Unicode: the necessary practical minimum for each developer
Unicode is a very large and complex world, because the standard allows us to represent and work on a computer with all the major scripts of the world. Some writing systems have existed for over a thousand years, and many of them developed almost independently from each other in different parts of the world. People invented so much and it is often so different from each other that to combine all this into a single standard was an extremely difficult and ambitious task.
To really deal with Unicode, you need to at least superficially imagine the features of all the scripts with which the standard allows you to work. But does every developer need this? We say no. To use Unicode in most everyday tasks, it is enough to possess a reasonable minimum of information, and then go deeper into the standard as needed.
In the article we will talk about the basic principles of Unicode and highlight the important practical issues that developers will certainly encounter in their daily work.
')
Before the advent of Unicode, single-byte encodings were used almost everywhere, in which the boundary between the characters themselves, their representation in computer memory and display on the screen was rather relative. If you worked with one or another national language, then the appropriate encoding fonts were installed on your system, which allowed the bytes to be drawn from the disk on the screen so that they represented meaning to the user.
If you printed a text file on the printer and saw a set of obscure cracks on the paper page, this meant that the appropriate fonts were not loaded into the printer and it did not interpret the bytes as you would like.
This approach as a whole and single-byte encodings in particular had a number of significant drawbacks:
We all understand that the computer does not know about any ideal entities, but operates with bits and bytes. But computer systems are still created by people, not machines, and it’s sometimes more convenient for us to operate with speculative concepts, and then move from the abstract to the concrete.
Important! One of the central principles in Unicode philosophy is a clear distinction between characters, their representation in a computer, and their display on an output device.
The concept of an abstract unicode symbol is introduced, which exists exclusively in the form of a speculative concept and agreement between people, enshrined in the standard. Each unicode symbol is assigned a nonnegative integer, called its code point.
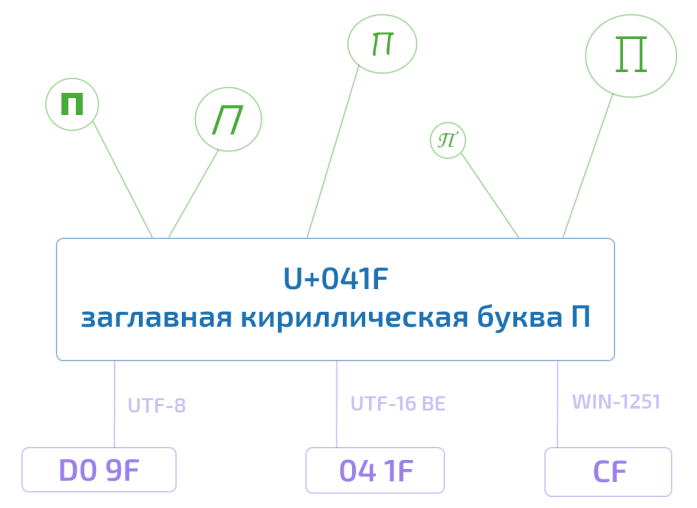
So, for example, the Unicode symbol U + 041F is the capital Cyrillic letter P. There are several possibilities for representing this symbol in the computer's memory, exactly like several thousand ways of displaying it on the monitor screen. But at the same time P, it will be P or U + 041F in Africa too.
This is a well-known encapsulation or separation of the interface from the implementation - a concept that has proven itself in programming.
It turns out that, guided by the standard, any text can be encoded as a sequence of Unicode characters.
write on a piece of paper, pack in an envelope and send to any end of the Earth. If they know about the existence of Unicode, then the text will be perceived by them exactly the same way as we are with you. They will not have the slightest doubt that the penultimate character is a Cyrillic lowercase e (U + 0435), and not a Latin small e (U + 0065). Note that we did not say a word about the byte representation.
Although Unicode symbols are called symbols, they do not always correspond to a symbol in the traditional naive sense, such as a letter, number, punctuation mark, or hieroglyph. (For details, see under the spoiler.)
The Unicode code space consists of 1,114,112 code positions in the range from 0 to 10FFFF. Of these, only 128 237 are assigned to the ninth version of the standard. Part of the space is reserved for private use, and the Unicode consortium promises never to assign values to positions from these special areas.
For the sake of convenience, the whole space is divided into 17 planes (six of them are now involved). Until recently, it was customary to say that most likely you will have to face only the Basic Multilingual Plane (BMP), which includes Unicode characters from U + 0000 to U + FFFF. (Looking a little further: the characters from BMP are represented in UTF-16 by two bytes, not four). In 2016, this thesis is already in doubt. For example, the popular characters of Emoji may well meet in the user message and you need to be able to handle them correctly.
If we want to send text over the Internet, then we will need to encode a sequence of Unicode characters as a sequence of bytes.
