How we tried DDD, CQRS and Event Sourcing and what conclusions did
For about three years now I have been using the principles of Spec By Example , Domain Driven Design and CQRS . During this time, the experience of practical application of these practices on the .NET platform has been gained. In the article I want to share our experience and conclusions that can be useful to teams wishing to use these approaches in the design.
All development managers using DDD, with whom I discussed the topic, noted the “high cost” of this methodology, primarily due to the lack of answers to practical questions “how do I do FooBar without violating DDD principles in the Evans book?”.
The most common question in the Google CQRS group is Greg Young: “The boss asks me to build an annual report. When I raise all the roots of the aggregation in memory, everything starts to slow down. What should I do?". There is an obvious answer to this question: “you need to write a SQL query”. However, writing a manual SQL query is definitely against the DDD rules.
Evans himself agreed with Young that the book should have been written in a different order. The key concepts are the Bounded Context and Ubiquitous Language , not Entity and ValueObject .
')
Reports do not need a domain model. A report is simply a table with data. Data Driven - much better suited for reporting than Domain Driven. At first glance, at this moment DDD sucks should be said. However, it is not. Simply using DDD to build reports is not the correct Bounded Context.
The most important thesis of DDD is not to try to develop one large domain model for the entire application. It is too complicated and no one needs. It is possible to create one domain model for the entire application only if it is decided at the company management level that all departments use the same terminology and understand all business processes in the same way.
We made sure that it is very difficult to reach an agreement with all members of the team on terminology. The term Entity became a stumbling block: we tried to use the IEntity <TKey> interface, but we quickly realized that Id could also use ValueObjects to send commands. Using IEntity <TKey> for such objects confused people, and we abandoned IEntity in favor of IHasId .
There are quite a few NHibernate vs Entity Framework for DDD discussions on Stack Overflow. NHibernate, on the whole, does better, but there are still a lot of problems. The standard approach for using ORM is to use parameterless constructors and set values through property setters. This is a break encapsulation. There are certain problems with collections and Lazy Load. In addition, the team must decide where the “domain” ends and the “infrastructure” begins and how to ensure Persistence Ignorance.
Evans is a man from the world of Java. In addition, the book was written a long time ago.
This interface allows you to work with collections in memory, but not suitable for building SQL queries. In modern C #, this option is more suitable:
Domain modeling is not an easy task. DDD involves delegating some of the tasks for analytics to developers. This is justified in cases where the cost of the error is high. It doesn’t matter how quickly you write the code and how fast your system works, if it doesn’t work correctly and you lose money. Actually, the opposite is true - if you develop software for HFT and do not fully understand how it should work, it is better that your software slows down or does not work at all. So you will at least not lose money on super-fast, but not correct trading :)
In unsustainable businesses (especially startups) there is often no understanding of the subject model. Everything can change daily. Under these conditions, it is useless to require business process participants to use common terminology.
The conclusion is obvious: DDD is not a “silver bullet”, but it's a pity :) However, you can get a significant gain due to the “point application” of DDD in certain Bounded Context .
In 1980, Bertrand Meyer coined the very simple term CQS. At the beginning of the two thousandth, Greg Young expanded and popularized this concept. So CQRS appeared ... and CQRS in many respects repeated the fate of the DDD, in the sense that it was repeatedly not correctly interpreted.
Despite the fact that there are plenty of materials on the CQRS on the Internet, everyone “prepares” it differently. Many teams use the principles of CQRS, although they do not call it that. The system may not have Command and Query abstractions. They can be replaced by IOperation or even Func <T1, T2> and Action <T> .
