Creating shared storage based on CEPH RBD and GFS2
Most cluster system software assumes that the file system is accessible from all cluster nodes. This file system is used to store software, data, to organize the work of some cluster subsystems, etc. The performance requirements of such an FS can vary greatly for different tasks, however, the higher it is, the more it is considered that the cluster is more stable and versatile. The NFS server on the master node is the minimum variant of such an FS. For large clusters, NFS is complemented by the deployment of LusterFS, a high-performance, specialized distributed file system that uses multiple servers as file storage and several meta-information servers. However, this configuration has a number of properties that make it difficult to work with it when clients use independent virtualized clusters. The HPC HUB vSC system uses the well-known CEPH solution and the GFS2 file system to create a shared FS.
As part of the work on the HPC HUB project, based on OpenStack, the task arose of creating fault-tolerant and high-performance shared storage for several groups of virtual machines, each of which is a small virtual HPC cluster. Each such cluster is issued to a separate client, which from the inside completely controls it. Thus, the task cannot be solved within the framework of a “normal” distributed system assembled on physical computers, since Ethernet networks of clusters are isolated from each other at the L2 level to protect customer data and their network traffic from each other. At the same time, data cannot be placed on each of the virtual machines within the framework of the classic shared system, because each machine lacks the capabilities and wants to free up valuable processor resources immediately after the calculations, without spending it on “data transfusion”, especially taking into account the use of the pay-per model -use. Fortunately, not everything is so bad. In light of the fact that shared storage is supposed to be used for HPC calculations, you can make several assumptions about the load:
A peer-to-peer system with nodes on which the calculation is made and data are simultaneously stored contradicts the HPC paradigm in principle, since Two un-synchronized activities appear on the node: an account and data recording from some other node. We were forced to abandon it initially. It was decided to build a two-tier system. There are several approaches to such a repository:
Let's try to analyze the advantages and disadvantages of these approaches.
')
In option 1) the classic distributed file system (or some subtree) is mounted to the guest OS. In this case, the file system servers are visible from each system and each other. This breaks network isolation at L2 level and potentially allows different users to see each other’s traffic with stored data. In addition, for the case of CEPH, only cooperative quotas are possible (that is, the user can reuse the allowable disk space at the expense of other users) in the file system mount mode via FUSE (filesystem in userspace), and not directly in the kernel. When mounted directly in the kernel, quotas are not supported at all.
In option 2) - a virtual file system (virtio-9p in QEMU) on top of a distributed file system mounted in a host - to work, you need to run QEMU on behalf of the superuser without lowering privileges, which reduces the overall security of the system or configure specific ACLs to store guest IDs users and guest access rights.
In option 3) in the absence of disk space on the physical servers, we can use only remote block devices of some kind of distributed storage. This option is not advisable for several reasons:
In option 4) we decided to try a distributed block device based on CEPH and some kind of file system within the cluster working with such a device. In fact, the guest, of course, sees the device not as a CEPH block device, but as an ordinary virtual VirtIO SCSI or, optionally, VirtIO block. We chose VirtIO SCSI for a very simple reason - because of the SCSI support for the unmap command, an analog of the well-known SATA TRIM command, which is sent by the guest when deleting files and freeing up space in the virtual storage.
Choosing a file system for a guest is also easy. There are only two options:
The installation of CEPH is perfectly described in the docs.ceph.com/docs/master/start documentation and did not cause any special problems. Currently, the system works with one redundant copy of data and without authorization. The CEPH network is isolated from the client network. Creating a block device also did not cause problems. Everything is standard.
Unfortunately, setting up with GFS2 took a lot longer than originally estimated. Explanatory descriptions in the network is extremely small and they are confused. The general idea looks something like this. The work of the shared file system in the kernel is controlled by several demons, the correct setting of which requires nontrivial effort or knowledge.