The Unicode standard includes a description of a series of Unicode encodings, such as UTF-8 and UTF-16BE / UTF-16LE, which allow you to encode the entire space of code positions. Conversion between these encodings can be freely carried out without loss of information.
Also, no one has canceled single-byte encodings, but they allow you to encode your individual and very narrow piece of the unicode spectrum — 256 or less code positions. For such encodings, there are tables available and available to everyone, where each value of a single byte is associated with a Unicode-character (see, for example, CP1251.TXT ). Despite the limitations, single-byte encodings turn out to be very practical when it comes to working with a large array of mono-language textual information.
Of the unicode encodings, UTF-8 is the most widely used on the Internet (it won the championship in 2008), mainly due to its cost-effectiveness and transparent compatibility with seven-bit ASCII. Latin and service characters, basic punctuation marks and numbers - i.e. All seven-bit ASCII characters are encoded in UTF-8 in one byte, the same as in ASCII. The characters of many basic scripts, not counting some of the more rare hieroglyphic characters, are represented in it by two or three bytes. The largest code point defined by the standard - 10FFFF - is encoded by four bytes.
Note that UTF-8 is a variable length encoding. Each Unicode symbol in it is represented by a sequence of code quanta with a minimum length of one quantum. The number 8 means the bit length of a code quantum (code unit) is 8 bits. For the UTF-16 family of encodings, the size of the code quantum is 16 bits, respectively. For UTF-32, 32 bits.
For storing string information, applications often use 16-bit Unicode encodings due to their simplicity, as well as the fact that the characters of the main world writing systems are encoded with one 16-bit quantum. For example, Java successfully uses UTF-16 for internal string representation. The Windows operating system also uses UTF-16 internally.
In any case, as long as we remain in Unicode space, it is not so important how the string information is stored within a separate application. If the internal storage format allows you to correctly encode all a million or more code points and at the boundary of the application, for example, when reading from a file or copying to the clipboard, there is no loss of information, then all is well.
To correctly interpret the text read from a disk or from a network socket, you must first determine its encoding. This is done either using the meta-information provided by the user, written in or next to the text, or determined heuristically.
There is a lot of information and it makes sense to give a brief pressing of everything that was written above:
There may be some confusion with the term encoding. Within Unicode, encoding occurs twice. The first time a Unicode character set (character set) is encoded, in the sense that a code position is assigned to each Unicode character. As part of this process, the Unicode character set is transformed into a coded character set. The second time a sequence of unicode characters is converted to a byte string, and this process is also called encoding.
In English terminology, there are two different verbs to code and to encode, but even native speakers are often confused. In addition, the term character set (character set or charset) is used as a synonym for the term coded character set (coded character set).
All this we say to that it makes sense to pay attention to the context and to distinguish between situations when it comes to the code position of an abstract unicode symbol and when it comes to its byte representation.
There are so many different aspects to Unicode that it’s impossible to cover everything in one article. Yes, and unnecessary. The above information is quite enough to not be confused with the basic principles and work with the text in most everyday tasks (read: without going beyond the framework of BMP). In the following articles we will talk about normalization, give a more complete historical overview of the development of encodings, talk about the problems of Russian-language Unicode terminology, and also make a material about the practical aspects of using UTF-8 and UTF-16.
To really deal with Unicode, you need to at least superficially imagine the features of all the scripts with which the standard allows you to work. But does every developer need this? We say no. To use Unicode in most everyday tasks, it is enough to possess a reasonable minimum of information, and then go deeper into the standard as needed.
In the article we will talk about the basic principles of Unicode and highlight the important practical issues that developers will certainly encounter in their daily work.
')
Why did you need Unicode?
Before the advent of Unicode, single-byte encodings were used almost everywhere, in which the boundary between the characters themselves, their representation in computer memory and display on the screen was rather relative. If you worked with one or another national language, then the appropriate encoding fonts were installed on your system, which allowed the bytes to be drawn from the disk on the screen so that they represented meaning to the user.
If you printed a text file on the printer and saw a set of obscure cracks on the paper page, this meant that the appropriate fonts were not loaded into the printer and it did not interpret the bytes as you would like.
This approach as a whole and single-byte encodings in particular had a number of significant drawbacks:
- It was possible to work simultaneously with only 256 characters, the first 128 were reserved for Latin and control characters, and in the second half, in addition to the characters of the national alphabet, it was necessary to find a place for pseudographics (╗).
- Fonts were bound to a specific encoding.
- Each encoding represented its own set of characters and conversion from one to another was possible only with partial losses, when the missing characters were replaced with graphically similar ones.
- Transferring files between devices running different operating systems was difficult. It was necessary either to have a converter program, or to drag along with the file additional fonts. The existence of the Internet as we know it was impossible.
