Evolutionary database design

Over the past decade, we have developed and improved several methods that allow database design to evolve in parallel with the development of the application.
This is a very valuable feature of flexible methodologies. The methods rely on the application of continuous integration and automated refactoring to database development, as well as close interaction between application developers and database administrators. These methods work both in preproduction and in already started systems, in fresh projects without Legacy, and in inherited systems.
In the last decade, we have seen an increase in flexible methodologies . Compared to their predecessors, they change the requirements for database design. One of the most important requirements is the idea of an evolutionary architecture. In a flexible project, you assume that you cannot fix the system requirements in advance. As a result, it becomes impractical to have a detailed, clear design stage at the beginning of a project. The system architecture should evolve simultaneously with software iterations. Flexible methods, in particular, extreme programming (XP), have a set of techniques that make this evolutionary architecture practical.
When we and our colleagues from ThoughtWorks began to do agile-projects, we realized that we need to solve the problem of database evolution to support the evolution of architecture. We started around 2000 with a project, the database of which eventually reached almost 600 tables. In the process of working on this project, we developed methods that allowed us to change the scheme and conveniently migrate existing data. This made the database fully flexible and evolving. We described the methods in earlier versions of this article, and its content inspired other commands and toolsets. Since then, we have used and further developed methods in hundreds of projects around the world, from small groups to large multinational programs. We have long been going to update this article, and now this opportunity has appeared.
Jen realizes new user story
In order to get an idea of how it all works, let's outline what happens when a developer (Jen) writes code to implement a new user story. The story describes a user who has the ability to see, search and update the position, batch number and serial number of goods in stock. Looking at the database schema, Jen sees that there are currently no fields in the product availability table, only one inventory_code field, which is the concatenation (union) of these three fields. It must divide the single code into three separate fields: location_code, batch_number, and serial_number.
Here are the steps she must take:
- Add new columns to the inventory table in an existing scheme.
- Write a migration script and separate the data from the inventory_code column by created columns: location_code, batch_number, and serial_number.
- Modify application code to use new columns.
- Modify all parts of the database code, such as samples, stored procedures, and triggers, to use the new columns.
- Change all indexes based on inventory_code.
- Save the database migration script and all application code changes to the version control system
To add new columns and transfer data, Jen writes a migration script for SQL, which she can compare with the current schema. This will simultaneously change the scheme and transfer all available data about the goods in stock.
ALTER TABLE inventory ADD location_code VARCHAR2(6) NULL; ALTER TABLE inventory ADD batch_number VARCHAR2(6) NULL; ALTER TABLE inventory ADD serial_number VARCHAR2(10) NULL; UPDATE inventory SET location_code = SUBSTR(product_inventory_code,1,6); UPDATE inventory SET batch_number = SUBSTR(product_inventory_code,7,6); UPDATE inventory SET serial_number = SUBSTR(product_inventory_code,11,10); DROP INDEX uidx_inventory_code; CREATE UNIQUE INDEX uidx_inventory_identifier ON inventory (location_code,batch_number,serial_number); ALTER TABLE product_inventory DROP COLUMN inventory_code; Jen runs the migration script in a local copy of the database on his computer. It then proceeds to update the code to use the new columns. In the process, it applies the existing test suite to the new code to detect any changes in the behavior of the application. Some tests, those that covered the combined column, need to be updated. Perhaps you need to add some more tests. After Jen did all this, and the application passed all the tests on her computer, she loads the changes into the common project repository, which we call mainline . These changes include migration scripts and application code changes.
If Jen is not very familiar with making these changes, she is lucky that they are universal for databases. Therefore, it can look into the book about the refactoring of databases . Online there is help on this topic.
After the changes appear in the mainline, they are picked up by the continuous integration server . It runs migration scripts on the database copy in mainline, and then all application tests. If everything is successful, this process will be repeated at each stage of the Deployment Pipeline , including testing (QA) and staging. The same code will finally run in production, this time updating the actual database schema and data.
