Sharding - patterns and antipatterns

Konstantin Osipov ( kostja ), Alexey Rybak ( fisher )
Konstantin Osipov: The report was born from the next conversation. As always, I tried to convince Alexey to use Tarantool more, and he said that there is still no sharding and, generally, is not interesting. Then we began to talk about why not. I began to tell that there is no one universal solution, the automation is complete for you, and you only drink coffee at work and all ...
Therefore, this report was born - to look at what sharding is, what methods are used in which systems, what are the advantages and disadvantages, why it is impossible to solve everything with a single silver bullet?
If we talk about sharding as a problem, then, generally speaking, there is no such problem. There is a problem with distributed systems, i.e. There are large databases that scale horizontally, they have many tasks, we have listed them:
')

First of all, the more nodes you have, the more acute the problem of their failure. Imagine that you out of 1000 computers one by one will break, on average, every other day or more. Therefore, you are faced with the task of data redundancy in order not to lose them. And this is not sharding. It is rather a replication.
The most difficult problem in a distributed system is the problem of membership, i.e. who enters it, who does not, because the machines fail, errors occur, and permanent membership in the distributed system changes. We will not talk about this either.
There is a task of distributed execution of complex queries. MapReduce or distributed SQL. This is not it either.
So, what are we going to talk about?
We will take one topic, namely the topic of how a certain amount of data that does not fit on one machine can be distributed horizontally across a horizontal cluster, and how to manage it all afterwards.
Alex Rybak: I will add. The term is already settled, but, nevertheless, what is sharding? Suddenly, someone does not know. Sharding is a method, as a rule, of horizontal data separation. Most often, sharding is spoken not only about distributed databases, but, in general, about distributed storage. We will primarily focus on databases.

Konstantin Osipov: In our report we took three things that make up the sharding itself:
- sharding function selection,
- where your data is located (how you find it),
- how you redistribute your data.
We will try to make this report not theoretical, but how it works in those projects that we know, i.e. there will be life stories.
Alexei Rybak: Despite the fact that we will tell all sorts of stories about what has been done and how, nevertheless, the basis of the report is methodological. To imagine how everything is usually done (and, in one way or another, everything is done in only a few ways), so that the terms are settled, and the next time, if we go into some topics, we would speak the same language.
Konstantin Osipov: We are not faced with the task of convincing you to use one or another product, but with the help of this report, maybe you can better understand how this or that product works “under the hood” and what are the advantages and disadvantages of the solution chosen by the developers this product.
You can manage any system only by understanding how it works.
Actually, what is sharding on the surface? This is the choice of the method. I will designate this choice like this:

We have a key, we need to define a shard. A shard is usually either the IP address or the DNS address of the computer on which it is all located.
In fact, the formula is incorrect, because in the general case there should be a function of the key and the number of servers, i.e. how many machines we have or, in general, from multiple servers. And it should produce the right server, because it works differently on different numbers of servers.
But before we talk about this, we want to talk about something more fun, namely, choosing the right key for which this partitioning is performed. Here the story, in general, is this: you choose the key, by which you shuffle the data once, and you live with it all your life, well, or for a long time - several years, and you get all the advantages and disadvantages of this business.
And much later, when something cannot be done (because the data are already distributed in a certain way, the system is already running, downtime is impossible), what problems can there be, stories?
One story - from 2001, the time of SpyLOG's youth - there the sharding was based on users. What is SpyLOG? Now it is openstat. It collects statistics of visits, i.e. This is such a tracker, a counter, a small button on the page.
In general, all sites, both large and small, were at that time distributed over 40 machines. And, accordingly, larger sites lived together with smaller sites, i.e. the sharding key was the site ID, for example, anecdot.ru, rambler.ru, yandex.ru ...
It so happened that the big sites actually laid our machines, because one traffic generated by one sharding key was more than one machine could accept.
Therefore, when you choose what you shuffle the data, you must select a small enough object so that it does not put the system.
