Search Yandex from an engineering point of view. Lecture in Yandex
Today we are publishing one more of the reports that were heard at the summer meeting on the Yandex search device. The speech of the head of the ranking department, Peter Popov, turned out to be the most accessible for a wide audience that day: a minimum of formulas, a maximum of general concepts about search. But it was interesting to everyone, because Peter went several times to the details and eventually told a lot of things that Yandex had never publicly announced.
By the way, simultaneously with the publication of this decryption, the second meeting of the series on Yandex technologies begins. Today's event is no longer about search, but about infrastructure. Here is a link to the broadcast .
Well, under the cut - a lecture by Peter Popov and part of the slides.
')
My name is Petr Popov, I work in Yandex. I've been here for about seven years. Before that, he programmed computer games, was engaged in 3D graphics, knew about video cards, wrote in SSE-assembler, in general, he dealt with such things.
It must be said that when I got a job at Yandex, I knew very little about the subject area - about what people do here. He knew only that good people work here. Therefore, I had some doubts.

Now I will tell you quite fully, but not very deeply about how our search looks. What is Yandex? This is a search engine. We must receive a user request and form a top ten results. Why exactly the top ten? Users rarely go to farther pages. We can assume that the ten documents - that's all that we show.
I don’t know if there are people in the hall who advertise Yandex, because they believe that the main product of Yandex is something completely different. As usual, there are two points of view and both are correct.
We believe that the main thing is the happiness of the user. And, surprisingly, on the composition of dozens and how a dozen are ranked, this happiness depends. If we worsen the issue, users use Yandex less, go to other search engines, feel bad.

What construction have we built for the sake of solving this simple task - to show ten documents? The design is quite powerful, from the bottom, apparently, the developers look at it.
Our work model. We need to do a few things. We need to bypass the Internet, index the resulting documents. We call the document the downloaded web page. Index, add to the search index, run a search program on this index, and respond to the user. In general, everything, profit.
Walk through the steps of this conveyor. What is the Internet and how much is it? Internet, count, endless. Take any site that sells something, some online store, change the sorting options there - another page will appear. That is, you can set the GGI parameters of the page, and the content will be completely different.
How many fundamentally significant pages do we know to the accuracy of discarding insignificant CGI parameters? Now - about a few trillion. We download pages at speeds of the order of several billion pages per day. And it would seem that we could do our work in a finite time, there, in two years.
How do we even find new pages on the Internet? We went around some page, pulled out links from there. They are our potential victims for download. It is possible that in two years we will go around these trillions of URLs, but new ones will appear, and in the process of parsing documents, links to new pages will appear. Already here it is clear that our main task is to deal with the infinity of the Internet, having the ultimate engineering resources in the form of data centers.
We downloaded all the crazy trillions of documents, indexed. Next you need to put them in the search index. In the index, we put not everything, but only the best of what we downloaded.

There is Comrade Ashmanov, widely known in the narrow circles of a specialist in search engines on the Internet. He builds different quality charts of search engines. This is a graph of the completeness of the search base. How is it built? A query from a rare word is set, it looks what documents are in all search engines, this is 100%. Every search engine knows about some share. From above in red we, from below in black - our main competitor.
Here you can ask the question: how have we achieved this? There are several possible answers. Option one: we parsed the page with these tests, tore out all the URLs, all the queries that Comrade Ashmanov asks and indexed the pages. No, we didn't do that. The second option: for us, Russia is the main market, and for competitors it is something marginal, somewhere in the periphery of view. This answer has the right to life, but I don’t like it either.
The answer, which I like, is that we have done a lot of engineering work, we have done a project called a “big base”, we bought a lot of iron for it and now we are seeing this result. The competitor can also be beaten, he is not iron.