This is a simple explanation. The first results for the CQRS query produce something like the image below:
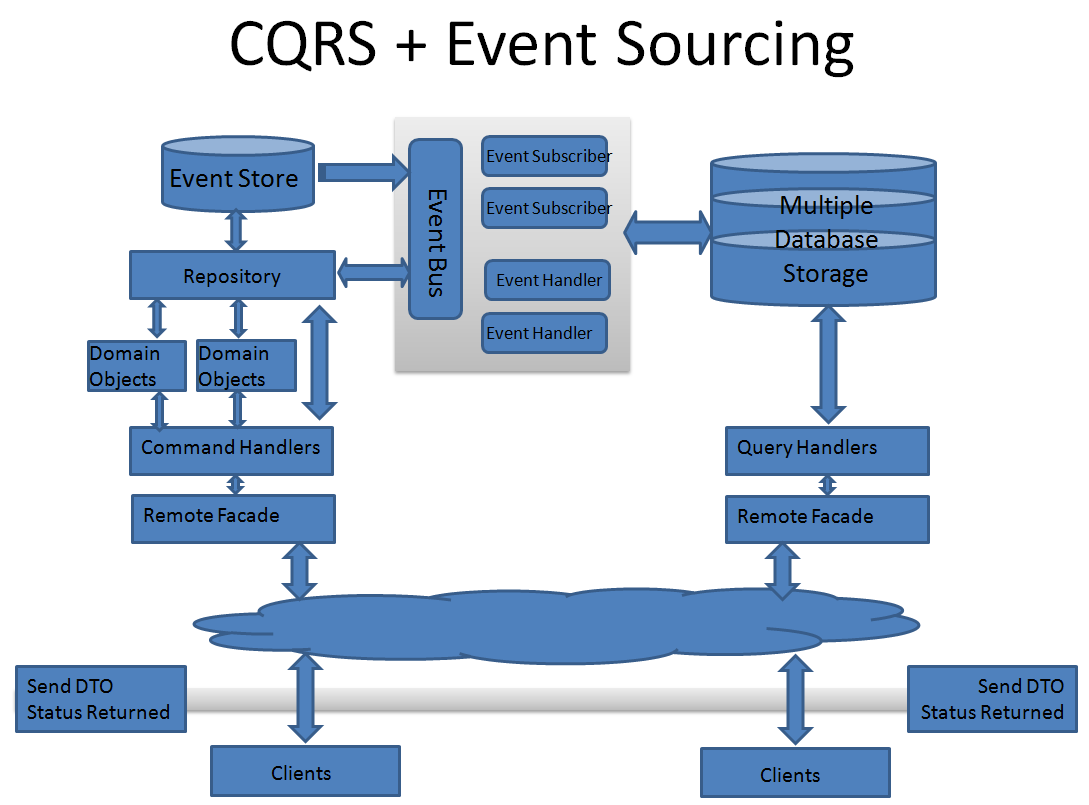
This implementation Dino Esposito calls DELUXE . The point here is that GQ Young is interested in CQRS mainly in the context of Event Sourcing . In fact, you must use CQRS for Event Sourcing, but not vice versa.
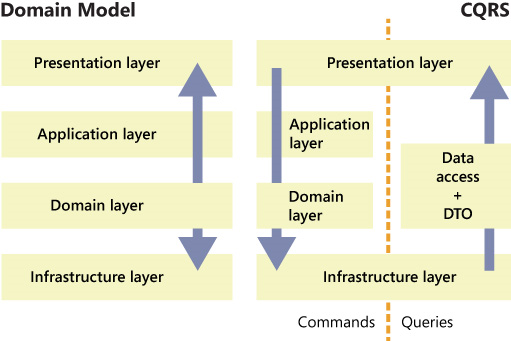
Thus, using CQRS, we can solve the problem of brake reports by dividing application stacks by Read and Write and without using the Domain Model in the Read stack. A read stack can use another database and / or another more optimal data access API.
Splitting the application into commands, handlers, and requests has another advantage: better predictability. In the case of DDD, in order to know where to look for this or that business logic, you need to understand the subject area. In the case of CQRS, the programmer always knows that the recording takes place in command handlers, and Query is used to access the data. In addition, there are still some not obvious, at first glance, advantages. We will look at them below.
The main interfaces in CQRS might look like this :
We have agreed that:
In this case, in the absence of commands, all Query always return the same results on the same input data . Such an organization greatly simplifies debugging, because Query does not have a state that could change the return result.
If necessary, Audit Log or full-fledged Event Sourcing can be connected to all command handlers via the base class.
CQRS principles are very well suited for HTTP protocol implementation. The HTTP specification clearly says GET requests should return data from the server. POST, PUT, PATCH - change the state. A good practice in web programming is to redirect to GET after performing a POST operation, for example, submitting a form.