In a small user history, as in the example, there is only one database migration, large user histories are often split into several separate migrations for each change in the database. Our rule is to make every change in the database as small as possible. The smaller, the easier it is to get the correct result, and any errors can be quickly detected and debugged. Migrations, as in the example, are easy to combine, so it is better to do a lot of small ones.
Work with changes
Since flexible methods became popular in the early 2000s, one of their most obvious characteristics is the tendency to change. Before they appeared, the most common ideas about software were: understanding the requirements at an early stage, setting requirements, using requirements as a basis for design, design execution, and then project execution. This plan-driven cycle is often called (usually with a mock) waterfall approach.
Such approaches are used in attempts to minimize changes, which translates into excessive preliminary work. And when the preliminary work is completed, the changes lead to serious problems. As a result, if requirements change, these approaches lead to malfunctions, and the revision of requirements is a headache for such processes.
Flexible processes have other methodological approaches to change. They are friendly to change, even in the later stages of project development. Changes are monitored, but the nature of the process makes them as likely as possible. Partly - this is the answer to the embedded instability of the requirements of many projects, in part - the concept of better support for dynamic business structures and helping them with changes, under the pressure of competitors.
In order to put this process on the wheels, you need to change the attitude to the design. Instead of thinking of design as a phase that ends before the design phase, you look at design as a continuous process that alternates with design, testing, and even delivery. Such a contrast between planned and evolutionary design.
One of the most important contributions of flexible methods is approaches in which evolutionary design has the ability to keep work under control. And instead of the usual chaos that often takes over, when design is not planned in advance, these methods give rise to ways to control evolutionary design and make them practical.
An important part of this approach is iterative development, when the full life cycle of software runs many times over the entire existence of a project. Flexible processes run the full life cycle in each iteration, completing the iteration with a working, tested, integrated code and a small subset of the requirements of the final product. These iterations are short - from a few hours to several weeks: more experienced teams use shorter iterations.
Although the interest and use of these methods has increased, one of the most important questions is how to use evolutionary design for databases. For a long time, a group of people from the database community perceived the design of the database as something that necessarily required preliminary planning. Changing the database schema in the final phases of development usually leads to propagating defects in the application. In addition, a change in the schema after deployment leads to painful data migration.
Over the past ten and a half years, we have participated in many large projects that used the evolutionary design of the database and it worked successfully. Some projects included more than 100 people at several work locations around the world. Others - more than half a million lines of code, more than 500 tables. Some of them had several versions of the application in production and each required around-the-clock service. In the course of these projects, we came across iterations lasting for a month and a week, but shorter iterations worked better. The methods described below made this possible.
From the first days we tried to spread the techniques to more of our projects. We got more experience from covering more cases, and now all our projects use this approach. We also draw inspiration, ideas, and experience from other people using this approach.
Restrictions
Before we begin to understand the approaches, I want to say that we have not solved all the problems of the evolutionary design of databases.
We had projects with hundreds of retail stores, with their own databases, each of which needed to be updated. But we have not yet considered the situation when a large group of sites have a lot of settings. As an example, you can consider a small business application that allows you to make schema settings crammed in thousands of different small companies.
Increasingly, we see people using a variety of schemas as part of a unified database environment. We worked with projects that used several similar schemes, but did not try dozens or hundreds. Over the next few years, we predict to deal with this situation.
We do not believe that these problems are unsolvable. In the end, when we wrote the original version of this article, we did not get rid of the problem of continuous work or database integration. We found ways to deal with them and hope that we will expand the boundaries of the evolutionary design of the database. But until this happens, we will not argue that we are not capable of solving such problems.
Techniques
Our approach to the evolutionary design of the database is based on several important techniques.
