Interview with MapR's VP of Technology Strategy
Greetings, Habr! I helped my friends a little to prepare the CEE-SECR 2016 conference and, in the process, I met Crystal Valentine, vice president of MapR's technology strategy. Kristal is a great fellow, very collected, purposeful, deeply understanding her industry. With her exceptional employment she is able to cooperate very comfortably. And her company is not one of the last. I think her report in Moscow will be very interesting, but I wanted to know more about the views on the future of the industry vice president for technology strategy and I came up with an interview with Crystal. Here's what I got. Crystal very kindly answered all the questions I asked her. On the whole, Crystal answers are distinguished by the density of information provided for a line of text, clarity of formulations, the ability to remain within the desired boundaries and an extremely clear vision of the company's mission and future market.
 Me: For several years, a scalable file system has been a unique feature of the MapR architecture. Now, data storage itself is becoming cheaper and cheaper, and users are more interested in system flexibility and performance. Tell us what new key decisions in the development of MapR should respond to the growing demands of consumers.
Me: For several years, a scalable file system has been a unique feature of the MapR architecture. Now, data storage itself is becoming cheaper and cheaper, and users are more interested in system flexibility and performance. Tell us what new key decisions in the development of MapR should respond to the growing demands of consumers.
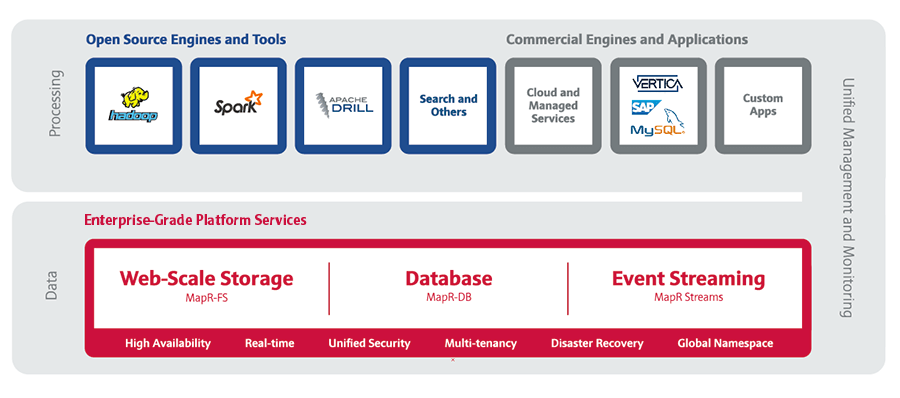
Crystal (hereinafter referred to as K): The MapR company has traveled quite a long and difficult path since its inception in 2009. As it developed, the company introduced a series of leading industry innovations, and today all these innovations are brought together in the MapR Convergent Data Platform (hereinafter referred to as CDP MapR) .
When MapR first entered the market in 2011, it gained fame through the Hadoop enterprise system, built on the basis of the MapR file system, a patented high-performance scalable data storage layer that supports the Apache HDFS API. This product was recognized by Forrester (a US independent technology and market research company) as the best Hadoop platform.
')
In 2013, the company introduced the MapR DB - NoSQL database with support for the Apache HBase API. Forrester also ranked this product as the best NoSQL database. Later, support for JSON documents was added to MapR DB, and in 2014 Apache Drill appeared. He was recognized as the best SQL tool by Gigaom (Media Company in California) .
Last year, MapR introduced the MapR Streams product - a scalable messaging system that supports the Apache Kafka API and has high performance and high bandwidth.
Of course, each of these tools can be used alone, many of them were recognized as the best in their segment. But, in my opinion, the maximum effect from the use of CDP MapR occurs when all of these products work — a large data warehouse of various levels of availability, scalable NoSQL and streaming and storage of messages — on a single platform. In CDP, all files, tables, and streams — potentially located in multiple data centers — can be accessed in a single space. The platform supports many different computing systems (including MapReduce, Spark, YARN jobs and many others) with multi-user access. This makes it possible to create applications with a modern architecture, when old data is used together with new data sources on a high-performance platform.
In the future, it is also expected to introduce very interesting innovative products and options. For example, we recently announced that CDP will support microservices.
Me: What significant releases do you foresee in the market for big data and machine learning in the near future?
K: We live in an extraordinarily exciting and cool time, because most of the theories of machine learning and artificial intelligence were developed back in the 50s, but only now we have enough powerful big data platforms that are able to support these data-loaded algorithms in volume, speed and cost, which allow to realize these theories.