Reports are not the only frequent data reading task. A more general definition of typical read operations is:
We actively use AutoMapper to build projections. One of the distinguishing features of this mapper are Queryable-Extensions : the ability to build an Expression for conversion to SQL, instead of mapping in RAM. These projections are not always accurate and productive, but they are ideal for rapid prototyping.
For paginal output from any table in the database and filtering support, you can use just one implementation of IQuery .
The ApplyIfPossible method will check whether filtering is performed at the level of the aggregate or projection (sometimes it is necessary both ways ). The Project method will create a projection using AutoMapper.
AutoFilter and Dynamic Linq can help if you work with a large number of uniform forms.
To build aggregates from create / edit commands, you can use a generic TypeConverter .
In order to simplify the registration in the container, you can use the agreement .
We actively use CQRS without Event Sourcing at work and so far the impressions are very good.
DDD. findings
- Very expensive
- Works well in established business processes.
- Sometimes it's the only way to do the right thing.
- Badly scaled
- Difficult to implement in high load applications
- It works poorly in startups
- Not suitable for building reports
- Requires special attention with ORM
- Entity words are best avoided because everyone understands it in their own way.
- With LINQ, the standard implementation of the Specification "does not work"
Very expensive
All development managers using DDD, with whom I discussed the topic, noted the “high cost” of this methodology, primarily due to the lack of answers to practical questions “how do I do FooBar without violating DDD principles in the Evans book?”.
The most common question in the Google CQRS group is Greg Young: “The boss asks me to build an annual report. When I raise all the roots of the aggregation in memory, everything starts to slow down. What should I do?". There is an obvious answer to this question: “you need to write a SQL query”. However, writing a manual SQL query is definitely against the DDD rules.
Evans himself agreed with Young that the book should have been written in a different order. The key concepts are the Bounded Context and Ubiquitous Language , not Entity and ValueObject .
')
Reports do not need a domain model. A report is simply a table with data. Data Driven - much better suited for reporting than Domain Driven. At first glance, at this moment DDD sucks should be said. However, it is not. Simply using DDD to build reports is not the correct Bounded Context.
Bounded context
The most important thesis of DDD is not to try to develop one large domain model for the entire application. It is too complicated and no one needs. It is possible to create one domain model for the entire application only if it is decided at the company management level that all departments use the same terminology and understand all business processes in the same way.
Entity everyone understands their own way
We made sure that it is very difficult to reach an agreement with all members of the team on terminology. The term Entity became a stumbling block: we tried to use the IEntity <TKey> interface, but we quickly realized that Id could also use ValueObjects to send commands. Using IEntity <TKey> for such objects confused people, and we abandoned IEntity in favor of IHasId .
DDD requires special attention with ORM
There are quite a few NHibernate vs Entity Framework for DDD discussions on Stack Overflow. NHibernate, on the whole, does better, but there are still a lot of problems. The standard approach for using ORM is to use parameterless constructors and set values through property setters. This is a break encapsulation. There are certain problems with collections and Lazy Load. In addition, the team must decide where the “domain” ends and the “infrastructure” begins and how to ensure Persistence Ignorance.
With LINQ, the standard implementation of the Specification "does not work"
Evans is a man from the world of Java. In addition, the book was written a long time ago.
public abstract class Specification<T> { public abstract bool IsSatisfiedBy(T entity) }; This interface allows you to work with collections in memory, but not suitable for building SQL queries. In modern C #, this option is more suitable:
public abstract class Specification<T> { public bool IsSatisfiedBy(T item) { return SatisfyingElementsFrom(new[] { item }.AsQueryable()).Any(); } public abstract IQueryable<T> SatisfyingElementsFrom(IQueryable<T> candidates); } Application area
Domain modeling is not an easy task. DDD involves delegating some of the tasks for analytics to developers. This is justified in cases where the cost of the error is high. It doesn’t matter how quickly you write the code and how fast your system works, if it doesn’t work correctly and you lose money. Actually, the opposite is true - if you develop software for HFT and do not fully understand how it should work, it is better that your software slows down or does not work at all. So you will at least not lose money on super-fast, but not correct trading :)
In unsustainable businesses (especially startups) there is often no understanding of the subject model. Everything can change daily. Under these conditions, it is useless to require business process participants to use common terminology.