Database administrators work closely with developers
One of the principles of flexible methods is that workers with different skills and experience should interact very closely with each other. They do not have to communicate only through official meetings and documents. They need to contact and work with each other all the time. This affects everyone: analysts, project managers, subject matter experts, developers ... and database administrators.
Each task that a developer is working on may potentially need the help of a database administrator. Both developers and administrators must consider whether significant changes to the database schema will be included in the development task. If so, the developer should consult with the database administrator to decide how to make changes. The developer knows what new functionality is required, and the administrator has a unified view of the data of the current application and other surrounding applications. Often, developers have an idea of the application they are working on, but do not have all the other upstream or downstream dependencies of the scheme. Even if it is a single database application, it may contain dependencies about which the developer is not up to date.
At any time, the developer can contact the administrator and ask to understand the changes in the database. When the pair style is used, the developer learns how the database works, and the administrator learns the specifics of the database requirements. The most common question — whether to apply for changes to the DBA or not — lies with the developer if he is concerned about the impact of the changes on the database. But the DBA is also taking the initiative. When they see requirements that they believe can have a significant impact on the data, they can contact the developers to discuss the impact on the database. DBAs may also affect migrations, as they are fixed in the version control system. Since the return migration is annoying, we benefit from every small migration that is easier to reverse.
To make this possible, the DBA must willingly go forward and be accessible. It is necessary that the developer can easily descend and ask a few questions in slak or khipchaty - any means of communication that developers use. When you are organizing a workspace for a project, try to make the DBAs and the developers sit closer to each other so that they are easy to contact. Make sure that administrators are aware of any meetings related to the design of the application, so that they can easily catch up. In working microclimates, we often see people creating barriers between database administrators and development functions. For the evolutionary process of database design to work, you need to erase these barriers.
All database artifacts are version controlled with application code
Developers benefit greatly from using version control of all their artifacts: application code, functional and unit tests, code like build scripts, Chef or Puppet scripts used to create a working environment.
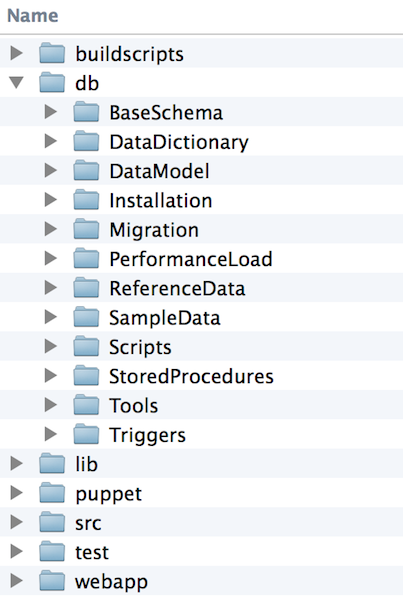
Figure 1: All database artifacts in version control, along with other project artifacts
Similarly, all database artifacts must be in a version control system, in the same repository that is used by everyone else. The advantages of this:
- Everything is in one place and it is easy for any project participant to find the right one.
- Every change to the database is saved, making it easy to check if any problem occurs. We can track any database deployment and find the required status of the schema and auxiliary data.
- We do not deploy if the database is not synchronized with the application, which leads to the return of errors and data updates.
- We can easily create new environments: for development, testing, and of course production. Everything you need to create a working version of the application must be in the same repository so that you can quickly clone and assemble.
All database changes are migrations.
In many organizations, there is a process in which developers make changes to the database using schema editing tools and ad-hoc SQL for data. After they finish development, database administrators compare the developed database with the database in production and make the appropriate changes there, putting the application into a working state. But in production it is difficult to do this, because the context indicator of changes, the one that was in development, was lost. We need to understand again why the changes were made, but to a different group of people.
To avoid this, we prefer to capture the changes during development and save them as an artifact of the first level, which can then be tested and fixed with the same process and control as for changes in the application code. We do this by displaying every change in the database, like a script for migrating the database, which, like changes in the application code, are in the version control system. These migration scripts include: schema changes, database code changes, reference data updates, transaction data updates, and data problems corrected due to production bugs.
