Technologies of development and support of a complex product: the experience of "Hydra"

In our blog, we already talked about billing for Hydra communication operators - our approaches to the development of complex products , and also described real cases of system implementation . Today we will talk more about the stack of technologies and tools that are used in the development and operation of our project.
Architecture
Before describing the technologies used, we will take a closer look at what the billing system consists of.
- Data - information about services consumed by subscribers, personal account balances, details of payments and debits.
- The kernel is part of the system in which all data operations are conducted. In Hydra, it is integrated with data - business logic is located directly in the database in the form of stored procedures. Modifying data directly to external applications is prohibited, it can be done only through the API.
- AAA server (Authentication, Authorization, Accounting) is an element that is responsible for authentication, authorization and accounting of important information about the services consumed by subscribers.
- Payment gateway - accepts information about payments made from various payment systems.
- Subscriber personal account and web control panel - interfaces for access and work with the system.
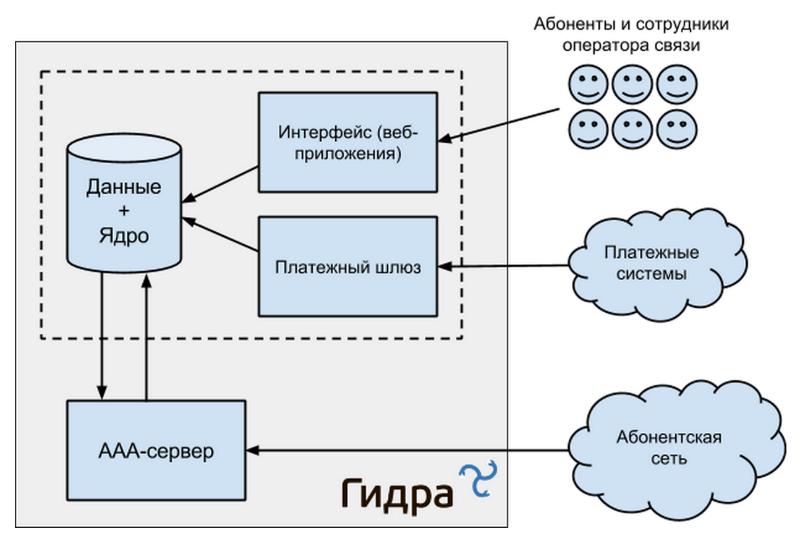
System architecture overview
')
Now let's talk about specific technologies.
DBMS: Oracle and MongoDB
Our billing system uses the relational DBMS Oracle for accounting of primary data and storage of financial information. It is perfect for this purpose. The main database stores data and the core of the system. We use a degenerate three-tier architecture - business logic (stored procedures and functions in Oracle) and data (tables) are tightly integrated into the DBMS, the browser (“thin client”) acts as a client, and the web interface serves as a program shell to the kernel.
But some Hydra modules, for example, a RADIUS server, work under high load and can receive thousands of requests per second with severe restrictions on the processing time of the request. In addition, in the database of our autonomous RADIUS server, the data is stored as an AVP set (attribute / value pair). In such a scenario, a relational DBMS no longer looks like the best solution, and then MongoDB comes to the rescue with its repository of documents of arbitrary structure, quick response and horizontal scalability.
When operating on more than 100 Hydra installations over the past 5 years, we have not found any serious problems with Mongo. But a couple of nuances are still there. First, after a sudden shutdown of the server, the database, although it recovers from the log, but it happens slowly. Fortunately, the need for this occurs infrequently. Secondly, even with a small database size, rarely used data is flushed to disk, and when a request is received, it takes a long time to retrieve it. As a result, the restrictions on the execution time of the request are violated.
All of this refers to the MMAPv1 engine, which Mongo uses by default. We have not yet experimented with others (WiredTiger and InMemory) - the problems are not so serious.
See also: When it is worth and not worth using MongoDB
Work with data: JSON
In addition to Hydra billing, we are developing an open-source business process management system Hydra OMS. In this project, PostgreSQL is also used, and JSON is used to work with data. In particular, we store in these fields the values of process variables, the structure of which is determined at the time of product introduction, and not during its development.
Work with the fields of the table is made through the adapter framework Ruby On Rails for PostgreSQL. Reading and writing work in native Ruby mode - through hashes and lists. Thus, you can work with data from the field without additional conversions.
