, indicating what level to consider the zone of failure. Using this new map, Ceph will more intelligently distribute data, taking into account the individual characteristics of the organization, preventing the sad consequences of a fire in a data center or a meteorite falling on a whole city. Moreover, thanks to this flexible mechanism, it is possible to create additional layers, both at the upper levels (data centers and cities), and at the lower levels (for example, additional division into groups of disks within one server).
Ceph provides several ways to increase cluster performance with cache methods.
Primary-affinity
Each OSD has several weights, and one of them is responsible for which OSD in the placement group will be primary. And, as we found out earlier, the client writes the data on the primary OSD. So, you can add to the cluster a pack of SSD drives, making them always primary, reducing the weight of primary-affinity HDD drives to zero. And then the recording will always be carried out first on a fast disk, and then slowly replicate to slow ones. This method is the wrong, but the easiest to implement. The main disadvantage is that one copy of the data will always be on the SSD and it will take a lot of such disks to fully cover the replication. Although someone used this method in practice, I rather mentioned it in order to tell about the possibility of controlling the priority of a recording.
Removal of journals on SSD
In general, the lion's share of performance depends on the OSD logs. When writing, the daemon first writes the data to the log, and then to the storage itself. This is always true, except when using BTRFS as a file system on OSD, which can do this in parallel thanks to the copy-on-write technique, but I still do not understand how ready it is for industrial use. Each OSD has its own log, and by default it is on the same disk as the data itself. However, logs from four or five drives can be brought to one SSD, not bad speeding up write operations. The method is not very flexible and convenient, but quite simple. The disadvantage of the method is that during the departure of the SSD with the magazine, we will lose several OSDs at once, which is not very pleasant and introduces additional difficulties into all further support, which scales with the growth of the cluster.
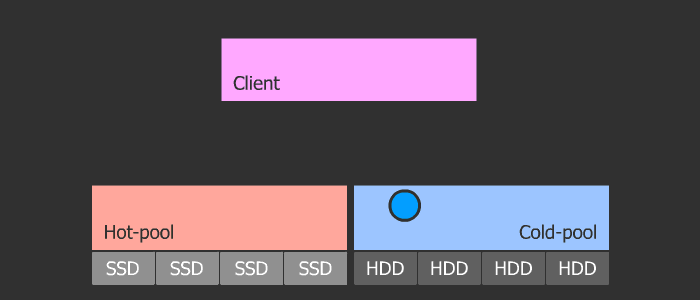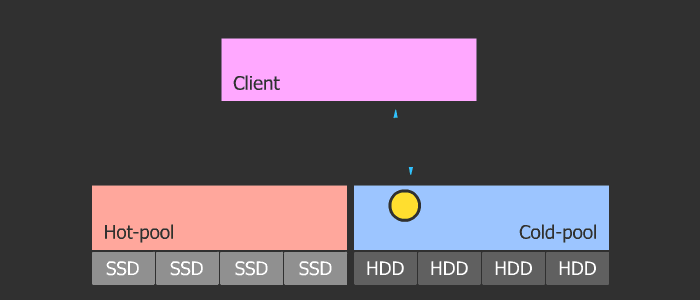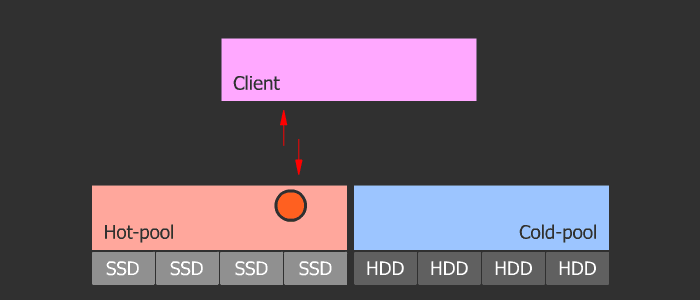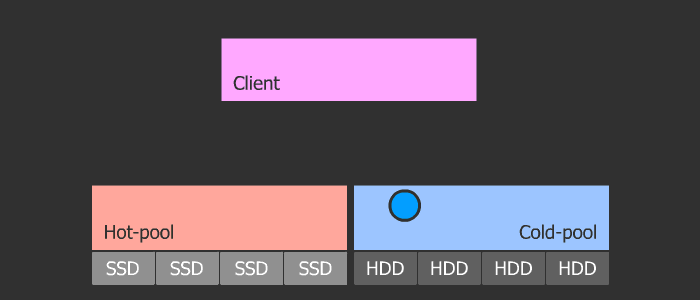
Cash Tiring
The orthodoxy of this method is in its flexibility and scalability. The scheme is such that we have a pool with cold data and a pool with hot data. With frequent access to the object, it heats up and enters the hot pool, which consists of fast SSDs. Then, if the object cools, it falls into a cold pool with slow HDDs. This scheme allows you to easily change the SSD in the hot pool, which in turn can be of any size, because the parameters of heating and cooling are regulated.