Here is the change, the addition of min_insurance_value and max_insurance_value to the equipment_type table, with several default values.
ALTER TABLE equipment_type ADD( min_insurance_value NUMBER(10,2), max_insurance_value NUMBER(10,2) ); UPDATE equipment_type SET min_insurance_value = 3000, max_insurance_value = 10000000; This change adds a set of fixed data to the location and equipment_type tables.
-- Create new warehouse locations #Request 497 INSERT INTO location (location_code, name , location_address_id, created_by, created_dt) VALUES ('PA-PIT-01', 'Pittsburgh Warehouse', 4567, 'APP_ADMIN' , SYSDATE); INSERT INTO location (location_code, name , location_address_id, created_by, created_dt) VALUES ('LA-MSY-01', 'New Orleans Warehouse', 7134, 'APP_ADMIN' , SYSDATE); -- Create new equipment_type #Request 562 INSERT INTO equipment_type (equipment_type_id, name, min_insurance_value, max_insurance_value, created_by, created_dt) VALUES (seq_equipment_type.nextval, 'Lift Truck', 40000, 4000000, 'APP_ADMIN', SYSDATE); When working with this method, we never have to use schema editing tools such as Navicat, DBArtisanor, or SQL Developer, and we never run wireless DDL or DML to add persistent data or fix errors. In addition to updates in the database, which occur because of applications, all changes are made by migrations.
Calling migrations as SQL command sets, we only tell part of the story, but in order to use them correctly, we need something else.
- Each migration requires a unique identification.
- Need to keep track of which migrations have been applied to the database.
- You need to manage the constraints of the sequence of actions between migrations. In the example above, we must apply the ALTER TABLE migration at the beginning, otherwise the second migration will not be able to add the equipment type insert.
We process these requirements by assigning a serial number to each migration. It acts as a unique identifier and ensures that the order in which they are applied in the database can be maintained. When a developer creates a migration, he puts the SQL into a text file within the migration folder, within the project version control repository. It looks at the highest currently used number in the migration folder, and uses that number along with a description to give the file a name. The earliest pair of migrations can be called 0007_add_insurance_value_to_equipment_type.sql and 0008_data_location_equipment_type.
In order to track the application of migrations in the database, we use the changelog table. Database migration frameworks, as a rule, create this table and automatically update it every time a migration is applied. Then the database can always tell which migration was synchronized. If we do not use such a framework, because there are no such, we automate the process using a script at the beginning of our work.

Figure 2: The changelog table maintained by the database migration framework
Using this numbering scheme, we can track changes when they are applied to the set of databases we work with.

Figure 3: Migration script cycle from its inception to deployment in production
Some of these migrations may need to be implemented more often than migrations associated with new components. In this scenario, we noticed that it is useful to have a separate migration repository or folder for debugging data-related bugs.

Figure 4: Separate folders for managing new changes to database components and correcting data in production
Each of these folders can be tracked separately using database migration tools: Flyway, dbdeploy, MyBatis or similar. Each should have a separate table for storing the number of migrations. The flyway.table property in Flyway is used to change the name of the table where the migration metadata is stored.
Everyone has their own copy of the database.
Most development companies use a single database, jointly, by all employees. They may use a separate database for testers or staging, but they basically limit the number of active databases. Sharing a database in this way is a consequence of the fact that copies are difficult to install and manage. As a result, companies minimize their number. Control over who is responsible for changing the scheme in such situations is different: some companies require that all changes be made by administrative teams, others allow developers to make any changes, and administrators are attracted when the changes go to the next level.
