Java Continuations
It is intensely difficult to distinguish ...
Grady booch
Let's go back a few decades ago and take a look at how the sample programs of those years looked like. Then dominated the imperative approach. Let me remind you that the name it received due to the total control of the program over the calculation process: the program clearly states what should be done and when. Like a set of orders of the Emperor. Most operating systems offered this approach for writing executable programs. It is widely used to this day, for example, when writing various kinds of utilities. Moreover, with this approach begins the study of programming in school. What is the reason for its popularity? The fact is that the imperative style is very simple and understandable to man. To master it is not difficult.
Take a look at an example. I chose Pascal to make the code archaic. The program prompts you to enter a value for the variable “x”, reads the entered value from the console, then the same for the variable “y”, at the end displays the sum of “x” and “y”. All actions are initiated by the program - both input and output. In strict sequence.
var x, y: integer; begin write('x = '); readln(x); write('y = '); readln(y); writeln('x + y = ', x + y); end. Now let's rewrite the code a bit and introduce a number of abstractions (yes, the term “abstraction” is not proprietary to the PLO) in order to emphasize the main actions of the program.
')
var x, y: integer; begin x := receiveArg; y := receiveArg; sendResult('x + y = ', x + y); end. In fact, entering abstractions where it would seem possible to do without them is another tool for dealing with complexity; this is all the same encapsulation, even if there are no classes or visibility modifiers. Later we will remember about this code. In the meantime, move on.
The evolution of operating systems led to the appearance of graphical shells, and the imperative style ceased to be dominant. Graphic OSs offer a completely different approach to program structure, the so-called. event-driven approach. The essence of the approach is that the program is idle most of the time, does nothing and reacts only to “stimuli” from the operating system. The point is that the graphical user interface gives the user simultaneous access to all window controls and we cannot poll them sequentially, as happens in imperative programs. On the contrary, the program should promptly respond to any user actions with any part of the window, if this is provided by logic or it is expected by the user. The event-driven approach is not the choice of application developers, it is the choice of OS developers, because This model allows more efficient use of machine resources. In addition, the OS assumes the maintenance of the graphical shell and in this sense is a “fat” intermediary between the client and the application programs. In fact, technically applied programs remain imperative, since they have an imperative "nucleus", the so-called. message loop or event loop. But in most cases this nucleolus is typical and hidden in the depths of the graphic libraries used by programmers.
Is the event-driven approach an evolutionary development of software development? Rather, it is a necessity. It just turned out to be easier and more economical. This approach has known drawbacks. First of all, it is less natural than the imperative approach, and leads to additional overhead, but more on that later. I started talking about this approach, which is why: the fact is that this approach has spread far beyond the limits of application software. This is the external interface of most servers. Roughly speaking, a typical server declares a list of commands that it can execute. Like an application graphics program, the server is idle until an event command arrives from outside, which it can process. Why did the event-drive approach migrate to the server architecture? After all, there are no restrictions on the part of the graphical OS shell. I think that there are several reasons: first of all, the features of the used network protocols (as a rule, the connection is initiated by the client) and the same need to save machine resources, the consumption of which is easy to regulate in the event-driven approach.
Response onRequest(Request request) { switch (request.type) { case "sum": int x = request.get("x"); int y = request.get("y"); return new Response(x + y); ... And here I would like to draw attention to one of the major drawbacks of the event-driven approach - this is a large overhead and the absence of explicit abstractions in the code that reflect the logic of the server's behavior. First of all, I mean the relationship between the various commands that the server declares: not all of them are independent, some must be performed in a certain sequence. But since When using event-driven, it is not always possible to reflect the relationship between different operations, there are overhead costs in the form of restoring the context to perform each operation, and in the form of additional checks that are needed to make sure that this operation can be performed. In other words, in case the protocol implemented by the server is complicated, the saving of resources from using the event-driven approach becomes not so obvious. But despite this, there are other good reasons for its use: language tools, standards, and used libraries do not leave the developer a choice. However, then I want to talk about the important changes that have occurred in recent years, and about the fact that this approach fits well with the new reality.
