JS Programming Contest: Word Classifier (Special Prizes)
We deeply apologize for the long delay in preparing this post. Today we publish an analysis of the self-learning solutions sent to the programming competition , and present two special prizes.
The English version of this post is on GitHub .
So, 9 of the submitted solutions turned out to be self-learning. The idea of self-study is this: since all words are selected from a finite vocabulary, and non-words are generated randomly, then any line that was presented to the program being tested again is more likely to be a word than a non-word. With sufficiently long testing, most of the words from the dictionary will have time to repeat, whereas for non-words, random repetitions are much less common.
')
To observe the behavior of self-learning solutions, we tested them for 1,000,000 blocks . To test all the solutions on such a number of blocks would be unrealistic, but these nine turned out to be quite fast.
The graph below shows the dependence of the percentage of correct answers on the number of processed blocks. Note that the horizontal scale is logarithmic.
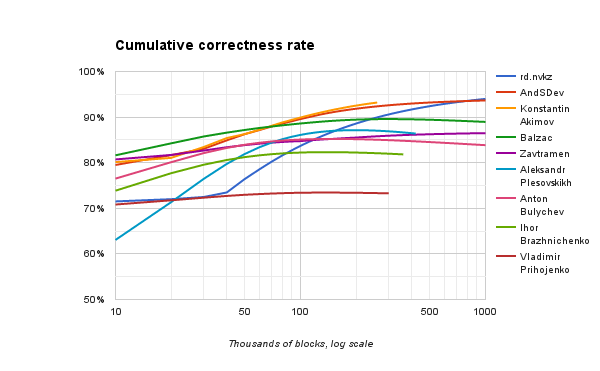
Some solutions did not have enough memory when testing on a very large number of blocks, so their lines were interrupted before reaching a million blocks.
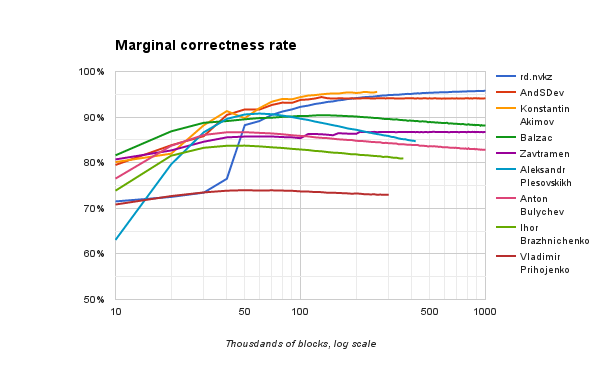
The following graph shows not the cumulative percentage of correct answers (average over the entire period of operation), but only for the last 10,000 blocks at each point. Here you can better see how the solution behaves after a certain amount of training.
Below are graphs of the frequency of false-negative and false-positive results, respectively. Here, too, the behavior in the last 10,000 blocks is taken into account, and not cumulative from the beginning of work.

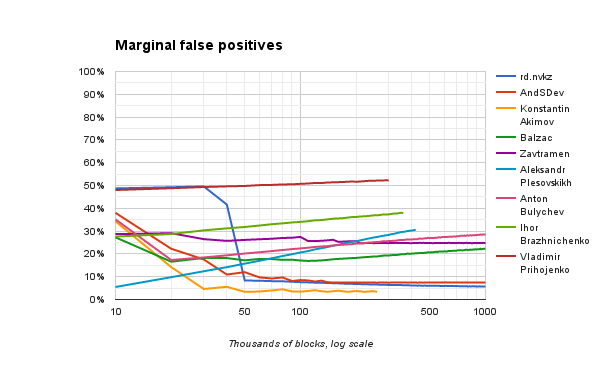
Please note that the results of some decisions with long training begin to deteriorate somewhat. Obviously, this is due to the fact that some non-words are also randomly repeated, and the algorithm takes them for words. The last graph shows that it is false positive results that grow.
On the special page on GitHub you can find detailed research results for 1,000,000 blocks.
Based on the study, we decided to award special prizes of 400 USD for participants under the pseudonyms rd.nvkz and AndSDev . Their solutions achieved the highest rates - 93.99% and 93.65% respectively. In addition, their behavior does not deteriorate with prolonged training, and the first of them even continues to improve. Our congratulations!
Follow the Hola blog! There will be new contests.
The English version of this post is on GitHub .
So, 9 of the submitted solutions turned out to be self-learning. The idea of self-study is this: since all words are selected from a finite vocabulary, and non-words are generated randomly, then any line that was presented to the program being tested again is more likely to be a word than a non-word. With sufficiently long testing, most of the words from the dictionary will have time to repeat, whereas for non-words, random repetitions are much less common.
')
To observe the behavior of self-learning solutions, we tested them for 1,000,000 blocks . To test all the solutions on such a number of blocks would be unrealistic, but these nine turned out to be quite fast.
The graph below shows the dependence of the percentage of correct answers on the number of processed blocks. Note that the horizontal scale is logarithmic.
Some solutions did not have enough memory when testing on a very large number of blocks, so their lines were interrupted before reaching a million blocks.
The following graph shows not the cumulative percentage of correct answers (average over the entire period of operation), but only for the last 10,000 blocks at each point. Here you can better see how the solution behaves after a certain amount of training.
Below are graphs of the frequency of false-negative and false-positive results, respectively. Here, too, the behavior in the last 10,000 blocks is taken into account, and not cumulative from the beginning of work.
Please note that the results of some decisions with long training begin to deteriorate somewhat. Obviously, this is due to the fact that some non-words are also randomly repeated, and the algorithm takes them for words. The last graph shows that it is false positive results that grow.
On the special page on GitHub you can find detailed research results for 1,000,000 blocks.
Based on the study, we decided to award special prizes of 400 USD for participants under the pseudonyms rd.nvkz and AndSDev . Their solutions achieved the highest rates - 93.99% and 93.65% respectively. In addition, their behavior does not deteriorate with prolonged training, and the first of them even continues to improve. Our congratulations!
Follow the Hola blog! There will be new contests.
Source: https://habr.com/ru/post/313176/
All Articles