When we started experimenting with flexible projects, we noticed that developers usually work in the same way — they use their own copy of the code. Just as people learn, going through different options, developers are experimenting with the implementation of components and can make several attempts before choosing the right one. It is necessary that they have the opportunity to experiment in their workspace, and then download the code to the shared repository when it is more and more stable. If everyone works in the same space, then they inevitably interfere with each other with half-ready changes. Although we prefer continuous integration, when integration does not occur more than a few hours later, a personal working copy plays an important role. Version control systems support this work, allowing developers to work independently and support the integration of their work into the mainline copy.
, . – , , . , , .
, , , . , , . . , Vagrant " " , .
5:

6:
, - , , . , , .
<target name="create_schema" description="create a schema as defined in the user properties"> <echo message="Admin UserName: ${admin.username}"/> <echo message="Creating Schema: ${db.username}"/> <sql password="${admin.password}" userid="${admin.username}" url="${db.url}" driver="${db.driver}" classpath="${jdbc.classpath}" > CREATE USER ${db.username} IDENTIFIED BY ${db.password} DEFAULT TABLESPACE ${db.tablespace}; GRANT CONNECT,RESOURCE, UNLIMITED TABLESPACE TO ${db.username}; GRANT CREATE VIEW TO ${db.username}; ALTER USER ${db.username} DEFAULT ROLE ALL; </sql> </target> , , . .