Here I must note that the imperative style is also used when writing server-side code: it is quite suitable for p2p connections, or in “real-time” programs, for example, in games where the amount of resources used is limited, and the speed of response from the server is very important.
for (;;) { Request request = receive(); switch (request.type) { case "sum": int x = receiveInt(); int y = receiveInt(); send(new Response(x + y)); break; ... Remember the Pascal code to which I added the receiveArg and sendResult operations. Agree that it is very similar to what we see in this example: we consistently request arguments and send the result. The only difference is that here the role of the console is played by the network connection with the client. Imperative style allows you to get rid of overhead in the processing of related operations. However, without the use of special mechanisms, which will be discussed later, it more aggressively exploits the resources of the machine, and is unsuitable for the implementation of servers serving more connections. Judge for yourself: if in the event-driven approach, the flow is allocated to a separate operation, then the flow is allocated at least to the session, the lifetime of which is significantly longer. Spoiler: aggressive use of resources in the imperative approach is a removable drawback.
Now let's take a look at the “typical” server implementation - the code below is not associated with any framework and reflects only the query processing scheme. As a basis, I took the procedure of registering a new user with confirmation via SMS-code. Let this procedure consist of two related operations: register and confirm.
Response onReceived(Request request) { switch (request.type) { case "register": User user = registerUser(request); user.confCode = generateConfirmationCode(); sendSms("Confirmation code " + user.confCode); return Response.ok; case "confirm": String code = request.get("code"); User user = lookupUser(request); if (user == null || !Objects.equals(code, user.confCode)) { return Response.fail; } return user.confirm() ? Response.ok : Response.fail; ... Let's run through the code. Operation register. Here we create a new client using data from the request. But let's think about what the client creation process involves: it is, potentially, a series of calls to one or several external systems (code generation, sending SMS), disk operations. For example, the operation sendSms, will return control to us only after the SMS message with the code is successfully sent to the user. Calls to external systems (the delivery time of the request, the time it was processed, the time the result was transferred back) and disk operations take time and will lead to downtime of the current stream. Note: we bind the generated code to the client (the confCode field). The fact is that after processing this request, we will leave the handler, and all local variables will be reset. We also need to save the code for later comparison when the confirm request is received. When processing it, we first restore the execution context. These are the overheads that I mentioned.
Synchronous processing of requests, as in our example, is associated with an abundance of blocking operations, resulting in downtime of a valuable system resource. And everything would be fine, but increasing requirements for throughput and response time are imposed on service systems. Downtime system resources become an unaffordable luxury. Let's take a look at the chart.
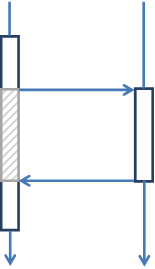
Here I made a blocking call. The shaded area is a simple calling thread. Is it significant? Remember the size and number of timeouts used in your system. They eloquently tell you about the amount of possible downtime. This is not about milliseconds, but about tens of seconds, and sometimes minutes. With a load of 1000 TpS, an idle time of 1 second is 1000 operations for the processing of which an additional resource was allocated.
What solutions does the industry offer us to increase throughput and decrease response time? Iron developers, for example, offer multi-core. Yes, it expands the capabilities of a single machine. Event-driven approach, thanks to scalability, easily utilizes a new resource. But the synchronous implementation of query handlers makes the use of threads inefficient. And here asynchronous calls come to the rescue.

The task of an asynchronous call is to initiate the operation and return control as soon as possible. The result of the operation we get through the callback function, which is passed as an additional parameter. Thus, immediately after such a call, we can continue to work, or complete it until the result is received. Let's modify our example and rewrite it in asynchronous style.
void onReceived(Request request) { switch (request.type) { case "register": registerUser(request, user -> { generateConfirmationCode(code -> { user.confCode = code; sendSms("Confirmation code " + code, () -> { reply(Response.ok); }); }); }); break; ... Here I gave only one operation register. But this is enough to see the main drawback of the asynchronous style: the worst readability of the code, the increase in its size. Appearances of callbacks, instead of a series of synchronous calls. This example looks bearable only thanks to lambda. Without them, it would be more difficult to perceive asynchronous code. In other words, the Java language is not well adapted to the new requirements. It does not have the necessary tools that make working with asynchronous code more comfortable.