For example, in the case of Facebook, you have a Justin Bieber page, and you decide to share the data on users too. Naturally, Justin Bieber has a million of followers, likes, a lot of reposts for his every message, etc. Therefore, probably, the choice of Justin Bieber as the one for whom you will be sharding is not the best idea.
The second point that must be borne in mind when sharding is that sharding is not about normalization, i.e. if you think that there is some canonical way to look at your data and determine how you will distribute it across your machines, then it is not. That is, you should look not at the data, but at the use cases, at your application, at your business, and you should think about which use case in your business is the most important and should be the most productive. Because in sharding there are always compromises. Some requests work quickly, instantly, some requests you will have to perform on the entire cluster. And the choice of which key you shuffle determines this.
Alexey Rybak: About Justin Bieber. And I think that in most social networks, in fact, the user's choice as a sharding key is a good choice. But it must be remembered that if you are packing all the posts, comments, etc., into the same shard, then be prepared that at some point you will have a very non-uniform distribution of data and you may need to use Your project has two types of sharding - one is your original, by users, and the second is some kind of additional - for example, by comments.
This will naturally cause the data to be (with some probability) inconsistent, that you will need to make two instead of one request. It's not scary, because with this you get the opportunity to somehow grow.
And if you pack everything on one shard, then you will have everything very unbalanced, and the quality of your software and your service for users can be very low. Therefore, it is not scary that we will make programming more complicated, but then everything will be quite fast. That is, it is quite a reasonable trade-off.
Konstantin Osipov: Another point that I would like to say. Not always sharding key you have stored. For example, storing sessions on mail.ru. Suppose you have an ID mail.ru, I have it kostea.mail.ru or something. Session is the object that identifies the device from which I came. Accordingly, one login has many sessions. Mail.ru keeps all sessions of one user on one shard, i.e. sharding key is login. But the session itself, i.e. object identifier - the primary key is not the sharding key. That is, it is not always the case that the object identifier is a sharding key. And it happens conveniently, since everything is stored on one shard. We can single user, for example, log off everywhere, if we suspect that his password has been hacked, etc. We can easily manage it.
Here is an example of good and bad shard keys:

Alexey Rybak: We will return to this example more than once, so we will continue.
If you are faced with sharding, then most likely it happened at the moment when you did not hear our report. You tried to search something on the Internet and found nothing special. In the past ten years, probably, many teams have gone the same way the invention of bicycles. Therefore, we will begin to examine our patterns or ways of organizing sharding with some of the most common and not the worst methods.
As the first two you can choose the following.
As a rule, it all starts with a single server, and there is such a completely simple for, including system administration, method - “yogurt of system administrators”. "Yogurt" - because it is light and useful.
Before we move on to this method, I want to note: when a large system is made, despite the fact that it starts with one or two servers, the most important thing when it grows is the cost of support — how many, relatively speaking, problems in operation this whole economy arises. Therefore, the convenience of the system administrator is a value that should probably be in the first place when such systems are designed.
So, you have one server, you picked up a replica, attached data to it, after some time you distributed the load, including by recording, and you think what to do next. And then you buy two more servers, each of them has its own replica. Why replica? Because from the point of view of system administration, this is quite simple - you set up a replica, then for some time there were banned recordings, so you just share as an amoeba, which is shown in this figure:
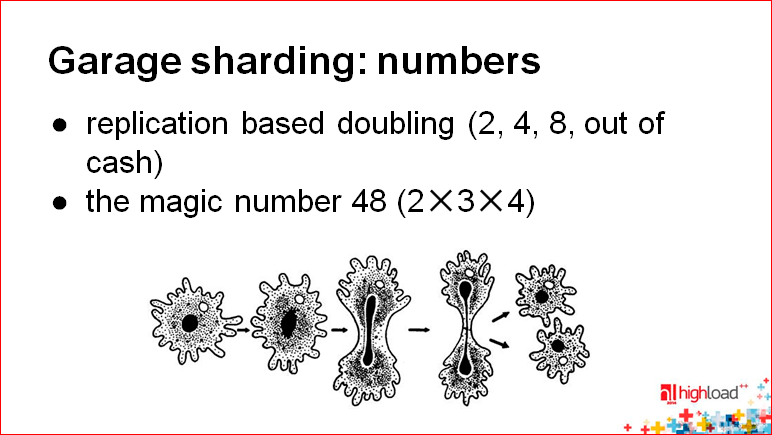
The problem is that you need to double all the time, and it will be very expensive. Therefore it is necessary to use something else.
