readRss - local rss reader as browser extension
This is an rss reader in the form of a browser extension (js-application), which allows you to read rss-streams in general without the presence of the Internet, even pictures are downloaded in advance. And now more.
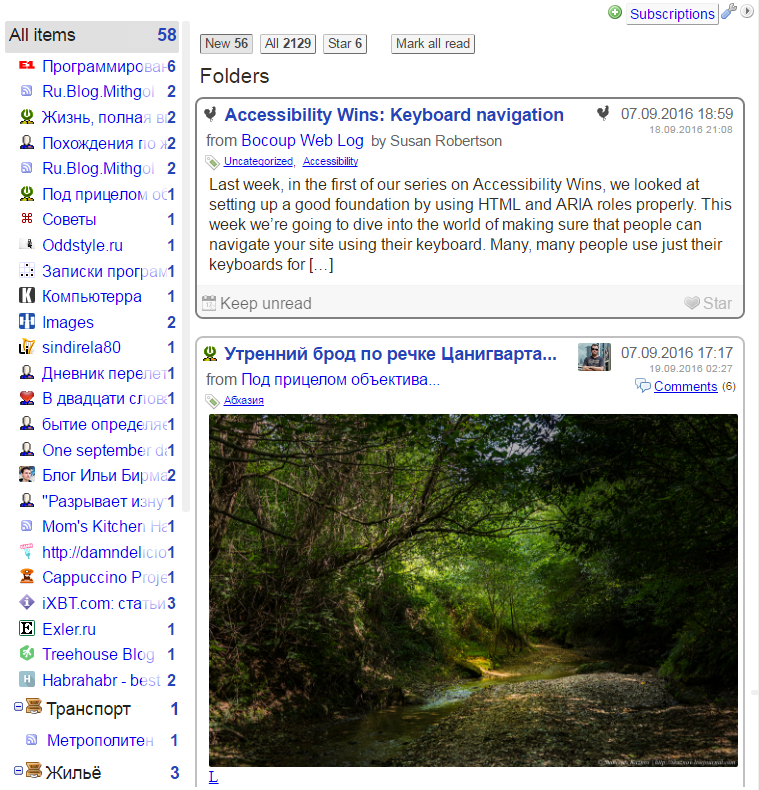
Screenshot of what it looks like:
In the near 2012, when GR left, I began to think how could I continue reading the news. I looked through a bunch of different readers. Among them were very worthy ones that can be used, but they had many different drawbacks - then you have to pay, then there are no necessary functions, etc.
')
As a front-end developer, I decided to write an application on js that would work locally, connecting to the browser. This is convenient primarily because, for example, the problem of authorization goes into the background. There are rss-streams that work only if you are authorized on the site. For example, the same live journal. In this case, all the subrecordary entries (entries for friends) will be great to come to the reading room.
Secondly, it is convenient in that the browser is a platform, a foundation in which there is a lot of ready-made. Access to the sqlite database, download files, application icon.
I honestly looked at the interface from a Google reader, a little bit of it.
In those years I created a similar project for reading forums. The kernel was written in php, but it seemed to me outdated and poorly developed, I made a bet on javascript. And I took the design from this project, added the core to js and embedded it in the extension. And that's what happened.
Now this extension is a beta version, with a small number of bugs and workable, I use it to read RSS, so when it became stable, I decided to share it with the public. You can use it by putting it as an extension (through the folder in developer mode). I do not guarantee super-magic of design when this extension works, but it works, I can say for sure.
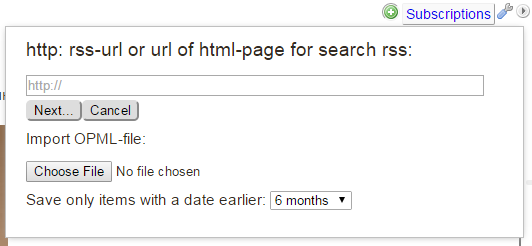
1. Specify the exact address of the stream.
2. Specify just url-pages. You will be shown a list of streams found there and you can subscribe after leaving the necessary daws.
3. Import the OPML file. Import works in turn, so please be patient.
Different types of streams are supported - rss, atom, rdf. Almost everything that is inside is supported - attachments, geo, categories, comments, author, etc.
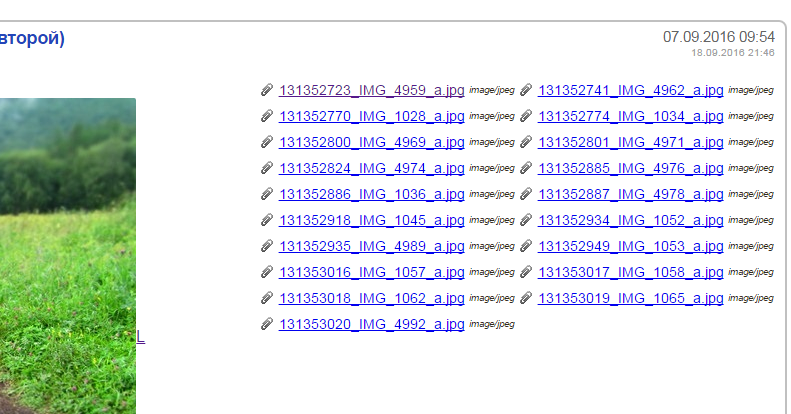
Attachments will be shown in the list on the right, and if this is a picture, it is shown as a picture:

If such a picture is already in the text of the article, then there will be just a title so as not to be duplicated:
Video and audio - the player will seem. There is a list of subscriptions and you can unsubscribe. There is a quick search.