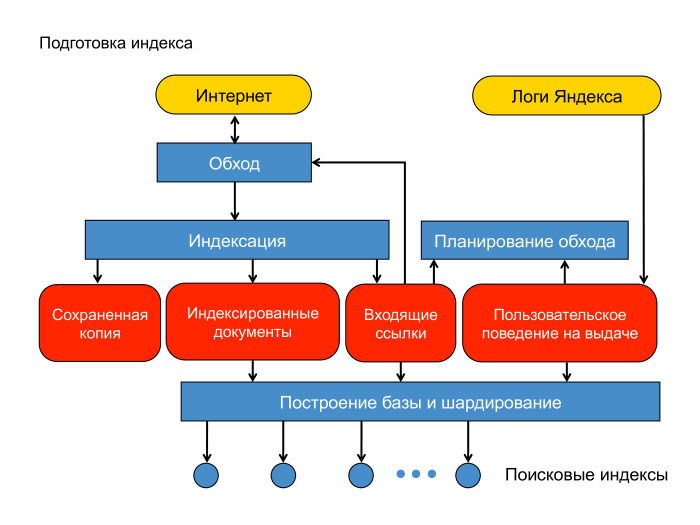
Documents we downloaded. How do we build a search base? Here is a diagram of our content system. There is the Internet, a cloud of documents. There are cars that bypass it - spiders, spiders. The document we downloaded. For a start - put it in a saved copy. This is, in fact, a separate, interdatacented hash table, where you can read and write in case we later want to index or show this document to the user as a saved copy at issue.
Then we indexed the document, defined the language and pulled out the words given according to the morphology of the language to the main forms. We also pulled out links leading to other pages.
There is another source of data that we widely use when building an index and generally in ranking - Yandex logs. The user asked for a request, got the top ten results and somehow behaves there. Documents appeared to him, he clicks or does not click.
It is reasonable to assume that if the document appeared in the issue, or, especially, if the user clicked on it, did some kind of interaction, then such a document should be left in the search base. In addition, it is logical to assume that links from such a good document lead to documents that are also good and which would be a good priority to download. This is a walkthrough planning. The arrow from planning a walk should lead to a walk.
Next is the stage of building a search index. These rounded rectangles lie in MapReduce, our own implementation of MapReduce, which is called YT, Yandex Table . Here I am a little varnishing - in fact, building the base and sharding operate with indices as files. We will fix this a little bit. These rounded rectangles will lie in MapReduce. The total amount of data here is about 50 PB. Here they turn into search indexes, into files.
There are problems in this scheme. The main reason is that MapReduce is a purely batch operation. To determine the priority documents for traversing, for example, we take the entire link graph, interrupt it with all user behavior, and form a queue for the jump. This process is rather latent, taking some time. Exactly the same with the construction of the index. There is a stage of processing - they are batchevy for the entire base. And the layout is the same, we either lay out the delta or everything.
An important task with these volumes is to speed up the index delivery process. I must say that this task is difficult for us. We are talking about the fight against the batting nature of building the base. We have a special fast circuit that pumps all kinds of news in real time, communicates to the user. This is our line of work, what we do.

But the second side of the coin. The first is the content system, the second is the search. You can understand why I painted the pyramid - because the search for Yandex really looks like a pyramid, such a hierarchical structure. On top are balancers, fronts that generate the issue. Slightly lower - aggregating meta-searches, which aggregate the output from different verticals. I must say that at the extradition you probably saw web documents, videos and pictures. We have three different indexes, they are polled independently.
Each of your search queries goes down this hierarchy and goes down to each piece of the search base. We have built the entire index, divided into thousands of pieces. Conventionally, for two, three, five thousand. Above each piece raised the search, and this request went down everywhere.

It is immediately clear that the search for Yandex is a big thing. Why is she big? Because we keep in our memory, as you saw in the previous slides, a fairly representative and powerful piece of the Internet. We store more than once: in each data center from two to four copies of the index. Our request goes down to each search, in fact, is traversed by each index. Now used data structures are such that we have to store all this directly in the RAM.

What do we have to do? Instead of expensive RAM, use a cheap SSD, speed up the search, say, twice, and get a profit - tens or hundreds of millions of dollars in capital expenditures. But there is no need to say: the crisis, Yandex saves and all that. In fact, all that we save, we put in a useful thing. We will double the index. We will look for it better. And this is what this kind of complex engineer is doing for. This is a real project, however, it is rather heavy and sluggish, but we really do it, we want to improve our search.
The search cluster is not only large enough - it is also very complex. There really are millions of instances of various programs. I wrote at first — hundreds of thousands, but comrades from exploitation corrected me — still millions. On each machine in very many instances 10-20 pieces exactly spinning.