The first and most important thing to know is that you most likely will not be able to raise this file system on Ubuntu. Or you will have to rebuild a lot of little-used packages outside of RedHat under Ubuntu, allowing a bunch of non-trivial API-level conflicts.
Under a RedHat-like system, the sequence is more or less clear. Below are the commands for the guest CentOS 7.
First off, turn off SELinux. GFS2 will not work with it. This is official information from the manufacturer.
Put the basic software:
Enable / disable the necessary services:
NTP is necessary for the operation of the system; all distributed locks of areas of the block device are tied to it. The system is configured for a cluster isolated from the outside world, therefore, we disable firewalls. Next, we put the necessary software binding on each of the cluster nodes:
Please note that you do not need to create the user 'hacluster', it is created by itself when installing packages. In the future, you will need his password to create a network of mutual authorization between the cluster machines.
You can now create distributed storage if this has not been done before. It is done on any CEPH node, that is, in our case, on a physical node:
When formatting a file system, the cluster name is specified - in our case, 'gfs2' and the name of the file system within this cluster is 'fs', the number of journals is '-j17', which should be equal to the number of nodes (in our case, 17) that simultaneously work with this cluster and lock protocol for allocating disk space (in our case, 'lock_dlm' is distributed locking). The names of the cluster and file system will have to be specified when mounting the partition. In an isolated network within a cluster, you can use the same names for different clusters. This is not a problem.
Now it remains only to configure the mount in the guest OS. The configuration is performed with one of the cluster machines once.
Creating a mutual authorization network:
here, master and n01..n04 are virtual hosts on which a shared partition will be available.
Create a default cluster. Note that the cluster name must match the one used when creating the file system in the previous step.
Running service daemons - clvmd & dlm:
Mounting a GFS2 partition in / shared, shared block device - sdb:
From this point on, you can enjoy the start of the whole system, raising services one by one with the help of the command:
In the end, if everything worked out right for you, you should see that the / shared file system will be available on each node.
For the tests, a simple script was used that sequentially reads and writes data from each of the nodes via dd, for example:
The block size is set large, reading is done in the 'direct' mode to test the file system itself, and not the speed of working with disk cache. The results were as follows:
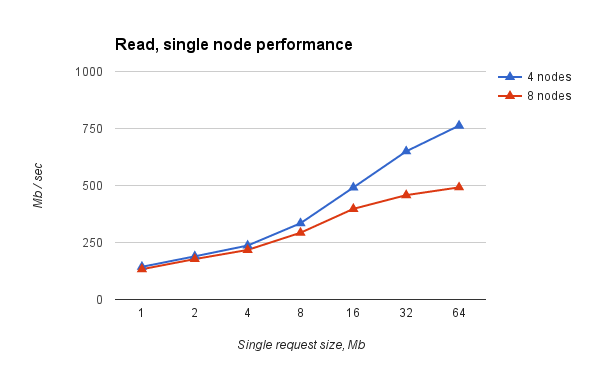
Fig.1. Simultaneous reading from all nodes of virtual clusters of different sizes. Performance per node.
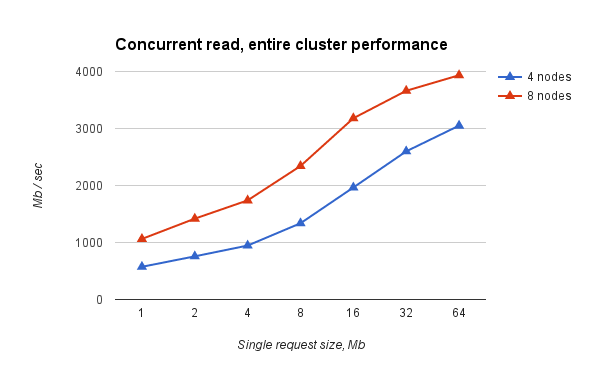
Fig.2. Simultaneous reading from all nodes of virtual clusters of different sizes. Total performance
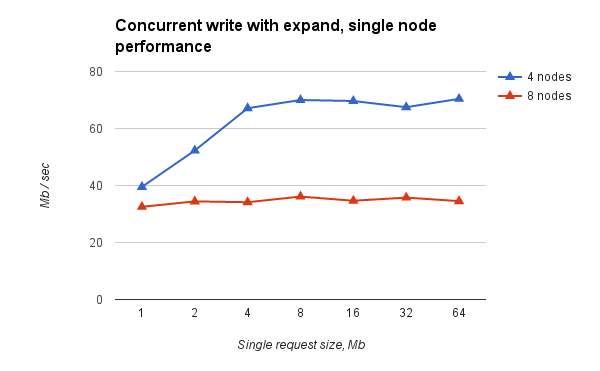
Fig.3. Simultaneous recording from all nodes of virtual clusters of different sizes. Performance per node.