There is some combination based on magic numbers. I wrote 48 here, in fact, this is just an example for an idea. What is convenient number 48? It is divided by 12, by 6, by 4, by 3. You can start with the fact that on one server you will hold 48 schemes or 48 tables, initially cut into such a number. After that, with simple operations for the system administrator, with dumps, you can transfer some of the data to other servers. In this case, of course, somewhere you should have a coordination logic, which we will talk about later. This method — using some special numbers that are easy to divide — will allow you to grow quite easily, for example, up to 48-50 servers.
Konstantin Osipov: In general, when you think about sharding, you first need to analyze your subject area, i.e. what kind of data you have stored.
There can not be a lot of data. Even if we talk about all the people on our planet, it is only 7-8 billion. It's not that much. Suppose if we are talking about all advertisements on any avito, then these are also millions, but these are not extraordinary values. Those. you have a ceiling. Any system grows, but its growth slows down as it grows larger. Therefore, it is not always necessary to take some of the most complex decisions in order to maximize everything. If you know that you will have a maximum of 10 servers, you may need a simple solution.
I also want to note that the choice of sharding formulas (on the slide, this formula — we just divide in half) is always associated with resharing.
Alexey Rybak: How do we distribute data between keys? While we spoke from the transfer of some schemes between servers. Then the question arises: how do we, in general, scatter the data? Chose the key, scattered data on the servers. There are two of the largest ways.
The first method is something similar to hashing. It does not have to be consistent, that is, roughly speaking, when adding new servers, your set of keys can be shuffled a lot (this is the next moment we'll talk about). Anyway, what are you doing? If this is a numeric key, you can simply divide it by the number of servers, get the remainder of the division - and this will be your server number. If this is a string key, for example, an e-mail, then you can take a numeric hash from it, then do the same.
There are more “garage” methods - such as choosing the first letter of a login, but since you can’t determine the distribution of logins by letter, you must initially take into account the distribution of letters in the language, but this is also quite difficult. Moreover, if you put one letter on one server, and then one letter does not fit into one server, then you will need to change the configuration very strongly in order to scatter this letter. Very bad idea. I would say that this is an anti-pattern.
We denote only one problem that occurs during hashing. This is adding new servers. What happens in case of rewarding from the point of view of support? You have a node crashes, you need to raise a master node for this part of the replicas and make it as fast as possible. Secondly, your load has simply increased, you need to purchase new servers and put them into operation as quickly as possible. Accordingly, resharing is a key issue.
If you just take the remainder of the division, then more servers appear, all the hashes are "re-blurred", all keys, all data needs to be moved. This is a very hard and bad operation. It works when you keep everything in mind.
For example, we have a memcached cluster in Badoo. We distributed everything according to the remainder of the division, added new servers (this happens not so often), and after maybe 5-10 minutes all the data was re-sorted. All this happens quite quickly, without any problems, because to move the data over the network and put it in the memory of another machine is garbage.
If you have user data on the disk, for example, some kind of correspondence, etc., then this is a much more complicated thing.
Konstantin Osipov: There is a sharding “for adults”. And this is the second part of our report.

What it is? Sooner or later, the idea that we have, in general, everything is a cloud, and we want to make our database resiliently scale up. Our sharding scheme should be exactly the same so that we don’t have to think about all these little details. This is very tempting.
We will now try to see if this is possible or not. We will analyze how this works, and you will draw conclusions.
Alexey Rybak: There are two very fundamental points here, two methods. We will consider one of them - Table functions.