How to be? Is there a way to keep the comfort of working with synchronous code, and at the same time get rid of its key flaws, using asynchronous mechanisms?
Yes, there is such a way.
Continuations
Continuations are another mechanism for controlling the progress of a program (in addition to cycles, conditional branches, method calls, etc.), which allows you to suspend the execution of a method at a certain point for an indefinite period, releasing the current flow.
Here are the main artifacts of this tool.
- Suspendable method - a method whose execution can be suspended indefinitely and then resumed
- Coroutine / Fiber retain stack when execution is suspended. The stack can be transferred over the network to another machine in order to resume execution of the suspended method there.
- CoIterator allows you to create a type of iterator called generator (implemented in the Mana library)
This is not a complete list. Artifacts such as Channel , Reactive dataflow and Actor are also very curious, but these are topics for individual articles. Here I will not consider them.
Currently, the continuations are supported by a number of web-frameworks. Common solutions that allow using continuations in Java, unfortunately, can be counted on fingers. Until recently, they were all for the most part artisanal (experiment) or very obsolete.
- Jau VM - add-on over JVM, "experimental" project (2005)
- JavaFlow - an attempt to create a capital library, not supported since 2008
- jyield - a small "experimental" project (February 2010)
- coroutines - another “pilot” project (October 2010)
- jcont - relatively fresh attempt (2013)
- Continuations library Matisa Mana - the simplest and most successful, in my opinion, solution for Java
The concept implemented by Mann is simple and easy to learn. Unfortunately, it is not currently supported. In addition, the original article describing the library has literally become unavailable recently.
But it is not all that bad. Gentlemen from Parallel Universe , having taken Man’s library as a basis, reworked it, making its own more weighty version - Quasar .
Quasar inherited the main ideas from the Man library, developed them, and added some infrastructure to it. In addition, at the moment it is the only such solution that works with
What gives us this tool? First of all, we get the opportunity to write asynchronous code, without losing the visibility of synchronous. Moreover, now we can write server code in imperative style.
for (;;) { Request request = receive(); switch (request.type) { case "register": User user = registerUser(request); int confCode = generateConfirmationCode(); sendSms("Confirmation code " + confCode); reply(Response.confirm); String code = receiveConfirmationCode(); if (Objects.equals(code, confCode) && user.confirm()) { reply(Response.ok); } else { reply(Response.fail); } break; ... This is an example of the same user registration. Please note that there is only one option left for the register / confirm pair request: register. confirm disappeared, because here we no longer need it. In this implementation, the minimum overhead: the entire context of the operation is stored in local variables, we do not need to remember the generated code, look around the user again. After registering it, generating code and sending SMS, we just expect to receive this code from the client and nothing more. Not a new request with a bunch of extra attributes, but just one code!
How does this work? I propose to start with the library Mana. The library contains only a few classes, the main of which is Coroutine.
Coroutine co = new Coroutine(new CoroutineProto() { @Override public void coExecute() throws SuspendExecution { ... Coroutine.yield(); // suspend execution ... } }); ... co.run(); // run execution ... co.run(); // resume execution Coroutine is, in essence, a shell for Runnable. More precisely, not for the standard Runnndable, but for the special version of this interface - CoroutineProto. The task of the coroutine is to preserve the state of the stack at the moments when the execution of the embedded task is suspended. The Korutins themselves do nothing: the execution of the nested when initiated by the run method, which starts or resumes, after stopping, the execution of the code in the coExecute method. Control from the run method returns after the coExecute method finishes its work, or suspends it by calling the static method Coroutine.yield. You can find out about the state of the coExecute method in a call to Couroutine.getState. The three methods, run, yield, and getState, in fact, describe the entire meaningful interface of the Coroutine class. Everything is very simple. Notice the SuspendExecution exception. First of all, it is a marker indicating that the method may pause. A special feature of the Mana library is that this exception is actually thrown at the moment of suspension (the only “empty” - without a stack is an instance). This exception cannot be "strangled". This is one of the disadvantages of the library.