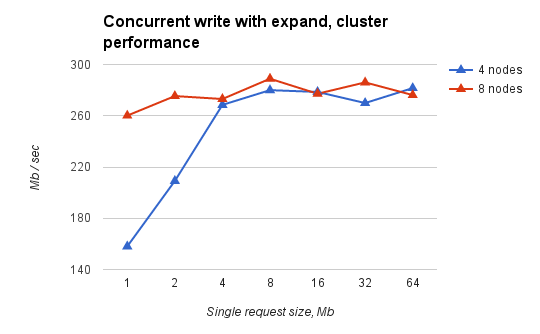
Fig.4. Simultaneous recording from all nodes of virtual clusters of different sizes. Total performance
What conclusions can be drawn:
The pitfalls include the need to correctly shut down at least the last of all virtual machines using a cluster. Otherwise, the file system may be in a state that requires recovery. A serious problem is also the correct setting of fencing to disconnect from the pcs cluster of a node that has lost synchronization with others. But more about that in the following articles.
The material was prepared by Andrey Nikolaev, Denis Lunev, Anna Subbotina.
As part of the work on the HPC HUB project, based on OpenStack, the task arose of creating fault-tolerant and high-performance shared storage for several groups of virtual machines, each of which is a small virtual HPC cluster. Each such cluster is issued to a separate client, which from the inside completely controls it. Thus, the task cannot be solved within the framework of a “normal” distributed system assembled on physical computers, since Ethernet networks of clusters are isolated from each other at the L2 level to protect customer data and their network traffic from each other. At the same time, data cannot be placed on each of the virtual machines within the framework of the classic shared system, because each machine lacks the capabilities and wants to free up valuable processor resources immediately after the calculations, without spending it on “data transfusion”, especially taking into account the use of the pay-per model -use. Fortunately, not everything is so bad. In light of the fact that shared storage is supposed to be used for HPC calculations, you can make several assumptions about the load:
- operations will be performed in large blocks;
- write operations will not be frequent, but will be interspersed with time significant intervals;
- write operations can begin immediately from all nodes almost simultaneously, but even in this case, you want to finish the recording as quickly as possible so that the nodes continue counting.
A peer-to-peer system with nodes on which the calculation is made and data are simultaneously stored contradicts the HPC paradigm in principle, since Two un-synchronized activities appear on the node: an account and data recording from some other node. We were forced to abandon it initially. It was decided to build a two-tier system. There are several approaches to such a repository:
- Distributed file system mounted on a virtual node through a specially organized network device to avoid performance losses from OpenStack network virtualization.

- A distributed file system mounted on a physical node and accessed from the guest system via a virtual file system.