The market is growing incredibly fast. It is difficult to identify any one specific product. But I think we will see a serious development of some sectors, namely, the Internet of things, cloud computing (in particular, hybrid clouds or applications that can use multiple data centers), microservices (which have several advantages and are ideal for learning and validating machine learning models) as well as deep learning.
Me: When MapR established a partnership with Skytree three years ago, it was a big step in the right, but unknown direction. Now the advantages of this direction are obvious and understandable for everyone. But don't you think that now in the machine learning market, open source products are more in demand than patented ones?
Q: The advantage of CDP is the ability to give users a wide choice of tools and thereby ensure the flexibility of the data analysis and processing process. Yes, of course, open source products are developing rapidly. But many customers are looking for partners such as SkyTree to provide a quick start by applying a variety of algorithms and machine learning models. In the end, we want to give freedom to application developers. CDP provides this capability and improves application performance, regardless of whether they use open source products or proprietary systems.
Me: Do you think Spark and Hadoop are competing with each other? Or is this technology rather complementary? Which of them would you recommend for building a business infrastructure?
K: The big data market is quite complex. At present, the consumer has a wide choice of open source solutions focused on the use of a single approach to data processing. As a result, applications with more complex characteristics often require complex, composite architectures consisting of several solutions working on different clusters and connected by a set of protocols.
One such solution is Apache Spark. Not so long ago, Apache Spark began to gain popularity because it uses methods to simplify I / O operations compared to the traditional approach that Apache implemented as MapReduce tasks, and also because Apache Spark offers more tools in its API than Map Reduce .
However, Spark does not have its own data storage layer, so it happens that it works on a MapR or Apache Hadoop cluster. Therefore, answering your question, I can say that they rather complement each other. Although today it is obvious that users prefer Apache Spark rather than “just” Map Reduce tasks. But here one should clearly understand the difference between the computing system and the infrastructure. In the end, both Spark and Hadoop allow you to develop interesting applications, but for large organizations it would be wise to have a holistic approach to their data, namely, to use a platform that can support both Hadoop and Spark along with many other computing systems.
Me: MapR and Google are known to be partner companies, MapR provides services based on the Google cloud. What do you think the impact of Tensor Processing will have on your product?
K: In general, MapR has partnerships with all major cloud providers, including Google Cloud. And, by the way, Google Capital is one of our investors. We have an extensive affiliate program, including Amazon Web Services, Microsoft Azure and CenturyLink Cloud.
We are convinced that cloud computing platforms will continue to conquer the market in the future. Therefore, on the one hand, we want to develop the computing systems that our customers wish to use, and on the other hand, we want to give them the opportunity to use the infrastructure that is convenient for them, whether it is on-premise or publicly available or even a combination both kinds.
Google Tensor Flow and TPU are examples of great innovations being developed by a cloud technology provider. After all, in the end, machine learning algorithms (whether they work on TPU or not) only benefit from the ability to use large data sets for training. This, coupled with the ability to support real-time data flow and the development of flexible microservice practices for testing and training multiple models, makes CDP very attractive for those customers who use machine learning, including on Google Cloud.
Me: Tell me about your favorite cases of using MapR technology clients.
K: In fact, MapR clients are usually tech-savvy people, they choose CDP because they are focused on solving innovative problems, which means that a platform requires one that will provide a wide field for developing competitive advantages. It seems to me that the Adtech field is very interesting, since it is an industry whose development is directly determined by technology. The main competitive advantage of a company that operates in this area should be the quality and speed of its platform. In many respects, Adtech would not exist in the form in which we know this area, if not for the huge advances in computing platforms.
But overall, my favorite case is the Aadhaar project, which was implemented by the government of India. The population of India is extremely diverse, its number is 1.3 billion people. These people inhabit 640,000 villages and speak 22 official languages. A huge number of workers are migrants (300 million), the level of poverty of the population is very high, 60% of the population live on less than $ 2 a day. 75 million homeless people live in the country. The government spends about $ 40 billion a year in subsidies for the poor, including food, fuel, transportation. But most of this money has disappeared in an unknown direction due to fraud and corruption. The problem was that the country did not have a reliable state identification system. Due to the low literacy rate of the population, the government decided to implement a biometric database that could identify a citizen of India on the basis of his fingerprints and an iris scan.