Ceph provides the client with various options for accessing data: a block device, a file system, or object storage.

Block Device (RBD, Rados Block Device)
Ceph allows you to create a block RBD device in the data pool, and later mount it on operating systems that support it (at the time of writing, there were only various linux distributions, however FreeBSD and VMWare are also working in this direction). If the client does not support RBD (for example, Windows), then an intermediate iSCSI-target with RBD support (for example, tgt-rbd) can be used. In addition, such a block device supports snapshots.
CephFS file system
A client can mount a CephFS file system if it has linux with kernel version 2.6.34 or newer. If the kernel version is older, then you can mount it through FUSE (Filesystem in User Space). In order for clients to connect Ceph as a file system, you need to raise at least one metadata server (MDS) in a cluster
Object Gateway
Using the RGW Gateway (RADOS Gateway), customers can be given the opportunity to use storage through a RESTful Amazon S3 or OpenStack Swift compatible API.
Other...
All these data access levels operate on top of the RADOS level. The list can be supplemented by developing your data access layer using the librados API (through which the access layers listed above work). At the moment there are C, Python, Ruby, Java and PHP bindings
RADOS (Reliable Autonomic Distributed Object Store), in a nutshell, this is a layer of interaction between customers and the cluster.
Wikipedia says that Ceph itself is written in C ++ and Python, and Canonical, CERN, Cisco, Fujitsu, Intel, Red Hat, SanDisk, and SUSE take part in the development.
Why did I write all this and draw pictures? Then that despite all these advantages, Ceph is either not very popular, or people eat it secretly, judging by the amount of information about it on the Internet.
The fact that Ceph is flexible, simple and convenient, we found out. The cluster can be raised on any hardware in a normal network, spending a minimum of time and effort, while Ceph will take care of data integrity by taking the necessary measures in case of iron failures. The fact that Ceph is flexible, simple and scalable converges many points of view. However, reviews of performance are very diverse. Maybe someone did not cope with the logs, someone summed up the network and delays in I / O operations. That is, making the cluster work is easy, but making it work quickly is perhaps more difficult. Therefore, I appeal to IT professionals who have experience using Ceph in production. Share in comments about your negative impressions.
Links
Meet Ceph
Ceph is an open source software-defined distributed file system, devoid of bottlenecks and single points of failure, which is a cluster of nodes that perform various functions, provides storage and replication of data, as well as load distribution, which guarantees high availability and reliability. The system is free, although developers can provide paid support. No special equipment is required.
')
When any disk, node or group of nodes fails, Ceph will not only ensure data integrity, but will also restore lost copies on other nodes until the failed nodes or disks are replaced with working ones. At the same time, a rebuild occurs without a second downtime and is transparent to customers.
Node roles and demons
Since the system is software defined and works on top of standard file systems and network layers, you can take a bunch of different servers, stuff them with different disks of different sizes, connect all this happiness with some kind of network (better fast) and raise the cluster. You can plug into these servers on the second network card, and connect them with a second network to speed up the inter-server data exchange. And experiments with settings and schemes can be easily carried out even in a virtual environment. My experience of experiments shows that the longest in this process is the installation of the OS. If we have three servers with disks and a configured network, it will take 5-10 minutes to raise a working cluster with default settings (if everything is done correctly).