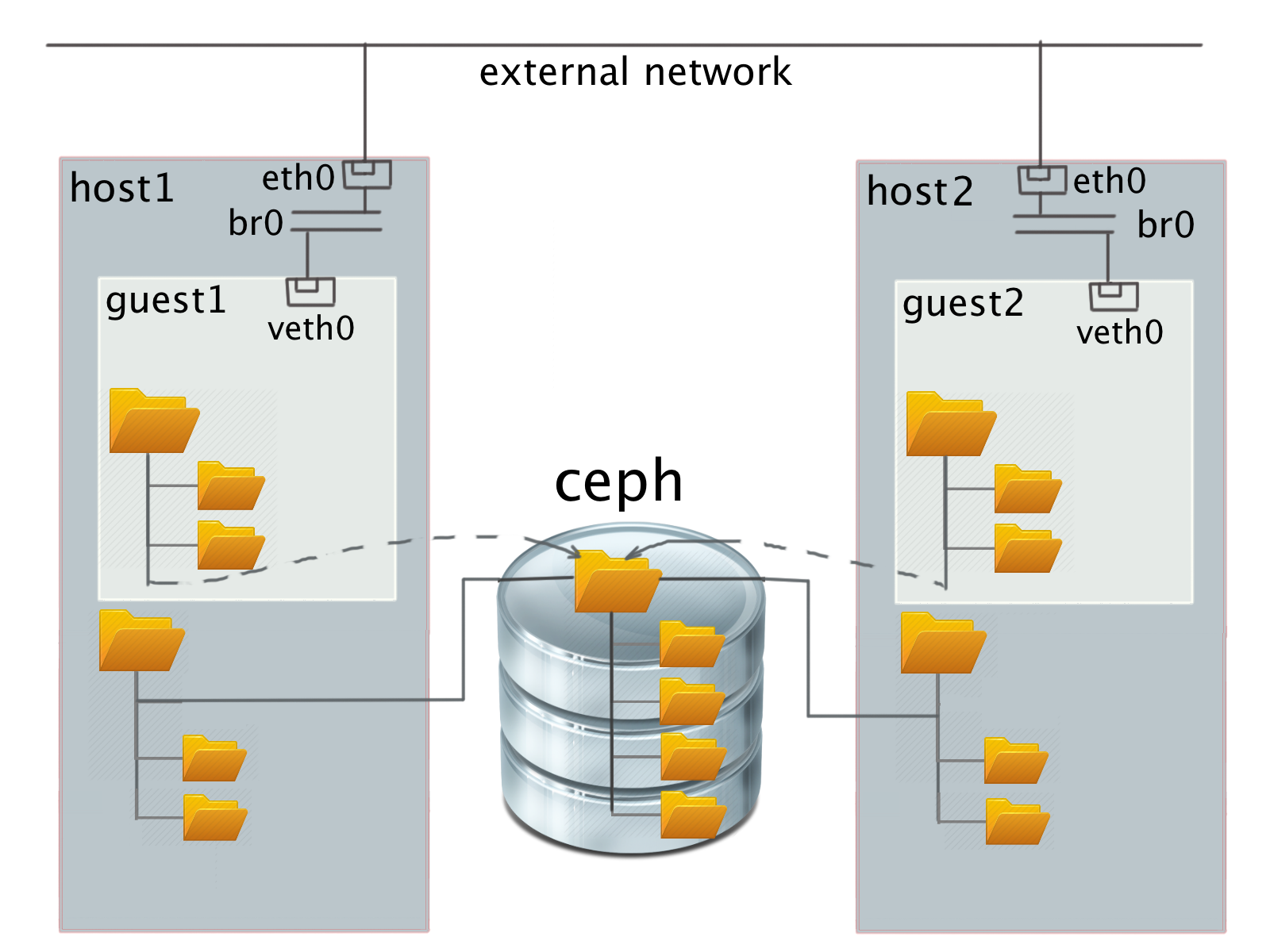
- Classic distributed file system inside a virtual cluster on top of a guest block device.