<target name="drop_schema"> <echo message="Admin UserName: ${admin.username}"/> <echo message="Working UserName: ${db.username}"/> <sql password="${admin.password}" userid="${admin.username}" url="${db.url}" driver="${db.driver}" classpath="${jdbc.classpath}" > DROP USER ${db.username} CASCADE; </sql> </target> , , . - build.properties , Jen db.username, . , , create_schema .
, , , , , , , , .
, . QA , , . , .
, , — , (CI). CI , mainline . : mainline, . , — GoCD, SNAP CI, Jenkins, Bambooand Travis CI.
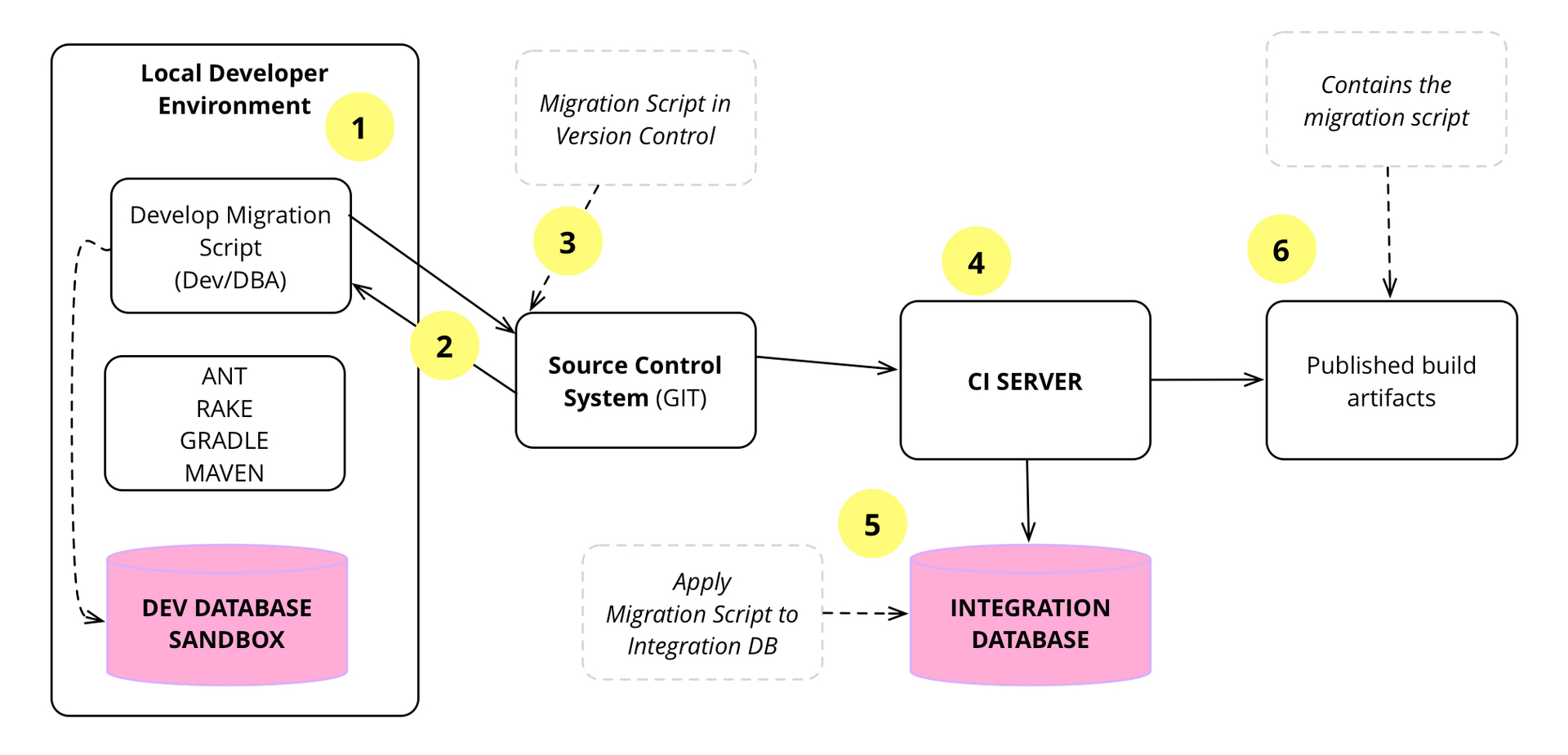
7: ,
7 , , , , CI , .
1) , . , , , , . , .
, , .
ALTER TABLE project ADD projecttypeid NUMBER(10) NULL; ALTER TABLE project ADD (CONSTRAINT fk_project_projecttype FOREIGN KEY (projecttypeid) REFERENCES projecttype DEFERRABLE INITIALLY DEFERRED); UPDATE project SET projecttypeid = (SELECT projecttypeid FROM projecttype WHERE name='Integration'); — , , . , , .
2) , , . — mainline. , , . , , .
- , — , — . , , . , .
, , , . , . , , mainline.
3) mainline. , — Parallel Change .
4) CI mainline , .
5) CI , , . , : , , .
6) , , CI . , downstream , Deployment Pipeline. , jar, war, dll .
. . — DDL, DML, Data, , , , — , . , , , , .
, , . , (), . ( ). , , . , , .
, , . , , , , . , , , .. - production, .
. — . , . — . , , , .
, , , , , .
, . , , .
, , . , . . , , . Incremental Migration .
, , , , , . , . Jailer .
—
, , , , . , , . , .
, , ,
, . , , , .
, , .
, , , , .
, . , . .
non nullable , , null, . , , . , null.
( ), , . ( ) . .
ALTER TABLE customer MODIFY last_usage_date DEFAULT sysdate; UPDATE customer SET last_usage_date = (SELECT MAX(order_date) FROM order WHERE order.customer_id = customer.customer_id) WHERE last_usage_date IS NULL; UPDATE customer SET last_usage_date = last_updated_date WHERE last_usage_date IS NULL; ALTER TABLE customer MODIFY last_usage_date NOT NULL; — . , , , , , , .
, . .
, , , . , . , , , .
— , , . . ( , DDL, DML , , .)