One of the uses of Corutin Man was to create a special kind of iterator: generators. Apparently, Mana (like his predecessors) was oppressed by the fact that there are support for generators in many languages, including in C # (yield return, yield break). In his library, he included a special class CoIterator, which implements the Iterator interface. To create a generator, you need to examine the CoIterator and implement the abstract suspended run method. In the CoIterator constructor, a korutin is generated, which feeds the abstract run method.
class TestIterator extends CoIterator<String> { @Override public void run() throws SuspendExecution { produce("A"); produce("B"); for(int i = 0; i < 4; i++) { produce("C" + i); } produce("D"); produce("E"); } } After Man’s idea of his library becomes clear, mastering Quasar is easy. Quasar uses a slightly different terminology. For example, the Fiber used in Quasar in the role of Korutin is, in fact, a lightweight version of the stream (the term is probably borrowed from the Win API, where the filers have been present for quite some time). Using it is as easy as using korutiny.
Fiber fiber = new Fiber (new SuspendableRunnable() { public void run() throws SuspendExecution, InterruptedException { ... Fiber.park(); // suspend execution ... } }).start(); // start execution ... fiber.unpark(); // resume execution Here we see SuspendExecution already familiar to us. However, in Quasar, he honestly plays the role of a marker, and is not required. Instead, you can use the @Suspendable annotation.
class C implements I { @Suspendable public int f() { try { return g() * 2; } catch(SuspendExecution s) { assert false; } } } Thus, we get the ability to create suspendable implementations of virtually any interfaces, which the Man library did not allow us to do, requiring the presence of a marker exception.
The Quasar library has everything you need to "turn" asynchronous interfaces into pseudo-synchronous, providing the client code with the visibility of synchronous and efficient asynchronous. In addition, instances of Fiber are serializable, i.e. and they can be partially performed on different machines: start on one node, pause, transfer over the network to another node, and resume execution there.
To understand the power of the faibers, let's imagine the following situation. Suppose we have a classic server with synchronous processing of requests. Let us, when processing requests from users, our server from time to time access external resources. To DB, for example. Suppose we have allocated 1000 threads for the server to work. And so, at some point, our external resource began to “blunt”. In this case, the handlers of new requisitions will begin to freeze when accessing this resource, blocking their flows. With a high load on the server, the thread pool will be quickly used up, and rejects will begin. If the thread pool is shared, even those requests that are not related to the external resource will be rejected. In this case, the server can do nothing at all. A bottleneck in our entire system was an external resource that could not cope with the load and failed.
What will help us faybery? Fiber turns our synchronous handler into asynchronous. Now, when accessing an external resource, we can calmly return the thread to the pool, and request only a little memory from the machine to save the current execution stack. When a response comes from an external resource, we will take a free stream in the pool, restore the stack and continue processing the request. Beauty!
But here it is necessary to make a reservation: it will all work only if the interface to an external resource is asynchronous.Unfortunately, a lot of libraries provide only a synchronous interface. A typical JDBC example. But it should be noted that Java is moving in the direction of asynchrony. Old interfaces are rewritten (NIO, AIO, CompletableFuture, Servlet 3.0), new ones are often asynchronous initially (Netty, ZooKeeper).
Of course, I would very much like to see progress in this direction on the part of Oracle. The work is underway , but very slowly, and in the next version of Java, full-time support for the continuations should not be expected. Hopefully, the Quasar library will not remain unique, and we will see many more interesting solutions that make writing asynchronous code simple and convenient.
Source: https://habr.com/ru/post/313070/
All Articles