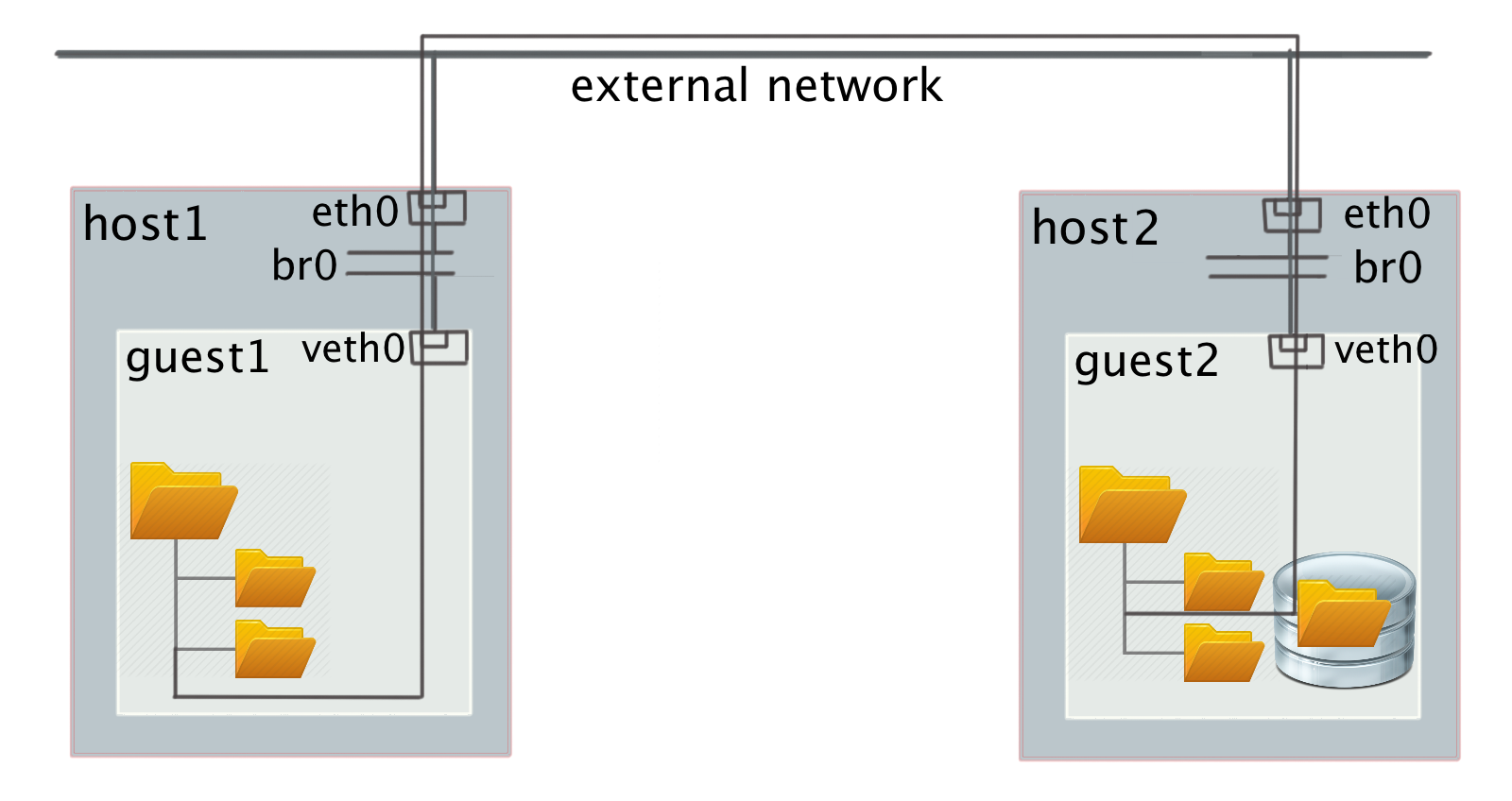
- A distributed block device, common to each virtual node, and a pre-configured file system within a virtual cluster, running on top of this shared device.

Let's try to analyze the advantages and disadvantages of these approaches.
