Overview of options for implementing failover clusters: Stratus, VMware, VMmanager Cloud

There are varieties of business where service outages are unacceptable. For example, if the billing system of a mobile operator stops due to a server failure, subscribers will be left without communication. From the awareness of the possible consequences of this event there is a reasonable desire to insure.
We will tell you what are the ways to protect against server failures and what architectures are used when implementing VMmanager Cloud: a product that is designed to create a high availability cluster .
Foreword
In the field of protection against failures on clusters, terminology on the Internet varies from site to site. In order to avoid confusion, we will designate the terms and definitions that will be used in this article.
')
- Fault tolerance (Fault Tolerance, FT) - the ability of the system to continue to work after the failure of any of its elements.
- A cluster is a group of servers (computing units) connected by communication channels.
- Failover Cluster (Fault Tolerant Cluster, FTC) - a cluster in which a server failure does not lead to the complete failure of the entire cluster. Tasks of a failed machine are distributed between one or more of the remaining nodes in automatic mode.
- Continuous Availability (CA) - the user can use the service at any time, there is no interruption in the provision. How much time has passed since the failure of the node does not matter.
- High availability (High Availability, HA) - if the node fails, the user will not receive the service for a while, but the system will be restored automatically; downtime is minimized.
- KND - cluster of continuous availability, CA cluster.
- KVD - high availability cluster, HA-cluster.
Suppose you want to deploy a cluster of 10 nodes, where virtual machines are started on each node. The goal is to protect virtual machines from hardware failures. To increase the computational density racks decided to use dual-processor servers.
At first glance, the most attractive option for a business is that in the event of a failure the service of users is not interrupted, that is, a cluster of continuous availability. KND cannot be done at least in the tasks of the already mentioned subscriber billing and in the automation of continuous production processes. However, along with the positive features of this approach, there are also “pitfalls”. About them the next section of the article.
Continuous availability
Uninterrupted customer service is possible only if there is at any time an exact copy of the server (physical or virtual) on which the service is running. If you create a copy after the failure of the equipment, it will take time, which means that the service will be interrupted. In addition, after a breakdown, it will be impossible to obtain the contents of the RAM from the problem machine, which means that the information there will be lost.
There are two ways to implement CA: hardware and software. We will tell about each of them in a little more detail.
The hardware method is a “forked” server: all components are duplicated, and the calculations are performed simultaneously and independently. For synchronism meets the node, which among other things compares the results with the halves. In the event of a discrepancy, a search for the cause and an attempt to correct the error are performed. If the error is not corrected, the faulty module is disabled.
On Habré was recently an article on the topic of hardware CA-servers. The manufacturer described in the material ensures that the annual downtime is not more than 32 seconds. So, in order to achieve such results, it is necessary to purchase equipment. The Russian partner of the Stratus company reported that the cost of a CA server with two processors for each synchronized module is about $ 160,000, depending on the configuration. Total per cluster will require $ 1 600 000.
Program method.
At the time of this writing, the most popular tool for deploying a cluster of continuous availability - vSphere from VMware. The technology for ensuring Continuous Availability in this product is called “Fault Tolerance”.
Unlike the hardware method, this option has limitations in use. We list the main ones:
- The physical host must have a processor:
- Intel Sandy Bridge Architecture (or newer). Avoton is not supported.
- AMD Bulldozer (or newer).
- Machines that use Fault Tolerance should be connected to a low 10 Gigabit network. VMware strongly recommends a dedicated network.
- No more than 4 virtual processors on the VM.
- No more than 8 virtual processors per physical host.
- No more than 4 virtual machines per physical host.
- Cannot use virtual machine snapshots.
- Unable to use Storage vMotion.
A complete list of limitations and incompatibilities is in the official documentation .
It was established experimentally that VMware's Fault Tolerance technology significantly “slows down” the virtual machine. In the course of the vmgu.ru study, after turning on the FT, VM performance when working with the database dropped by 47%.
Licensing vSphere is tied to physical processors. The price starts at $ 1,750 for a license + $ 550 for a one-year subscription and technical support. Also, to automate cluster management, you need to purchase VMware vCenter Server, which costs from $ 8000. Since for continuous availability, the 2N scheme is used, in order for 10 nodes to work with virtual machines, you need to additionally purchase 10 redundant servers and licenses to them. The total cost of the program part of the cluster will be 2 * ( 10 + 10 ) * ( 1750 + 550 ) + 8000 = $ 100,000.