CQRS
The conclusion is obvious: DDD is not a “silver bullet”, but it's a pity :) However, you can get a significant gain due to the “point application” of DDD in certain Bounded Context .
In 1980, Bertrand Meyer coined the very simple term CQS. At the beginning of the two thousandth, Greg Young expanded and popularized this concept. So CQRS appeared ... and CQRS in many respects repeated the fate of the DDD, in the sense that it was repeatedly not correctly interpreted.
Despite the fact that there are plenty of materials on the CQRS on the Internet, everyone “prepares” it differently. Many teams use the principles of CQRS, although they do not call it that. The system may not have Command and Query abstractions. They can be replaced by IOperation or even Func <T1, T2> and Action <T> .
This is a simple explanation. The first results for the CQRS query produce something like the image below:
This implementation Dino Esposito calls DELUXE . The point here is that GQ Young is interested in CQRS mainly in the context of Event Sourcing . In fact, you must use CQRS for Event Sourcing, but not vice versa.
Thus, using CQRS, we can solve the problem of brake reports by dividing application stacks by Read and Write and without using the Domain Model in the Read stack. A read stack can use another database and / or another more optimal data access API.
Splitting the application into commands, handlers, and requests has another advantage: better predictability. In the case of DDD, in order to know where to look for this or that business logic, you need to understand the subject area. In the case of CQRS, the programmer always knows that the recording takes place in command handlers, and Query is used to access the data. In addition, there are still some not obvious, at first glance, advantages. We will look at them below.
CQRS main findings
- Event Sourcing requires CQRS, but not vice versa.
- Cheap
- Fits everywhere
- Scaled
- Does not require 2 data stores. This is one of the possible implementations, but not an obligation.
- The command handler may return a value. If you do not agree, argue with Greg Young and Dino Esposito, but not with me
- If the handler returns a value, it is worse scaled, but there is async / await, but you need to understand how they work
The main interfaces in CQRS might look like this :
[PublicAPI] public interface IQuery<out TOutput> { TOutput Ask(); } [PublicAPI] public interface IQuery<in TSpecification, out TOutput> { TOutput Ask([NotNull] TSpecification spec); } [PublicAPI] public interface IAsyncQuery<TOutput> : IQuery<Task<TOutput>> { } [PublicAPI] public interface IAsyncQuery<in TSpecification, TOutput> : IQuery<TSpecification, Task<TOutput>> { } [PublicAPI] public interface ICommandHandler<in TInput> { void Handle(TInput input); } [PublicAPI] public interface ICommandHandler<in TInput, out TOutput> { TOutput Handle(TInput input); } [PublicAPI] public interface IAsyncCommandHandler<in TInput> : ICommandHandler<TInput, Task> { } [PublicAPI] public interface IAsyncCommandHandler<in TInput, TOutput> : ICommandHandler<TInput, Task<TOutput>> { } We have agreed that:
- Query always only receives data, but does not change the state of the system. To change the system, use the commands
- Query can return the necessary projections to the line, bypassing the domain model
In this case, in the absence of commands, all Query always return the same results on the same input data . Such an organization greatly simplifies debugging, because Query does not have a state that could change the return result.
If necessary, Audit Log or full-fledged Event Sourcing can be connected to all command handlers via the base class.
It's not hard to see that the main CQRS interfaces can be brought to Func <T1, T2> and Action <T> . Add stateless and immutable, and you will get pure functions (hello functional programming;) Strictly speaking, this is certainly not the case, because most of the Query will work with the file system, database or network. You also probably want to cache the results of the Query, but you can get the benefit from the linearization of data-flow and composability.
CQRS over HTTP
CQRS principles are very well suited for HTTP protocol implementation. The HTTP specification clearly says GET requests should return data from the server. POST, PUT, PATCH - change the state. A good practice in web programming is to redirect to GET after performing a POST operation, for example, submitting a form.
so
- GET is Query
- POST / PUT / PATCH / DELETE - this is Command
Base Classes for Commonly Used Operations
Reports are not the only frequent data reading task. A more general definition of typical read operations is:
- Filtration
- Pagination (paginated)
- Creation of projections (representation of aggregates in the form required on the client side)
We actively use AutoMapper to build projections. One of the distinguishing features of this mapper are Queryable-Extensions : the ability to build an Expression for conversion to SQL, instead of mapping in RAM. These projections are not always accurate and productive, but they are ideal for rapid prototyping.