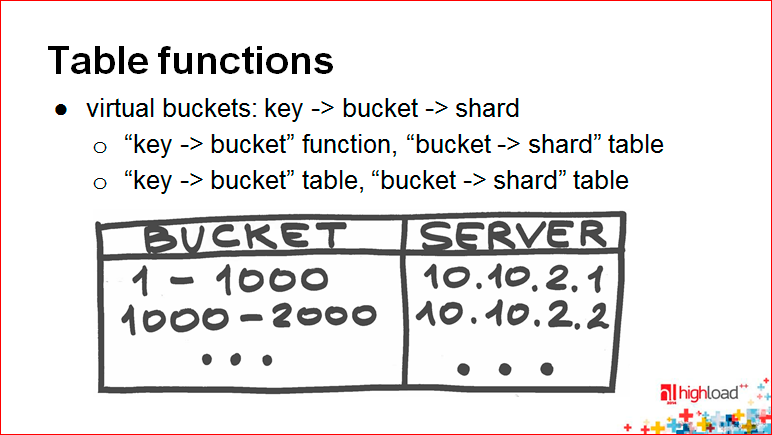
This is just a table function.
Let me remind you that one of the important tasks of this report is to reach an agreement, including on terms. For example, I used to use other words to denote this. I divided the methods into deterministic, i.e. when there is a certain mathematical formula, and non-deterministic, when you can freely configure where a particular key is mapped.
By and large, this is a table function and consistent hashing.
Table functions is when you just have some kind of config. The use of Table functions to sharding is very closely tied to such a concept as the virtual bucket.
Remember, you have the function of displaying the key on the shard. Imagine that you have some kind of intermediate display in the middle, i.e. this mapping turns into two. First you map the key to some virtual bucket, then the virtual bucket to the corresponding coordinate in the space of your cluster.
There are not very many methods to do it all. And we remember that the most important thing is to give freedom and convenience of work to the system administrator.
Virtual bucket-s, as a rule, are selected in a sufficiently large number. Why are they virtual? Because in reality they do not reflect a real physical server. And several methods are used to map the key directly to the shard.
One method is when the first part of the “key to bucket” function is just some kind of hash or consistent hash, i.e. some part that is determined by the formula, and the bucket directly on the shard is displayed through the config.
The second thing is more complicated - when you display both through the config. More complicated, because, relatively speaking, for each key you still need to remember where it lies. You acquire the ability to move any key anywhere, but on the other hand you lose the ability to quickly and easily, having just a small config in “bucket to shard”, determine the bucket from the key and then quickly go to the right place.
Konstantin Osipov: Why do these options, in general, arise? We will now talk about routing and resharing. Here everything is, in principle, beautiful, comfortable, fully manageable, but you have a certain condition. This state you need to store somewhere, it needs to be changed. You have increased the number of servers, you need to change your tables. There are two approaches here: first, you are hammering into the fact that you have a state, trying to control this state; the second approach - you try to mathematize your formula as much as possible, and then you have the most deterministic, without any state you can determine where to go when routing.
Here is one of the approaches that allows you to somehow functionally describe the sharding scheme. This is a consistent hashing approach.
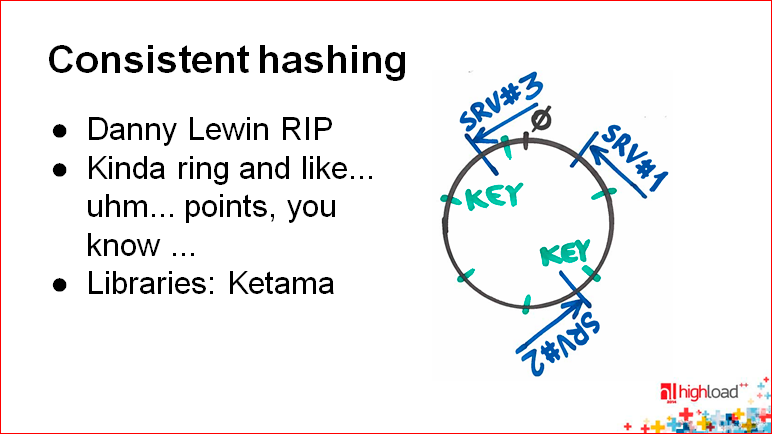
First, tell you how it works. We imagine that the entire range of our hash function is not displayed on a straight line from 0 to 2 32 (~ 4 billion), but on a ring. Those. we have 4 billion is approximately in the same place, where 0, we, like, fasten our straight line.