We have thousands of different types of services spread across the cluster. It is necessary to clarify: a cluster is such machines, hosts, programs are running on them, they all communicate over TCP / IP. Programs have different consumption of CPU, memory, hard disk, network - in short, all these resources. Programs live on hostel hosts. More precisely, if we plant one program per host, then the cluster will not be recycled. Therefore, we are forced to settle programs with each other.
Next slide about what to do with it. And here - a small note that we roll all these programs, all releases using torrents, and the number of hands on our torrent tracker exceeds the number on Pirate Bay. We are really big.
What needs to be done with all this cluster design? It is necessary to improve the mechanisms of virtualization. We really invest in the development of the Linux kernel, we have our own container management system à la Docker, Oleg will tell you more about it.
We need to plan in advance on which hosts which programs should be allocated to each other, this is also a difficult task. We constantly have something on the cluster goes. Now there must be ten releases rolling.
We need to skillfully lodge programs with each other, we need to improve virtualization, we still need to combine two large clusters - robot and search. We somehow independently ordered iron and believed that there are separate machines with a huge number of disks and separately - thin blades for search. Now we understand that it is better to order unified hardware and run MapReduce and search programs in isolation: one eats mostly disks and a network, the second mainly CPU, but they have a balance on CPU, you need to turn it back and forth. These are big engineering projects that we also do.
What do we get from this? Benefit tens of millions of dollars in capital cost savings. You already know how we will spend this money - we will spend it on improving our search.
Here I talked about the design as a whole. Any separate building blocks. These blocks people hollowed chisel, and they got something.

Matrixnet ranking function. Simple enough feature. You can read - there are binary signs of the document in the vector, and in this cycle the relevance is calculated. I am sure that among you there are specialists who can program on SSE, and they would speed it up ten times faster. So it happened at some point. A thousand lines of code saved us 10-15% of the total CPU consumption on our cluster, which again amounts to tens of millions of dollars in capital expenditures, which we know how to spend. This is a thousand lines of code, which are very expensive.
We have more or less cleaned it out of the repository, optimized it, but there is still something to do there.
We have a platform for machine learning. Indices from the previous slide need to pick up in a greedy way, going through all the possibilities. On the CPU, this is a long time to do. On the GPU - quickly, but the pools for learning do not climb into memory. What do we have to do? Or buy custom solutions, where these glands are stuck a lot, or connect machines fast, use interconnect of some kind, infiniband, learn to live with it. It is typically buggy, does not work. This is a very funny engineering challenge that we also meet. He, it would seem, is not at all connected with our main activity, but nonetheless.

What we are investing in is data compression algorithms. The main task of compression looks like this: there is a sequence of integers, you need to compress it somehow, but not just compress it - you also need to have random access to the i-element. A typical algorithm is to compress it in small blocks, to have markup for the overall data flow. Such a task is completely different than context compression of the zip or LZ-family type. There are completely different algorithms. Can be compressed with Huffman, Varlnt, PFORX type blocks. We have our own proprietary algorithm, we are improving it, and this again is 10-15% savings in RAM for a simple algorithm.
We have all sorts of funny little things, such as improvements in the CPU, Linux schedulers. Is there any problem with hyperhigh stones from Intel? That there are two threads on the physical core. When there two threads occupy two threads, then they work slowly, the latency increases. It is necessary to correctly distribute puzzles on physical processors.
If you scatter correctly, and not in the way the stock planner does, you can get 10-15% of the latency of our query, conditionally. This is what users see. Multiple milliseconds multiplied by the number of searches - this is the saved time for users.
We have some really weird things like malloc's own implementation, which actually doesn't work. It works in arenas, and each location simply moves the pointer inside this arena. Well, the ref counter of the arena raises one. The arena is alive while the last location is alive. For any mixed load, when we have a short-lived and long-lived location, this does not work, it looks like a memory leak. But our server programs are not the same. A request comes in, we allocate internal structures there, somehow we work, then we give an answer to the user, everything is demolished. This allocator works perfectly for our server programs that are stateless. Due to the fact that all locations are local, consistent in the arena, it works very quickly. There are no page faults, cache miss, etc. Very quickly - this is from 5% to 25% of the speed of our typical server programs.
This is an engineer, what else can you do? You can do machine learning. Sasha Safronov will tell you about it with love.
And now questions and answers.