For paginal output from any table in the database and filtering support, you can use just one implementation of IQuery .
public class ProjectionQuery<TSpecification, TSource, TDest> : IQuery<TSpecification, IEnumerable<TDest>> , IQuery<TSpecification, int> where TSource : class, IHasId where TDest : class { protected readonly ILinqProvider LinqProvider; protected readonly IProjector Projector; public ProjectionQuery([NotNull] ILinqProvider linqProvier, [NotNull] IProjector projector) { if (linqProvier == null) throw new ArgumentNullException(nameof(linqProvier)); if (projector == null) throw new ArgumentNullException(nameof(projector)); LinqProvider = linqProvier; Projector = projector; } protected virtual IQueryable<TDest> GetQueryable(TSpecification spec) => LinqProvider .GetQueryable<TSource>() .ApplyIfPossible(spec) .Project<TSource, TDest>(Projector) .ApplyIfPossible(spec); public virtual IEnumerable<TDest> Ask(TSpecification specification) => GetQueryable(specification).ToArray(); int IQuery<TSpecification, int>.Ask(TSpecification specification) => GetQueryable(specification).Count(); } public class PagedQuery<TSortKey, TSpec, TEntity, TDto> : ProjectionQuery<TSpec, TEntity, TDto>, IQuery<TSpec, IPagedEnumerable<TDto>> where TEntity : class, IHasId where TDto : class, IHasId where TSpec : IPaging<TDto, TSortKey> { public PagedQuery(ILinqProvider linqProvier, IProjector projector) : base(linqProvier, projector) { } public override IEnumerable<TDto> Ask(TSpec spec) => GetQueryable(spec).Paginate(spec).ToArray(); IPagedEnumerable<TDto> IQuery<TSpec, IPagedEnumerable<TDto>>.Ask(TSpec spec) => GetQueryable(spec).ToPagedEnumerable(spec); public IQuery<TSpec, IPagedEnumerable<TDto>> AsPaged() => this as IQuery<TSpec, IPagedEnumerable<TDto>>; } The ApplyIfPossible method will check whether filtering is performed at the level of the aggregate or projection (sometimes it is necessary both ways ). The Project method will create a projection using AutoMapper.
AutoFilter and Dynamic Linq can help if you work with a large number of uniform forms.
public static class AutoFilterExtensions { public static IQueryable<T> ApplyDictionary<T>(this IQueryable<T> query , IDictionary<string, object> filters) { foreach (var kv in filters) { query = query.Where(kv.Value is string ? $"{kv.Key}.StartsWith(@0)" : $"{kv.Key}=@0", kv.Value); } return query; } public static IDictionary<string, object> GetFilters(this object o) => o.GetType() .GetTypeInfo() .GetProperties(BindingFlags.Public) .Where(x => x.CanRead) .ToDictionary(k => k.Name, v => v.GetValue(o)); } public class AutoFilter<T> : ILinqSpecification<T> where T: class { public IDictionary<string, object> Filter { get; } public AutoFilter() { Filter = new Dictionary<string, object>(); } public AutoFilter([NotNull] IDictionary<string, object> filter) { if (filter == null) throw new ArgumentNullException(nameof(filter)); Filter = filter; } public IQueryable<T> Apply(IQueryable<T> query) => query.ApplyDictionary(Filter); } To build aggregates from create / edit commands, you can use a generic TypeConverter .
In order to simplify the registration in the container, you can use the agreement .
Conclusion
We actively use CQRS without Event Sourcing at work and so far the impressions are very good.
- It's easier to test the code, because the classes are small and guaranteed to answer for only one thing.
- For the same reason, making changes to the system is simplified.
- Simplified communication, the debate about where a particular code should be. The code of different team members has become uniform.
- DDD is used for initial system modeling and aggregation. Aggregates may not be instantiated at all if all methods above the corresponding table are rigidly optimized (implemented to bypass the ORM)
- Event sourcing in full banana - implementation has never been required, Audit Log is implemented quite often.
Source: https://habr.com/ru/post/313110/
All Articles