- In the world there are non-alphabetic writing systems (hieroglyphic writing), which in single-byte encoding cannot be represented in principle.
Basic Unicode Principles
We all understand that the computer does not know about any ideal entities, but operates with bits and bytes. But computer systems are still created by people, not machines, and it’s sometimes more convenient for us to operate with speculative concepts, and then move from the abstract to the concrete.
Important! One of the central principles in Unicode philosophy is a clear distinction between characters, their representation in a computer, and their display on an output device.
The concept of an abstract unicode symbol is introduced, which exists exclusively in the form of a speculative concept and agreement between people, enshrined in the standard. Each unicode symbol is assigned a nonnegative integer, called its code point.
So, for example, the Unicode symbol U + 041F is the capital Cyrillic letter P. There are several possibilities for representing this symbol in the computer's memory, exactly like several thousand ways of displaying it on the monitor screen. But at the same time P, it will be P or U + 041F in Africa too.
This is a well-known encapsulation or separation of the interface from the implementation - a concept that has proven itself in programming.
It turns out that, guided by the standard, any text can be encoded as a sequence of Unicode characters.
U+041F U+0440 U+0438 U+0432 U+0435 U+0442 write on a piece of paper, pack in an envelope and send to any end of the Earth. If they know about the existence of Unicode, then the text will be perceived by them exactly the same way as we are with you. They will not have the slightest doubt that the penultimate character is a Cyrillic lowercase e (U + 0435), and not a Latin small e (U + 0065). Note that we did not say a word about the byte representation.
Although Unicode symbols are called symbols, they do not always correspond to a symbol in the traditional naive sense, such as a letter, number, punctuation mark, or hieroglyph. (For details, see under the spoiler.)
Examples of different unicode characters
There are purely technical Unicode characters, for example:
There are punctuation markers, for example, U + 200F: a marker for changing the direction of the letter from right to left.
There is a whole cohort of spaces of various widths and purposes (see the excellent habr article: everything (or almost all) about the space ):
There are combinable diacritical marks (combining diacritical marks) - all sorts of strokes, points, tildes, etc., which change / specify the meaning of the previous mark and its style. For example:
There is even such an exotic thing as language tags (U + E0001, U + E0020 – U + E007E, and U + E007F), which are now in limbo. They conceived as an opportunity to mark certain sections of the text as belonging to one or another variant of the language (say, American and British English), which could affect the details of the text display.
What is a symbol, how does a grapheme cluster (read: perceived as a single whole image of a symbol) differ from a unicode symbol and from a code quantum we will tell next time.
- U + 0000: the null character;
- U + D800 – U + DFFF: junior and senior substitutes for the technical presentation of code positions in the range from 10,000 to 10FFFF (read: outside the BMNP / BMP) in the UTF-16 family of encodings;
- etc.
There are punctuation markers, for example, U + 200F: a marker for changing the direction of the letter from right to left.
There is a whole cohort of spaces of various widths and purposes (see the excellent habr article: everything (or almost all) about the space ):
- U + 0020 (space);
- U + 00A0 (non-breaking space, & nbsp; in HTML);
- U + 2002 (semicircular space or En Space);
- U + 2003 (round space or Em Space);
- etc.
There are combinable diacritical marks (combining diacritical marks) - all sorts of strokes, points, tildes, etc., which change / specify the meaning of the previous mark and its style. For example:
- U + 0300 and U + 0301: signs of the main (acute) and secondary (weak) stress;
- U + 0306: is short (superscript arc), as in th;
- U + 0303: superscript tilde;
- etc.
There is even such an exotic thing as language tags (U + E0001, U + E0020 – U + E007E, and U + E007F), which are now in limbo. They conceived as an opportunity to mark certain sections of the text as belonging to one or another variant of the language (say, American and British English), which could affect the details of the text display.
What is a symbol, how does a grapheme cluster (read: perceived as a single whole image of a symbol) differ from a unicode symbol and from a code quantum we will tell next time.
Unicode code space
The Unicode code space consists of 1,114,112 code positions in the range from 0 to 10FFFF. Of these, only 128 237 are assigned to the ninth version of the standard. Part of the space is reserved for private use, and the Unicode consortium promises never to assign values to positions from these special areas.
For the sake of convenience, the whole space is divided into 17 planes (six of them are now involved). Until recently, it was customary to say that most likely you will have to face only the Basic Multilingual Plane (BMP), which includes Unicode characters from U + 0000 to U + FFFF. (Looking a little further: the characters from BMP are represented in UTF-16 by two bytes, not four). In 2016, this thesis is already in doubt. For example, the popular characters of Emoji may well meet in the user message and you need to be able to handle them correctly.
Encodings
If we want to send text over the Internet, then we will need to encode a sequence of Unicode characters as a sequence of bytes.