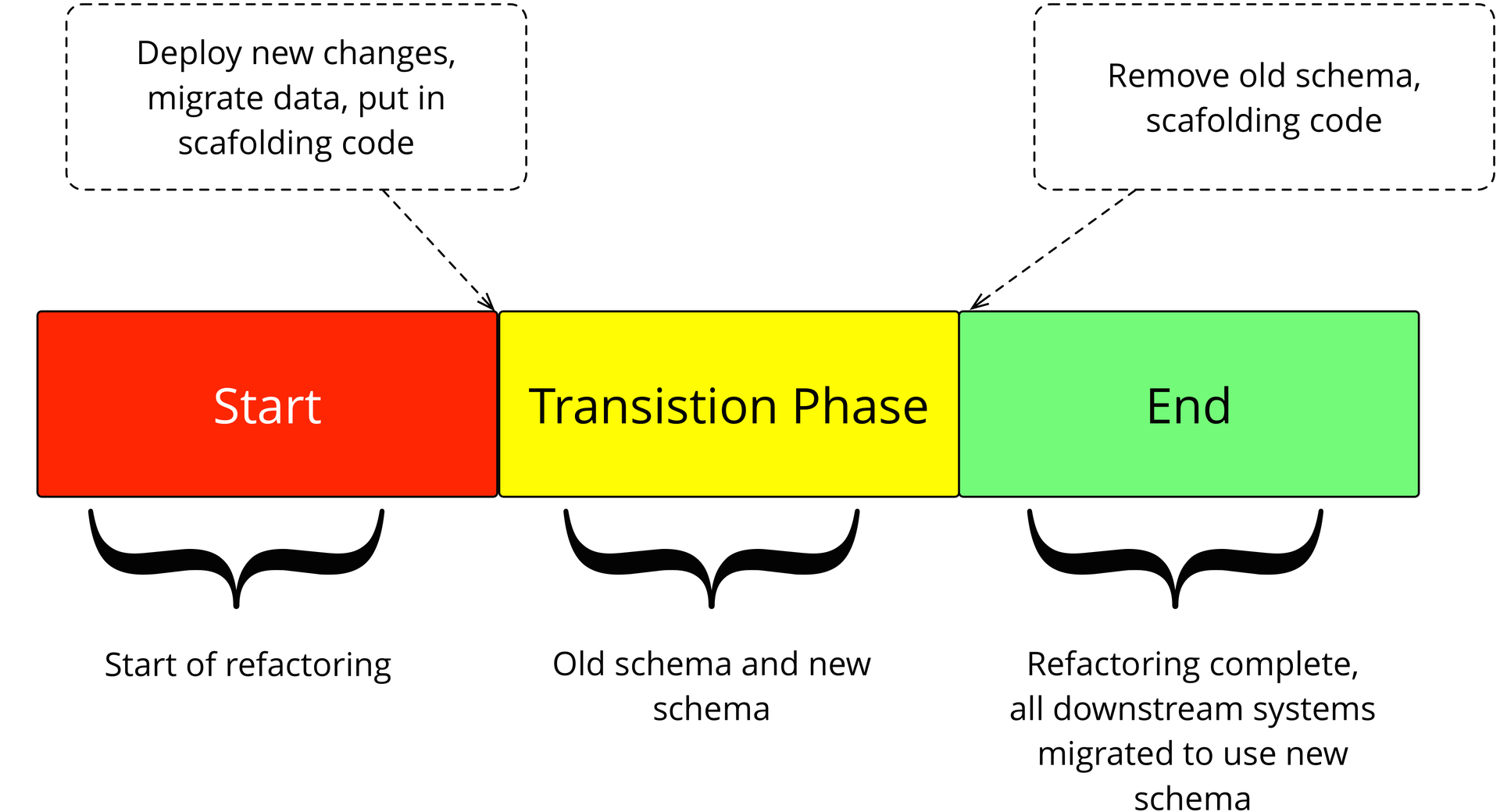
8: , ,
ALTER TABLE customer RENAME to client; CREATE VIEW customer AS SELECT id, first_name, last_name FROM client; , , customer client, customer, . . , downstream . , .
, . . . LiquiBase Active Record Migrations DSL , .
, . .
, , SQL DDL ( ) DML ( ) . , , . .
, . , , . , production.
production , . , , . , production , . , .