We did not write out specific node configurations: the composition of the components in the servers always depends on the tasks of the cluster. Network equipment also does not make sense to describe: in all cases the set will be the same. Therefore, in this article we decided to consider only what exactly will differ: the cost of licenses.
It is worth mentioning those products whose development has stopped.
There is a Xen-based Remus , a free open source solution. The project uses technology microsnappings. Unfortunately, the documentation has not been updated for a long time; for example, the installation is described for Ubuntu 12.10, whose support was discontinued in 2014. And oddly enough, even Google did not find a single company that used Remus in its activities.
Attempts were made to refine QEMU in order to add the ability to create continuous availability of the cluster. At the time of this writing, there are two such projects.
The first is Kemari , an open source product led by Yoshiaki Tamura. It is supposed to use QEMU live migration mechanisms. However, the fact that the last commit was made in February 2011 suggests that the development is most likely deadlocked and will not resume.
The second is Micro Checkpointing , founded by Michael Hines, also open source. Unfortunately, there is already no activity in the repository for a year. It seems that the situation is similar to the project Kemari.
Thus, there is currently no implementation of continuous availability based on KVM virtualization.
So, practice shows that despite the advantages of continuous availability systems, there are many difficulties in implementing and operating such solutions. However, there are situations when fault tolerance is required, but there are no strict requirements for service continuity. In such cases, you can apply clusters of high availability, ARC.
High availability
In the context of the ARC, fault tolerance is provided by automatically detecting the equipment failure and then starting the service on a working cluster node.
The ARC does not synchronize the processes running on the nodes of the process and does not always synchronize the local disks of the machines. Therefore, the media used by the nodes must be in a separate independent storage, for example, in the network data storage. The reason is obvious: in case of failure of the node, communication with it will be lost, which means that it will not be possible to get access to information on its drive. Naturally, the storage system should also be fault tolerant, otherwise the ARC will not work by definition.
Thus, a high availability cluster is divided into two subclusters:
- Computational. This includes nodes that are directly running virtual machines.
- Storage Cluster. There are disks that are used by the nodes of the computational subcluster.
At the moment, for the implementation of the ARC with virtual machines on the nodes there are the following tools:
- Heartbeat version 1.x in conjunction with DRBD;
- Pacemaker;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- Openstack;
- oVirt;
- Red Hat Enterprise Virtualization;
- Windows Server Failover Clustering in conjunction with the server role “Hyper-V”;
- VMmanager Cloud.
We will introduce you to the features of our product VMmanager Cloud.
VMmanager Cloud
Our VMmanager Cloud solution uses QEMU-KVM virtualization. We made a choice in favor of this technology, since it is actively developed and supported, and also allows you to install any operating system on a virtual machine. Corosync is used as a tool for detecting failures in a cluster. If one of the servers fails, VMmanager sequentially distributes the virtual machines running on it across the remaining nodes.
In a simplified form, the algorithm is as follows:
- The cluster node is searched with the fewest virtual machines.
- A request is made whether there is enough free RAM to place the current VM in the list.
- If there is enough memory for the distributed machine, then VMmanager gives the command to create a virtual machine on this node.
- If there is not enough memory, then a search is performed on servers that carry more virtual machines.
We tested many hardware configurations, polled existing VMmanager Cloud users, and based on the data obtained, we concluded that distribution and resumption of all VMs from the failed node required from 45 to 90 seconds depending on the hardware performance.
Practice shows that it is better to single out one or more nodes for emergencies and not deploy VMs on them during normal operation. This approach eliminates the situation when there are not enough resources on the “live” nodes in the cluster to host all the virtual machines with the “dead” ones. In the case of one backup server, the backup scheme is called “N + 1”.
VMmanager Cloud supports the following storage types: file system, LVM, Network LVM, iSCSI, and Ceph . In the context of ARCs, the last three are used.