On top of the operating system, there are Ceph daemons that perform various cluster roles. Thus, a single server can act, for example, both as a monitor (MON), and as a data warehouse (OSD). In the meantime, another server can act as a data warehouse and as a metadata server (MDS). In large clusters, daemons run on separate machines, but in small clusters, where the number of servers is very limited, some servers can perform two or three roles at once. Depends on server power and the roles themselves. Of course, everything will work faster on separate servers, but it is not always possible to implement it. A cluster can even be assembled from one machine and just one disk, and it will work. Another conversation that it would not make sense. It should be noted that due to software determinability, the storage can be raised even on top of a RAID or iSCSI device, but in most cases this will also not make sense.
The documentation lists 3 types of daemons:
- Mon - monitor daemon
- OSD - storage daemon
- MDS - Metadata Server (required only when using CephFS)
The initial cluster can be created from several machines, combining cluster roles on them. Then, with the growth of the cluster and the addition of new servers, some roles can be duplicated on other machines or completely transferred to separate servers.
Storage structure
For a start, short and incomprehensible. A cluster can have one or many data pools of different purposes and with different settings. Pools are divided into placement groups. In the placement groups are stored objects that are accessed by customers. At this the logical level ends and the physical begins, because each placement group has one main disk and several replica disks (how much depends on the pool replication factor). In other words, at the logical level, an object is stored in a particular placement group, and at the physical level - on disks that are assigned to it. In this case, the disks can physically be located on different nodes or even in different data centers.
Further detail & understandable.
Replication factor (RF)
Replication factor is the level of data redundancy. The number of copies of data that will be stored on different disks. The variable size is responsible for this parameter. The replication factor can be different for each pool, and can be changed on the fly. In general, in Ceph almost all parameters can be changed on the fly, instantly receiving a cluster response. At first, we can have size = 2, and in this case, the pool will store two copies of one piece of data on different disks. This parameter of the pool can be changed to size = 3, and at the same time the cluster will begin to redistribute the data, decomposing another copy of the existing data on the disks, without stopping the work of clients.
Pool
A pool is a logical abstract container for storing user data. Any data is stored in the pool as objects. Multiple pools can be spread on the same disks (and maybe in different ways how to configure) using different sets of placement groups. Each pool has a number of customizable parameters: replication factor, number of placement groups, the minimum number of live replicas of the object required for operation, etc. Each pool can have its own replication policy (by city, data center, rack or even disk). For example, a pool for hosting may have a replication factor of size = 3, and a failure zone will be data centers. And then Ceph will ensure that each piece of data has one copy in three data centers. In the meantime, the pool for virtual machines may have a replication factor of size = 2, and the level of failure will already be the server rack. And in this case, the cluster will store only two copies. At the same time, if we have two racks with a storage of virtual images in one data center, and two racks in another, the system will not pay attention to data centers, and both copies of data can fly into one data center, but guaranteed to be in different racks, as we wanted .
Placement Group (PG)
Placement groups are such a link between the physical storage layer (disks) and the logical organization of data (pools).
Each object at the logical level is stored in a specific place-group. At the physical level, it lies in the right number of copies on different physical disks, which are included in this placement group (in fact, not disks, but OSD, but usually one OSD is one disk, and for simplicity I will call it drive, although I remind you, it may be a RAID array or an iSCSI device). With the replication factor size = 3, each placement group includes three disks. But at the same time, each disc is in a multitude of placement groups, and for some groups it will be primary, for others - a replica. If OSD is included, for example, into three placement groups, then when such an OSD falls, placement groups will exclude it from work, and in its place each placement group will select a working OSD and spread the data on it. Using this mechanism, a fairly uniform distribution of data and load is achieved. This is a very simple and at the same time flexible solution.
Monitors
A monitor is a daemon that acts as a coordinator from which the cluster begins. As soon as we have at least one working monitor, we have a Ceph cluster. The monitor stores information about the health and condition of the cluster, exchanging various maps with other monitors. Clients access monitors to find out which OSDs to write / read data on. When a new storage is deployed, the monitor (or several) is created first. A cluster can live on one monitor, but it is recommended to make 3 or 5 monitors, in order to avoid the fall of the entire system due to the fall of a single monitor. The main thing is that the number of these should be odd in order to avoid situations of a split consciousness (split-brain). Monitors operate in a quorum, so if more than half of the monitors fall, the cluster will be locked to prevent data mismatch.