If we just use the hash function, we have to re-cache all this when adding new nodes. It turns out that we use the remainder of the division by the number of nodes.
And here we do not use the remainder of the division by the number of nodes. We do this — we have a hash function, perhaps another, apply it to the server identifier, and also locate the server on this ring. Thus, it turns out that each server is responsible for a certain range of keys after it on the ring. Accordingly, when you add a new server, it takes away the ranges that are before it and after it, i.e. he partially divides the range. No shuffling is absolutely required.
Alexey Rybak: I, when I heard it for the first time a long time, I still did not understand anything. If you do not understand anything, not scary.
The idea here is this: in consistent hashing when you add new nodes, you shuffle only a small part of the keys. And that's all.
How this is done, you can look at the relevant keywords.
Konstantin Osipov: Another couple of words about the shortcomings of this hashing story. This, after all, is about some random variables. The hash function is a certain randomizer, it takes your natural meaning, gives you a random one in response to this. All accidentally falls somewhere on the ring. And it does not provide in the simple case of an ideal distribution, i.e. you can do this (see the picture) so that server number 3 is near server number 1, and between server number 2 and number 3 is such a large half ring - almost half of the data.
In order for consistent hashing to work properly, you also need to add some state in the form of virtual buckets, mapping tables. And virtual buckets need to be stored somewhere. Mapping between virtual buckets and servers. Those. you have a condition. This is not pure mathematics.
We have another interesting slide with the keyword Guava / Sumbur:
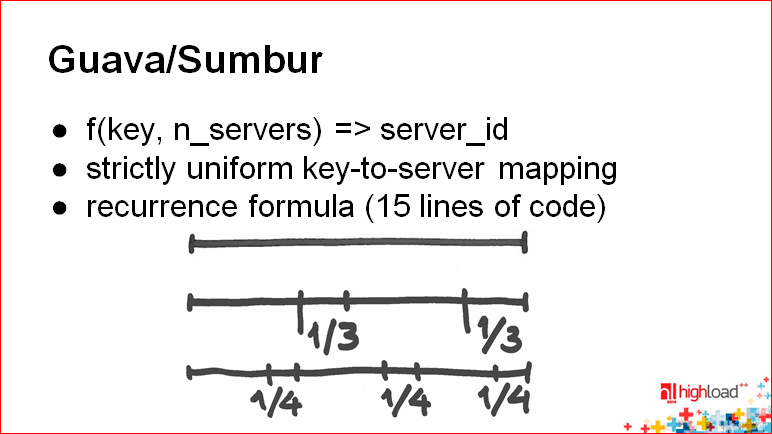
The idea of Guava - your state disappears altogether. In principle, this is a function that takes the key and the number of servers, and gives you server_id. , , - — — server_id.
. , — , , , .
— , . , , .. , . , , .
, , — , , , .. , .
: , , .
, .

, — :
- « »;
- ;
- coordinator
«».
« » — .