I will take the question I liked the most, which came to the newsletter and which should be included in my presentation. Comrade Anatoly Drapkov asks: there is a famous slide about how quickly the formula was growing before the introduction of Matrixnet. In fact, both before and after. Are there any problems of growth now?
Growth problems we are in full growth. The next order of increase in the number of iterations in the ranking formula. Now we are doing about 200 thousand iterations there in the function of Matriksnet to respond to the user. Was obtained by the next engineering step. Previously, we ranked on base. This means that each baseline runs Matriksnet and produces a hundred results. We said: let's combine the best one hundred results on the average and rank it again with a very heavy formula. Yes, we did it, on average you can calculate the MatrixNet function in several streams, because you need a thousand times less resources. This is a project that allowed us to reach the next order of increasing the volume of the ranking function. What will happen - I do not know.
Andrei Styskin, Head of Yandex Search Products Management:
- How many bytes did the first Yandex ranking formula?
Peter:
- A dozen, I guess.
Andrew:
- Well, yes, probably, there are a hundred symbols somewhere. And how much does the Yandex ranking formula take now?
Peter:
- Somewhere 100 MB.
Andrew:
- Formula of relevance. This is for our broadcast rangers, SEO specialists. Try reengineering our 100MB rankings.
Ales Bolgova, Intel:
- In the last slide about malloc, could you explain how you allocate memory? Very interesting.
Peter:
- The usual page, 4 KB, is taken at the beginning of the rev counter, and then we are each location ... if the small locations are smaller than the page, we simply move in this page. In each thread, of course, this page has its own. When the page was closed - everything was forgotten about it. The only thing she has rev counter at the beginning.
Alesya:
- So you select the page?
Peter:
“Inside the page, with growings like this.” The only page lives, while in it the last allocation lives. For normal workload, it looks like a leak, for ours, it’s like normal work.
- How do you determine the quality of the page, should it be put in the index or not? Also machine learning?
Peter:
- Yes of course. The page has many factors, from its size to impressions on the search, to ...
Andrew:
- Up to robot rank. It is located on some host, in some subdirectory of the host, there are some links to it. Those who refer to it, have some quality. We take all this and try to predict with what probability, if the given page is downloaded, there will be information on it that will be returned to the issue by some kind of request. , — , - , . . .
- ...
:
— .
— , ?
:
— , Mail.Ru.
:
— — . , . , , , , , …
:
— , . , . , — -. 30 , . .
:
— .
:
— , , .
:
- Okay. — ? , ?
:
— , , . , , — .
:
— . , .
:
— , — , . , .
:
— , . : , , Lenta.ru. Lenta.ru, . . , .
:
— , 3-4 .
:
— , , real time.
:
— ?
:
— -, , .
:
— .
:
— . — , . — , , , - . .
:
— , , , ? , , ? : «Google». , . , -, - …
:
— , .
:
— , . , , . , , , . — , , , - , . «Google», Google - , , . .
:
— , . , .
:
— , , , : , - . , , , .
:
— : . , , .
:
— , «», , — , , , , .
:
— , .
:
— , , , . , . , - ?
:
— . : - , , , . « », , .
:
— — . , CPU- . Xeon Phi Intel? , GPU.
:
— , , . , - 1,5%. , , , ++-, .
— , , . , - ?
:
— . , , . , , , . , .
:
— . , , - , . , , , , , — . -, .
:
— , .
():
— , . deep learning ? -, ?
:
— Deep learning , . . , .
:
— , 0,5% , deep learning . - , , .
:
— , , -100 . . .
:
— deep learning , , , — .
:
— . , , , . , 10 , , ? , , 10 ?
:
— , - . .
:
— . , . , , , , , , , .
:
— 10 — , , .
():
— , , ?
:
— — 50 , , . , . , .
:
— ?
:
— — torrent, torrent share. .
:
— - ?
:
— , . , , .
:
— F5 — , …
:
— , , .
:
— - ?
:
— , , .
:
— .
:
— . , , , , , - . , , .
:
— . , , , . - — , - , — . DDoS .
, Sphinx Search:
— . — ? SSD , - , SSD?
— , 50-100 , . , . , . , . , .
:
— bandwidth latency?
:
— . , .
:
— , : -…
:
— , - — .
:
— ?
:
— -.