When using a perpetual license, the cost of the software part of the cluster of ten “combat” nodes and one backup will be € 3,520 or $ 3,865 today (the license costs € 320 per node, regardless of the number of processors on it). The license includes a year of free updates, and from the second year they will be provided as part of an upgrade package worth € 880 per year for the entire cluster.
Let us consider how the VMmanager Cloud users implemented high availability clusters.
Firstbyte
FirstByte started providing cloud hosting in February 2016. Initially, the cluster was running on OpenStack. However, the lack of available specialists in this system (both in terms of availability and price) prompted a search for another solution. The following requirements were placed on the new tool for controlling the ARC:
- The ability to provide virtual machines on KVM;
- Integration with Ceph;
- Integration with billing suitable for the provision of available services;
- Affordable cost of licenses;
- Availability of manufacturer support.
As a result, VMmanager Cloud came up best with the requirements.
Cluster features:
- Data transfer is based on Ethernet technology and is based on Cisco equipment.
- Cisco ASR9001 is responsible for routing; about 50,000 IPv6 addresses are used in the cluster.
- Link speed between compute nodes and 10 Gbps switches.
- Between switches and storage nodes, the data rate is 20 Gb / s; the aggregation of two 10 Gb / s channels is used.
- Between racks with storage nodes, there is a separate 20-gigabit link used for replication.
- In the storage nodes installed SAS-drives in conjunction with SSD-drives.
- Storage Type - Ceph.
In general, the system looks like this:

This configuration is suitable for hosting sites with high traffic, for hosting game servers and databases with a load from medium to high.
FirstVDS
The company FirstVDS provides failover hosting services, the product launch took place in September 2015.
The company has come to use VMmanager Cloud for the following reasons:
- Extensive experience with ISPsystem products.
- Integration with BILLmanager by default.
- Excellent quality technical support products.
- Ceph support.
The cluster has the following features:
- The data transfer is based on an Infiniband network with a connection speed of 56 Gb / s;
- Infiniband-network is built on the equipment Mellanox;
- SSD carriers are installed in the storage nodes;
- The type of storage used is Ceph.
The general scheme looks like this:
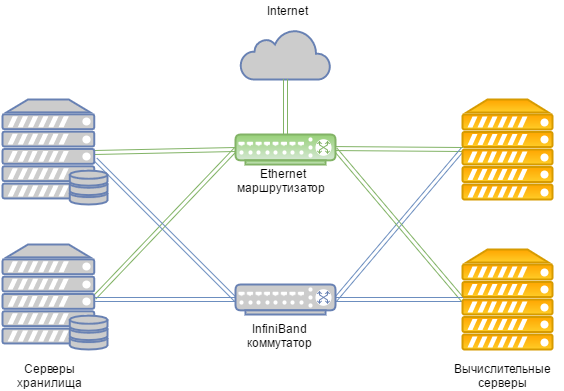
In the case of a general failure of the Infiniband network, the connection between the VM disk storage and the computing servers is performed via an Ethernet network, which is deployed on Juniper hardware. “Pickup” happens automatically.
Due to the high speed of interaction with the storage, such a cluster is suitable for hosting sites with ultra-high traffic, video hosting with streaming content playback, as well as for performing operations with large amounts of data.
Epilogue
Let's summarize the article. If every second of service downtime causes significant losses, you cannot do without a cluster of continuous availability.
However, if circumstances allow you to wait 5 minutes while the virtual machines are deployed on the backup node, you can look towards the ARC. This will provide savings in the cost of licenses and equipment.
In addition, we can not but recall that the only means to increase resiliency is redundancy. Providing server redundancy, do not forget to reserve lines and data transmission equipment, Internet access channels, power supply. All that you can reserve - back up. Such measures exclude a single point of failure, a thin spot, due to a malfunction in which the entire system stops working. By taking all the measures described above, you will get a fault-tolerant cluster that is really difficult to disable.
If you decide that a high availability scheme is more suitable for your tasks and have chosen VMmanager Cloud as a tool for its implementation, you will find installation instructions and documentation to help you get acquainted with the system in detail. We wish you uninterrupted work!
PS If you have hardware CA servers in your organization, please write in the comments who you are and why you use them. We are really interested to hear for which projects the use of such equipment is economically feasible :)
Source: https://habr.com/ru/post/313066/
All Articles