How many heap spaces do 100 million lines occupy in java?
When working with natural language and linguistic analysis of texts, we often have to operate with a huge number of unique short lines. The score goes to tens and hundreds of millions - that is how much there are, for example, meaningful combinations of two words in a language. The main platform for us is Java and we know firsthand about its voracity when working with so many small objects.
To estimate the scale of the disaster, we decided to conduct a simple experiment - to create 100 million blank lines in Java and see how much RAM to pay for them.
Attention: At the end of the article is a survey. It will be interesting if you try to answer it before reading the article, for self-control.
')
The rule of good tone when conducting any measurements is considered to publish the version of the virtual machine and test run parameters:
Pointer compression enabled (read: heap size less than 32 GB):
Pointer compression disabled (read: heap size greater than 32 GB):
The source code of the test itself:
Process
We look for the process ID using the jps utility and take a heap dump with jmap :
Analyze a heap snapshot using Eclipse Memory Analyzer (MAT) :
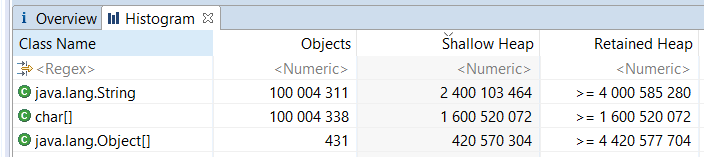

For the second test with the pointer compression off, no images are given, but we honestly conducted an experiment and asked to take a word (optimally: reproduce the test and see for ourselves).
findings
If you are working with a heap size larger than 32GB (pointer compression is off), then the pointers will cost even more. Accordingly, there will be such results:
Total, for each line you in addition to the size of the array of characters pay 44 bytes (64 bytes without compressing pointers). If the average string length is 15 characters, it turns out almost 5 bytes for each character. Prohibitively expensive when it comes to home gland.
How to fight
There are two main strategies for saving resources:
Unfortunately, there are no built-in mechanisms for storing each individual line more compactly in Java. In the future, the situation may improve slightly for individual scenarios: see JEP 254 .
On look
We strongly recommend that you look at the report by Alexei Shipilev from Oracle under the loud title “Catechism java.lang.String” (thanks to periskop for the tip). There he talks about the problem of the article at 4:26 and about the internment / deduplication of strings, starting at 31:52.
Finally
The solution to any problem begins with an assessment of its scale. Now you know these scales and can take into account the overhead when working with a large number of lines in your projects.
To estimate the scale of the disaster, we decided to conduct a simple experiment - to create 100 million blank lines in Java and see how much RAM to pay for them.
Attention: At the end of the article is a survey. It will be interesting if you try to answer it before reading the article, for self-control.
')
The rule of good tone when conducting any measurements is considered to publish the version of the virtual machine and test run parameters:
> java -version java version "1.8.0_101" Java(TM) SE Runtime Environment (build 1.8.0_101-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode) Pointer compression enabled (read: heap size less than 32 GB):
java -Xmx12g -Xms12g -XX:+UseConcMarkSweepGC -XX:NewSize=4g -XX:+UseCompressedOops ... ru.habrahabr.experiment.HundredMillionEmptyStringsExperiment Pointer compression disabled (read: heap size greater than 32 GB):
java -Xmx12g -Xms12g -XX:+UseConcMarkSweepGC -XX:NewSize=4g -XX:-UseCompressedOops ... ru.habrahabr.experiment.HundredMillionEmptyStringsExperiment The source code of the test itself:
package ru.habrahabr.experiment; import org.apache.commons.lang3.time.StopWatch; import java.util.ArrayList; import java.util.List; public class HundredMillionEmptyStringsExperiment { public static void main(String[] args) throws InterruptedException { List<String> lines = new ArrayList<>(); StopWatch sw = new StopWatch(); sw.start(); for (int i = 0; i < 100_000_000L; i++) { lines.add(new String(new char[0])); } sw.stop(); System.out.println("Created 100M empty strings: " + sw.getTime() + " millis"); // System.gc(); // while (true) { System.out.println("Line count: " + lines.size()); Thread.sleep(10000); } } } Process
We look for the process ID using the jps utility and take a heap dump with jmap :
> jps 12777 HundredMillionEmptyStringsExperiment > jmap -dump:format=b,file=HundredMillionEmptyStringsExperiment.bin 12777 Dumping heap to E:\jdump\HundredMillionEmptyStringsExperiment.bin ... Heap dump file created Analyze a heap snapshot using Eclipse Memory Analyzer (MAT) :
For the second test with the pointer compression off, no images are given, but we honestly conducted an experiment and asked to take a word (optimally: reproduce the test and see for ourselves).
findings
- 2.4 GB takes a binding of objects of class String + pointers to arrays of characters + hashes.
- 1.6 GB takes binding arrays of characters.
- 400 MB occupy pointers to lines.
If you are working with a heap size larger than 32GB (pointer compression is off), then the pointers will cost even more. Accordingly, there will be such results:
- 3.2 GB takes the binding of objects of class String + pointers to arrays of characters + hashes.
- 2.4 GB is a binding of arrays of characters.
- 800 MB occupy pointers to lines.
Total, for each line you in addition to the size of the array of characters pay 44 bytes (64 bytes without compressing pointers). If the average string length is 15 characters, it turns out almost 5 bytes for each character. Prohibitively expensive when it comes to home gland.
How to fight
There are two main strategies for saving resources:
- For a large number of duplicate lines, interning (string interning) or deduplication (string deduplication) can be used. The essence of the mechanism is as follows: since the lines in Java are immutable, you can store them in a separate pool and, when repeated, refer to an existing object instead of creating a new line. This approach is not free - it costs both memory and processor time for storing the structure of the pool and searching it.
What is the difference between internment and deduplication, what are the variations of the latter, and what the use of the String.intern () method is fraught with in Alexey Shipilev's wonderful report ( link ), starting at 31:52. - If, as in our case, the strings are unique, there is nothing else left but to use various algorithmic tricks. Mini-announcement: how we work with hundreds of millions of digrams (read: word + word or 15 characters) in our tasks we will tell in the very near future.
Unfortunately, there are no built-in mechanisms for storing each individual line more compactly in Java. In the future, the situation may improve slightly for individual scenarios: see JEP 254 .
On look
We strongly recommend that you look at the report by Alexei Shipilev from Oracle under the loud title “Catechism java.lang.String” (thanks to periskop for the tip). There he talks about the problem of the article at 4:26 and about the internment / deduplication of strings, starting at 31:52.
Finally
The solution to any problem begins with an assessment of its scale. Now you know these scales and can take into account the overhead when working with a large number of lines in your projects.
Source: https://habr.com/ru/post/312738/
All Articles