:
— : ?
:
— .
:
— .
:
— , . .
:
— - ?
:
— , , - .
:
— , …
:
— .
:
— ?
:
— - .
:
— , , .
:
— . , .
:
— ?
:
— .
:
— , .
:
— . . , ?
:
— , . … -, 250 , 95- . , - 700 .
:
— , JavaScript, 250 , 700.
:
— , , . .
:
— . , . ?
:
— , , , . .
:
— , , . , , , , , .
:
— , . , .
:
— , , ?
:
— . , , .
:
— real time, - . up . , .
:
— , .
:
— , , real time?
:
— , . , .
:
— , - , ?
:
— , . , .
:
— ?
:
— . , . , , . .
:
— ? , , ?
:
— , 50% . 40-50% — . - . 50-60%. .
By the way, simultaneously with the publication of this decryption, the second meeting of the series on Yandex technologies begins. Today's event is no longer about search, but about infrastructure. Here is a link to the broadcast .
Well, under the cut - a lecture by Peter Popov and part of the slides.
')
My name is Petr Popov, I work in Yandex. I've been here for about seven years. Before that, he programmed computer games, was engaged in 3D graphics, knew about video cards, wrote in SSE-assembler, in general, he dealt with such things.
It must be said that when I got a job at Yandex, I knew very little about the subject area - about what people do here. He knew only that good people work here. Therefore, I had some doubts.
Now I will tell you quite fully, but not very deeply about how our search looks. What is Yandex? This is a search engine. We must receive a user request and form a top ten results. Why exactly the top ten? Users rarely go to farther pages. We can assume that the ten documents - that's all that we show.
I don’t know if there are people in the hall who advertise Yandex, because they believe that the main product of Yandex is something completely different. As usual, there are two points of view and both are correct.
We believe that the main thing is the happiness of the user. And, surprisingly, on the composition of dozens and how a dozen are ranked, this happiness depends. If we worsen the issue, users use Yandex less, go to other search engines, feel bad.
What construction have we built for the sake of solving this simple task - to show ten documents? The design is quite powerful, from the bottom, apparently, the developers look at it.
Our work model. We need to do a few things. We need to bypass the Internet, index the resulting documents. We call the document the downloaded web page. Index, add to the search index, run a search program on this index, and respond to the user. In general, everything, profit.
Walk through the steps of this conveyor. What is the Internet and how much is it? Internet, count, endless. Take any site that sells something, some online store, change the sorting options there - another page will appear. That is, you can set the GGI parameters of the page, and the content will be completely different.
How many fundamentally significant pages do we know to the accuracy of discarding insignificant CGI parameters? Now - about a few trillion. We download pages at speeds of the order of several billion pages per day. And it would seem that we could do our work in a finite time, there, in two years.
How do we even find new pages on the Internet? We went around some page, pulled out links from there. They are our potential victims for download. It is possible that in two years we will go around these trillions of URLs, but new ones will appear, and in the process of parsing documents, links to new pages will appear. Already here it is clear that our main task is to deal with the infinity of the Internet, having the ultimate engineering resources in the form of data centers.
We downloaded all the crazy trillions of documents, indexed. Next you need to put them in the search index. In the index, we put not everything, but only the best of what we downloaded.
There is Comrade Ashmanov, widely known in the narrow circles of a specialist in search engines on the Internet. He builds different quality charts of search engines. This is a graph of the completeness of the search base. How is it built? A query from a rare word is set, it looks what documents are in all search engines, this is 100%. Every search engine knows about some share. From above in red we, from below in black - our main competitor.
Here you can ask the question: how have we achieved this? There are several possible answers. Option one: we parsed the page with these tests, tore out all the URLs, all the queries that Comrade Ashmanov asks and indexed the pages. No, we didn't do that. The second option: for us, Russia is the main market, and for competitors it is something marginal, somewhere in the periphery of view. This answer has the right to life, but I don’t like it either.
The answer, which I like, is that we have done a lot of engineering work, we have done a project called a “big base”, we bought a lot of iron for it and now we are seeing this result. The competitor can also be beaten, he is not iron.
Documents we downloaded. How do we build a search base? Here is a diagram of our content system. There is the Internet, a cloud of documents. There are cars that bypass it - spiders, spiders. The document we downloaded. For a start - put it in a saved copy. This is, in fact, a separate, interdatacented hash table, where you can read and write in case we later want to index or show this document to the user as a saved copy at issue.