, . . , , , . , . , , production, , , , , .
, , , Flyway, LiquiBase, MyBatis, DBDeploy. Flyway.
psadalag:flyway-4 $ ./flyway migrate Flyway 4.0.3 by Boxfuse Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2) Successfully validated 9 migrations (execution time 00:00.021s) Creating Metadata table: "JEN_DEV"."schema_version" Current version of schema "JEN_DEV": << Empty Schema >> Migrating schema "JEN_DEV" to version 0 - base version Migrating schema "JEN_DEV" to version 1 - asset Migrating schema "JEN_DEV" to version 2 - asset type Migrating schema "JEN_DEV" to version 3 - asset parameters Migrating schema "JEN_DEV" to version 4 - inventory Migrating schema "JEN_DEV" to version 5 - split inventory Migrating schema "JEN_DEV" to version 6 - equipment type Migrating schema "JEN_DEV" to version 7 - add insurance value to equipment type Migrating schema "JEN_DEV" to version 8 - data location equipment type Successfully applied 9 migrations to schema "JEN_DEV" (execution time 00:00.394s). psadalag:flyway-4 $ .
, mainline — , . , , , , , . — mainline .
. , , - mainline . 8, . .
psadalag:flyway-4 $ ./flyway migrate Flyway 4.0.3 by Boxfuse Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2) ERROR: Found more than one migration with version 8 Offenders: -> /Users/psadalag/flyway-4/sql/V8__data_location_equipment_type.sql (SQL) -> /Users/psadalag/flyway-4/sql/V8__introduce_fuel_type.sql (SQL) psadalag:flyway-4 $ , : 9, mainline. . , , 8 9 .
psadalag:flyway-4 $ mv sql/V8__introduce_fuel_type.sql sql/V9__introduce_fuel_type.sql psadalag:flyway-4 $ ./flyway clean Flyway 4.0.3 by Boxfuse Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2) Successfully cleaned schema "JEN_DEV" (execution time 00:00.031s) psadalag:flyway-4 $ ./flyway migrate Flyway 4.0.3 by Boxfuse Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2) Successfully validated 10 migrations (execution time 00:00.013s) Creating Metadata table: "JEN_DEV"."schema_version" Current version of schema "JEN_DEV": << Empty Schema >> Migrating schema "JEN_DEV" to version 0 - base version Migrating schema "JEN_DEV" to version 1 - asset Migrating schema "JEN_DEV" to version 2 - asset type Migrating schema "JEN_DEV" to version 3 - asset parameters Migrating schema "JEN_DEV" to version 4 - inventory Migrating schema "JEN_DEV" to version 5 - split inventory Migrating schema "JEN_DEV" to version 6 - equipment type Migrating schema "JEN_DEV" to version 7 - add insurance value to equipment type Migrating schema "JEN_DEV" to version 8 - data location equipment type Migrating schema "JEN_DEV" to version 9 - introduce fuel type Successfully applied 10 migrations to schema "JEN_DEV" (execution time 00:00.435s). psadalag:flyway-4 $ , , , - , . , . : .
, , , mainline - .
, , , . , , , mainline.
, , , . SQL , . , . Patterns of Enterprise Application Architecture .
. , SQL, , SQL. , , . , , SQL, , . , .
, . - , — .
, production . , , , , .
Variations
, , , .
, , . AB Canary Releases , , . , . production, , , .
, — , . , , , , production.
, . , ( ), , , , Flyway .
,
— Shared Database . , , , . , , , . , , , , . , , .
NoSQL
, , , . , , NoSQL , . , , , .
NoSQL , "". , . , , . , . . , .
, . , ( QA, ) . , . , , .
. ( ), , . , , - , , , .
. , , . DevOps (Puppet, Chef, Docker, Rocket, and Vagrant) .
, , , , , production . — . , . , , , .
(Translation by Natalia Bass )
')
Source: https://habr.com/ru/post/312970/
All Articles