The Unicode standard includes a description of a series of Unicode encodings, such as UTF-8 and UTF-16BE / UTF-16LE, which allow you to encode the entire space of code positions. Conversion between these encodings can be freely carried out without loss of information.
Also, no one has canceled single-byte encodings, but they allow you to encode your individual and very narrow piece of the unicode spectrum — 256 or less code positions. For such encodings, there are tables available and available to everyone, where each value of a single byte is associated with a Unicode-character (see, for example, CP1251.TXT ). Despite the limitations, single-byte encodings turn out to be very practical when it comes to working with a large array of mono-language textual information.
Of the unicode encodings, UTF-8 is the most widely used on the Internet (it won the championship in 2008), mainly due to its cost-effectiveness and transparent compatibility with seven-bit ASCII. Latin and service characters, basic punctuation marks and numbers - i.e. All seven-bit ASCII characters are encoded in UTF-8 in one byte, the same as in ASCII. The characters of many basic scripts, not counting some of the more rare hieroglyphic characters, are represented in it by two or three bytes. The largest code point defined by the standard - 10FFFF - is encoded by four bytes.
Note that UTF-8 is a variable length encoding. Each Unicode symbol in it is represented by a sequence of code quanta with a minimum length of one quantum. The number 8 means the bit length of a code quantum (code unit) is 8 bits. For the UTF-16 family of encodings, the size of the code quantum is 16 bits, respectively. For UTF-32, 32 bits.
If you send an HTML page with Cyrillic text over the network, then UTF-8 can give a very tangible gain, since all the markup, as well as JavaScript and CSS blocks will be efficiently encoded in one byte. For example, the main Habr page in UTF-8 occupies 139Kb, and in UTF-16 already 256Kb. For comparison, if you use win-1251 with the loss of the ability to save some characters, the size, compared with UTF-8, will be reduced by only 11Kb to 128Kb.
For storing string information, applications often use 16-bit Unicode encodings due to their simplicity, as well as the fact that the characters of the main world writing systems are encoded with one 16-bit quantum. For example, Java successfully uses UTF-16 for internal string representation. The Windows operating system also uses UTF-16 internally.
In any case, as long as we remain in Unicode space, it is not so important how the string information is stored within a separate application. If the internal storage format allows you to correctly encode all a million or more code points and at the boundary of the application, for example, when reading from a file or copying to the clipboard, there is no loss of information, then all is well.
To correctly interpret the text read from a disk or from a network socket, you must first determine its encoding. This is done either using the meta-information provided by the user, written in or next to the text, or determined heuristically.
In the dry residue
There is a lot of information and it makes sense to give a brief pressing of everything that was written above:
- Unicode postulates a clear distinction between characters, their representation in the computer and their display on the output device.
- Unicode characters do not always correspond to a character in the traditional naive sense, such as a letter, number, punctuation mark, or hieroglyph.
- The Unicode code space consists of 1,114,112 code positions in the range from 0 to 10FFFF.
- The basic multilanguage plane includes Unicode characters from U + 0000 to U + FFFF, which are encoded in UTF-16 in two bytes.
- Any Unicode encoding allows you to encode the entire space of Unicode code positions and conversion between various such encodings is carried out without loss of information.
- Single-byte encodings allow you to encode only a small part of the Unicode spectrum, but may be useful when working with a large amount of single-language information.
- UTF-8 and UTF-16 encodings have variable code lengths. In UTF-8, each Unicode character can be encoded with one, two, three, or four bytes. In UTF-16, two or four bytes.
- The internal format of storing textual information within a single application can be arbitrary, provided that it works correctly with the entire Unicode code position space and there is no loss in cross-border data transfer.
A brief note about coding
There may be some confusion with the term encoding. Within Unicode, encoding occurs twice. The first time a Unicode character set (character set) is encoded, in the sense that a code position is assigned to each Unicode character. As part of this process, the Unicode character set is transformed into a coded character set. The second time a sequence of unicode characters is converted to a byte string, and this process is also called encoding.
In English terminology, there are two different verbs to code and to encode, but even native speakers are often confused. In addition, the term character set (character set or charset) is used as a synonym for the term coded character set (coded character set).
All this we say to that it makes sense to pay attention to the context and to distinguish between situations when it comes to the code position of an abstract unicode symbol and when it comes to its byte representation.
Finally
There are so many different aspects to Unicode that it’s impossible to cover everything in one article. Yes, and unnecessary. The above information is quite enough to not be confused with the basic principles and work with the text in most everyday tasks (read: without going beyond the framework of BMP). In the following articles we will talk about normalization, give a more complete historical overview of the development of encodings, talk about the problems of Russian-language Unicode terminology, and also make a material about the practical aspects of using UTF-8 and UTF-16.
Source: https://habr.com/ru/post/312642/
All Articles