Then we indexed the document, defined the language and pulled out the words given according to the morphology of the language to the main forms. We also pulled out links leading to other pages.
There is another source of data that we widely use when building an index and generally in ranking - Yandex logs. The user asked for a request, got the top ten results and somehow behaves there. Documents appeared to him, he clicks or does not click.
It is reasonable to assume that if the document appeared in the issue, or, especially, if the user clicked on it, did some kind of interaction, then such a document should be left in the search base. In addition, it is logical to assume that links from such a good document lead to documents that are also good and which would be a good priority to download. This is a walkthrough planning. The arrow from planning a walk should lead to a walk.
Next is the stage of building a search index. These rounded rectangles lie in MapReduce, our own implementation of MapReduce, which is called YT, Yandex Table . Here I am a little varnishing - in fact, building the base and sharding operate with indices as files. We will fix this a little bit. These rounded rectangles will lie in MapReduce. The total amount of data here is about 50 PB. Here they turn into search indexes, into files.
There are problems in this scheme. The main reason is that MapReduce is a purely batch operation. To determine the priority documents for traversing, for example, we take the entire link graph, interrupt it with all user behavior, and form a queue for the jump. This process is rather latent, taking some time. Exactly the same with the construction of the index. There is a stage of processing - they are batchevy for the entire base. And the layout is the same, we either lay out the delta or everything.
An important task with these volumes is to speed up the index delivery process. I must say that this task is difficult for us. We are talking about the fight against the batting nature of building the base. We have a special fast circuit that pumps all kinds of news in real time, communicates to the user. This is our line of work, what we do.
But the second side of the coin. The first is the content system, the second is the search. You can understand why I painted the pyramid - because the search for Yandex really looks like a pyramid, such a hierarchical structure. On top are balancers, fronts that generate the issue. Slightly lower - aggregating meta-searches, which aggregate the output from different verticals. I must say that at the extradition you probably saw web documents, videos and pictures. We have three different indexes, they are polled independently.
Each of your search queries goes down this hierarchy and goes down to each piece of the search base. We have built the entire index, divided into thousands of pieces. Conventionally, for two, three, five thousand. Above each piece raised the search, and this request went down everywhere.
It is immediately clear that the search for Yandex is a big thing. Why is she big? Because we keep in our memory, as you saw in the previous slides, a fairly representative and powerful piece of the Internet. We store more than once: in each data center from two to four copies of the index. Our request goes down to each search, in fact, is traversed by each index. Now used data structures are such that we have to store all this directly in the RAM.
What do we have to do? Instead of expensive RAM, use a cheap SSD, speed up the search, say, twice, and get a profit - tens or hundreds of millions of dollars in capital expenditures. But there is no need to say: the crisis, Yandex saves and all that. In fact, all that we save, we put in a useful thing. We will double the index. We will look for it better. And this is what this kind of complex engineer is doing for. This is a real project, however, it is rather heavy and sluggish, but we really do it, we want to improve our search.
The search cluster is not only large enough - it is also very complex. There really are millions of instances of various programs. I wrote at first — hundreds of thousands, but comrades from exploitation corrected me — still millions. On each machine in very many instances 10-20 pieces exactly spinning.
We have thousands of different types of services spread across the cluster. It is necessary to clarify: a cluster is such machines, hosts, programs are running on them, they all communicate over TCP / IP. Programs have different consumption of CPU, memory, hard disk, network - in short, all these resources. Programs live on hostel hosts. More precisely, if we plant one program per host, then the cluster will not be recycled. Therefore, we are forced to settle programs with each other.
Next slide about what to do with it. And here - a small note that we roll all these programs, all releases using torrents, and the number of hands on our torrent tracker exceeds the number on Pirate Bay. We are really big.
What needs to be done with all this cluster design? It is necessary to improve the mechanisms of virtualization. We really invest in the development of the Linux kernel, we have our own container management system à la Docker, Oleg will tell you more about it.
We need to plan in advance on which hosts which programs should be allocated to each other, this is also a difficult task. We constantly have something on the cluster goes. Now there must be ten releases rolling.