OSD (Object Storage Device)
OSD is a storage unit that stores the data itself and processes customer requests, exchanging data with other OSDs. This is usually a disk. And usually a separate OSD daemon is responsible for each OSD, which can be run on any machine on which this disk is installed. This is the second thing that needs to be added to the cluster, when deployed. One monitor and one OSD - the minimum set in order to raise the cluster and start using it. If there are 12 disks spinning on the server for storage, then the same OSD daemons will be launched on it. Clients work directly with the OSD themselves, bypassing the bottlenecks, and thus achieving load distribution. The client always writes the object to the primary OSD for some group placement, and further on this OSD synchronizes data with the other (secondary) OSD from the same placement group. Confirmation of a successful record can be sent to the client immediately after writing to the primary OSD, or maybe after reaching the minimum number of records (pool parameter min_size). For example, if the replication factor size = 3, and min_size = 2, then confirmation of successful recording will be sent to the client when the object is written to at least two of the three OSDs (including the primary one).
With different options for setting these parameters, we will observe different behavior.
If size = 3 and min_size = 2: everything will be fine as long as 2 out of 3 OSD placement groups are alive. When only 1 live OSD remains, the cluster will freeze the operations of this placement group until at least one more OSD comes to life.
If size = min_size, then the placement group will be blocked when any OSD that is part of it is dropped. And due to the high level of data blurring, the majority of crashes of at least one OSD will result in freezing of the entire or almost the entire cluster. Therefore, the size parameter should always be at least one item larger than the min_size parameter.
If size = 1, the cluster will work, but the death of any OSD will mean irretrievable data loss. Ceph allows you to set this parameter to one, but even if the administrator does this for a specific purpose for a short time, he takes the risk.
An OSD disk consists of two parts: the log and the data itself. Accordingly, the data is first written to the log, then to the data section. On the one hand, this provides additional reliability and some optimization, and on the other hand, an additional operation that affects performance. The issue of log performance will be discussed below.
CRUSH algorithm
The mechanism of decentralization and distribution is based on the so-called CRUSH algorithm (Controlled Replicated Under Scalable Hashing), which plays an important role in the system architecture. This algorithm allows you to uniquely determine the location of an object based on the object name hash and a specific map, which is formed based on the physical and logical structures of the cluster (data centers, halls, rows, racks, nodes, disks). The map does not include location information. Each client determines the path to the data himself, using the CRUSH algorithm and the current map, which he first asks for the monitor. When you add a disk or server crashes, the map is updated.
Thanks to determinism, two different clients will find the same unique path to one object on their own, eliminating the need to keep all these paths on some servers, synchronizing them with each other, giving a huge overload to the storage as a whole.
Example:
A client wants to write some object1 to pool1. To do this, he looks at the card of placement groups, which the monitor has kindly provided him before, and sees that Pool1 is divided into 10 placement groups. Then, using the CRUSH algorithm, which accepts the object name and the total number of placement groups in Pool1 as input, the placement group ID is calculated. Following the map, the client understands that this OS placement group has three OSDs (say, their numbers: 17, 9, and 22), the first of which is primary, which means the client will write to him. By the way, there are three of them, because replication factor size = 3 is set in this pool. After the object is successfully written to OSD_17, the client’s work is finished (this is if the pool parameter is min_size = 1), and OSD_17 replicates this object to OSD_9 and OSD_22 assigned to this placement group. It is important to understand that this is a simplified explanation of the operation of the algorithm.
By default, our CRUSH card is flat, all nodes are in the same space. However, you can easily turn this plane into a tree by distributing servers in racks, racks in rows, rows in halls, halls in data centers, and data centers in different cities and planets, indicating what level to consider the zone of failure. Using this new map, Ceph will more intelligently distribute data, taking into account the individual characteristics of the organization, preventing the sad consequences of a fire in a data center or a meteorite falling on a whole city. Moreover, thanks to this flexible mechanism, it is possible to create additional layers, both at the upper levels (data centers and cities), and at the lower levels (for example, additional division into groups of disks within one server).
Caching
Ceph provides several ways to increase cluster performance with cache methods.