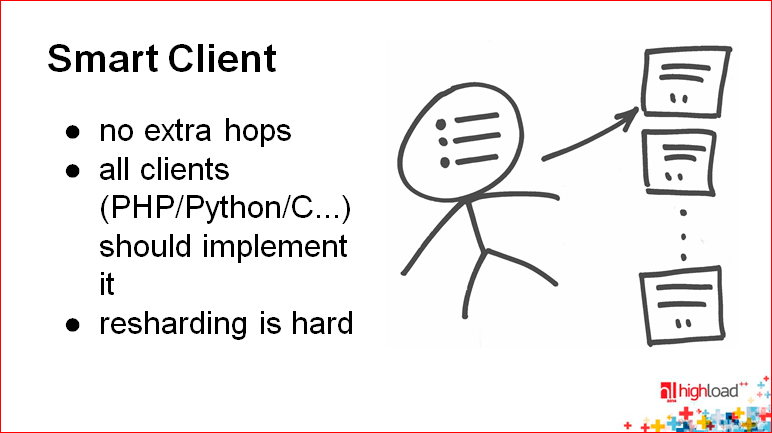
, , bucket. - , - . config, , , 1000 , 1000 , 1000 -. , - . , , , .
, , . — , , - - , , , — -. -, - , maintenance subwindow, , — , . - , - , - .. , , .
— .
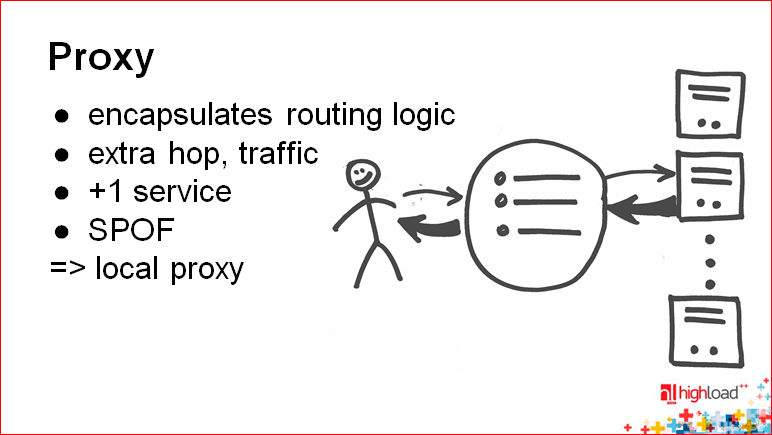
— .
: , ? , - , : «, ! ».
: , highload- ( ), , « — , , . , . , API, , , - … ».
, . , , : «, , ».
, , . .
, : , , , , , .
- , , , , , . , , , , , - , , .
, . , , . — , , . — .
, — .
: . . , . , ? load balancing-, , , .. , failover . Those.Proxy allows you to make application logic very simple.
There is a certain way to simplify all this technology, if you make the proxy work on the same host on which the application itself is running.
Another problem with proxies is that you need to propagate the sharding state, i.e. Proxy should know where the key is. And here we come to the following technology, which simplifies precisely this history - the technology of putting this state into one place - into the coordinator.
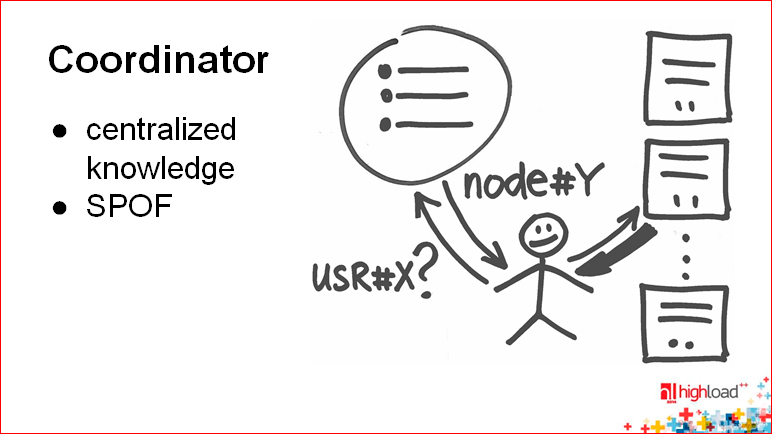
Alexey Rybak: — , (.. , - , ), . — , « ?». , .. , , -. , .
« ». - , . . - in-memory .
— , — , , .
. , . , — -, -.
: , , - , , , .. .
: , ( ) , , . .