The project was launched in 2009 and works on the basis of CDP MapR. Today, more than 1 billion people are already registered in the system. This represents 95% of the adult population of India. Every day, 500,000 new people are registered in the system. More than 100 million authorizations are performed by the system daily. The average response time is 200 milliseconds. The system uses a MapR mirror for greater availability and to prevent errors, so even interruptions in electricity or the network are not able to disable it.
I love this case, because it is an excellent example of how technologies change people's lives for the better. Government subsidies in India finally reach all recipients and improve the quality of life of those who need it.
Me: What strategy would you recommend to companies that are trying to integrate big data into their business strategy?
K: We in MapR often say that companies need to develop a specific data strategy. The concepts of marketing strategy, technology strategy, pricing strategy are familiar and understandable for business. But today this is not enough, today business also needs to have a data strategy. All companies, regardless of the industry today, recognize that the huge opportunities are hidden in the proper use of the data available to them. In order to do this in the most efficient way, IT companies must change their way of thinking. Now, no applications dictate what data is needed. Now the data should be central. Using a data platform that provides fast, secure, and easy access to all of your organization’s data will accelerate the development of many innovative applications.
Me: For several years, a scalable file system has been a unique feature of the MapR architecture. Now, data storage itself is becoming cheaper and cheaper, and users are more interested in system flexibility and performance. Tell us what new key decisions in the development of MapR should respond to the growing demands of consumers.Crystal (hereinafter referred to as K): The MapR company has traveled quite a long and difficult path since its inception in 2009. As it developed, the company introduced a series of leading industry innovations, and today all these innovations are brought together in the MapR Convergent Data Platform (hereinafter referred to as CDP MapR) .
When MapR first entered the market in 2011, it gained fame through the Hadoop enterprise system, built on the basis of the MapR file system, a patented high-performance scalable data storage layer that supports the Apache HDFS API. This product was recognized by Forrester (a US independent technology and market research company) as the best Hadoop platform.
')
In 2013, the company introduced the MapR DB - NoSQL database with support for the Apache HBase API. Forrester also ranked this product as the best NoSQL database. Later, support for JSON documents was added to MapR DB, and in 2014 Apache Drill appeared. He was recognized as the best SQL tool by Gigaom (Media Company in California) .
Last year, MapR introduced the MapR Streams product - a scalable messaging system that supports the Apache Kafka API and has high performance and high bandwidth.
Of course, each of these tools can be used alone, many of them were recognized as the best in their segment. But, in my opinion, the maximum effect from the use of CDP MapR occurs when all of these products work — a large data warehouse of various levels of availability, scalable NoSQL and streaming and storage of messages — on a single platform. In CDP, all files, tables, and streams — potentially located in multiple data centers — can be accessed in a single space. The platform supports many different computing systems (including MapReduce, Spark, YARN jobs and many others) with multi-user access. This makes it possible to create applications with a modern architecture, when old data is used together with new data sources on a high-performance platform.
In the future, it is also expected to introduce very interesting innovative products and options. For example, we recently announced that CDP will support microservices.
Me: What significant releases do you foresee in the market for big data and machine learning in the near future?
K: We live in an extraordinarily exciting and cool time, because most of the theories of machine learning and artificial intelligence were developed back in the 50s, but only now we have enough powerful big data platforms that are able to support these data-loaded algorithms in volume, speed and cost, which allow to realize these theories.
The market is growing incredibly fast. It is difficult to identify any one specific product. But I think we will see a serious development of some sectors, namely, the Internet of things, cloud computing (in particular, hybrid clouds or applications that can use multiple data centers), microservices (which have several advantages and are ideal for learning and validating machine learning models) as well as deep learning.
Me: When MapR established a partnership with Skytree three years ago, it was a big step in the right, but unknown direction. Now the advantages of this direction are obvious and understandable for everyone. But don't you think that now in the machine learning market, open source products are more in demand than patented ones?
Q: The advantage of CDP is the ability to give users a wide choice of tools and thereby ensure the flexibility of the data analysis and processing process. Yes, of course, open source products are developing rapidly. But many customers are looking for partners such as SkyTree to provide a quick start by applying a variety of algorithms and machine learning models. In the end, we want to give freedom to application developers. CDP provides this capability and improves application performance, regardless of whether they use open source products or proprietary systems.
MapR Converged Data Platform
Me: Do you think Spark and Hadoop are competing with each other? Or is this technology rather complementary? Which of them would you recommend for building a business infrastructure?