Primary-affinity
Each OSD has several weights, and one of them is responsible for which OSD in the placement group will be primary. And, as we found out earlier, the client writes the data on the primary OSD. So, you can add to the cluster a pack of SSD drives, making them always primary, reducing the weight of primary-affinity HDD drives to zero. And then the recording will always be carried out first on a fast disk, and then slowly replicate to slow ones. This method is the wrong, but the easiest to implement. The main disadvantage is that one copy of the data will always be on the SSD and it will take a lot of such disks to fully cover the replication. Although someone used this method in practice, I rather mentioned it in order to tell about the possibility of controlling the priority of a recording.
Removal of journals on SSD
In general, the lion's share of performance depends on the OSD logs. When writing, the daemon first writes the data to the log, and then to the storage itself. This is always true, except when using BTRFS as a file system on OSD, which can do this in parallel thanks to the copy-on-write technique, but I still do not understand how ready it is for industrial use. Each OSD has its own log, and by default it is on the same disk as the data itself. However, logs from four or five drives can be brought to one SSD, not bad speeding up write operations. The method is not very flexible and convenient, but quite simple. The disadvantage of the method is that during the departure of the SSD with the magazine, we will lose several OSDs at once, which is not very pleasant and introduces additional difficulties into all further support, which scales with the growth of the cluster.
Cash Tiring
The orthodoxy of this method is in its flexibility and scalability. The scheme is such that we have a pool with cold data and a pool with hot data. With frequent access to the object, it heats up and enters the hot pool, which consists of fast SSDs. Then, if the object cools, it falls into a cold pool with slow HDDs. This scheme allows you to easily change the SSD in the hot pool, which in turn can be of any size, because the parameters of heating and cooling are regulated.
From the client's point of view
Ceph provides the client with various options for accessing data: a block device, a file system, or object storage.
Block Device (RBD, Rados Block Device)
Ceph allows you to create a block RBD device in the data pool, and later mount it on operating systems that support it (at the time of writing, there were only various linux distributions, however FreeBSD and VMWare are also working in this direction). If the client does not support RBD (for example, Windows), then an intermediate iSCSI-target with RBD support (for example, tgt-rbd) can be used. In addition, such a block device supports snapshots.
CephFS file system
A client can mount a CephFS file system if it has linux with kernel version 2.6.34 or newer. If the kernel version is older, then you can mount it through FUSE (Filesystem in User Space). In order for clients to connect Ceph as a file system, you need to raise at least one metadata server (MDS) in a cluster
Object Gateway
Using the RGW Gateway (RADOS Gateway), customers can be given the opportunity to use storage through a RESTful Amazon S3 or OpenStack Swift compatible API.
Other...
All these data access levels operate on top of the RADOS level. The list can be supplemented by developing your data access layer using the librados API (through which the access layers listed above work). At the moment there are C, Python, Ruby, Java and PHP bindings
RADOS (Reliable Autonomic Distributed Object Store), in a nutshell, this is a layer of interaction between customers and the cluster.
Wikipedia says that Ceph itself is written in C ++ and Python, and Canonical, CERN, Cisco, Fujitsu, Intel, Red Hat, SanDisk, and SUSE take part in the development.
Impressions
Why did I write all this and draw pictures? Then that despite all these advantages, Ceph is either not very popular, or people eat it secretly, judging by the amount of information about it on the Internet.
The fact that Ceph is flexible, simple and convenient, we found out. The cluster can be raised on any hardware in a normal network, spending a minimum of time and effort, while Ceph will take care of data integrity by taking the necessary measures in case of iron failures. The fact that Ceph is flexible, simple and scalable converges many points of view. However, reviews of performance are very diverse. Maybe someone did not cope with the logs, someone summed up the network and delays in I / O operations. That is, making the cluster work is easy, but making it work quickly is perhaps more difficult. Therefore, I appeal to IT professionals who have experience using Ceph in production. Share in comments about your negative impressions.
Links
Ceph website
Wikipedia
Documentation
Github
Ceph Recipe Book
Learning Ceph Book
Ceph on VMWare in 10 minutes
Ceph Intensive in Russian
Source: https://habr.com/ru/post/313644/
All Articles