We need to skillfully lodge programs with each other, we need to improve virtualization, we still need to combine two large clusters - robot and search. We somehow independently ordered iron and believed that there are separate machines with a huge number of disks and separately - thin blades for search. Now we understand that it is better to order unified hardware and run MapReduce and search programs in isolation: one eats mostly disks and a network, the second mainly CPU, but they have a balance on CPU, you need to turn it back and forth. These are big engineering projects that we also do.
What do we get from this? Benefit tens of millions of dollars in capital cost savings. You already know how we will spend this money - we will spend it on improving our search.
Here I talked about the design as a whole. Any separate building blocks. These blocks people hollowed chisel, and they got something.
Matrixnet ranking function. Simple enough feature. You can read - there are binary signs of the document in the vector, and in this cycle the relevance is calculated. I am sure that among you there are specialists who can program on SSE, and they would speed it up ten times faster. So it happened at some point. A thousand lines of code saved us 10-15% of the total CPU consumption on our cluster, which again amounts to tens of millions of dollars in capital expenditures, which we know how to spend. This is a thousand lines of code, which are very expensive.
We have more or less cleaned it out of the repository, optimized it, but there is still something to do there.
We have a platform for machine learning. Indices from the previous slide need to pick up in a greedy way, going through all the possibilities. On the CPU, this is a long time to do. On the GPU - quickly, but the pools for learning do not climb into memory. What do we have to do? Or buy custom solutions, where these glands are stuck a lot, or connect machines fast, use interconnect of some kind, infiniband, learn to live with it. It is typically buggy, does not work. This is a very funny engineering challenge that we also meet. He, it would seem, is not at all connected with our main activity, but nonetheless.
What we are investing in is data compression algorithms. The main task of compression looks like this: there is a sequence of integers, you need to compress it somehow, but not just compress it - you also need to have random access to the i-element. A typical algorithm is to compress it in small blocks, to have markup for the overall data flow. Such a task is completely different than context compression of the zip or LZ-family type. There are completely different algorithms. Can be compressed with Huffman, Varlnt, PFORX type blocks. We have our own proprietary algorithm, we are improving it, and this again is 10-15% savings in RAM for a simple algorithm.
We have all sorts of funny little things, such as improvements in the CPU, Linux schedulers. Is there any problem with hyperhigh stones from Intel? That there are two threads on the physical core. When there two threads occupy two threads, then they work slowly, the latency increases. It is necessary to correctly distribute puzzles on physical processors.
If you scatter correctly, and not in the way the stock planner does, you can get 10-15% of the latency of our query, conditionally. This is what users see. Multiple milliseconds multiplied by the number of searches - this is the saved time for users.
We have some really weird things like malloc's own implementation, which actually doesn't work. It works in arenas, and each location simply moves the pointer inside this arena. Well, the ref counter of the arena raises one. The arena is alive while the last location is alive. For any mixed load, when we have a short-lived and long-lived location, this does not work, it looks like a memory leak. But our server programs are not the same. A request comes in, we allocate internal structures there, somehow we work, then we give an answer to the user, everything is demolished. This allocator works perfectly for our server programs that are stateless. Due to the fact that all locations are local, consistent in the arena, it works very quickly. There are no page faults, cache miss, etc. Very quickly - this is from 5% to 25% of the speed of our typical server programs.
This is an engineer, what else can you do? You can do machine learning. Sasha Safronov will tell you about it with love.
And now questions and answers.
I will take the question I liked the most, which came to the newsletter and which should be included in my presentation. Comrade Anatoly Drapkov asks: there is a famous slide about how quickly the formula was growing before the introduction of Matrixnet. In fact, both before and after. Are there any problems of growth now?
Growth problems we are in full growth. The next order of increase in the number of iterations in the ranking formula. Now we are doing about 200 thousand iterations there in the function of Matriksnet to respond to the user. Was obtained by the next engineering step. Previously, we ranked on base. This means that each baseline runs Matriksnet and produces a hundred results. We said: let's combine the best one hundred results on the average and rank it again with a very heavy formula. Yes, we did it, on average you can calculate the MatrixNet function in several streams, because you need a thousand times less resources. This is a project that allowed us to reach the next order of increasing the volume of the ranking function. What will happen - I do not know.