All pictures in articles are loaded into the database and then displayed when viewed. Made it cleverly, the picture is loaded from the database only if it appears in the viewing area. Further, if it leaves the viewing area, it is unloaded. This will certainly save memory.
In the future, the picture is cached for a week, and if it is no longer needed, it is deleted from the database automatically. Folders are provided in the architecture, but the interface is not yet implemented when adding a stream, to which folder to add. At the moment, only the basis has been done, much has not been done, but I plan to add it as much as possible.
» Source code posted on github
Essentially, the rss-parser library is of interest. I created it myself from scratch, because there is no finished one, especially with the opportunities that I added there.
Sanitize is used to clean up the html of all the excess that is not needed for reading.
Of course, my govnokod will be of little interest to anyone, but if you use it, write a link to me so that it is clear who to beat =)
Plans a lot. Although the minimum algorithm for calculating the time for further loading of the stream is implemented, it is very rough and stupid. The plans are to make it smart, so that less traffic is spent on the scan. Although caching and issuing headers are already being applied, so for the most part there is an answer 304. At the first stage, the goal was to promptly deliver information without delay.
The plans, of course, add a lot of convenient interface stuff - delete the stream, move to another folder, etc.
Thank.
Screenshot of what it looks like:
In the near 2012, when GR left, I began to think how could I continue reading the news. I looked through a bunch of different readers. Among them were very worthy ones that can be used, but they had many different drawbacks - then you have to pay, then there are no necessary functions, etc.
')
As a front-end developer, I decided to write an application on js that would work locally, connecting to the browser. This is convenient primarily because, for example, the problem of authorization goes into the background. There are rss-streams that work only if you are authorized on the site. For example, the same live journal. In this case, all the subrecordary entries (entries for friends) will be great to come to the reading room.
Secondly, it is convenient in that the browser is a platform, a foundation in which there is a lot of ready-made. Access to the sqlite database, download files, application icon.
I honestly looked at the interface from a Google reader, a little bit of it.
In those years I created a similar project for reading forums. The kernel was written in php, but it seemed to me outdated and poorly developed, I made a bet on javascript. And I took the design from this project, added the core to js and embedded it in the extension. And that's what happened.
Now this extension is a beta version, with a small number of bugs and workable, I use it to read RSS, so when it became stable, I decided to share it with the public. You can use it by putting it as an extension (through the folder in developer mode). I do not guarantee super-magic of design when this extension works, but it works, I can say for sure.
Work keys J, K, V, M
J - next entry
K - previous
V - open link in new tab
M - mark as unread
There are three ways to add a stream.
1. Specify the exact address of the stream.
2. Specify just url-pages. You will be shown a list of streams found there and you can subscribe after leaving the necessary daws.
3. Import the OPML file. Import works in turn, so please be patient.
Those details
Different types of streams are supported - rss, atom, rdf. Almost everything that is inside is supported - attachments, geo, categories, comments, author, etc.
Attachments will be shown in the list on the right, and if this is a picture, it is shown as a picture:
If such a picture is already in the text of the article, then there will be just a title so as not to be duplicated:
Video and audio - the player will seem. There is a list of subscriptions and you can unsubscribe. There is a quick search.
All pictures in articles are loaded into the database and then displayed when viewed. Made it cleverly, the picture is loaded from the database only if it appears in the viewing area. Further, if it leaves the viewing area, it is unloaded. This will certainly save memory.
In the future, the picture is cached for a week, and if it is no longer needed, it is deleted from the database automatically. Folders are provided in the architecture, but the interface is not yet implemented when adding a stream, to which folder to add. At the moment, only the basis has been done, much has not been done, but I plan to add it as much as possible.
» Source code posted on github
Essentially, the rss-parser library is of interest. I created it myself from scratch, because there is no finished one, especially with the opportunities that I added there.
Sanitize is used to clean up the html of all the excess that is not needed for reading.
Of course, my govnokod will be of little interest to anyone, but if you use it, write a link to me so that it is clear who to beat =)
Plans
Plans a lot. Although the minimum algorithm for calculating the time for further loading of the stream is implemented, it is very rough and stupid. The plans are to make it smart, so that less traffic is spent on the scan. Although caching and issuing headers are already being applied, so for the most part there is an answer 304. At the first stage, the goal was to promptly deliver information without delay.
The plans, of course, add a lot of convenient interface stuff - delete the stream, move to another folder, etc.
Thank.
Source: https://habr.com/ru/post/312564/
All Articles