')
In option 1) the classic distributed file system (or some subtree) is mounted to the guest OS. In this case, the file system servers are visible from each system and each other. This breaks network isolation at L2 level and potentially allows different users to see each other’s traffic with stored data. In addition, for the case of CEPH, only cooperative quotas are possible (that is, the user can reuse the allowable disk space at the expense of other users) in the file system mount mode via FUSE (filesystem in userspace), and not directly in the kernel. When mounted directly in the kernel, quotas are not supported at all.
In option 2) - a virtual file system (virtio-9p in QEMU) on top of a distributed file system mounted in a host - to work, you need to run QEMU on behalf of the superuser without lowering privileges, which reduces the overall security of the system or configure specific ACLs to store guest IDs users and guest access rights.
In option 3) in the absence of disk space on the physical servers, we can use only remote block devices of some kind of distributed storage. This option is not advisable for several reasons:
- data access will require 2 times more network bandwidth. Data is first transferred from the distributed storage to a specific virtual node and only then sent to the final consumer;
- as a rule, all such systems support data redundancy, which is unacceptable. For example, with the default settings for CEPH, the usable storage capacity is already reduced by 4 times the available disk space. All network loads that support distributed FS will also be inside the virtual network space. And, what is the most difficult, the latter option will actually require the allocation of physical nodes for storage virtualke, which leads to a sharp decrease in overall efficiency.
In option 4) we decided to try a distributed block device based on CEPH and some kind of file system within the cluster working with such a device. In fact, the guest, of course, sees the device not as a CEPH block device, but as an ordinary virtual VirtIO SCSI or, optionally, VirtIO block. We chose VirtIO SCSI for a very simple reason - because of the SCSI support for the unmap command, an analog of the well-known SATA TRIM command, which is sent by the guest when deleting files and freeing up space in the virtual storage.
Choosing a file system for a guest is also easy. There are only two options:
- OCFS2,
- Gfs2
Shared Storage Configuration
The installation of CEPH is perfectly described in the docs.ceph.com/docs/master/start documentation and did not cause any special problems. Currently, the system works with one redundant copy of data and without authorization. The CEPH network is isolated from the client network. Creating a block device also did not cause problems. Everything is standard.
GFS2 configuration
Unfortunately, setting up with GFS2 took a lot longer than originally estimated. Explanatory descriptions in the network is extremely small and they are confused. The general idea looks something like this. The work of the shared file system in the kernel is controlled by several demons, the correct setting of which requires nontrivial effort or knowledge.
The first and most important thing to know is that you most likely will not be able to raise this file system on Ubuntu. Or you will have to rebuild a lot of little-used packages outside of RedHat under Ubuntu, allowing a bunch of non-trivial API-level conflicts.
Under a RedHat-like system, the sequence is more or less clear. Below are the commands for the guest CentOS 7.
First off, turn off SELinux. GFS2 will not work with it. This is official information from the manufacturer.
vi /etc/sysconfig/selinux # , Put the basic software:
yum -y install ntp epel-release vim openssh-server net-tools Enable / disable the necessary services:
chkconfig ntpd on chkconfig firewalld off NTP is necessary for the operation of the system; all distributed locks of areas of the block device are tied to it. The system is configured for a cluster isolated from the outside world, therefore, we disable firewalls. Next, we put the necessary software binding on each of the cluster nodes:
yum -y install gfs2-utils lvm2-cluster pcs fence-agents-all chkconfig pcsd on # PaceMaker - RedHat lvmconf --enable-cluster # GFS2 echo <PASSWORD> | passwd --stdin hacluster # . :) reboot # SELinux LVM Please note that you do not need to create the user 'hacluster', it is created by itself when installing packages. In the future, you will need his password to create a network of mutual authorization between the cluster machines.