Andrei Styskin, Head of Yandex Search Products Management:
- How many bytes did the first Yandex ranking formula?
Peter:
- A dozen, I guess.
Andrew:
- Well, yes, probably, there are a hundred symbols somewhere. And how much does the Yandex ranking formula take now?
Peter:
- Somewhere 100 MB.
Andrew:
- Formula of relevance. This is for our broadcast rangers, SEO specialists. Try reengineering our 100MB rankings.
Ales Bolgova, Intel:
- In the last slide about malloc, could you explain how you allocate memory? Very interesting.
Peter:
- The usual page, 4 KB, is taken at the beginning of the rev counter, and then we are each location ... if the small locations are smaller than the page, we simply move in this page. In each thread, of course, this page has its own. When the page was closed - everything was forgotten about it. The only thing she has rev counter at the beginning.
Alesya:
- So you select the page?
Peter:
“Inside the page, with growings like this.” The only page lives, while in it the last allocation lives. For normal workload, it looks like a leak, for ours, it’s like normal work.
- How do you determine the quality of the page, should it be put in the index or not? Also machine learning?
Peter:
- Yes of course. The page has many factors, from its size to impressions on the search, to ...
Andrew:
- Up to robot rank. It is located on some host, in some subdirectory of the host, there are some links to it. Those who refer to it, have some quality. We take all this and try to predict with what probability, if the given page is downloaded, there will be information on it that will be returned to the issue by some kind of request. , — , - , . . .
- ...
:
— .
— , ?
:
— , Mail.Ru.
:
— — . , . , , , , , …
:
— , . , . , — -. 30 , . .
:
— .
:
— , , .
:
- Okay. — ? , ?
:
— , , . , , — .
:
— . , .
:
— , — , . , .
:
— , . : , , Lenta.ru. Lenta.ru, . . , .
:
— , 3-4 .
:
— , , real time.
:
— ?
:
— -, , .
:
— .
:
— . — , . — , , , - . .
:
— , , , ? , , ? : «Google». , . , -, - …
:
— , .
:
— , . , , . , , , . — , , , - , . «Google», Google - , , . .
:
— , . , .
:
— , , , : , - . , , , .
:
— : . , , .
:
— , «», , — , , , , .
:
— , .
:
— , , , . , . , - ?
:
— . : - , , , . « », , .
:
— — . , CPU- . Xeon Phi Intel? , GPU.
:
— , , . , - 1,5%. , , , ++-, .
— , , . , - ?
:
— . , , . , , , . , .
:
— . , , - , . , , , , , — . -, .
:
— , .
():
— , . deep learning ? -, ?
:
— Deep learning , . . , .
:
— , 0,5% , deep learning . - , , .
:
— , , -100 . . .
:
— deep learning , , , — .
:
— . , , , . , 10 , , ? , , 10 ?
:
— , - . .
:
— . , . , , , , , , , .
:
— 10 — , , .
():
— , , ?
:
— — 50 , , . , . , .
:
— ?
:
— — torrent, torrent share. .
:
— - ?
:
— , . , , .
:
— F5 — , …
:
— , , .
:
— - ?
:
— , , .
:
— .
:
— . , , , , , - . , , .
:
— . , , , . - — , - , — . DDoS .
, Sphinx Search:
— . — ? SSD , - , SSD?
— , 50-100 , . , . , . , . , .
:
— bandwidth latency?
:
— . , .
:
— , : -…
:
— , - — .
:
— ?
:
— -.
:
— : ?
:
— .
:
— .
:
— , . .
:
— - ?
:
— , , - .
:
— , …
:
— .
:
— ?
:
— - .
:
— , , .
:
— . , .
:
— ?
:
— .
:
— , .
:
— . . , ?
:
— , . … -, 250 , 95- . , - 700 .
:
— , JavaScript, 250 , 700.
:
— , , . .
:
— . , . ?
:
— , , , . .
:
— , , . , , , , , .
:
— , . , .
:
— , , ?
:
— . , , .
:
— real time, - . up . , .
:
— , .
:
— , , real time?
:
— , . , .
:
— , - , ?
:
— , . , .
:
— ?
:
— . , . , , . .
:
— ? , , ?
:
— , 50% . 40-50% — . - . 50-60%. .
Source: https://habr.com/ru/post/312716/
All Articles