K: The big data market is quite complex. At present, the consumer has a wide choice of open source solutions focused on the use of a single approach to data processing. As a result, applications with more complex characteristics often require complex, composite architectures consisting of several solutions working on different clusters and connected by a set of protocols.
One such solution is Apache Spark. Not so long ago, Apache Spark began to gain popularity because it uses methods to simplify I / O operations compared to the traditional approach that Apache implemented as MapReduce tasks, and also because Apache Spark offers more tools in its API than Map Reduce .
However, Spark does not have its own data storage layer, so it happens that it works on a MapR or Apache Hadoop cluster. Therefore, answering your question, I can say that they rather complement each other. Although today it is obvious that users prefer Apache Spark rather than “just” Map Reduce tasks. But here one should clearly understand the difference between the computing system and the infrastructure. In the end, both Spark and Hadoop allow you to develop interesting applications, but for large organizations it would be wise to have a holistic approach to their data, namely, to use a platform that can support both Hadoop and Spark along with many other computing systems.
Me: MapR and Google are known to be partner companies, MapR provides services based on the Google cloud. What do you think the impact of Tensor Processing will have on your product?
K: In general, MapR has partnerships with all major cloud providers, including Google Cloud. And, by the way, Google Capital is one of our investors. We have an extensive affiliate program, including Amazon Web Services, Microsoft Azure and CenturyLink Cloud.
We are convinced that cloud computing platforms will continue to conquer the market in the future. Therefore, on the one hand, we want to develop the computing systems that our customers wish to use, and on the other hand, we want to give them the opportunity to use the infrastructure that is convenient for them, whether it is on-premise or publicly available or even a combination both kinds.
Google Tensor Flow and TPU are examples of great innovations being developed by a cloud technology provider. After all, in the end, machine learning algorithms (whether they work on TPU or not) only benefit from the ability to use large data sets for training. This, coupled with the ability to support real-time data flow and the development of flexible microservice practices for testing and training multiple models, makes CDP very attractive for those customers who use machine learning, including on Google Cloud.
Me: Tell me about your favorite cases of using MapR technology clients.
K: In fact, MapR clients are usually tech-savvy people, they choose CDP because they are focused on solving innovative problems, which means that a platform requires one that will provide a wide field for developing competitive advantages. It seems to me that the Adtech field is very interesting, since it is an industry whose development is directly determined by technology. The main competitive advantage of a company that operates in this area should be the quality and speed of its platform. In many respects, Adtech would not exist in the form in which we know this area, if not for the huge advances in computing platforms.
But overall, my favorite case is the Aadhaar project, which was implemented by the government of India. The population of India is extremely diverse, its number is 1.3 billion people. These people inhabit 640,000 villages and speak 22 official languages. A huge number of workers are migrants (300 million), the level of poverty of the population is very high, 60% of the population live on less than $ 2 a day. 75 million homeless people live in the country. The government spends about $ 40 billion a year in subsidies for the poor, including food, fuel, transportation. But most of this money has disappeared in an unknown direction due to fraud and corruption. The problem was that the country did not have a reliable state identification system. Due to the low literacy rate of the population, the government decided to implement a biometric database that could identify a citizen of India on the basis of his fingerprints and an iris scan.
The project was launched in 2009 and works on the basis of CDP MapR. Today, more than 1 billion people are already registered in the system. This represents 95% of the adult population of India. Every day, 500,000 new people are registered in the system. More than 100 million authorizations are performed by the system daily. The average response time is 200 milliseconds. The system uses a MapR mirror for greater availability and to prevent errors, so even interruptions in electricity or the network are not able to disable it.
I love this case, because it is an excellent example of how technologies change people's lives for the better. Government subsidies in India finally reach all recipients and improve the quality of life of those who need it.
Me: What strategy would you recommend to companies that are trying to integrate big data into their business strategy?
K: We in MapR often say that companies need to develop a specific data strategy. The concepts of marketing strategy, technology strategy, pricing strategy are familiar and understandable for business. But today this is not enough, today business also needs to have a data strategy. All companies, regardless of the industry today, recognize that the huge opportunities are hidden in the proper use of the data available to them. In order to do this in the most efficient way, IT companies must change their way of thinking. Now, no applications dictate what data is needed. Now the data should be central. Using a data platform that provides fast, secure, and easy access to all of your organization’s data will accelerate the development of many innovative applications.
Source: https://habr.com/ru/post/313390/
All Articles