You can now create distributed storage if this has not been done before. It is done on any CEPH node, that is, in our case, on a physical node:
rbd create my-storage-name --image-format 2 --size 6291456 # ! sudo rbd map rbd/my-storage-name sudo mkfs.gfs2 -p lock_dlm -t gfs2:fs -j17 /dev/rbd0 sudo rbd unmap /dev/rbd0 When formatting a file system, the cluster name is specified - in our case, 'gfs2' and the name of the file system within this cluster is 'fs', the number of journals is '-j17', which should be equal to the number of nodes (in our case, 17) that simultaneously work with this cluster and lock protocol for allocating disk space (in our case, 'lock_dlm' is distributed locking). The names of the cluster and file system will have to be specified when mounting the partition. In an isolated network within a cluster, you can use the same names for different clusters. This is not a problem.
Now it remains only to configure the mount in the guest OS. The configuration is performed with one of the cluster machines once.
pcs cluster destroy --all # , Creating a mutual authorization network:
pcs cluster auth master n01 n02 n03 n04 -u hacluster -p 1q2w3e4r --force here, master and n01..n04 are virtual hosts on which a shared partition will be available.
Create a default cluster. Note that the cluster name must match the one used when creating the file system in the previous step.
pcs cluster setup --name gfs2 master n01 n02 n03 n04 pcs cluster start --all # pcs cluster enable --all # Running service daemons - clvmd & dlm:
pcs property set no-quorum-policy=ignore pcs stonith create local_stonith fence_kdump pcmk_monitor_action="metadata" pcs resource create dlm ocf:pacemaker:controld op monitor interval=30s \ on-fail=fence clone interleave=true ordered=true pcs resource create clvmd ocf:heartbeat:clvm op monitor interval=30s \ on-fail=fence clone interleave=true ordered=true pcs constraint order start dlm-clone then clvmd-clone pcs constraint colocation add clvmd-clone with dlm-clone Mounting a GFS2 partition in / shared, shared block device - sdb:
pcs resource create clusterfs Filesystem device="/dev/sdb" \ directory="/shared" fstype="gfs2" "options=noatime,nodiratime" op \ monitor interval=10s on-fail=fence clone interleave=true pcs constraint order start clvmd-clone then clusterfs-clone pcs constraint colocation add clusterfs-clone with clvmd-clone From this point on, you can enjoy the start of the whole system, raising services one by one with the help of the command:
pcs status resources In the end, if everything worked out right for you, you should see that the / shared file system will be available on each node.
Performance tests
For the tests, a simple script was used that sequentially reads and writes data from each of the nodes via dd, for example:
dd if=/shared/file of=/dev/null bs=32M iflag=direct dd if=/root/file of=/shared/file bs=32M oflag=direct The block size is set large, reading is done in the 'direct' mode to test the file system itself, and not the speed of working with disk cache. The results were as follows:
Fig.1. Simultaneous reading from all nodes of virtual clusters of different sizes. Performance per node.
Fig.2. Simultaneous reading from all nodes of virtual clusters of different sizes. Total performance
Fig.3. Simultaneous recording from all nodes of virtual clusters of different sizes. Performance per node.
Fig.4. Simultaneous recording from all nodes of virtual clusters of different sizes. Total performance
findings
What conclusions can be drawn:
- reading almost rests on network bandwidth (~ 9 Gbps, Infiniband, IPoIB) and scales well with the increase in the number of nodes of the virtual cluster;
- the record rests on the practical ceiling and does not scale. But given the assumptions made, it suits us so far. The mechanism that led to the existence of such a ceiling remains unclear to us.
Underwater rocks
The pitfalls include the need to correctly shut down at least the last of all virtual machines using a cluster. Otherwise, the file system may be in a state that requires recovery. A serious problem is also the correct setting of fencing to disconnect from the pcs cluster of a node that has lost synchronization with others. But more about that in the following articles.
The material was prepared by Andrey Nikolaev, Denis Lunev, Anna Subbotina.
Source: https://habr.com/ru/post/312652/
All Articles