See also: How to use JSON restrictions when working with PostgreSQL
Performance Optimization: Denormalization
We in Latera do a lot of work on optimizing the performance of the billing system, which is not surprising given the volumes of our clients and the specifics of the telecom industry.
On Habré we discussed the material of foreign colleagues on the use of denormalization of databases. One of the examples presented in this article assumes the creation of a table with intermediate totals to speed up the reports. Of course, the most difficult thing in this approach is to maintain the current state of such a table. Sometimes it is possible to shift this task to a DBMS — for example, to use materialized views. But, when business logic is slightly more complex to obtain intermediate results, the relevance of denormalized data has to be maintained manually.
So, Hydra has a deeply developed system of privileges for users, billing operators. Rights are granted in several ways - you can allow certain actions to a specific user, you can prepare roles in advance and give them different sets of rights, you can give a certain department special privileges. Just imagine how slow the calls to any entities of the system would be if every time you had to go through this whole chain to make sure: “yes, this employee is allowed to enter into agreements with legal entities” or “no, this operator does not have enough privileges to work with subscribers of the neighboring branch ". Instead, we separately store the ready aggregated list of existing rights for users and update it when changes are made to the system that can affect this list. Employees move from one department to another much less frequently than they open the next subscriber in the billing interface, which means we have to calculate the full set of their rights just as often.
Of course, denormalizing the repository is only one of the measures taken. Part of the data should be cached directly in the application, but if intermediate results on average live much longer than user sessions, it makes sense to seriously think about denormalization to speed up reading.
See also: Why database denormalization is needed, and when to use it
Hardware Control: Clojure
We are now using Clojure hardware management commands. The specificity of the task lies in the requirements for simultaneity in the execution of commands and flexible constraints. On the one hand, it is impossible to “fill up” one device with commands, on the other hand, to execute all commands sequentially inefficiently, because they can be executed in parallel on different equipment. This task is easily solved by the core.async library, which adds support for go-blocks and channels familiar from the Go language, where they use interacting sequential processes (a term better known as CSP).
At the same time, Slojure is a general-purpose language; it is easy to find its use. Since it is based on the JVM, there is actually a huge choice of libraries for it, so using it does not need to write everything anew, which greatly reduces the entry threshold.
Even if you don’t tolerate Lisp, you should become familiar with the concepts that are inherent in the language, many of them make you take a fresh look at programming.
See also: Why you should learn and use Clojure
Project management and support
Initially, the Jira system was used for the tasks of the implementation and technical support department. However, over time it became obvious that adapting this tool for developers to the tasks of the implementation and support department is not so easy. As a result, we began to look for alternative means.
One of the options considered was the Zendesk service, but the inconvenient one-page interface was an obstacle to its use, in which and only in which, according to the authors, the support department staff should work. In addition, the speed of Zendesk left much to be desired. We encountered these problems in 2013, perhaps now the project has taken a step forward, however we have already found an alternative to it.
She became the service Freshdesk - it is similar to Zendesk, but has a more friendly interface and is developing quite actively. The developers promptly respond to requests, the API interface is implemented in their system.
To manage implementation projects, we use the Teamwork PM service. In this system, all the necessary stages of the project, tasks that need to be completed, and those areas of work that will be unlocked after this are shown. Also listed are those responsible for solving the tasks on both sides.

Also for some tasks Jira is still used (management of tasks that are not suitable for the purpose of any of the other control systems).
In addition, we have organized our own data warehouse (Data Warehouse), which uploads information from all existing systems and Hydra billing itself, which is used for charging the paid support time (it is automatically loaded into the billing from the storage) and billing. This information is then used to organize the work of the support department.
See also: How to organize support for a complex product
Conclusion
Our project has been developing for 9 years, and during this time we have participated in more than 100 implementation projects. We are constantly working to make the system more reliable and convenient for customers.
In our blog, we will continue to talk about the technologies we use and approaches to improving the work of “Hydra”.
Other articles on IT infrastructure from the Latera team:
- Weekdays billing: How we prepared for the denomination in Belarus
- How to make migration to a new billing easy and understandable: automate data transfer
- We automate the accounting of addresses and bindings in IPoE-networks
- Developing an application to increase the efficiency of field staff: Experience Planado.ru
- What else affects the infrastructure: How to ensure the quality of equipment installation
Source: https://habr.com/ru/post/313508/
All Articles