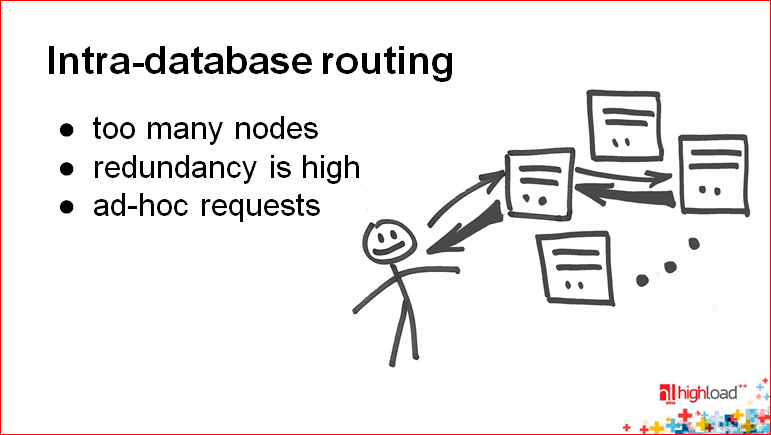
: . , , , , . — . Those. , . , . , .
— - , , , . Those. , , , . , , . , , . , .
, 100 , .
, , Redis. , .
, , , , .. . .
.

? , . , . .
: , . - , . , , . — — , - . .
: -. , , , . Those. - , , , , , . , , . — - , , — , « ».
: , , , , , .. , .
: . , , , , , , , . , . , , .
, - , , , , , , , .

: , , — . , ?
:The most successful implementations are implementations, which somehow manage without automatic or manual resarding, i.e. admins generally do not think about it. Only the developer thinks about it.
One approach is “update is a move”. The idea that follows is that whenever you change a key, you move it implicitly. Suppose you have a sharding key - this is actually the sharding key and the timestamp. When you change data, you change the timestamp, and you naturally find yourself on another shard. At some point you can close the updates to a certain shard and sooner or later just disable it. Those. , .
., , e-mail-. , e-mail ( ), -. , .. , timestamp.
, , , . . , .
, , , .
: , , , , - … - .
: — «data expiration».
memcached Badoo. , , — .
, . - . .
: — . , , - , , , , (, twitter )…
: , twitter . , , , … - , , — . .
: , , , .
. Badoo, , , . .
— , .. Badoo - — - , - . , 10 , «». What are we doing? «», , ( ) . , - , - . , ( , , , ) .
« ». , , .
: , — . - schema-less, , .
: — , ? , ..
, . — , . , , , . , .
, , .
: timestamp- . — ? Those.I'm looking for some word in my mail, how do I know when she came to me? How to go to the node?
Konstantin Osipov: Timestamp is used simply to make it automatically moved. This is used in the sharding key, but not in the search. When searching for another index, i.e. when a search query is made, this part is not used. It is used, relatively speaking, with the update.
Question from the audience: But I need an index to look for later. Back.
Alexey Rybak: Everything is fine with the index. Question: where does all this lie? The problem is that there is no coordination on any particular node. There is a query in parallel from the entire cluster. In fact, this is a choice between two large distributed search architectures. This is a separate topic.
— . .
— «», , , .
: Timestamp ?
: , .
: Newdata — . sharding function?
: sharding function . Badoo. . , . , -, , , Badoo , , y.
sharding function , . , , , , .
, Badoo. , -. bucket, bucket config-. config , - bucket- . , bucket-, , . - .
- , , -, . .
: , .. , , … - , ?
: .
-, - , . , .. « », - — , — Redis, Mongo — , , . , . It works. Cassandra, Hadoop, Mongo, Redis Cluster. Tarantool- .
, — . , , , , — . - , , . Those. , , .
, , , — .
: , , . , , . , - - , - . : « ? ». , , « », , — , - .
, . , , , .
Contacts
kostja
fisher
Mail.ru
Badoo
— HighLoad++ . 2016 — HighLoad++ , 7 8 .
— HighLoad++. , — :)
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Source: https://habr.com/ru/post/313366/
All Articles